基于python与PyQt5对本地部署Qwen3-ASR的7B模型语音转文本
本文介绍了一个基于PyQt5的本地化AI智能助手工具,集成了Qwen3-ASR语音识别和Ollama大语言模型。该应用采用多线程架构实现语音转文字、本地模型调用和结果展示功能,主要特点包括:1)支持多种音频格式和多语言识别;2)可连接本地Ollama服务进行文本处理;3)提供直观的GUI界面操作;4)完全本地运行确保数据隐私。系统具备设备自适应、流式响应和错误处理等关键技术特性,适用于会议记录、多
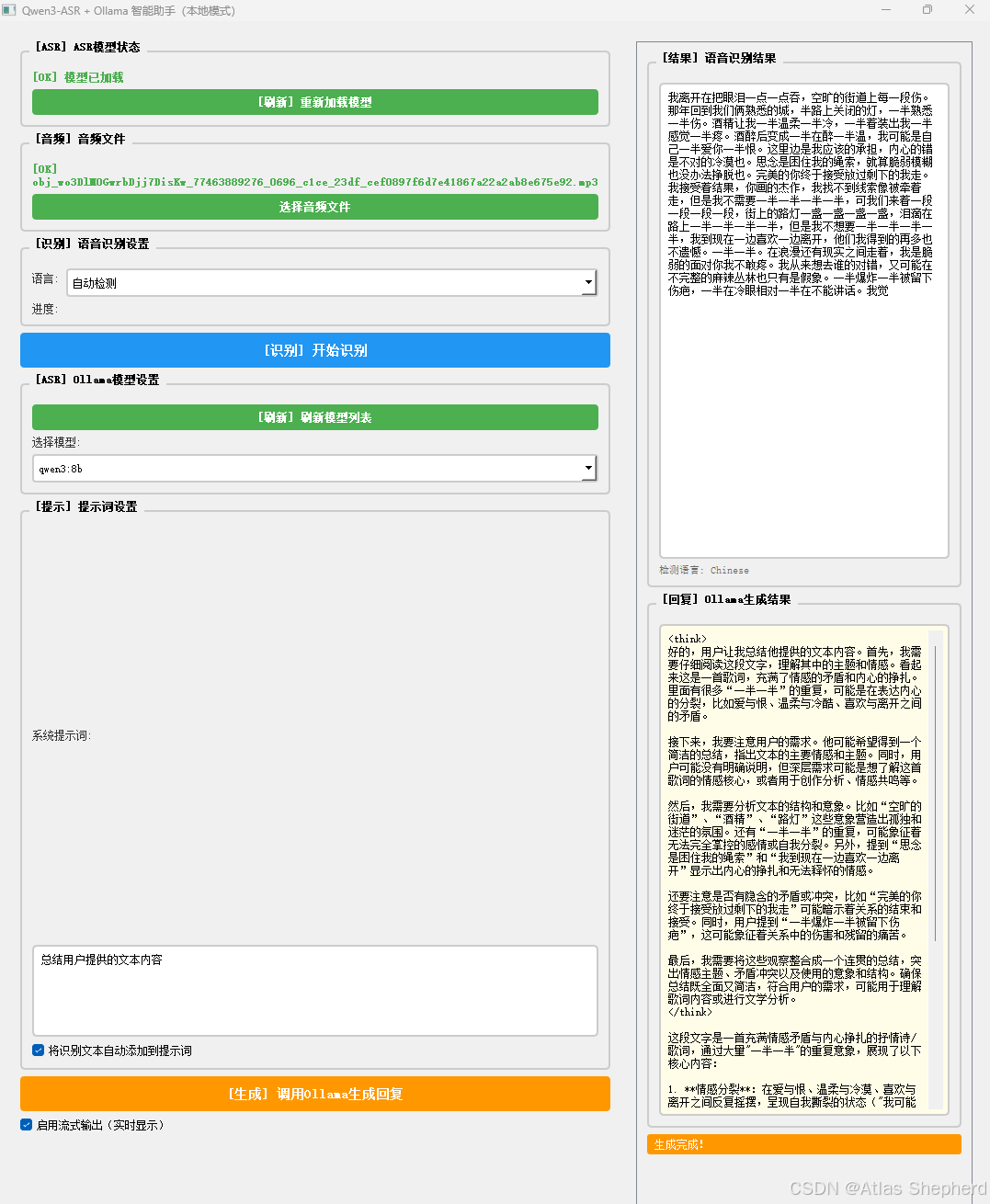
基于PyQt5的桌面应用程序,结合了Qwen3-ASR语音识别和Ollama本地大语言模型的智能助手工具。
概述
这个应用是一个本地化AI助手工具,主要功能包括:
-
音频文件识别(语音转文字)
-
将识别文本发送给本地运行的Ollama模型进行智能处理
-
在GUI界面中展示结果
核心架构
1. 多线程设计
应用采用工作线程模型,避免长时间操作阻塞UI:
-
ASRWorker: 处理语音识别
-
OllamaWorker: 调用Ollama API生成回复
-
FetchModelsWorker: 获取Ollama模型列表
-
LoadModelWorker: 加载Qwen3-ASR模型
2. 核心功能模块
语音识别模块
-
使用Qwen3-ASR模型进行本地语音识别
-
支持多种音频格式(wav, mp3, ogg, flac, m4a, aac)
-
支持多语言识别(中文、英语、粤语、日语、韩语、法语、德语、西班牙语)
-
自动检测音频采样率并适配
Ollama集成模块
-
连接到本地Ollama服务(默认端口11434)
-
支持流式输出(实时显示生成内容)
-
可加载本地已安装的Ollama模型列表
-
支持自定义系统提示词
3. GUI界面布局
左侧控制面板:
-
模型状态区:显示Qwen3-ASR加载状态
-
音频文件区:选择和管理音频文件
-
识别设置区:选择识别语言
-
Ollama设置区:刷新和选择模型
-
提示词区:设置系统提示词
-
控制按钮:开始识别、生成回复
右侧结果面板:
-
识别结果区:显示转写的文本
-
生成结果区:显示Ollama的回复
-
状态栏:显示当前操作状态
4. 关键技术特性
设备自适应
# 自动选择设备(CPU/GPU)
device_map = "cuda:0" if torch.cuda.is_available() else "cpu"
# 自动选择精度
dtype = "float32" if not torch.cuda.is_available() else "float16"流式响应
-
启用流式输出时,实时显示Ollama的生成过程
-
提供更好的用户体验
错误处理
-
完善的异常捕获和用户提示
-
详细错误日志输出
5. 使用流程
-
启动应用 → 自动加载Qwen3-ASR模型
-
选择音频文件 → 从本地选择音频
-
选择语言 → 设置识别语言(或自动检测)
-
开始识别 → 将音频转为文字
-
选择模型 → 从本地Ollama中选择大模型
-
设置提示词 → 定义系统角色
-
生成回复 → 将识别文本发送给模型处理
-
查看结果 → 在右侧面板查看AI回复
6. 依赖要求
核心依赖:
-
PyQt5: GUI框架
-
torch: 深度学习框架
-
qwen-asr: 语音识别模型
-
soundfile: 音频处理
-
requests: HTTP请求
硬件要求:
-
足够的内存加载Qwen3-ASR模型
-
GPU(可选,用于加速识别)
-
已安装并运行Ollama服务
7. 优势和特点
优势
-
完全本地化:数据不上传,保护隐私
-
一体化:语音识别+AI对话一站式完成
-
可扩展:支持多种Ollama模型
-
用户友好:直观的GUI界面
-
跨平台:基于Python和PyQt5
适用场景
-
会议录音转写和总结
-
音频内容分析
-
多语言翻译辅助
-
智能客服对话分析
-
教育学习辅助
8. 可能的改进点
-
增加实时录音功能
-
支持批量文件处理
-
添加历史记录保存
-
支持更多模型参数调整
-
添加导出功能(文本、PDF等)
9.代码
"""
测试GUI应用是否可以正常启动(本地模式)
"""
import sys
import os
# 设置Python路径
PYTHON_PATH = r"D:\python310\python.exe"
def check_dependencies():
"""检查依赖"""
print("检查依赖...")
# 检查PyQt5
try:
import PyQt5
print("✓ PyQt5 已安装")
except ImportError:
print("✗ PyQt5 未安装")
return False
# 检查requests
try:
import requests
print("✓ requests 已安装")
except ImportError:
print("✗ requests 未安装")
return False
# 检查soundfile
try:
import soundfile
print("✓ soundfile 已安装")
except ImportError:
print("✗ soundfile 未安装")
return False
# 检查torch
try:
import torch
print("✓ torch 已安装")
print(f" - 版本: {torch.__version__}")
print(f" - CUDA: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f" - GPU数量: {torch.cuda.device_count()}")
except ImportError:
print("✗ torch 未安装")
return False
# 检查qwen-asr
try:
from qwen_asr import Qwen3ASRModel
print("✓ qwen-asr 已安装")
except ImportError:
print("✗ qwen-asr 未安装")
return False
return True
def check_services():
"""检查服务状态"""
print("\n检查服务状态...")
import requests
# 检查Ollama
try:
response = requests.get("http://localhost:11434/api/tags", timeout=3)
if response.status_code == 200:
print("✓ Ollama 运行中 (http://localhost:11434)")
models = response.json().get('models', [])
if models:
print(f" - 已安装 {len(models)} 个模型:")
for m in models[:5]: # 只显示前5个
print(f" • {m['name']}")
if len(models) > 5:
print(f" ... 还有 {len(models)-5} 个模型")
else:
print(" - 未安装模型 (请运行: ollama pull llama3)")
else:
print(f"✗ Ollama 状态异常: {response.status_code}")
except:
print("✗ Ollama 未启动 (请运行: ollama serve)")
print(" - 注意: GUI会自动刷新模型列表")
def check_model_files():
"""检查模型文件"""
print("\n检查模型文件...")
from pathlib import Path
model_path = Path("Qwen/Qwen3-ASR-1.7B")
if model_path.exists():
print(f"✓ 模型目录存在: {model_path}")
files = list(model_path.glob("*.safetensors"))
if files:
print(f" - 找到 {len(files)} 个模型权重文件")
else:
print(" - 警告: 未找到.safetensors文件")
config_files = list(model_path.glob("config*.json"))
if config_files:
print(f" - 找到 {len(config_files)} 个配置文件")
else:
print(f"✗ 模型目录不存在: {model_path}")
print(" - 模型会自动从ModelScope下载")
def main():
print("=" * 50)
print("Qwen3-ASR + Ollama GUI 启动检查 (本地模式)")
print("=" * 50)
print()
# 检查依赖
if not check_dependencies():
print("\n错误: 缺少必要的依赖")
print("请运行: pip install -r gui_requirements.txt")
input("\n按回车键退出...")
sys.exit(1)
# 检查模型文件
check_model_files()
# 检查Ollama服务
check_services()
print("\n" + "=" * 50)
print("检查完成!")
print("=" * 50)
print("\n说明:")
print(" - Qwen3-ASR模型会在首次启动时自动下载")
print(" - 首次加载可能需要 10-30 分钟")
print(" - Ollama是可选的,不影响基本语音识别功能")
# 询问是否启动GUI
response = input("\n是否启动GUI应用?(y/n): ").strip().lower()
if response == 'y':
print("\n正在启动GUI应用...")
print("注意: 首次启动会自动下载和加载模型...")
try:
os.execv(PYTHON_PATH, [PYTHON_PATH, "asr_gui_app.py"])
except Exception as e:
print(f"启动失败: {e}")
import traceback
traceback.print_exc()
input("\n按回车键退出...")
else:
print("已取消启动")
if __name__ == "__main__":
main()
"""
Qwen3-ASR + Ollama GUI 应用程序
功能:音频识别 + Ollama模型调用(直接使用本地模型)
"""
import sys
import os
import json
import requests
import soundfile as sf
import io
import torch
from typing import List, Optional
from pathlib import Path
from PyQt5.QtWidgets import (
QApplication, QMainWindow, QWidget, QVBoxLayout, QHBoxLayout,
QPushButton, QLabel, QTextEdit, QComboBox, QFileDialog,
QGroupBox, QProgressBar, QSplitter, QMessageBox, QCheckBox,
QFormLayout, QScrollArea, QFrame, QSpinBox
)
from PyQt5.QtCore import Qt, QThread, pyqtSignal, QTimer
from PyQt5.QtGui import QFont, QTextCursor, QColor
# 导入Qwen3-ASR模型
from qwen_asr import Qwen3ASRModel
# ===================== 配置 =====================
MODEL_PATH = "." # 使用当前目录(模型文件已在此目录下)
OLLAMA_API_URL = "http://localhost:11434"
# ===================== 工作线程 =====================
class ASRWorker(QThread):
"""语音识别工作线程 - 直接使用本地模型"""
finished = pyqtSignal(bool, str, str) # success, text, language
progress = pyqtSignal(str) # progress message
error = pyqtSignal(str) # error message
def __init__(self, audio_path: str, model, language: Optional[str] = None):
super().__init__()
self.audio_path = audio_path
self.model = model
self.language = language
def run(self):
try:
self.progress.emit("正在读取音频文件...")
# 读取音频文件
with open(self.audio_path, 'rb') as f:
audio_bytes = f.read()
# 转换为numpy数组
audio, sr = sf.read(io.BytesIO(audio_bytes))
self.progress.emit("正在初始化模型...")
# 确保模型已加载
if self.model is None:
self.error.emit("模型未初始化")
return
self.progress.emit(f"正在识别语音(语言: {self.language or '自动检测'})...")
# 调用ASR模型
results = self.model.transcribe(
audio=(audio, sr),
language=self.language
)
if results and len(results) > 0:
result = results[0]
text = result.text
language = result.language
self.finished.emit(True, text, language)
else:
self.error.emit("未返回识别结果")
except Exception as e:
import traceback
error_details = traceback.format_exc()
print(f"ASR错误详情:\n{error_details}")
self.error.emit(f"处理失败: {str(e)}")
class OllamaWorker(QThread):
"""Ollama模型调用工作线程"""
finished = pyqtSignal(str) # response text
error = pyqtSignal(str) # error message
streaming = pyqtSignal(str) # streaming text
def __init__(self, model: str, prompt: str, api_url: str, enable_streaming: bool = False):
super().__init__()
self.model = model
self.prompt = prompt
self.api_url = api_url
self.enable_streaming = enable_streaming
def run(self):
try:
# 调用Ollama API
if self.enable_streaming:
# 流式输出
response = requests.post(
f"{self.api_url}/api/generate",
json={
"model": self.model,
"prompt": self.prompt,
"stream": True
},
stream=True,
timeout=300
)
for line in response.iter_lines():
if line:
try:
data = json.loads(line)
if 'response' in data:
self.streaming.emit(data['response'])
except json.JSONDecodeError:
continue
self.finished.emit("")
else:
# 普通输出
response = requests.post(
f"{self.api_url}/api/generate",
json={
"model": self.model,
"prompt": self.prompt,
"stream": False
},
timeout=300
)
if response.status_code == 200:
result = response.json()
self.finished.emit(result.get('response', ''))
else:
self.error.emit(f"Ollama错误: HTTP {response.status_code}")
except Exception as e:
self.error.emit(f"调用失败: {str(e)}")
class FetchModelsWorker(QThread):
"""获取Ollama模型列表的线程"""
finished = pyqtSignal(list) # models list
error = pyqtSignal(str) # error message
def __init__(self, api_url: str):
super().__init__()
self.api_url = api_url
def run(self):
try:
response = requests.get(f"{self.api_url}/api/tags", timeout=10)
if response.status_code == 200:
result = response.json()
models = [m['name'] for m in result.get('models', [])]
self.finished.emit(models)
else:
self.error.emit(f"获取模型列表失败: HTTP {response.status_code}")
except Exception as e:
self.error.emit(f"连接失败: {str(e)}")
class LoadModelWorker(QThread):
"""加载Qwen3-ASR模型的线程"""
finished = pyqtSignal(object) # model object
error = pyqtSignal(str) # error message
progress = pyqtSignal(str) # progress message
def __init__(self, model_path: str, device_map: str, dtype: str):
super().__init__()
self.model_path = model_path
self.device_map = device_map
self.dtype = dtype
def run(self):
try:
self.progress.emit("正在加载Qwen3-ASR模型...")
self.progress.emit("这可能需要几分钟时间,请耐心等待...")
# 加载模型
# CPU使用float32,GPU使用float16
dtype_map = {
'float16': torch.float16,
'bfloat16': torch.bfloat16,
'float32': torch.float32
}
dtype = dtype_map.get(self.dtype, torch.float32)
model = Qwen3ASRModel.from_pretrained(
self.model_path,
dtype=dtype,
device_map=self.device_map,
max_inference_batch_size=32,
max_new_tokens=256,
)
self.progress.emit("模型加载完成!")
self.finished.emit(model)
except Exception as e:
import traceback
error_details = traceback.format_exc()
print(f"模型加载错误详情:\n{error_details}")
self.error.emit(f"模型加载失败: {str(e)}")
# ===================== 主窗口 =====================
class ASROllamaApp(QMainWindow):
def __init__(self):
super().__init__()
self.current_audio_path = None
self.asr_model = None
self.asr_worker = None
self.ollama_worker = None
self.fetch_models_worker = None
self.load_model_worker = None
self.ollama_api_url = OLLAMA_API_URL
self.init_ui()
self.load_asr_model()
def init_ui(self):
"""初始化UI界面"""
self.setWindowTitle("Qwen3-ASR + Ollama 智能助手(本地模式)")
self.setGeometry(100, 100, 1200, 800)
# 主布局
main_widget = QWidget()
self.setCentralWidget(main_widget)
main_layout = QHBoxLayout(main_widget)
# 使用分割器
splitter = QSplitter(Qt.Horizontal)
main_layout.addWidget(splitter)
# 左侧面板
left_panel = self.create_left_panel()
splitter.addWidget(left_panel)
# 右侧面板
right_panel = self.create_right_panel()
splitter.addWidget(right_panel)
# 设置分割器比例
splitter.setStretchFactor(0, 1)
splitter.setStretchFactor(1, 2)
# 设置样式
self.setStyleSheet("""
QMainWindow {
background-color: #f0f0f0;
}
QGroupBox {
font-weight: bold;
border: 2px solid #cccccc;
border-radius: 5px;
margin-top: 10px;
padding-top: 10px;
}
QGroupBox::title {
subcontrol-origin: margin;
left: 10px;
padding: 0 3px;
}
QPushButton {
background-color: #4CAF50;
color: white;
border: none;
padding: 8px 16px;
border-radius: 4px;
font-weight: bold;
}
QPushButton:hover {
background-color: #45a049;
}
QPushButton:pressed {
background-color: #3d8b40;
}
QPushButton:disabled {
background-color: #cccccc;
}
QTextEdit {
border: 2px solid #cccccc;
border-radius: 5px;
padding: 5px;
background-color: white;
}
QComboBox {
border: 2px solid #cccccc;
border-radius: 4px;
padding: 5px;
background-color: white;
}
QLabel {
font-size: 12px;
color: #333333;
}
QProgressBar {
border: 2px solid #cccccc;
border-radius: 5px;
text-align: center;
}
QProgressBar::chunk {
background-color: #4CAF50;
}
""")
def create_left_panel(self) -> QWidget:
"""创建左侧控制面板"""
panel = QWidget()
layout = QVBoxLayout(panel)
# 1. 模型状态
model_group = QGroupBox("[ASR] ASR模型状态")
model_layout = QVBoxLayout()
self.model_status_label = QLabel("模型未加载")
self.model_status_label.setStyleSheet("color: #ff9800; font-weight: bold; font-size: 14px;")
model_layout.addWidget(self.model_status_label)
self.load_model_btn = QPushButton("[刷新] 重新加载模型")
self.load_model_btn.clicked.connect(self.load_asr_model)
model_layout.addWidget(self.load_model_btn)
model_group.setLayout(model_layout)
layout.addWidget(model_group)
# 2. 音频文件选择
audio_group = QGroupBox("[音频] 音频文件")
audio_layout = QVBoxLayout()
self.audio_path_label = QLabel("未选择文件")
self.audio_path_label.setStyleSheet("color: #666666; font-style: italic;")
self.audio_path_label.setWordWrap(True)
audio_layout.addWidget(self.audio_path_label)
select_audio_btn = QPushButton("选择音频文件")
select_audio_btn.clicked.connect(self.select_audio_file)
audio_layout.addWidget(select_audio_btn)
audio_group.setLayout(audio_layout)
layout.addWidget(audio_group)
# 3. ASR设置
asr_group = QGroupBox("[识别] 语音识别设置")
asr_layout = QFormLayout()
self.language_combo = QComboBox()
self.language_combo.addItem("自动检测", None)
self.language_combo.addItem("中文", "Chinese")
self.language_combo.addItem("英语", "English")
self.language_combo.addItem("粤语", "Cantonese")
self.language_combo.addItem("日语", "Japanese")
self.language_combo.addItem("韩语", "Korean")
self.language_combo.addItem("法语", "French")
self.language_combo.addItem("德语", "German")
self.language_combo.addItem("西班牙语", "Spanish")
asr_layout.addRow("语言:", self.language_combo)
self.asr_progress = QProgressBar()
self.asr_progress.setVisible(False)
asr_layout.addRow("进度:", self.asr_progress)
asr_group.setLayout(asr_layout)
layout.addWidget(asr_group)
# 4. 识别按钮
recognize_btn = QPushButton("[识别] 开始识别")
recognize_btn.setStyleSheet("""
QPushButton {
background-color: #2196F3;
color: white;
font-size: 14px;
padding: 12px;
}
QPushButton:hover {
background-color: #1976D2;
}
QPushButton:disabled {
background-color: #cccccc;
}
""")
recognize_btn.clicked.connect(self.start_asr)
recognize_btn.setEnabled(False) # 模型未加载时禁用
self.recognize_btn = recognize_btn
layout.addWidget(recognize_btn)
# 5. Ollama模型选择
ollama_group = QGroupBox("[ASR] Ollama模型设置")
ollama_layout = QVBoxLayout()
self.refresh_models_btn = QPushButton("[刷新] 刷新模型列表")
self.refresh_models_btn.clicked.connect(self.refresh_models)
ollama_layout.addWidget(self.refresh_models_btn)
ollama_layout.addWidget(QLabel("选择模型:"))
self.model_combo = QComboBox()
self.model_combo.setEnabled(False)
ollama_layout.addWidget(self.model_combo)
ollama_group.setLayout(ollama_layout)
layout.addWidget(ollama_group)
# 6. 提示词设置
prompt_group = QGroupBox("[提示] 提示词设置")
prompt_layout = QVBoxLayout()
prompt_layout.addWidget(QLabel("系统提示词:"))
self.system_prompt = QTextEdit()
self.system_prompt.setPlaceholderText("输入系统提示词...")
self.system_prompt.setMaximumHeight(100)
self.system_prompt.setText("你是一个专业的文本处理助手。请根据用户提供的文本内容,提供准确、有用的回复。")
prompt_layout.addWidget(self.system_prompt)
self.use_recognized_text = QCheckBox("将识别文本自动添加到提示词")
self.use_recognized_text.setChecked(True)
prompt_layout.addWidget(self.use_recognized_text)
prompt_group.setLayout(prompt_layout)
layout.addWidget(prompt_group)
# 7. 生成按钮
generate_btn = QPushButton("[生成] 调用Ollama生成回复")
generate_btn.setStyleSheet("""
QPushButton {
background-color: #FF9800;
color: white;
font-size: 14px;
padding: 12px;
}
QPushButton:hover {
background-color: #F57C00;
}
""")
generate_btn.clicked.connect(self.call_ollama)
layout.addWidget(generate_btn)
# 8. 流式输出选项
self.streaming_checkbox = QCheckBox("启用流式输出(实时显示)")
self.streaming_checkbox.setChecked(True)
layout.addWidget(self.streaming_checkbox)
layout.addStretch()
return panel
def create_right_panel(self) -> QWidget:
"""创建右侧结果面板"""
panel = QWidget()
layout = QVBoxLayout(panel)
# 创建滚动区域
scroll = QScrollArea()
scroll.setWidgetResizable(True)
scroll_content = QWidget()
scroll_layout = QVBoxLayout(scroll_content)
# 1. 识别结果
asr_result_group = QGroupBox("[结果] 语音识别结果")
asr_result_layout = QVBoxLayout()
self.asr_result_text = QTextEdit()
self.asr_result_text.setPlaceholderText("识别结果将显示在这里...")
self.asr_result_text.setReadOnly(True)
asr_result_layout.addWidget(self.asr_result_text)
self.detected_language_label = QLabel()
self.detected_language_label.setStyleSheet("color: #666666; font-size: 11px;")
asr_result_layout.addWidget(self.detected_language_label)
asr_result_group.setLayout(asr_result_layout)
scroll_layout.addWidget(asr_result_group)
# 2. Ollama生成结果
ollama_result_group = QGroupBox("[回复] Ollama生成结果")
ollama_result_layout = QVBoxLayout()
self.ollama_result_text = QTextEdit()
self.ollama_result_text.setPlaceholderText("Ollama的回复将显示在这里...")
self.ollama_result_text.setReadOnly(True)
self.ollama_result_text.setStyleSheet("""
QTextEdit {
background-color: #fffde7;
}
""")
ollama_result_layout.addWidget(self.ollama_result_text)
ollama_result_group.setLayout(ollama_result_layout)
scroll_layout.addWidget(ollama_result_group)
# 添加状态栏
self.status_label = QLabel("正在加载模型...")
self.status_label.setStyleSheet("""
QLabel {
background-color: #ff9800;
color: white;
padding: 5px;
border-radius: 3px;
}
""")
scroll_layout.addWidget(self.status_label)
scroll_layout.addStretch()
scroll.setWidget(scroll_content)
layout.addWidget(scroll)
return panel
def load_asr_model(self):
"""加载Qwen3-ASR模型"""
# 禁用相关按钮
self.load_model_btn.setEnabled(False)
self.recognize_btn.setEnabled(False)
self.model_status_label.setText("正在加载模型...")
self.model_status_label.setStyleSheet("color: #ff9800; font-weight: bold;")
# 确定设备和数据类型
device_map = "cuda:0" if torch.cuda.is_available() else "cpu"
# CPU使用float32,GPU使用float16
dtype = "float32" if not torch.cuda.is_available() else "float16"
# 创建加载线程
self.load_model_worker = LoadModelWorker(
MODEL_PATH,
device_map,
dtype
)
self.load_model_worker.progress.connect(self.on_model_progress)
self.load_model_worker.finished.connect(self.on_model_loaded)
self.load_model_worker.error.connect(self.on_model_error)
self.load_model_worker.start()
def on_model_progress(self, message: str):
"""模型加载进度"""
self.model_status_label.setText(message)
self.status_label.setText(message)
def on_model_loaded(self, model):
"""模型加载完成"""
self.asr_model = model
self.load_model_btn.setEnabled(True)
self.recognize_btn.setEnabled(True)
self.model_status_label.setText("[OK] 模型已加载")
self.model_status_label.setStyleSheet("color: #4CAF50; font-weight: bold;")
self.update_status("模型加载完成!")
print("Qwen3-ASR模型加载成功")
def on_model_error(self, error_msg: str):
"""模型加载错误"""
self.load_model_btn.setEnabled(True)
self.recognize_btn.setEnabled(False)
self.model_status_label.setText("[X] 模型加载失败")
self.model_status_label.setStyleSheet("color: #f44336; font-weight: bold;")
self.status_label.setStyleSheet("""
QLabel {
background-color: #f44336;
color: white;
padding: 5px;
border-radius: 3px;
}
""")
self.update_status("模型加载失败")
QMessageBox.critical(self, "模型加载失败", f"无法加载Qwen3-ASR模型:\n\n{error_msg}\n\n请确保:\n1. 模型文件存在于正确位置\n2. 有足够的内存\n3. 已安装正确的依赖")
def select_audio_file(self):
"""选择音频文件"""
file_path, _ = QFileDialog.getOpenFileName(
self,
"选择音频文件",
"",
"音频文件 (*.wav *.mp3 *.ogg *.flac *.m4a *.aac);;所有文件 (*.*)"
)
if file_path:
self.current_audio_path = file_path
self.audio_path_label.setText(f"[OK] {os.path.basename(file_path)}")
self.audio_path_label.setStyleSheet("color: #4CAF50; font-weight: bold;")
self.update_status(f"已选择: {os.path.basename(file_path)}")
def start_asr(self):
"""开始语音识别"""
if self.asr_model is None:
QMessageBox.warning(self, "警告", "模型未加载,请先加载模型!")
return
if not self.current_audio_path:
QMessageBox.warning(self, "警告", "请先选择音频文件!")
return
# 禁用按钮
self.set_ui_enabled(False)
# 显示进度条
self.asr_progress.setVisible(True)
self.asr_progress.setRange(0, 0) # 不确定进度
# 清理旧的 worker
if self.asr_worker is not None:
if hasattr(self.asr_worker, 'deleteLater'):
self.asr_worker.deleteLater()
self.asr_worker = None
# 创建并启动工作线程
try:
language = self.language_combo.currentData()
self.asr_worker = ASRWorker(
self.current_audio_path,
self.asr_model,
language
)
# 验证 worker 对象
if not isinstance(self.asr_worker, ASRWorker):
raise TypeError(f"Failed to create ASRWorker, got {type(self.asr_worker)}")
# 连接信号
self.asr_worker.progress.connect(self.on_asr_progress)
self.asr_worker.finished.connect(self.on_asr_finished)
self.asr_worker.error.connect(self.on_asr_error)
self.asr_worker.start()
except Exception as e:
self.asr_worker = None
self.asr_progress.setVisible(False)
self.set_ui_enabled(True)
QMessageBox.critical(self, "错误", f"创建ASR工作线程失败:{str(e)}")
self.update_status("识别失败")
def on_asr_progress(self, message: str):
"""ASR进度更新"""
self.update_status(message)
def on_asr_finished(self, success: bool, text: str, language: str):
"""ASR完成"""
self.asr_progress.setVisible(False)
self.set_ui_enabled(True)
if success:
self.asr_result_text.setText(text)
self.detected_language_label.setText(f"检测语言: {language}")
self.update_status("识别完成!")
else:
self.asr_result_text.clear()
self.detected_language_label.clear()
def on_asr_error(self, error_msg: str):
"""ASR错误"""
self.asr_progress.setVisible(False)
self.set_ui_enabled(True)
QMessageBox.critical(self, "识别失败", error_msg)
self.update_status("识别失败")
def check_ollama_connection(self):
"""检查Ollama连接"""
self.update_status("正在检查Ollama连接...")
# 清理旧的 worker
if self.fetch_models_worker is not None:
if hasattr(self.fetch_models_worker, 'deleteLater'):
self.fetch_models_worker.deleteLater()
self.fetch_models_worker = None
# 创建并启动工作线程
try:
self.fetch_models_worker = FetchModelsWorker(self.ollama_api_url)
# 验证 worker 对象
if not isinstance(self.fetch_models_worker, FetchModelsWorker):
raise TypeError(f"Failed to create FetchModelsWorker, got {type(self.fetch_models_worker)}")
# 连接信号
self.fetch_models_worker.finished.connect(self.on_models_fetched)
self.fetch_models_worker.error.connect(self.on_models_error)
self.fetch_models_worker.start()
except Exception as e:
self.fetch_models_worker = None
QMessageBox.critical(self, "错误", f"创建检查连接线程失败:{str(e)}")
self.update_status("检查失败")
def refresh_models(self):
"""刷新模型列表"""
self.model_combo.clear()
self.model_combo.addItem("正在加载...", None)
self.model_combo.setEnabled(False)
# 清理旧的 worker
if self.fetch_models_worker is not None:
if hasattr(self.fetch_models_worker, 'deleteLater'):
self.fetch_models_worker.deleteLater()
self.fetch_models_worker = None
# 创建并启动工作线程
try:
self.fetch_models_worker = FetchModelsWorker(self.ollama_api_url)
# 验证 worker 对象
if not isinstance(self.fetch_models_worker, FetchModelsWorker):
raise TypeError(f"Failed to create FetchModelsWorker, got {type(self.fetch_models_worker)}")
# 连接信号
self.fetch_models_worker.finished.connect(self.on_models_fetched)
self.fetch_models_worker.error.connect(self.on_models_error)
self.fetch_models_worker.start()
self.update_status("正在刷新模型列表...")
except Exception as e:
self.fetch_models_worker = None
self.model_combo.clear()
self.model_combo.addItem("加载失败", None)
QMessageBox.critical(self, "错误", f"创建模型列表线程失败:{str(e)}")
self.update_status("加载失败")
def on_models_fetched(self, models: List[str]):
"""模型列表获取完成"""
self.model_combo.clear()
if not models:
self.model_combo.addItem("未找到模型", None)
self.update_status("未找到Ollama模型")
else:
for model in models:
self.model_combo.addItem(model, model)
self.model_combo.setEnabled(True)
self.update_status(f"已加载 {len(models)} 个模型")
def on_models_error(self, error_msg: str):
"""模型列表获取错误"""
self.model_combo.clear()
self.model_combo.addItem("连接失败", None)
self.model_combo.setEnabled(False)
self.update_status("Ollama连接失败")
QMessageBox.warning(self, "连接失败", f"无法连接到Ollama: {error_msg}\n请确保Ollama服务正在运行。")
def call_ollama(self):
"""调用Ollama生成回复"""
# 检查是否选择了模型
model_name = self.model_combo.currentData()
if model_name is None or not isinstance(model_name, str):
QMessageBox.warning(self, "警告", "请先选择Ollama模型!")
return
# 检查是否有识别文本或提示词
recognized_text = self.asr_result_text.toPlainText()
system_prompt = self.system_prompt.toPlainText()
if not recognized_text and not system_prompt:
QMessageBox.warning(self, "警告", "请先进行语音识别或输入提示词!")
return
# 构建完整提示词
if self.use_recognized_text.isChecked() and recognized_text:
full_prompt = f"识别的文本内容:\n{recognized_text}\n\n{system_prompt}"
else:
full_prompt = system_prompt
# 清空之前的输出
self.ollama_result_text.clear()
self.set_ui_enabled(False)
self.update_status("正在调用Ollama...")
# 清理旧的 worker
if self.ollama_worker is not None:
if hasattr(self.ollama_worker, 'deleteLater'):
self.ollama_worker.deleteLater()
self.ollama_worker = None
# 创建并启动工作线程
try:
self.ollama_worker = OllamaWorker(
model_name,
full_prompt,
self.ollama_api_url,
self.streaming_checkbox.isChecked()
)
# 验证 worker 对象
if not isinstance(self.ollama_worker, OllamaWorker):
raise TypeError(f"Failed to create OllamaWorker, got {type(self.ollama_worker)}")
# 连接信号
self.ollama_worker.finished.connect(self.on_ollama_finished)
self.ollama_worker.error.connect(self.on_ollama_error)
self.ollama_worker.streaming.connect(self.on_ollama_streaming)
self.ollama_worker.start()
except Exception as e:
self.ollama_worker = None
self.set_ui_enabled(True)
QMessageBox.critical(self, "错误", f"创建Ollama工作线程失败:{str(e)}")
self.update_status("调用失败")
def on_ollama_finished(self, response: str):
"""Ollama完成"""
self.set_ui_enabled(True)
self.update_status("生成完成!")
if response:
self.ollama_result_text.append(response)
def on_ollama_error(self, error_msg: str):
"""Ollama错误"""
self.set_ui_enabled(True)
QMessageBox.critical(self, "调用失败", error_msg)
self.update_status("调用失败")
def on_ollama_streaming(self, text: str):
"""Ollama流式输出"""
self.ollama_result_text.moveCursor(QTextCursor.End)
self.ollama_result_text.insertPlainText(text)
self.ollama_result_text.ensureCursorVisible()
def set_ui_enabled(self, enabled: bool):
"""设置UI可用状态"""
for child in self.findChildren(QPushButton):
child.setEnabled(enabled)
self.language_combo.setEnabled(enabled)
self.model_combo.setEnabled(enabled and self.model_combo.count() > 1)
def update_status(self, message: str):
"""更新状态栏"""
self.status_label.setText(message)
def closeEvent(self, event):
"""窗口关闭事件"""
# 等待所有线程结束
if self.asr_worker and self.asr_worker.isRunning():
self.asr_worker.terminate()
self.asr_worker.wait()
if self.ollama_worker and self.ollama_worker.isRunning():
self.ollama_worker.terminate()
self.ollama_worker.wait()
if self.fetch_models_worker and self.fetch_models_worker.isRunning():
self.fetch_models_worker.terminate()
self.fetch_models_worker.wait()
if self.load_model_worker and self.load_model_worker.isRunning():
self.load_model_worker.terminate()
self.load_model_worker.wait()
event.accept()
# ===================== 主程序入口 =====================
def main():
app = QApplication(sys.argv)
# 设置应用信息
app.setApplicationName("Qwen3-ASR + Ollama")
app.setOrganizationName("ASR-Ollama")
# 创建并显示主窗口
window = ASROllamaApp()
window.show()
sys.exit(app.exec_())
if __name__ == "__main__":
main()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)