KAG: Boosting LLMs in Professional Domains viaKnowledge Augmented Generation
药品说明书、政务文件、法律条文等专业文档,通常具备标准化的文档结构。我们可将每类文档定义为一种实体类型,文档中的不同段落则作为该实体的不同属性。以政务领域为例,可预先定义 ** 政务(GovernmentAffair)
近年来新兴的检索增强生成(RAG)技术,实现了领域专属应用的高效构建。然而,该技术同样存在局限性,例如向量相似度与知识推理关联性之间存在偏差,且对数值、时序关系、专家规则等知识逻辑不敏感,这些问题制约了专业知识服务的效果。
本文提出一种面向专业领域的知识服务框架 ——知识增强生成(KAG)。KAG 旨在解决上述难题,其核心思路是充分发挥知识图谱(KG)与向量检索的优势,通过五大核心维度实现大语言模型(LLM)与知识图谱的双向增强,进而提升生成与推理性能,具体包括:
- 适配大语言模型的知识表示方式
- 知识图谱与原始文本块的双向索引
- 基于逻辑形式引导的混合推理引擎
- 结合语义推理的知识对齐
- 面向 KAG 的模型能力强化
在多跳问答任务中,研究人员将 KAG 与现有 RAG 方法进行对比,结果显示 KAG 的性能显著优于当前最优方法:在 HotpotQA 数据集上,F1 值相对提升 19.6%;在 2Wiki 数据集上,F1 值相对提升 33.5%。
该框架已成功应用于蚂蚁集团的两大专业知识问答场景,即电子政务问答与智慧医疗问答,相比传统 RAG 方法,服务的专业性得到显著提升。此外,团队即将在开源知识图谱引擎 OpenSPG 中原生支持 KAG,帮助开发者更便捷地构建严谨的知识决策服务或高效的信息检索服务,推动 KAG 的本地化部署,助力开发者打造精度更高、效率更优的领域知识服务。
1 引言
近年来,快速发展的检索增强生成(RAG)技术 [1,2,3,4,5],通过借助外部检索系统,为大语言模型(LLM)赋予了获取领域专属知识的能力。这一方式大幅减少了答案幻觉现象,同时实现了特定领域应用的高效构建。为提升 RAG 系统在多跳、跨段落任务中的表现,具备强大推理能力的知识图谱被引入 RAG 技术框架,相关方法包括 GraphRAG [6]、DALK [7]、SUGRE [8]、ToG 2.0 [9]、GRAG [10]、GNN-RAG [11] 以及 HippoRAG [12]。
尽管 RAG 及其优化方案,解决了因缺乏领域专属知识和实时更新信息而引发的大部分幻觉问题,但生成的文本仍缺乏连贯性与逻辑性,难以给出正确且有价值的答案,在法律、医学、科学等依赖分析推理的专业领域,这一问题尤为突出。该缺陷主要源于三方面原因:其一,实际业务场景中,通常需要基于知识单元间的特定关联进行推理检索,以获取与问题相关的信息,而 RAG 普遍依托文本或向量相似度检索参考信息,易导致检索结果不完整、存在重复;其二,实际业务常涉及逻辑推理或数值推理,例如判断时序数据的增减趋势,而语言模型采用的下一个词预测机制,在处理此类问题时仍存在明显短板。
与之相对,知识图谱的技术方案能够有效应对这些问题。首先,知识图谱以显式语义组织信息,其核心知识单元为 SPO 三元组,由实体及实体间的关系构成 [13]。实体拥有明确的类型与关联关系,含义相同但表述不同的实体可通过实体归一化实现统一,从而降低知识冗余,强化知识的关联性 [14]。在检索环节,借助 SPARQL [15]、SQL [16] 等查询语法,可显式限定实体类型,减少同名或相似实体带来的噪声,还能根据查询需求指定关系,实现推理式知识检索,而非盲目拓展相似但无关的邻近内容。
同时,知识图谱的查询结果具备显式语义,可作为带有特定含义的变量,进一步发挥大语言模型的规划与函数调用能力 [17],将检索结果作为变量代入函数参数,完成数值计算、集合运算等确定性推理。
为解决上述难题,满足专业领域知识服务的需求,本文提出 ** 知识增强生成(KAG)** 框架,充分发挥知识图谱与 RAG 技术的互补优势。KAG 并非简单地将图结构融入知识库构建流程,而是将知识图谱的语义类型、关联关系,以及知识图谱问答(KGQA)领域常用的逻辑形式,整合到检索与生成环节。如图 1 所示,该框架围绕五大模块展开优化:
-
提出适配大语言模型的知识表示框架 LLMFriSPG。借鉴 DIKW 模型中数据、信息、知识的层级结构,对 SPG 进行大语言模型友好化升级,命名为 LLMFriSPG。该框架可在同一知识类型(如实体类型、事件类型)下,兼容无模式约束的信息抽取与模式约束的专家知识构建,同时支持图结构与原始文本块的双向索引表示,既便于构建基于图结构的倒排索引,也助力逻辑形式的统一表示、推理与检索。
-
提出逻辑形式引导的混合求解与推理引擎。该引擎包含规划、推理、检索三类算子,将自然语言问题转化为语言与符号相结合的求解过程。过程中的每一步均可调用精确匹配检索、文本检索、数值计算、语义推理等不同算子,实现检索、知识图谱推理、语言推理、数值计算四类求解流程的深度融合。
-
提出基于语义推理的知识对齐方法。将领域知识定义为同义、上下位、包含等各类语义关系,在知识图谱离线索引构建与在线检索两大阶段均开展语义推理,让自动化生成的碎片化知识通过领域知识实现对齐与关联。该方法在离线索引阶段,可提升知识的规范性与关联性;在在线问答阶段,能精准搭建用户问题与索引之间的桥梁。
-
构建面向 KAG 的专用模型。为支撑 KAG 框架运行所需的索引构建、检索、问题理解、语义推理、文本摘要等能力,对通用大语言模型的自然语言理解(NLU)、自然语言推理(NLI)、自然语言生成(NLG)三项核心能力进行强化,使模型在各功能模块中实现更优表现。
研究团队在 2WikiMultiHopQA [18]、MuSiQue [19]、HotpotQA [20] 三个复杂问答数据集上,对系统效果进行了评估,评估维度涵盖端到端问答性能与检索效果。实验结果表明,相较于 HippoRAG [12],KAG 在三项任务中均实现显著提升,F1 分数分别提升 19.6%、12.2%、12.5%,同时各项检索指标也有明显优化。
KAG 已在蚂蚁集团的电子政务、智慧医疗两大专业问答场景中落地应用。在电子政务场景中,基于指定的文档库,为用户解答政务办理流程相关问题;在智慧医疗场景中,依托现有医疗资源,回应疾病、症状、治疗方案等相关咨询。实际应用结果显示,KAG 的准确率远高于传统 RAG 方法,有效提升了专业领域问答应用的可信度。团队即将在开源知识图谱引擎 OpenSPG 中原生支持 KAG,帮助开发者更便捷地构建严谨的知识决策服务与高效的信息检索服务。
综上,本文提出了面向专业问答场景的知识增强技术框架 KAG,并通过复杂问答任务验证了其有效性;展示了基于蚂蚁集团业务场景的两大行业应用案例,同时开源了相关代码,助力开发者基于 KAG 搭建本地化应用。
术语补充注释
- SPO 三元组:Subject-Predicate-Object,主体 - 谓词 - 客体,是知识图谱表示知识的基础结构
- DIKW:Data-Information-Knowledge-Wisdom,数据 - 信息 - 知识 - 智慧,是描述知识层级的经典模型
- SPG:Semantic Probabilistic Graph,语义概率图,本文提及的一种知识图谱表示形式
- NLU:Natural Language Understanding,自然语言理解
- NLI:Natural Language Inference,自然语言推理
- NLG:Natural Language Generation,自然语言生成
- 2WikiMultiHopQA、MuSiQue、HotpotQA:主流的多跳复杂问答评测数据集
2 方法
本节首先介绍 KAG 的整体框架,随后将在 2.1 至 2.5 节中详细阐述五大核心增强模块。如图 1 所示,KAG 框架由三部分组成:KAG 构建器(KAG-Builder)、KAG 求解器(KAG-Solver)和KAG 模型(KAG-Model)。其中,KAG 构建器用于构建离线索引,在该模块中,我们提出了适配大语言模型的知识表示框架,以及知识结构与文本块之间的双向索引机制。在 KAG 求解器模块中,我们引入了一种由逻辑形式引导的混合推理求解器,该求解器融合了大语言模型推理、知识推理和数理逻辑推理三种能力。此外,基于语义推理的知识对齐方法被同时应用于 KAG 构建器和 KAG 求解器中,用以提升知识表示与知识检索的准确性。KAG 模型则以通用语言模型为基础,对各模块所需的核心能力进行优化,进而全面提升整个框架的性能。
2.1 适配大语言模型的知识表示
为了为大语言模型定义更友好的知识语义表示形式,我们从深度文本上下文感知、动态属性和知识分层三个维度对 SPG(语义概率图)进行升级优化,并将升级后的模型命名为LLMFriSPG。
其形式化定义如下:M={T,ρ,C,L}
其中,M 代表 LLMFriSPG 中定义的所有类型集合;T 代表所有实体类型(例如图 2 中的 “人物(Person)”)、事件类型类别,以及所有与 LPG(标签属性图)语法声明兼容的预定义属性;C 代表所有概念类型类别、概念以及概念间的关联关系,值得注意的是,每棵概念树的根节点都是一个与 LPG 语法兼容的概念类型类别(例如图 2 中的 “人物分类体系(TaxoOfPerson)”),且每个概念节点都对应唯一的概念类型类别;ρ 代表从实例到概念的归纳关联关系;L 代表所有基于逻辑关系和逻辑概念定义的可执行规则。对于任意 t∈T,满足以下条件:
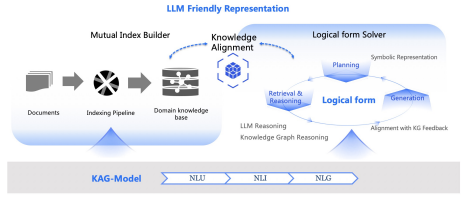
图 1:KAG 框架。左侧为 KAG 构建器(KAG-Builder),右侧为 KAG 求解器(KAG-Solver),图中底部的灰色区域代表 KAG 模型(KAG-Model)。
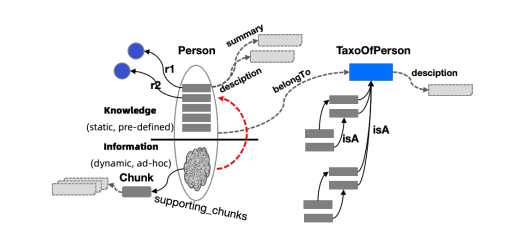
图 2:LLMFriSPG—— 面向大语言模型友好的知识表示框架。该框架将实例与概念分离,通过概念实现与大语言模型更高效的对齐。在本文中,若无特殊说明,实体实例与事件实例统称为实例。SPG 属性被划分为知识域与信息域(也称作静态域和动态域),既兼容具备强模式约束的决策专家知识,也适配开放信息表示的文档检索索引知识。红色虚线表示从信息到知识的融合与挖掘过程。增强后的文档块表示,为大语言模型提供了可溯源、可解释的文本上下文。

对于任意实例 ei,记其类型为 type of(ei)=tk。其中:
supporting_chunks代表包含该实例 ei 的所有文本块集合,用户可在 KAG 构建阶段定义文本块的生成策略及最大长度;description代表针对类型 tk 的通用描述信息。值得注意的是,附加在类型 tk 上的description与附加在实例 ei 上的description含义不同:当description绑定到 tk 时,它表示该类型的全局描述;反之,当它与实例 ei 关联时,它表示与原始文本文档上下文一致的、针对 ei 的通用描述信息。description能够有效辅助大语言模型理解特定实例或类型的精确含义,可应用于信息抽取、实体链接、摘要生成等任务;summary代表实例 ei 或关系 rj 在原始文档上下文中的摘要内容;belongTo代表从实例到概念的归纳语义关系。每种实体类型(EntityType)或事件类型(EventType)都可通过belongTo关联到一种概念类型(ConceptType)。
需要特别说明三点:
- T(实体 / 事件类型集合)与 C(概念类型集合)的功能不同。类型 t 采用面向对象的设计原则,以更好地匹配标签属性图(LPG)[21] 的表示形式;而 C 则通过基于文本的概念树进行管理。本文不对此处 SPG 的语义细节展开赘述;
- ptc(预定义属性)与 ptf(临时添加属性)可单独实例化。即二者共享相同的类声明,但在实例存储空间中,预定义的静态属性与实时添加的动态属性可以共存,同时我们也支持仅实例化其中一种属性。这种方式能够更好地平衡专业决策与信息检索两类应用场景:通用信息检索场景主要实例化动态属性,而专业决策应用场景主要实例化静态属性。用户可根据业务场景需求,在易用性与专业性之间找到平衡;
- ptc 与 ptf 共享相同的概念术语体系。概念是独立于特定文档或实例的通用常识性知识,将不同实例关联到同一个概念节点,可实现对实例的分类归类。我们能够通过概念图实现大语言模型与实例之间的语义对齐,同时概念也可作为知识检索的导航依据,具体细节将在 2.3 节与 2.4 节中展开说明。
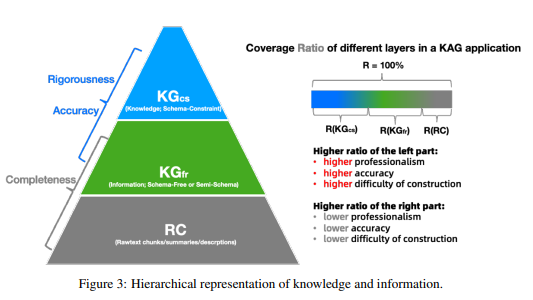
为更精准地定义信息与知识的层级化表示,如图 3 所示,我们将KGcs记为知识层,指代遵循领域模式约束、经过归纳、整合与校验的领域知识;将KGfr记为图信息层,指代通过信息抽取得到的实体、关系等图结构数据;将RC记为原始文本块层,指代经过语义切分后的原始文档块。
知识层 KGcs 完全遵循 SPG 语义规范,支持带有严格模式约束的知识构建与逻辑规则定义。SPG 要求领域知识必须具备预定义的模式约束,该层级的知识精度高、逻辑严谨,但由于高度依赖人工标注,构建的人力成本较高,且信息完备性不足。图信息层 KGfr 与 KGcs 共享相同的实体类型、事件类型和概念体系,为 KGcs 提供了有效的信息补充。同时,KGfr 与 RC 之间建立的支撑文本块、摘要、描述等关联边,构成了基于图结构的倒排索引,使得原始文本块层 RC 成为 KGfr 高效的原始文本上下文补充,具备极高的信息完备性。
如图 3 右侧部分所示,在特定领域应用中,R (KGcs)、R (KGfr)、R (RC) 分别代表三者在求解目标领域问题时的知识覆盖范围。若应用对知识精度和逻辑严谨性要求更高,则需要构建更多领域结构化知识,投入更多专家人力,以提升 R (KGcs) 的覆盖度。反之,若应用对检索效率要求更高,且对一定程度的信息缺失或错误具备容忍度,则需要提升 R (KGfr) 的覆盖度,充分发挥 KAG 的自动化知识构建能力,减少专家人力消耗。
关键术语说明
- KGcs:Knowledge Graph - Constrained Schema,约束模式知识图谱,即严谨的专家知识层
- KGfr:Knowledge Graph - Free Schema,自由模式知识图谱,即自动化抽取的图信息层
- RC:Raw Chunks,原始文本块,是最底层、信息最完整的数据源
- 模式约束(schema constraints):预先定义的知识结构规范,保证知识的结构化与严谨性
- 倒排索引(inverted index):基于图结构建立,实现从图节点到原始文本的快速回溯
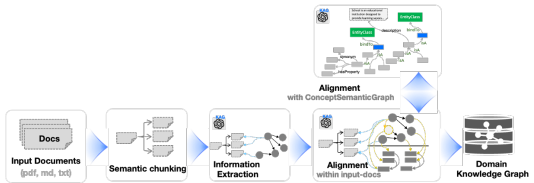 图 4:面向领域非结构化文档的 KAG 构建器流水线。从左至右,首先通过信息抽取得到短语与三元组,随后通过语义对齐完成消歧与融合,最终将构建好的知识图谱写入存储。
图 4:面向领域非结构化文档的 KAG 构建器流水线。从左至右,首先通过信息抽取得到短语与三元组,随后通过语义对齐完成消歧与融合,最终将构建好的知识图谱写入存储。
2.2 双向索引
如图 4 所示,KAG 构建器包含三个连贯的流程:结构化信息获取、知识语义对齐和图谱存储写入。该模块的核心目标包括:1)建立图结构与文本块之间的双向索引,为图结构补充更丰富的描述性上下文;2)借助概念语义图对齐不同粒度的知识,降低噪声,提升图谱的连通性。
2.2.1 语义分块
依据文档的结构层级以及段落间固有的逻辑关联,基于系统内置提示词实现语义分块。该语义分块生成的文本块,既满足长度约束(尤其适配大语言模型的上下文窗口限制),又保证语义连贯,确保每个文本块内的内容主题统一。
我们在原始文本块层(RC)中定义了块(Chunk)实体类型,包含 id、summary、mainText 等字段。经过语义切分得到的每个文本块,都会被写入一个 Chunk 实例中。其中,id 是由文章 ID(articleID)、段落编码(paraCode)、段内编号(idInPara)通过连接符 #依次拼接而成的复合字段,以此保证连续的文本块在 id 空间上也相邻。articleID 代表全局唯一的文档编号,paraCode 代表文档内的段落编码,idInPara 是该段落内每个文本块的顺序编号。由此,内容上的相邻关系对应着标识符上的顺序相邻。
此外,原始文档与其切分后的文本块之间会建立并维护一种双向关联关系,便于在不同粒度的文档内容间进行导航和上下文理解。这种结构化的切分方式,不仅优化了与大语言模型的兼容性,还保留并强化了文档本身的语义结构与关联。
2.2.2 附带丰富描述上下文的信息抽取
针对给定数据集,我们采用无需微调的大语言模型(如 GPT-3.5、DeepSeek、通义千问等)或自研的微调模型 Hum,抽取实体、事件、概念及关系,以构建图信息层(KGfr),并进一步建立 KGfr 与 RC 之间的双向索引结构,实现基于实体和关系的跨文档关联。
该过程分为三个步骤:
- 逐文本块抽取实体集合 E={e1,e2,e3,…};
- 抽取与所有实体关联的事件集合 EV={ev1,ev2,ev3,…},并迭代抽取实体集合 E 中各实体间的关系集合 R={r1,r2,r3,…};
- 完成所有实例与其 SPG 类别之间的上下位关系构建。
为给后续的知识对齐阶段提供便利,同时克服维基数据(Wikidata)、概念网络(ConceptNet)等知识库中知识短语区分度较低的问题,在实体抽取阶段,我们默认通过大语言模型为每个实例 e 一次性生成内置属性:描述(description)、摘要(summary)、语义类型(semanticType)、SPG 类别(spgClass)、语义类型描述(descriptionOfSemanticType)。如图 2 所示,我们按照e.description、e.summary、<e, belongTo, semanticType>以及<e, hasClass, spgClass>的结构,将这些信息存储在实例 e 的存储空间中。
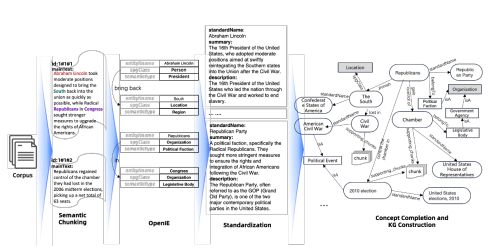
Figure 5: An Example of KAG-Builder pipeline
2.2.3 领域知识注入与约束
将开放信息抽取(openIE)应用于专业领域时,会引入无关噪声。已有研究 [3,5,24] 表明,含噪声、无关的语料会显著降低大语言模型的性能,而实现抽取信息与领域知识的粒度对齐也成为一大难点。KAG 具备的领域知识对齐能力主要包含三方面:
-
领域术语与概念注入本文采用迭代抽取的方法完成该过程:首先,将附带描述信息的领域概念与术语存入知识图谱存储系统;其次,通过开放信息抽取提取文档中的所有实例,再通过向量检索得到所有匹配的潜在概念与术语集合Ed;最后,将Ed加入抽取提示词中再次执行抽取,得到与领域知识高度对齐的实例集合Eda。
-
模式约束下的信息抽取在垂直专业领域中,各类数据源(如药品说明书、体检报告、政务文档、线上订单数据、结构化数据表等)内的多份文档,其数据结构具备高度一致性,更适合采用模式约束下的信息抽取方式。结构化的抽取结果也更便于开展知识管理与质量优化工作。关于基于模式约束的知识构建细节,可参考 SPG 技术文档及 OneKE [25] 相关研究,本文不再展开赘述。值得注意的是,如图 2 所示,针对同一实体类型(如人物(Person)),我们既可以预先定义姓名、性别、出生地等属性,以及(人物,有父亲,人物)、(人物,有朋友,人物)等关联关系;也可以通过开放信息抽取直接提取三元组,例如(周杰伦,SPG 类别,人物)、(周杰伦,星座,摩羯座)、(周杰伦,唱片公司,环球音乐集团)。
-
按文档类型预定义知识结构药品说明书、政务文件、法律条文等专业文档,通常具备标准化的文档结构。我们可将每类文档定义为一种实体类型,文档中的不同段落则作为该实体的不同属性。以政务领域为例,可预先定义 ** 政务(GovernmentAffair)实体类型,并为其设置行政区划、办理流程、所需材料、办理地点、适用人群等属性,切分后的文本块即为各属性对应的取值。当用户提出 “西湖区申请住房公积金需要准备哪些材料?” 这类问题时,可直接提取所需材料(required materials)** 属性对应的文本块进行解答。
2.2.4 文本块向量与知识结构的双向索引
KAG 的双向索引是一套符合 LLMFriSPG 语义表示规范的知识管理与存储机制。如 2.1 节所述,该机制包含四大核心数据结构与两类存储结构,具体定义如下:
四大核心数据结构
-
共享模式(Shared Schemas)是在项目层级预定义为 SPG 类的粗粒度类型,涵盖实体类型(EntityTypes)、概念类型(ConceptTypes)和事件类型(EventTypes),作为知识的高层级分类体系,例如人物(Person)、组织机构(Organization)、地理定位(GEOLocation)、日期(Date)、生物(Creature)、作品(Work)、事件(Event)等类别。
-
实例图谱(Instance Graph)包含知识层(KGcs)和图信息层(KGfr)中的所有事件实例与实体实例。即通过开放信息抽取实现的无模式约束构建、以及通过模式约束实现的结构化抽取所得到的实例,均会作为实例对象存储于知识图谱存储系统中。
-
文本块(Text Chunks)是符合 ** 块实体类型(Chunk EntityType)** 定义的特殊实体节点,为图谱提供原始文本上下文支撑。
-
概念图谱(Concept Graph)是实现知识对齐的核心组件,由一系列概念及概念间关联关系构成,概念节点同时也是实例的细粒度类型。通过关系预测,可将实例节点与概念节点建立关联,为实例赋予精细化的语义类型,实现不同粒度知识的语义对齐。
两类存储结构
-
知识图谱存储(KG Store)将知识图谱相关数据结构存储于标签属性图(LPG)数据库中,例如 TuGraph、Neo4J 等。
-
向量存储(Vector Store)将文本及其对应的向量存储于向量检索引擎中,例如 ElasticSearch、Milvus,也可存储于标签属性图引擎内置的向量存储模块中。
关键细节补充
- 双向索引的核心是实现知识结构(图谱)与文本块向量的双向关联与溯源,既让图谱节点能快速关联到原始文本块,也让文本块能通过向量检索匹配到对应的图谱实例与概念;
- 粗粒度的共享模式与细粒度的概念图谱形成层级化类型体系,为实例提供从高层分类到精细化语义的完整类型定义;
- 实例图谱对无模式 / 有模式抽取的实例做统一存储,兼顾了知识构建的灵活性与结构化,与 LLMFriSPG 的属性设计相呼应;
- 双存储结构的设计结合了图数据库的结构化关系表达优势与向量数据库的高效相似性检索优势,是 KAG 融合 KG 与向量检索的核心底层支撑。
2.3 逻辑形式求解器
在求解复杂问题的过程中,涉及三个核心步骤:规划(Planning)、推理(Reasoning)和检索(Retrieval)。
- 问题拆解是一种规划过程,用于确定下一步需要解决的子问题;
- 推理包括基于拆解后的问题检索信息、根据检索结果推断问题答案,或在检索内容无法解答问题时重新拆解子问题;
- 检索则是为原始问题或拆解后的子问题,寻找可作为参考依据的内容。
传统 RAG 中不同模块之间的交互基于自然语言的向量表示,这往往会导致结果存在偏差。受知识图谱问答(KGQA)领域中常用逻辑形式的启发,我们设计了一种具备推理与检索能力的可执行语言。该语言将单个问题分解为多个逻辑表达式,每个表达式均可能包含检索或逻辑运算相关函数,2.2 节所述的双向索引机制为这一过程的实现提供了支撑。
同时,受 ReSP [26] 的启发,我们设计了一种基于反思(Reflection)与全局记忆(Global Memory)的多轮求解机制。如图 6和算法 1所示,KAG 的求解过程流程如下:首先将当前问题querycur分解为一组以逻辑形式表示的子问题列表lflist,并通过混合推理对这些子问题进行求解;若能通过对结构化知识的多跳推理得到精确答案,则直接返回该答案;否则,对求解结果进行反思 —— 将lflist对应的答案与检索结果存入全局记忆,并判断原始问题是否已得到解决;若未解决,则生成补充问题并进入下一轮迭代求解。
2.3.1、2.3.2 和 2.3.3 节将分别介绍用于规划、推理和检索的逻辑形式函数。总体而言,本文提出的逻辑形式语言具备以下三大优势:
- 采用符号化语言,提升了问题分解与推理过程的严谨性和可解释性;
- 充分利用 LLMFriSPG 的层级化表示,在符号化图结构的引导下检索事实性知识与文本文档知识;
- 整合了问题分解与检索流程,降低了系统的复杂度。
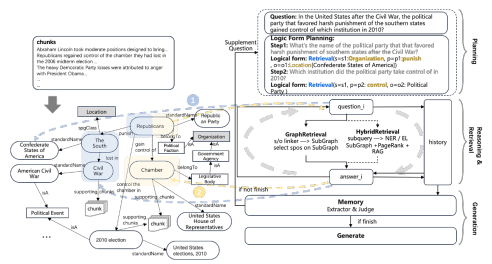
图 6:逻辑形式执行示例。本图中,左侧知识图谱(KG)的构建流程对应图 5,右侧展示了完整的推理与迭代过程。具体流程如下:首先,基于用户的整体问题进行逻辑形式分解;随后,借助逻辑形式引导的推理完成检索与推理操作;最后,由生成模块判断结果是否满足用户问题的需求。若未满足,则生成新的补充问题,进入新一轮的逻辑形式分解与推理流程;若判定已满足需求,则由生成模块直接输出最终答案。
2.3.1 逻辑形式规划
逻辑函数的定义如表 1 所示,每个函数对应一项执行操作。通过规划组合这些逻辑表达式,可实现复杂问题的拆解,进而完成对复杂问题的推理求解。
-
检索(Retrieval)该函数用于从 SPO 三元组中检索知识或信息,在同一个表达式中,主体
s、谓词p、客体o不得重复出现多次。检索时可对s、p、o添加约束条件。对于多跳查询,需要执行多次检索操作。当当前变量引用前面已提及的变量时,变量名必须与被引用的变量名保持一致,且仅需提供变量名即可;知识类型与名称仅在首次引用时进行指定。 -
排序(Sort)该函数用于对检索结果进行排序。其中
A是检索得到的 SPO 三元组(对应sᵢ、oᵢ,或s.prop、p.prop、o.prop)的变量名;direction指定排序方向,direction = min表示升序排序,direction = max表示降序排序;limit = n表示输出排名前n的结果。 -
数学运算(Math)该函数用于执行数学计算。
expr(表达式)采用 LaTeX 语法,可对检索结果(集合)或常量执行计算。mathᵢ代表计算结果,可作为变量名在后续操作中被引用。 -
推演(Deduce)该函数用于对检索结果或计算结果进行逻辑推演,以解答问题。
A、B可以是检索得到的 SPO 三元组对应的变量名,也可以是常量。操作符op = entailment\|greater\|less\|equal分别对应:A蕴含B、A大于B、A小于B、A等于B。
关键术语与细节补充
- 逻辑形式规划(Logical Form Planning):核心是将自然语言复杂问题,转化为「检索→排序→数学运算→推演→输出」的函数组合流程,是实现符号化严谨推理的基础;
- SPO 三元组:此处的
s(主体)、p(谓词 / 关系)、o(客体)对应知识图谱的核心组成单元,检索函数就是对知识图谱中的三元组进行精准查询; - LaTeX 语法:学术论文中常用的数学公式表示语法,文中
∥A∥(集合 A 的元素个数,即计数)、∑A(集合 A 的元素求和)是典型示例,确保数学运算的规范性与可解释性; - 多跳查询(multi-hop queries):需要跨越多个实体 - 关系关联才能完成的查询(例如 “周杰伦的唱片公司的总部在哪里”),需多次调用
Retrieval函数,且通过统一变量名实现多步结果的衔接; - 变量引用规则:“首次指定类型与名称,后续仅需统一变量名”,这一规则是简化逻辑表达式、避免冗余、确保多步操作衔接一致的关键。
2.3.2 用于推理的逻辑形式
- 自然语言的逻辑模糊性:核心问题是自然语言中的 “或 / 且” 等逻辑词缺乏明确的机器可识别标识,而逻辑形式通过符号化表达(对应前文函数),将模糊逻辑转化为精确的机器可执行逻辑,这是解决 “查询相似但答案迥异” 问题的关键。
- 显式语义关系(explicit semantic relations):相对于自然语言的隐含逻辑,逻辑形式通过函数和变量,将 “与、或、非、交集、差集” 等逻辑关系明确地展现出来,无歧义、可追溯。
- IRCOT:一种用于复杂问题拆解与推理的现有方法,本文借鉴了其 “问题拆解 - 多步操作规划” 的思路,同时结合 KAG 的逻辑形式函数与双向索引进行了优化。
- 两个核心检索模块:
GraphRetrieval:专注于知识图谱结构化检索,获取 SPO 三元组等图结构数据,支撑严谨的逻辑推理;HybridRetrieval:融合自然语言子问题与逻辑函数,同时检索文档(RC 层)与子图(KGcs/KGfr 层)信息,兼顾信息的完备性与结构化。
- 子问题依赖关系:通过 “变量引用” 建立依赖(例如前一个子问题的检索结果变量,作为后一个子问题的输入),实现复杂问题的分步推演,这是多跳推理、多轮迭代的基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)