【论文速读】TRM: Tiny 递归推理网络
通过极简的递归结构实现超越大模型的逻辑推理能力。本文提出了一种名为的架构,旨在解决复杂推理任务(如数独、ARC-AGI)。核心突破:证明了不需要复杂的生物学类比或双网络层级结构,仅使用一个单网络、2层深度的微型模型 (7M参数),通过递归推理和深度监督,即可在逻辑任务上显著超越等超大模型以及先前的 HRM 模型。关键发现:在数据稀缺且需严密逻辑的场景下,模型参数并非越大越好。“极小网络 + 深度递
论文标题: Less is More: Recursive Reasoning with Tiny Networks
作者: Alexia Jolicoeur-Martineau Samsung SAIL Montr e ˊ al ^{\text{Samsung SAIL Montréal}} Samsung SAIL Montreˊal
代码: SamsungSAILMontreal/TinyRecursiveModels
5. 总结
通过极简的递归结构实现超越大模型的逻辑推理能力。
本文提出了一种名为 Tiny Recursive Model (TRM) 的架构,旨在解决复杂推理任务(如数独、ARC-AGI)。
- 核心突破:证明了不需要复杂的生物学类比或双网络层级结构,仅使用一个单网络、2层深度的微型模型 (7M参数),通过递归推理和深度监督,即可在逻辑任务上显著超越 DeepSeek R1、Gemini 2.5 Pro 等超大模型以及先前的 HRM 模型。
- 关键发现:在数据稀缺且需严密逻辑的场景下,模型参数并非越大越好。“极小网络 + 深度递归” 能够更有效地学习通用算法而非死记硬背,从而避免过拟合。
1. 思想
当前,大语言模型 (LLM) 在解决需要长链条、严密逻辑的谜题(如 Sudoku-Extreme, Maze, ARC-AGI)时表现挣扎。
-
大问题:
- LLM 的自回归生成模式在长逻辑链中极其脆弱,单步错误会导致全盘皆输。
- 思维链 (CoT) 和测试时计算 (TTC) 虽然有效,但成本高昂且依赖推理数据的质量。
- 先前的 分层推理模型 (HRM) 虽然尝试引入递归小模型,但其设计基于复杂的生物学假设(不同脑波频率),使用了两个分离的网络 ( f L , f H f_L, f_H fL,fH),并依赖不稳定的隐函数定理 (Implicit Function Theorem, IFT) 和单步梯度近似,导致训练困难且性能次优。
-
小问题:
- HRM 假设递归会收敛到不动点 (fixed-point),但这在实际训练中很少发生,导致梯度近似失效。
- HRM 强行将潜变量分为 “高频” ( z L z_L zL) 和 “低频” ( z H z_H zH),缺乏数学上的必要性。
- 如何在极少训练样本 (~1000例) 下让神经网络学会通用的算法逻辑,而不是过拟合数据?
-
核心思想:
- 去魅与简化:抛弃生物学解释。将双潜变量重新解释为更直观的 “当前解” ( y y y) 和 “潜在推理状态” ( z z z)。
- 单网络统一:证明了只需要一个微型网络即可同时处理推理更新 ( z z z) 和答案生成 ( y y y)。
- 全递归反向传播:由于网络极小且步数有限,直接展开计算图进行完整的 Backpropagation Through Time (BPTT),摒弃不稳定的单步梯度近似。
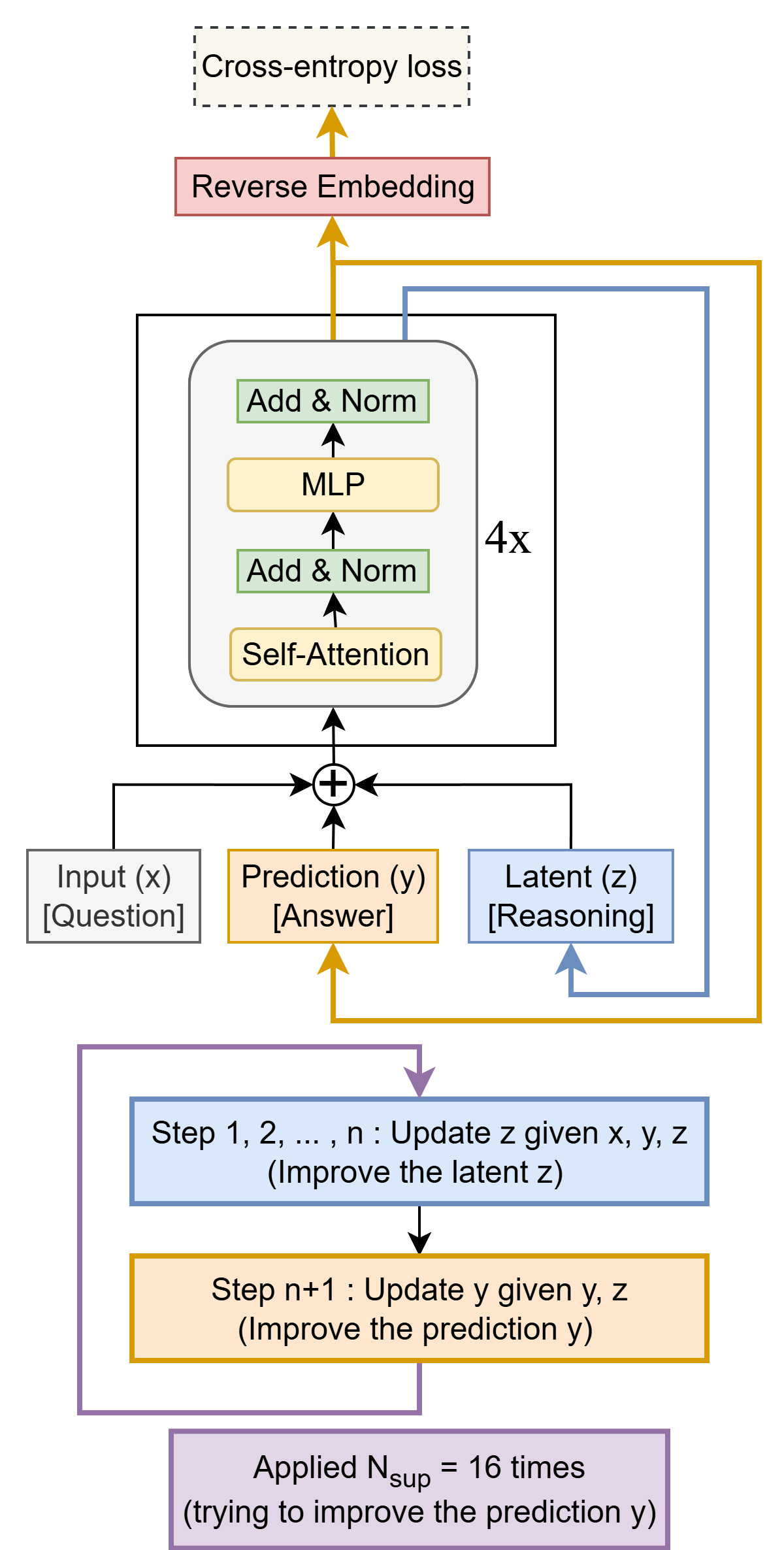
Figure 1: TRM 架构示意图。模型递归地利用输入问题 x x x、当前答案 y y y 和潜在状态 z z z 来精炼 z z z 和 y y y。
2. 方法
作者将复杂的 HRM 剥离为本质的数学形式,提出了 TRM。
2.1 重新诠释潜变量 (Reinterpretation)
HRM 使用 z L , z H z_L, z_H zL,zH 并通过 f L , f H f_L, f_H fL,fH 交替更新。TRM 指出这本质上是对 “解” 和 “思维” 的迭代:
- z H → y z_H \rightarrow y zH→y: 代表当前的显式解 (Answer)。
- z L → z z_L \rightarrow z zL→z: 代表当前的隐式推理状态 (Latent Reasoning/Scratchpad)。
在每一轮递归中,模型接收题目 x x x,参考上一轮的解 y y y 和思维状态 z z z,来生成新的 y y y 和 z z z。这类似于人类看着草稿纸 ( z z z) 和上一步填写的数字 ( y y y) 来思考下一步。
2.2 算法流程
TRM 使用单个网络 net ( ⋅ ) \text{net}(\cdot) net(⋅) 进行递归更新。给定输入 x x x,初始化 y , z y, z y,z。
训练过程包含 T T T 个大周期,每个周期内进行 n n n 次潜在推理更新。
-
潜在推理 (Latent Reasoning):
循环 n n n 次,仅更新思维状态 z z z:
z ← net ( x , y , z ) z \leftarrow \text{net}(x, y, z) z←net(x,y,z)
(注:此处 y y y 保持不变,模拟在不改变当前答案情况下的纯思考) -
答案细化 (Answer Refinement):
在 n n n 次思考后,更新答案 y y y 和状态 z z z:
y , z ← net ( y , z ) y, z \leftarrow \text{net}(y, z) y,z←net(y,z)
(注:这里是否输入 x x x 取决于具体实现,文中指出 z z z 已经包含了 x x x 的信息) -
深度监督 (Deep Supervision):
不同于 LLM 只监督最终输出,TRM 在每一个 T T T 周期结束时都计算 Loss 并进行监督。这迫使模型在每一步都向正确答案靠近。
2.3 摒弃不动点定理 (No Fixed-Point Theorem)
HRM 依赖 z ∗ = f ( z ∗ ) z^* = f(z^*) z∗=f(z∗) 的假设来使用 1-step 梯度近似:
∂ L ∂ θ ≈ ∂ L ∂ z ∗ ( I − J f ) − 1 ∂ f ∂ θ \frac{\partial L}{\partial \theta} \approx \frac{\partial L}{\partial z^*} (I - J_{f})^{-1} \frac{\partial f}{\partial \theta} ∂θ∂L≈∂z∗∂L(I−Jf)−1∂θ∂f
作者指出 HRM 在实际只有 4-6 步递归的情况下根本无法收敛到不动点,导致梯度估计错误。
# HRM 的伪代码实现
def hrm(z, x, n=2, T=2): # hierarchical reasoning
zH, zL = z
with torch.no_grad():
for i in range(n * T - 2):
zL = L_net(zL, zH, x)
if (i + 1) % T == 0:
zH = H_net(zH, zL)
# 1-step grad
zL = L_net(zL, zH, x)
zH = H_net(zH, zL)
return (zH, zL), output_head(zH), Q_head(zH)
def ACT_halt(q, y_hat, y_true):
target_halt = (y_hat == y_true)
loss = 0.5 * binary_cross_entropy(q[0], target_halt)
return loss
def ACT_continue(q, last_step):
if last_step:
target_continue = sigmoid(q[0])
else:
target_continue = sigmoid(max(q[0], q[1]))
loss = 0.5 * binary_cross_entropy(q[1], target_continue)
return loss
# Deep Supervision
for x_input, y_true in train_dataloader:
z = z_init
for step in range(N_sup): # deep supervision
x = input_embedding(x_input)
z, y_pred, q = hrm(z, x)
loss = cross_entropy(y_pred, y_true)
# Adaptive computational time (ACT) using Q-learning
loss += ACT_halt(q, y_pred, y_true)
_, _, q_next = hrm(z, x) # extra forward pass
loss += ACT_continue(q_next, step == N_sup - 1)
z = z.detach()
loss.backward()
opt.step()
opt.zero_grad()
if q[0] > q[1]: # early-stopping
break
Figure 2: HRM 的伪代码实现。
TRM 的方案:直接对展开的计算图进行反向传播。因为网络极小 (Tiny),即使展开几十步,显存消耗也可以忽略不计。
# TRM 的伪代码实现
def latent_recursion(x, y, z, n=6):
for i in range(n): # latent reasoning
z = net(x, y, z)
y = net(y, z) # refine output answer
return y, z
def deep_recursion(x, y, z, n=6, T=3):
# recursing T-1 times to improve y and z (no gradients needed)
with torch.no_grad():
for j in range(T-1):
y, z = latent_recursion(x, y, z, n)
# recursing once to improve y and z
y, z = latent_recursion(x, y, z, n)
return (y.detach(), z.detach()), output_head(y), Q_head(y)
# Deep Supervision
for x_input, y_true in train_dataloader:
y, z = y_init, z_init
for step in range(N_supervision):
x = input_embedding(x_input)
(y, z), y_hat, q_hat = deep_recursion(x, y, z)
loss = cross_entropy(y_hat, y_true)
loss += binary_cross_entropy(q_hat, (y_hat == y_true))
loss.backward()
opt.step()
opt.zero_grad()
if q_hat > 0: # early-stopping
break
Figure 3: TRM 的伪代码实现。逻辑清晰,通过简单的循环实现递归更新。
2.4 自适应计算时间 (Simplified ACT)
HRM 使用复杂的 Q-learning 来决定何时停止思考,需要额外的 Forward Pass。
TRM 的方案:仅学习一个二分类的停止概率 (Halting Probability),不再需要额外的 Q-value 估计,去掉了 Continue Loss,训练速度提升且无需额外推理开销。
3. 优势
- 参数效率极致:使用 7M 参数在数独任务上达到了 87.4% 的准确率,而 27M 参数的 HRM 仅为 55.0%。
- 训练稳定性:移除了不动点假设和梯度近似,训练收敛更稳定,残差 (Residuals) 显著降低。
- 架构极简:
- 2个网络 → \to → 1个网络。
- 生物学分层假设 → \to → y , z y, z y,z 状态机。
- 复杂 Q-learning → \to → 简单二分类停止预测。
4. 实验
实验主要在 Sudoku-Extreme (极难数独), Maze-Hard (30x30迷宫), 和 ARC-AGI (抽象推理) 上进行。这些任务的特点是训练数据少 (1k样本),但测试空间巨大。
4.1 核心对比结果
| 方法 | 参数量 | Sudoku Acc (%) | Maze Acc (%) | ARC-AGI-1 (%) |
|---|---|---|---|---|
| DeepSeek R1 | 671B | 0.0 | 0.0 | 15.8 |
| Claude 3.7 | ? | 0.0 | 0.0 | 28.6 |
| HRM (前SOTA) | 27M | 55.0 | 74.5 | 40.3 |
| TRM (Ours) | 7M | 87.4 | 85.3 | 44.6 |
- 超越大模型:在未经过特定训练的情况下,通用 LLM 即使使用 CoT 亦无法处理数独和迷宫(逻辑稍微断裂即失败)。
- 超越前作:TRM 以 1/4 的参数量,实现了大幅度的性能提升。
4.2 关键消融实验 (Ablation)
-
Less is More (层数越少越好):
作者惊奇地发现,2层 (2-layer) 网络的泛化性能优于 4层网络。- 2-layer: 87.4%
- 4-layer: 79.5%
- 深度解读: 在数据极度稀缺 (1k) 的逻辑任务中,增加参数会导致模型倾向于"记忆"而非"学习算法"。极小的网络逼迫模型学习通用的递归规则。
-
Attention vs MLP:
- 对于固定网格大小的任务 (Sudoku 9x9),使用 MLP-Mixer 替代 Self-Attention 效果更好 (87.4% vs 74.7%)。
- 对于长序列/大网格 (Maze 30x30, ARC),Self-Attention 仍然是必须的。
-
潜变量数量:
将 z z z 拆分为多个特征并无益处,维持单一的 z z z 和 y y y 是最优解。这验证了去除了生物学分层假设的正确性。
4.3 失败的尝试 (Negative Results)
为了学术诚信,作者列出了无效的尝试,这对研究极其有价值:
- MoE (Mixture of Experts): 导致泛化性能大幅下降。增加了不必要的容量。
- TorchDEQ: 使用 Deep Equilibrium Models 的求解器替代递归步骤,导致训练变慢且泛化变差。证明了不需要严格收敛到不动点,过程中的推理轨迹才是关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)