大模型技术栈全解析:10个核心概念,让你的AI产品不再瞎指挥
本文详细介绍了AI产品开发必须掌握的10个核心概念:RAG检索增强生成、Agent智能体、函数调用、思维链、向量数据库、量化、蒸馏、LoRA低秩适配、剪枝和推理加速技术。每个概念都从定义、实现方法和应用注意事项进行解析,帮助产品经理和程序员理解AI产品开发基础,避免"瞎指挥"。文章还提供了原型库和PRD模板作为学习资源。
本文详细介绍了AI产品开发必须掌握的10个核心概念:RAG检索增强生成、Agent智能体、函数调用、思维链、向量数据库、量化、蒸馏、LoRA低秩适配、剪枝和推理加速技术。每个概念都从定义、实现方法和应用注意事项进行解析,帮助产品经理和程序员理解AI产品开发基础,避免"瞎指挥"。文章还提供了原型库和PRD模板作为学习资源。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
产品经理的市场变了,超级多视线关注在AI方向,但我发现很多人分不清最基础的RAG和Agent的区别,更别提什么量化、蒸馏这些模型优化技术了。
说实话,不懂这些,做AI产品就是瞎指挥。
这篇文章,我把10个核心概念掰开了揉碎了讲。每个概念都会告诉你:是什么、怎么跑、落地时候要注意啥。
RAG全称是Retrieval-Augmented Generation,检索增强生成。
很多人问,大模型不是什么都知道吗?为啥还要检索?
停一下。大模型确实见多识广,但有两个致命硬伤。
第一,知识有截止日期。GPT-4的训练数据到2023年4月,你问它2024年的事,它只能瞎编。第二,私有知识它压根不知道。你公司的内部文档、产品手册、客户数据,这些从来没喂给过模型。
RAG的核心思路是:先搜、再问、后答。
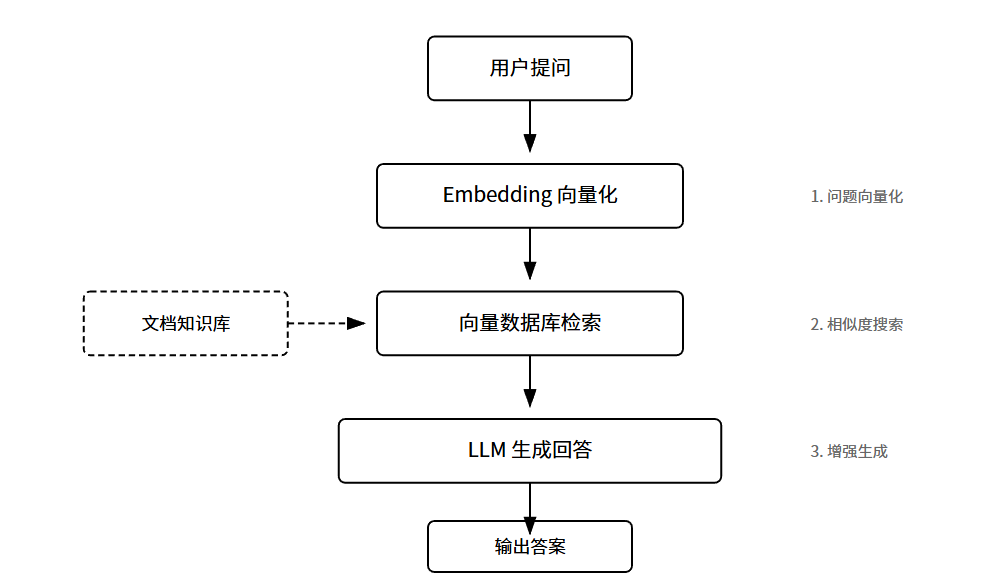
具体怎么跑?分三步。
第一步,建索引。把你的文档切成小块,每块大概几百字。然后用Embedding模型把文字变成向量,存进向量数据库。这一步是离线做的,提前准备好。
第二步,检索。用户提问的时候,先把问题也变成向量,然后去向量库里找最相似的几个文档块。相似度怎么算?通常用余弦相似度。找到的这几块文档,就是外部知识。
第三步,生成。把用户问题和检索到的文档拼在一起,丢给大模型。模型基于真实材料生成答案,而不是凭空瞎编。
这套机制解决了两个大问题。一是时效性。企业可以实时更新知识库,不用重新训练模型。二是可控性。答案有据可查,出了问题能追溯到源文档。
但RAG不是万能的。检索质量直接决定回答质量。如果检索出来的文档不相关,模型再强也没用。
Agent这个词用得太滥了。很多人把能对话的AI都叫Agent,这完全搞错了。
Agent的核心特征是:自主决策、工具调用、任务分解。
说白了,普通聊天机器人是「你问什么我答什么」,Agent是「你给个目标,我自己想办法搞定」。
传统大模型是个超级大脑,但没有手脚。你让它查天气,它只能告诉你「我没法上网」。Agent给这个大脑装上了手脚,让它能调用外部工具:搜索引擎、数据库、API、甚至控制浏览器。
Agent的运行逻辑是一个循环:感知 -> 思考 -> 行动 -> 观察结果 -> 再思考。
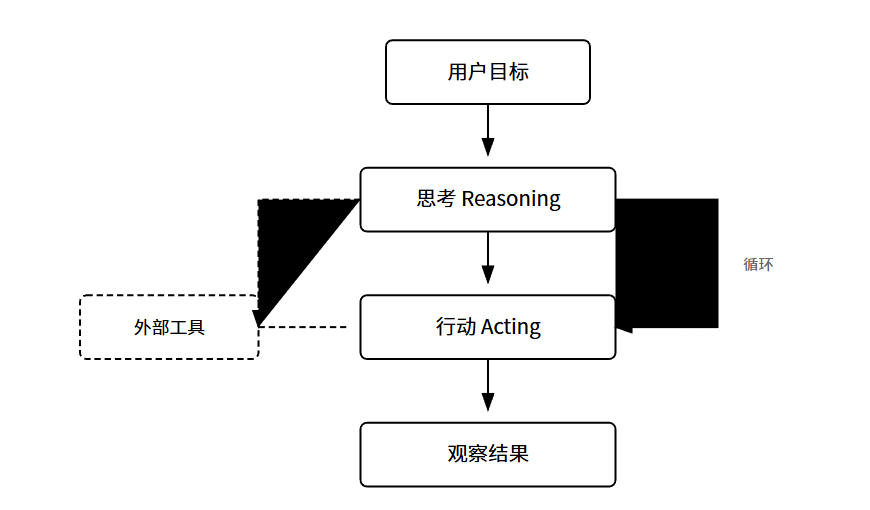
这里面有个关键概念叫ReAct框架,全称是Reasoning + Acting。核心思想是让模型在采取行动之前先想一想,把思考过程也说出来。
Agent的难点在哪?规划能力。复杂任务需要拆成很多步,模型容易迷失方向。错误恢复。某一步失败了,怎么优雅地回退或换个方案?成本控制。每次思考和行动都要调用模型,Token成本蹭蹭涨。
Function Calling是Agent的基础能力之一,但很多人分不清两者的关系。
简单说,Function Calling是「一次调用一个工具」,Agent是「自主规划调用多个工具完成任务」。
Function Calling解决的是:让模型能够以结构化的方式调用外部函数。
现在的Function Calling是模型原生支持的能力。你先告诉模型有哪些函数可以用,每个函数的参数是什么。模型理解用户意图后,直接输出JSON格式的函数调用请求。
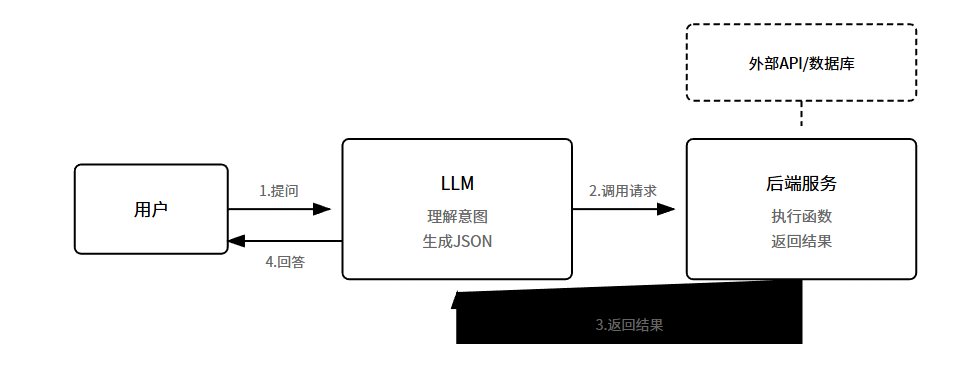
流程是这样的。第一步,定义函数Schema。第二步,用户提问。第三步,模型决策输出JSON。第四步,后端执行函数。第五步,结果回传给模型生成自然语言回复。
重点来了。模型并不真的执行函数,它只是生成调用请求。真正执行的是你的后端代码。
CoT全称Chain of Thought,思维链。这个概念2022年谷歌提出的,直接让大模型的推理能力上了一个台阶。
核心思想极其简单:让模型把思考过程说出来。
以前问模型数学题,模型直接蹦答案。用CoT:让模型一步步说推理过程。
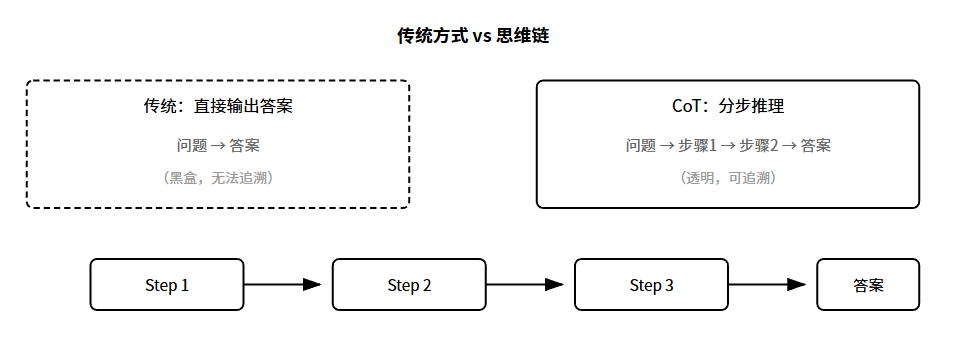
看起来只是多写几个字?不,这背后有深刻的道理。大模型本质上是预测下一个Token。当它直接预测答案时,相当于用一步完成整个推理。问题一复杂就容易出错。但如果让它分步推理,每一步都是简单预测,累计起来就能解决复杂问题。
实际使用的时候,有几种触发方式。Few-shot示例,在Prompt里给几个带推理过程的例子。直接指令,加一句「请一步步思考」。
向量数据库是RAG的底座,也是语义搜索的核心组件。
传统数据库存的是结构化数据,查询靠SQL。向量数据库存的是向量,查询靠相似度计算。
什么是向量?就是一串数字。比如[0.1, -0.3, 0.8, …]这种。Embedding模型能把任何东西变成向量:文字、图片、音频都行。
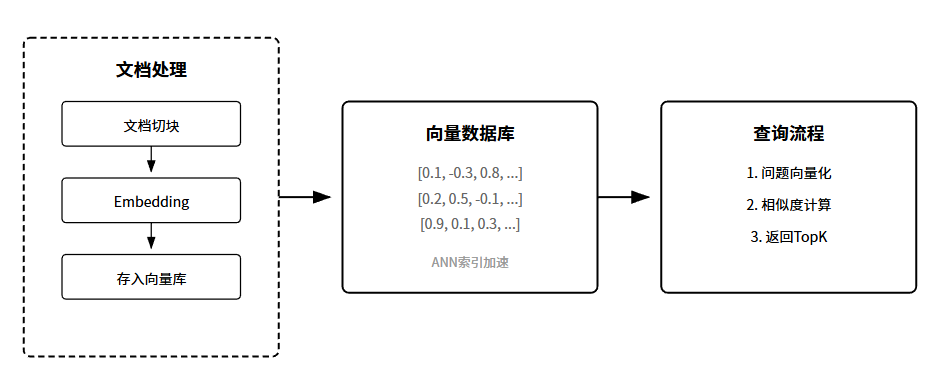
关键在于,语义相近的东西,向量也相近。
这就是向量数据库牛的地方:它做的是语义搜索,不是关键词匹配。
向量数据库的核心挑战是:快。你存了1亿条向量,用户一提问就要在这1亿里找最相似的Top10。所以向量数据库都会建ANN索引,用一些巧妙的数据结构,牺牲一点点精度换取百倍千倍的速度。
量化是模型压缩的核心技术之一。核心思路极其简单:降低数字的精度。
大模型的参数存储用的是浮点数。常见的是FP16,也就是16位浮点数。一个参数占2字节。7B模型有70亿参数,光存参数就要14GB显存。
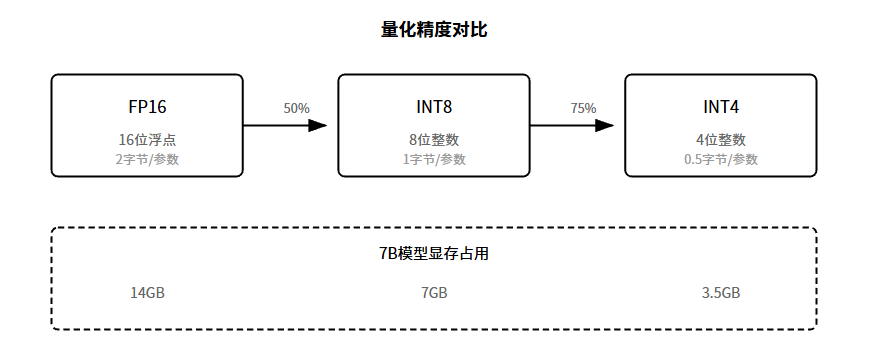
量化做的事是:把FP16降到INT8甚至INT4。INT8是8位整数,一个参数只占1字节,显存直接砍半。INT4更狠,4位整数,0.5字节,显存砍到四分之一。
精度降了,性能会不会崩?这就是量化技术的精髓:用各种技巧把精度损失降到最低。
量化分两大类。训练后量化PTQ,模型训练好之后直接转换精度。量化感知训练QAT,在训练过程中就模拟量化的影响。
蒸馏是模型压缩的另一个大方向。核心思路:用大模型教小模型。
大模型参数多,效果好,但跑起来慢、成本高。小模型参数少,快是快了,但效果差。蒸馏的目标是:训练一个小模型,让它达到大模型的效果。
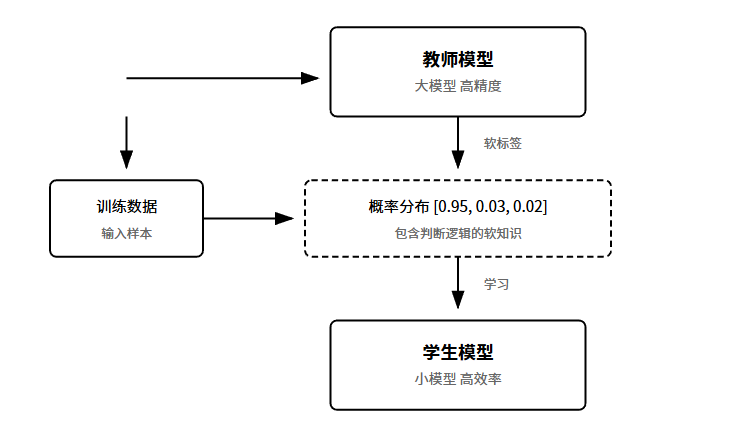
怎么做?传统的训练方式用硬标签Hard Label,图片是猫标签是1。蒸馏用的是软标签Soft Label,看大模型输出的概率分布。
比如大模型看一张图,输出:猫95%、狗3%、其它2%。这个概率分布本身就包含了丰富的信息。小模型学的不只是答案,还有大模型的判断逻辑。
这里有个关键参数叫温度T。T越大输出越平滑,能放大不同选项之间的差异,让小模型学到更细腻的知识。
LoRA全称Low-Rank Adaptation,低秩适配。这是目前最火的高效微调方法,没有之一。
问题背景是什么?大模型参数太多了。7B模型有70亿参数,全量微调要更新所有参数,显存根本扛不住。
LoRA的核心思想:不改原始参数,加一个小旁路。
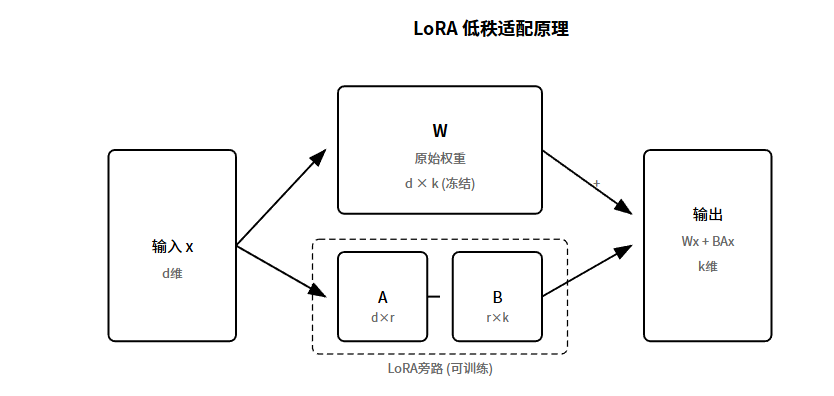
原始模型的权重矩阵是W,维度是d×k。微调时不动W,旁边加两个小矩阵A和B。A的维度是d×r,B的维度是r×k。r叫做秩,通常设成8、16、32这种小数字。
全量微调要更新d×k个参数。LoRA只更新d×r + r×k个参数。如果r远小于d和k,参数量能降几十甚至上百倍。
为什么低秩能work?研究发现,微调时模型的变化主要集中在一个低维子空间里。
剪枝是最直观的模型压缩方法:把不重要的参数直接删掉。
核心假设:神经网络里有大量冗余参数。这个假设是有道理的。训练时为了学到更多模式,参数会过量。训练完之后很多参数的值接近0,删了也不影响效果。
剪枝分两大类。非结构化剪枝,逐个参数判断重不重要,不重要的置零。问题是硬件不擅长处理稀疏矩阵。结构化剪枝,整行整列整层地删,对硬件友好。
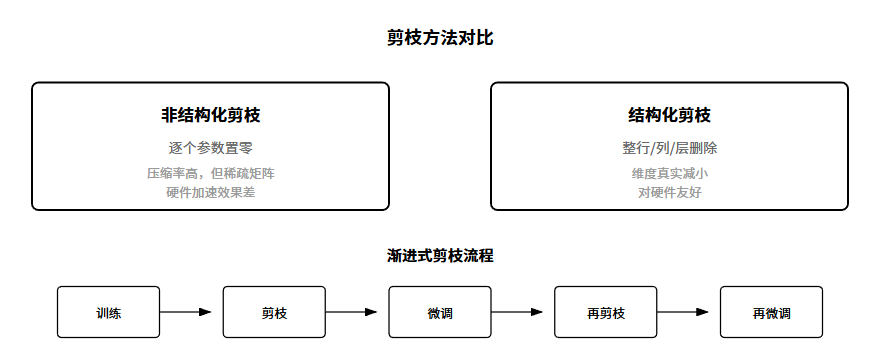
怎么判断参数重不重要?最简单的:看绝对值大小。值越接近0越不重要。进阶一点:看敏感度。
剪枝通常不是一次性完成的。常见流程:训练 -> 剪枝 -> 微调 -> 再剪枝 -> 再微调。
推理加速是工程侧的核心议题。模型再强,跑不快就没法上线。
加速手段可以分几个层面。
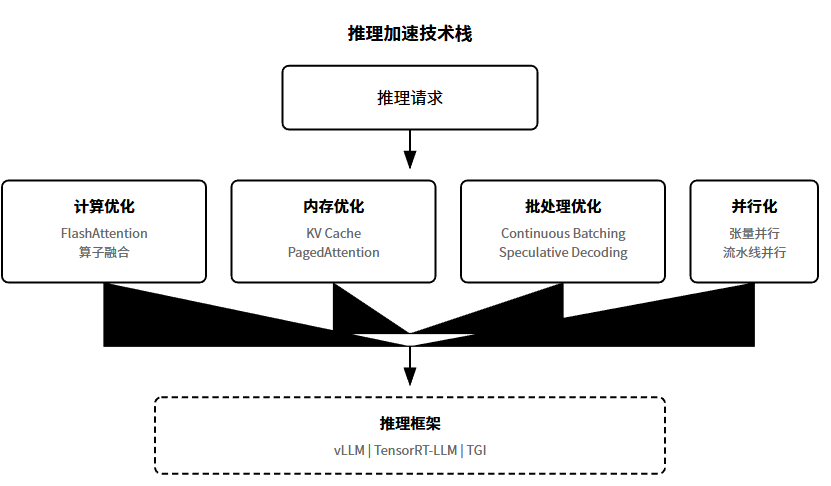
计算优化:FlashAttention重新设计注意力计算的内存访问模式,大幅减少显存读写,速度能快2-4倍。算子融合把多个小操作合成一个大操作。
内存****优化:KV Cache缓存历史Token的Key和Value复用。PagedAttention像操作系统管理内存一样管理KV Cache,避免碎片化。
批处理****优化:Continuous Batching允许动态加入新请求、移出已完成的请求。Speculative Decoding用小模型先快速生成草稿,大模型负责验证。
并行****化:张量并行把大矩阵切分到多张GPU。流水线并行把不同层放到不同GPU。
写在最后
这10个概念,覆盖了AI应用落地的核心技术栈。
懂技术原理不是为了炫技,是为了在落地时做对选择。技术服务于业务,永远不要本末倒置。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)