别让数据分析拖慢论文进度!虎贲等考 AI:30 分钟搞定从数据清洗到图表生成的全流程
对科研人来说,数据分析就像论文写作中的 “硬骨头”—— 手握几十页问卷数据却不知从何下手,对着 SPSS 的参数面板反复试错,熬夜画出的图表因格式不达标被导师打回,最后还要为分析论述的重复率焦虑。传统数据分析的 “高门槛、低效率、易出错”,让很多人陷入 “数据沉睡” 的困境。而虎贲等考 AI 智能写作平台()的数据分析功能,用 “AI 驱动 + 学术适配” 的双重优势,把复杂的统计分析变成 “一键
对科研人来说,数据分析就像论文写作中的 “硬骨头”—— 手握几十页问卷数据却不知从何下手,对着 SPSS 的参数面板反复试错,熬夜画出的图表因格式不达标被导师打回,最后还要为分析论述的重复率焦虑。传统数据分析的 “高门槛、低效率、易出错”,让很多人陷入 “数据沉睡” 的困境。而虎贲等考 AI 智能写作平台(https://www.aihbdk.com/)的数据分析功能,用 “AI 驱动 + 学术适配” 的双重优势,把复杂的统计分析变成 “一键操作”,哪怕是零基础的科研人,也能让数据 “开口说话”。
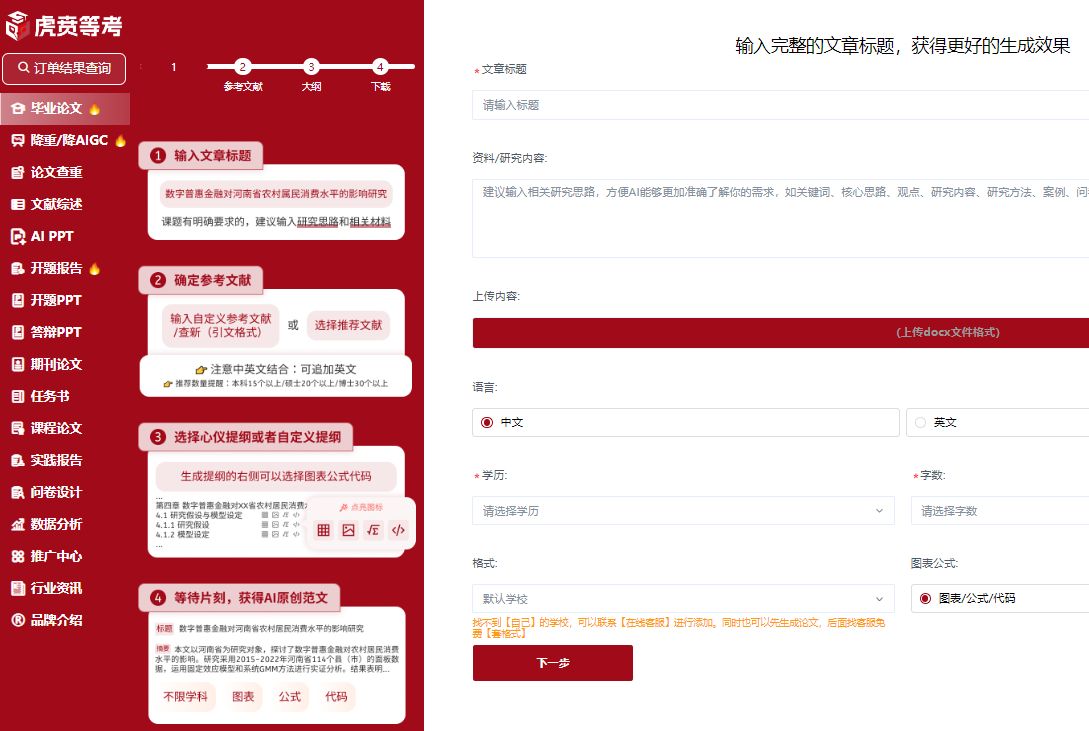
一、打破专业壁垒:零统计基础也能上手的 “傻瓜式” 操作
传统数据分析的第一道坎,是 “专业门槛”。非统计专业的学生要先啃完《统计学原理》,再花几天摸索 SPSS、Python 的操作逻辑,最后还可能因选错分析方法导致结果无效。虎贲等考 AI 彻底重构了操作流程,让 “不懂统计也能做分析” 成为现实。
数据导入零障碍是基础优势。无论是问卷调研的 Excel 表格、实验测量的 CSV 文件,还是从统计年鉴下载的二手数据,直接上传即可 —— 平台支持 10 + 种常见数据格式,无需手动转换格式或调整字段。更贴心的是,若使用平台的问卷设计功能生成调研问卷,回收数据会自动同步到数据分析模块,避免手动录入时的抄录错误,数据完整性直接拉满。
智能数据清洗帮你解决 “脏数据” 难题。上传数据后,AI 会自动扫描缺失值、异常值和重复数据:遇到 “年龄填 150 岁”“收入为负数” 这类逻辑矛盾的样本,会标记并询问是否剔除;针对少量缺失值,会推荐 “均值填充”“中位数插补” 等科学方案;甚至能识别问卷中的 “规律性作答”(如所有选项都选 “非常满意”),提醒用户排查无效样本。整个过程无需手动筛选,3 分钟就能完成传统方法 1 小时的工作量。
最颠覆的是自然语言驱动分析。不用记 “Pearson 相关”“Logistic 回归” 这些专业术语,只需用日常语言描述需求,比如 “分析不同学历农村居民的消费差异”“验证数字普惠金融对消费的影响”,AI 会自动匹配研究目标与数据类型,推荐最优分析模型。以 “数字普惠金融对河南省农村消费的影响” 研究为例,上传 2012-2021 年 17 个地市的面板数据后,输入需求,AI 会直接推荐混合 OLS 模型,并标注 “适用于面板数据的线性关系检验”,省去手动查文献选方法的时间。
二、覆盖全学科需求:从本科论文到核心期刊的 “万能分析库”
不同学科的数据分析需求天差地别:教育学要做信效度分析,医学需要 ROC 曲线检验,经管类常用回归分析。虎贲等考 AI 内置 60 + 种主流统计方法,适配理工、经管、教育、医学等多学科场景,真正实现 “一站式分析”。
对文科社科类研究,平台强化了问卷数据分析能力。做教育调研时,上传 300 份 “线上教学满意度” 问卷,AI 会自动计算 Cronbach's Alpha 信度系数(若结果为 0.85,会标注 “信度良好,可用于后续研究”),同时完成探索性因子分析,帮你验证问卷维度设计是否合理。生成的分析报告里,不仅有详细的数值表格,还会用通俗语言解读结果,比如 “‘教学互动’维度的因子载荷量均大于 0.7,说明该维度设计有效”,避免看不懂专业指标的尴尬。
对理工医学类实验,则侧重精准的差异与相关性分析。对比两种药物的疗效数据时,AI 会自动选择独立样本 T 检验,输出均值、标准差、P 值等核心指标,还会标注 “P<0.05,差异具有统计学意义”;分析细胞实验的浓度 - 效应关系时,会生成剂量反应曲线,并计算 EC50(半数效应浓度),图表标注严格符合《中华医学杂志》的排版规范。
针对经管类的深度研究,平台支持高级计量分析。以 “数字普惠金融对消费结构的影响” 为例,上传数据后,AI 可完成多元线性回归、中介效应检验、异质性分析:不仅能验证 “覆盖广度、使用深度、数字化程度” 三个子维度的影响系数,还能通过 Bootstrap 法检验 “收入水平” 的中介作用,生成的路径图会清晰标注各环节的系数与显著性,直接满足硕士论文或核心期刊的实证要求。
三、学术级输出:图表 + 报告 + 降重的 “一条龙” 服务
数据分析的最终目的,是为论文提供 “硬核支撑”。虎贲等考 AI 不仅能算出结果,还能生成符合学术规范的可视化图表与分析报告,甚至帮你解决重复率问题,真正做到 “拿来就能用”。
图表自动适配期刊规范是一大亮点。AI 会根据分析类型智能选择图表形式:做描述性统计时生成柱状图或箱线图,展示数据分布;做相关性分析时用热力图呈现变量关联强度;做回归分析时输出系数森林图,直观对比各变量影响大小。所有图表默认 300dpi 分辨率(满足印刷要求),字体用 Arial 或 Times New Roman,坐标轴标注 “物理量 + 单位”(如 “人均消费支出(元)”),连误差线的粗细、显著性标记(*p<0.05、**p<0.01)都严格遵循 GB/T 7714 标准。若投稿目标期刊有特殊要求(如 SCI 期刊偏好黑白配色),只需在设置里选择期刊名称,图表格式会自动调整,无需手动修改。
标准化分析报告帮你省去 “写论述” 的麻烦。报告包含 “数据来源、清洗过程、分析方法、结果解读、结论建议”5 个模块,语言严谨专业,可直接复制到论文的实证部分。以数字普惠金融研究为例,报告不仅会呈现 “数字普惠金融指数每提升 1 单位,农村居民消费增加 0.32 单位” 的核心结果,还会补充经济学解读:“这说明数字普惠金融通过降低融资成本、提升支付便利性,缓解了农村居民的流动性约束,进而促进消费”,连参考文献格式都已按 GB/T 7714 自动标注,无需手动排版。
更贴心的是与降重功能无缝衔接。很多人做完分析后,会因 “论述语言雷同” 导致重复率超标。虎贲等考 AI 在生成报告后,可一键触发 “智能改写”:在保留核心数据与结论的基础上,重构句式、替换专业术语,比如将 “数字普惠金融对消费有正向影响” 优化为 “数字普惠金融通过拓宽服务覆盖范围、深化使用场景,显著提升农村居民的消费意愿与能力”。同时,平台提供实时查重功能,修改后可直接查看重复率,确保控制在 25% 以内,彻底规避学术不端风险。
四、真实用户反馈:效率提升 10 倍的 “科研加速器”
“以前用 SPSS 分析数字普惠金融的面板数据,光是整理数据、设置回归参数就花了 3 天,结果还因遗漏控制变量被导师批评。用虎贲等考 AI 上传数据后,15 分钟就出了混合 OLS 模型的结果,连异质性分析都帮我做完了,图表直接插入论文,导师说实证部分比之前规范多了!”—— 某高校经管学院研究生小张的反馈,道出了很多科研人的心声。
无论是本科毕业论文的基础描述性统计,还是硕士论文的中介效应分析,亦或是期刊论文的高级计量检验,虎贲等考 AI 的数据分析功能都能精准适配。它不是简单的 “工具替代”,而是用 AI 技术降低学术门槛,让科研人把时间花在 “核心研究” 上,而非重复的机械操作。
现在打开虎贲等考 AI 官网(https://www.aihbdk.com/),上传你的数据,就能体验 “30 分钟搞定全流程分析” 的高效 —— 让沉睡的数据变成论文里的 “硬核加分项”,其实没那么难。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献948条内容
已为社区贡献948条内容

所有评论(0)