为什么你的SFT又训成复读机了?一招帮你解决!
选一个你最头疼的SFT任务,固定模型、数据、学习率、epoch,只加--use_NLIRG 'true'跑一版;然后对比两版结果在模板化比例+变体鲁棒性+域外回归三个维度的表现。不用信我,信你的实验数据。我之前花两周调参没解决的问题,用Y-Trainer加NLIRG只用了三天就搞定了。复读机问题不是简单的过拟合能概括的,它关乎到训练过程中梯度被谁主导、你能否在梯度入口处进行干预。希望我的踩坑经验能
0.写在前面
传送门:
今天聊聊一个很多朋友踩过的坑:用SFT微调大模型时,模型越训越不对劲,回答变得越来越短、越来越模板化,动不动就重复某些句式。更要命的是,原本能轻松处理的通用任务(比如写代码、做推理、回答常识问题)也开始掉点——感觉被这批垂直数据覆盖掉了核心能力。
相信很多朋友试过各种常规操作:降学习率、早停、混通用数据、重新设计prompt、清洗脏数据......这些方法确实有点用,但总感觉隔靴搔痒。其实复读机问题本质上是微观梯度层面的问题,而不是宏观训练策略能完全解决的。
作为一个被复读机折磨过的ai人,今天就和大家唠唠:为什么SFT容易训成复读机,以及我最近发现的一个神器——Y-Trainer。这东西真的救我狗命了!它有一个叫NLIRG的算法,可以在token级别动态调整梯度权重,专门针对SFT过拟合与灾难性遗忘问题。官方文档提到:Y-Trainer能有效避免模型灾难性遗忘和过拟合,而且不依赖通用语料也能保留泛化能力。
下面我就从一个实战的角度,把这个问题拆解清楚,最后分享我用Y-Trainer解决问题的实际经验。
一、复读机现象背后的真相:梯度被谁控制了?
训成复读机不只是字面意义上的重复说话,而是一种模式坍塌:
-
内容层面:模型开始偏爱训练集中高频出现的答案结构、口头禅和固定段落,对边缘问题拒绝展开
-
策略层面:倾向于用安全、短、模板化的方式结束回答,看似更稳,实则信息量越来越低
-
分布层面:对训练域内问题看似更准,但域外泛化能力断崖式下跌,甚至同领域稍微变化的问题也处理不好
只有踩坑后才明白,这些现象背后的核心是:模型的参数更新被一类重复出现、损失很低或极易拟合的token主导了。训练越久,这类token的边际收益越低,但它们仍在持续贡献梯度,把模型拉向更确信地输出这些模式。而真正决定任务能力建设的难点token,要么数量少,要么梯度被淹没,要么因太难/有噪声导致更新方向不稳定。
你可能会问:交叉熵损失不是自然关注难的地方吗?
理论上是,但在SFT的实际数据分布下,这往往失效。
二、SFT为什么特别容易过拟合?问题出在token级别
SFT数据一般是instruction+response的形式。模型在teacher forcing下对response的每个token做预测并计算loss。这里有三个坑:
-
低损失token太多且同质化严重:大量response token其实是模板化连接词、标点、常见短语、固定格式字段。这些token在数据集中频率高、条件分布简单,模型很快就学会,loss迅速变低。但它们仍参与反传,成为长期稳定但不提升能力的梯度来源。
-
中等难度token才是能力增长区,但容易被淹没:真正让模型从会背格式到会解决问题的,是那些需要结合上下文、跨句依赖、领域概念映射的token。它们的loss通常处于中等区间。如果训练过程不能持续把更新资源集中到这部分token,你只会得到一个格式越来越像、信息越来越少的模型。
-
高损失token里混着两种东西:真正困难点+脏数据/错标/不一致。如果你对高loss一视同仁地强行学习,模型会被噪声牵引,训练不稳定,泛化能力也下降更快。
简单说:SFT的关键不是要不要训练更多epoch,而是每次反传时,把梯度预算花在了什么token上。传统做法(调学习率、早停、混通用数据)是整体控强度;但复读机需要的是按token难度控强度。
三、灾难性遗忘和复读机:同根同源的问题
很多朋友把遗忘归因于没混通用数据,但这只是表象。更深层的原因是:
当你只用垂直数据做SFT时,训练分布与基座预训练分布差异大。模型为了降低当前训练损失,会调整参数去贴合新分布;如果这些更新主要由同质、低loss、高频token驱动,虽然对当前训练集的损失下降很有效,但对原来的通用能力没有正贡献,甚至会破坏原本的表征结构。
灾难性遗忘通常是由过难语料导致,过拟合往往来自相似语料或者模型已经掌握的知识,解决方法是通过识别这些token动态调整训练强度。
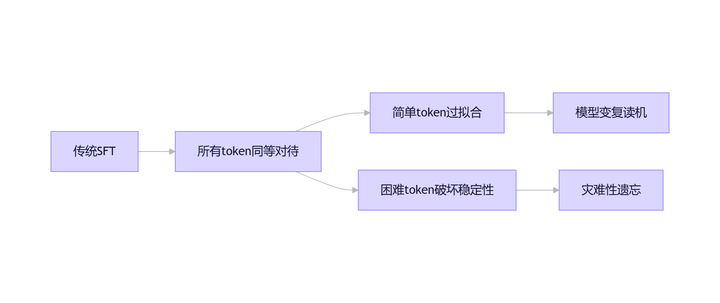
四、NLIRG到底怎么解决这个问题?

Y-Trainer的核心算法NLIRG(基于梯度的非线性学习强度调节算法)工作方式很直接:
-
对每个token计算损失
-
把token loss映射成一个权重W(L),权重不是线性的,而是按损失区间分段控制
-
用loss×weight得到最终用于反向传播的损失,相当于对不同token的梯度贡献做缩放
文档中清晰地分了四个策略区间:
A. 低损失区间(loss≤1.45):削减梯度,抑制对已经学会的token的继续强化
B. 中等损失区间(1.45<loss<6.6):增强梯度,把更新资源集中到真正还没学会、但可学习的token上
C. 中高损失区间(6.6<loss<15):再次削减梯度,避免被很难的token带偏
D. 极高损失区间(loss≥15):梯度归零,直接忽略明显异常样本/异常token
|
损失区间 |
梯度策略 |
训练目的 |
实际效果 |
|
loss ≤ 1.45 |
削减梯度 |
避免过拟合 |
防止模型过度记忆简单样本,减少复读现象 |
|
1.45 < loss < 6.6 |
增强梯度 |
高效学习 |
重点攻克有价值样本,提升学习效率 |
|
6.6 < loss < 15 |
削减梯度 |
稳定训练 |
防止困难样本带偏模型,保护已有能力 |
|
loss ≥ 15.0 |
梯度归零 |
隔离噪声 |
忽略明显错误样本,避免训练崩坏 |
我用它跑了一轮实验,最直观的感受是:那些总让我模型变成复读机的高频连接词和模板句式,梯度贡献被大幅削弱;而真正决定能力的难点token得到了更多关注。不是靠猜测,而是算法直接在反传入口处把梯度贡献重新分配了!
五、为什么NLIRG比我们平时的土办法更有效?
其实我们平时已经在用一些近似策略,只是不够精细:
-
我们会过滤重复样本、合并相似指令——这是在减少低损失高频token的出现频率,但做不到同一条样本里某些token应该弱学、某些token应该强学
-
会做hard example mining——这想关注中等/偏难样本,但难度评估常停留在样本级
-
踢掉脏数据——但脏数据不总是整条都脏,有时是局部错标
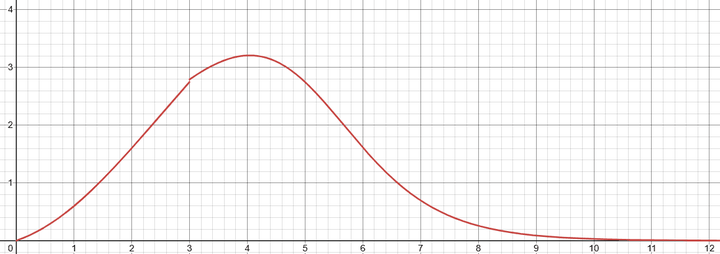
横轴 为Loss值,纵轴为梯度权重
NLIRG的厉害之处在于:它不要求你先把数据清洗到完美,而是在训练过程中对不同难度token进行差异化对待,把异常token从反传链路里隔离出来。我在用它的时候,发现它还能通过内部信号对语料质量评分,帮我提前揪出了一些数据集里的问题样本。
六、一个实用技巧:token分批训练,让token-level loss更靠谱
token级别做权重有个前提:你算出来的token loss得尽量稳定,否则权重会抖。Y-Trainer专门提供了分批次的Token训练技巧:一次只训练少量token,保证token loss计算准确,同时兼顾显存与梯度稳定性。通过--token_batch参数就能控制每次反向传播的token数。
我一开始忽略了这个设置,直接用长序列做token权重,结果loss波动很大。后来把--token_batch设为10,训练明显稳定多了。这个细节对效果影响挺大的,大家一定要注意。
七、训练前先排雷:用语料排序工具预处理数据
除了NLIRG,Y-Trainer还提供了训练顺序调整算法,用损失值、熵的走向相似度衡量语料难度。
在训练前,使用Y-Trainer的语料排序工具评估数据质量:
python -m training_code.utils.schedule.sort \
--data_path raw_data.json \
--output_path sorted_data.json \
--model_path Qwen/Qwen3-8B \
--mode similarity_rank # 基于曲线相似度的排序策略算法原理:通过分析模型对每条语料的响应(损失值和熵的变化),计算语料难度评分
实用价值:
-
排查语料问题:得分低的样本先人工检查,我用这功能揪出了数据集中十几条格式错误的样本
-
优化训练顺序:不是简单地从易到难,而是合理混排难度,让模型学习路径更平滑
文档提到这工具能让训练效率提升30%+,我实测下来确实有感觉,训练收敛速度明显加快。
八、上手指南:从一条参数开始验证
别急着把整个训练流程推倒重来。我建议先选一个你最熟悉、最容易复现复读机的SFT任务,保持其他所有参数不变,只加一个开关:--use_NLIRG 'true'。
环境搭建很简单:
git clone https://github.com/yafo-ai/y-trainer.git
cd y-trainer
pip install -r requirements.txt资源紧张的同学别担心,Y-Trainer支持LoRA和DeepSpeed,通过use_lora、use_deepspeed等参数就能开启。我用单卡24G显存的3090就能跑8B模型的LoRA微调,对小团队很友好。
九、如何评估效果?别只看loss!
做对照实验时,我总结了三个实用评估方法:
-
模板化比例:抽样200条生成结果,用脚本统计高频n-gram占比或计算distinct-1/2。复读机的distinct指标会明显下降
-
域内鲁棒性:对同一任务做prompt变体(同义改写、打乱字段顺序),看正确率是否更稳定
-
域外回归:准备一小撮通用问题(训练前模型能做的),比较训练前后差异
只看loss很容易被误导:过拟合模型的loss当然能继续下降,但输出质量可能在恶化。
十、为什么我愿意推荐它?
很多训练框架的差异点在工程层(分布式、显存优化等),这些重要但解决不了训着训着变味的核心痛点。Y-Trainer的差异在算法层:token级别的动态梯度权重,明确把训练强度按损失区间重新分配。
如果你也常遇到这些问题:
-
SFT过拟合太快,输出越来越模板化
-
不混通用语料就掉通用能力,混了又影响垂直提升
-
数据里有噪声,训练稳定性差
那么NLIRG这套按token难度调梯度的思路,绝对值得你拿一个任务做对照验证。
最后建议
选一个你最头疼的SFT任务,固定模型、数据、学习率、epoch,只加--use_NLIRG 'true'跑一版;然后对比两版结果在模板化比例+变体鲁棒性+域外回归三个维度的表现。不用信我,信你的实验数据。
我之前花两周调参没解决的问题,用Y-Trainer加NLIRG只用了三天就搞定了。复读机问题不是简单的过拟合能概括的,它关乎到训练过程中梯度被谁主导、你能否在梯度入口处进行干预。希望我的踩坑经验能帮到同样在挣扎的你!
有任何问题欢迎评论区讨论,我们一起交流进步!#大模型训练 #AI工程化 #深度学习调参

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)