LangChain上下文工程实战:解决AI智能体“翻车“问题的关键技术
文章介绍了LangChain框架中通过上下文工程构建可靠AI智能体的方法。从数据来源(运行时上下文、状态、存储)和生命周期(瞬态上下文和持久上下文)两个维度详细解释了上下文的类型和使用方法。瞬态上下文通过中间件动态调整模型调用参数,持久上下文通过工具回写和生命周期管理实现智能体的连续性学习。最后提供了实用的避坑指南,帮助开发者构建生产级的上下文管道。
文章介绍了LangChain框架中通过上下文工程构建可靠AI智能体的方法。从数据来源(运行时上下文、状态、存储)和生命周期(瞬态上下文和持久上下文)两个维度详细解释了上下文的类型和使用方法。瞬态上下文通过中间件动态调整模型调用参数,持久上下文通过工具回写和生命周期管理实现智能体的连续性学习。最后提供了实用的避坑指南,帮助开发者构建生产级的上下文管道。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
01 前言
这是 2026 年的第一篇文章,首先祝大家新年快乐!愿我们在新的一年里,继续在 AI 的浪潮中并肩前行。
在前两篇关于 LangChain V1.0 的文章中,我们聊了如何通过 create\_agent 极简构建智能体以及运行时模型。但在实战中发现,Agent 往往在原型阶段表现惊艳,一到生产环节就容易“翻车”或“断片”。
Agent 失败的主要原因是什么?
通常并非模型不够聪明,而是因为我们没能把“正确”的信息,在“正确”的时间,以“正确”的格式喂给它。这种缺乏“正确上下文”的现状是构建可靠智能体的最大阻碍。
今天,我们就来看看 AI 工程师的核心基本功:上下文工程(Context Engineering),以及在Langchain中是如何使用的。
02 概览
在 LangChain 的设计哲学中,Agent 的核心是一个闭环:模型调用(Model call)与工具执行(Tool execution)。上下文工程的任务,就是在这两步之间建立高效的数据流动机制。
我们可以从**“数据来源”和“生命周期”两个维度来理解上下文**:
- 数据来源(Data Sources)
这是上下文的“原材料”,LangChain 将其分为三类:
- 运行时上下文 (Runtime Context):外部注入的静态配置(如用户 ID、API 密钥、当前时间、权限 Scope)。
- 状态 (State):对话作用域内的短期记忆(如当前消息历史、上传的文件引用、工具中间结果)。
- 存储 (Store):跨对话的长期记忆(如用户画像、历史偏好、提取的知识库)。
- 上下文生命周期(Context Lifecycle)
基于上述数据源,在 Agent 的执行环中,可以通过两种方式使用上下文(将在下文详细展开):
- 瞬态上下文(Transient Context):仅影响当前单次模型调用的视角,不改变系统状态。主要是**模型上下文(01)。**例如:动态注入 System Prompt 或过滤敏感工具。
- 持久上下文(Persistent Context):会将变更写入状态或存储,影响未来所有的交互。包括工具上下文(02)和生命周期上下文(03)。例如:工具执行结果回写、对话历史的自动总结压缩。
上下文类型包括模型上下文、工具上下文、生命周期上下文。
数据流动过程如下图所示:输入 -> 处理 -> 输出/回写
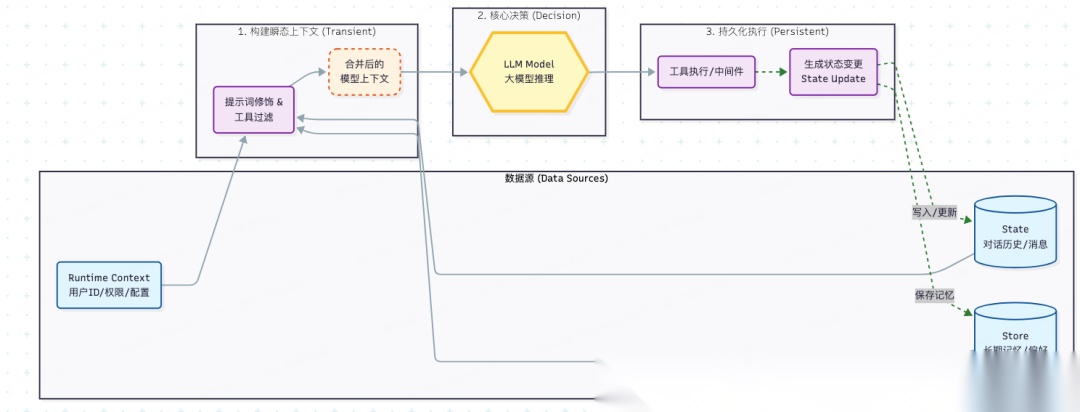
03 瞬态上下文
瞬态上下文(Transient Context)指的是模型在单次调用(Run)中看到的内容。它的特点是“阅后即焚”—我们可以灵活修改传给模型的信息,而不会污染系统中永久保存的状态。
通过Langchain的中间件(Middleware)机制,我们可以动态干预**模型上下文(Model Context)**的四个关键要素:
**1、**System Prompt:动态设定行为边界。例如根据用户 VIP 等级动态注入服务指令。
2、Messages:临时修剪或增强历史记录。例如在发送前隐藏某些敏感报错信息。
3、Tools:动态过滤工具集。例如用户未登录时,从 prompt 中移除“支付工具”的定义。
4、Response Format:强制结构化输出,确保返回结果符合业务 Schema。
一个示例:根据运行时权限动态注入提示词
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langchain.agents import create_agent
import os
from dataclasses import dataclass
@dataclass
classContext:
user_role: str
# 假设我们定义了一个上下文感知的 Prompt 函数
@dynamic_prompt
defcontext_aware_prompt(request: ModelRequest) -> str:
# 1. 从运行时上下文(Runtime Context)中读取用户元数据
user_role = request.runtime.context.user_role
base_prompt = "你是一个专业的AI助手。"
# 2. 根据角色动态调整 System Prompt (瞬态修改)
# 这个修改只影响本次请求,不会修改数据库里的用户角色
if user_role == "admin":
base_prompt += "\n当前用户拥有管理员权限,可以使用系统级工具。"
elif user_role == "viewer":
base_prompt += "\n当前用户仅有只读权限,涉及修改的操作请礼貌拒绝。"
print(base_prompt)
return base_prompt
# 定义agent
os.environ["DEEPSEEK_API_KEY"] = "sk-..."
agent = create_agent("deepseek-chat",
middleware=[context_aware_prompt],
context_schema=Context)
# 调用
response = agent.invoke(
{"messages": [{"role": "user", "content": "我有什么权限"}]},
context=Context(user_role="admin")
)
print(response)
示例首先定义一个上下文类Context,可以传入用户角色,然后定义一个上下文感知的 Prompt 函数动态修改系统提示词,并由**@dynamic_prompt**修饰作为中间件,最后定义agent对象并进行调用。
最终输出部分文本如下所示:
根据您的身份,您拥有**管理员权限**,
可以使用以下系统级工具...
04 持久上下文
与单次调用的“瞬态”不同,**持久上下文(Persistent Context)**的目标是永久改变 Agent 的认知或记忆,使其具备连续性和学习能力。
这主要通过以下两种机制实现:
1、工具回写 (Tool Writes)
工具不仅仅是执行动作,它还是更新状态的桥梁。工具可以通过返回特殊的 Command 对象,将结构化结果(如“用户手机号已验证”)回写到 State 中,或者将用户偏好存入 Store。
2、生命周期管理 (Life-cycle Management)
发生在模型与工具调用之间的自动化维护逻辑。
最典型的应用是自动总结(Summarization):当对话历史过长时,系统自动调用轻量级模型生成摘要,并永久性地在 State 中替换掉原始的陈旧消息,防止 Token 溢出并降低成本。
一个示例片段:使用内建中间件实现自动总结
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
# 初始化 Agent
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
# 注册总结中间件
SummarizationMiddleware(
# 使用廉价模型进行总结
model="gpt-4o-mini",
# 触发阈值:当历史记录超过 4000 token
trigger={"tokens": 4000},
# 策略:总结旧消息,但保留最近 20 条原文
keep={"messages": 20}
),
],
)
05 避坑指南
在构建生产级上下文管道时,可以参考官方经验指南:
**1、**先静态,后动态:不要一上来就设计复杂的动态路由。先用固定的 System Prompt 跑通业务闭环,再逐步增加上下文逻辑。
2、****分清“阅后即焚”与“永久铭刻”:仅影响本轮调用的逻辑(如权限校验提示)放在瞬态上下文;需要未来都“记得”的信息(如用户昵称)必须写入持久状态。
**3、**标准化内容格式:充分利用 LangChain 标准的 content\_blocks 消息格式,这能确保你的 Agent 在切换不同模型(如从 GPT-4 切换到 DeepSeek)时,多模态内容和工具调用依然稳定。
**4、**善用内建中间件:除非业务逻辑极度特殊,否则优先选择 SummarizationMiddleware 等经过社区验证的成熟方案,避免重复造轮子。
5、监控与度量:上下文工程直接关联成本。务必追踪每次调用的 Token 消耗和延迟,防止因为 Prompt 注入过多导致上下文过载。
06 总结
上下文工程不再是简单的“拼凑字符串”,它是对 Agent 数据流动的精细化治理。
在 LangChain V1.0+ 的体系下,通过清晰划分数据来源,并灵活组合瞬态与持久两种处理模式,我们才能构建出既“聪明”又“稳重”的智能体。
当下基础模型已经很强了,工程化的过程中,不再纠结于基础模型的微小差异,而是把精力放在构建更稳定、可靠的上下文环境上。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)