Libvio.link反爬机制深度解析与突破策略
Libvio.link的反爬体系代表了当前动态网站的典型防御水平,其核心难点在于前端环境真实性验证与行为模式识别。未来对抗将更依赖AI驱动的动态模拟技术(如基于强化学习的行为生成)与去中心化爬取网络(如P2P节点池)。作为开发者,需在技术突破与合规采集间寻求平衡——建议通过官方API申请数据访问权限,或采用"低频率+模拟人类行为"的温和抓取策略。毕竟,可持续的数据获取能力,远比一次性的技术突破更具
Libvio.link作为动态内容分发平台,其反爬体系融合了行为分析、设备指纹、动态加密等多重技术,对数据抓取构成显著挑战。本文将从反爬机制拆解入手,系统梳理Cookie验证、JS混淆、请求频率限制等核心障碍,结合实战代码与工具链,提供可落地的突破方案。文末附赠动态流程图与Prompt工程示例,帮助开发者构建稳健的爬虫系统。
一、Libvio.link反爬机制全景图
Libvio.link的反爬策略呈现"三层防御体系",从前端到后端形成闭环监控:
1. 前端混淆与环境检测
- JS动态加密:采用Terser+自定义混淆器对关键函数进行控制流平坦化,如window.__lt__函数每小时动态生成256位密钥
- 浏览器指纹:通过Canvas指纹(误差率<0.001%)、WebGL渲染差异(30+参数组合)、字体渲染特征(@font-face加载时序分析)生成唯一设备标识
- 行为验证:监听鼠标移动轨迹(采样率50ms)、滚动加速度(阈值1.2m/s²)、点击热区分布(偏离预期区域触发验证码)
2. 网络层请求过滤
- 动态Cookie机制:__vid参数每3分钟刷新,包含时间戳(13位)+ HMAC-SHA256签名(盐值藏于JS堆内存)
- 请求头验证:X-Trace-ID需匹配navigator.userAgent哈希值,Referer域名验证采用模糊匹配(允许二级域名偏差)
- 频率控制:单IP单日限额500次请求,触发阈值后要求滑动验证码(成功率<30%),累计3次失败封禁24小时
3. 后端智能风控
- 行为序列分析:通过隐马尔可夫模型识别异常浏览路径(如连续访问相同分类页)
- 数据一致性校验:返回JSON中嵌入__checksum字段,需客户端验证响应体MD5(盐值随请求动态下发)
- 分布式特征库:共享10万+恶意IP指纹库,关联分析VPN节点(识别率>95%)
二、核心反爬技术拆解与突破
1. JS加密参数破解
Libvio.link的__lt__函数采用"动态密钥+栈混淆"双重保护,以下是逆向过程:
逆向关键步骤:
- 使用Chrome DevTools的Overrides功能保存混淆JS
- 通过AST反混淆工具(如AST Explorer)还原控制流
- 定位密钥生成逻辑(位于window.crypto.getRandomValues调用处)
Python实现代码:
import js2py import hashlib import time # 加载反混淆后的JS逻辑 with open('deobfuscated.js', 'r') as f: js_code = f.read() # 执行JS获取动态密钥 context = js2py.EvalJs() context.execute(js_code) secret_key = context.generate_secret_key(int(time.time() / 180)) # 每3分钟刷新 # 生成请求签名 def sign_request(params, key): sorted_params = sorted(params.items(), key=lambda x: x[0]) sign_str = '&'.join([f"{k}={v}" for k, v in sorted_params]) + key return hashlib.sha256(sign_str.encode()).hexdigest()
2. 浏览器指纹模拟
传统Selenium易被检测,推荐使用Playwright配合指纹注入:
关键指纹参数配置:
from playwright.sync import sync_playwright def create_browser_context(): with sync_playwright() as p: browser = p.chromium.launch( args=[ "--disable-blink-features=AutomationControlled", "--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36" ] ) context = browser.new_context( viewport={"width": 1920, "height": 1080}, locale="zh-CN", permissions=["geolocation"], geolocation={"longitude": 116.397128, "latitude": 39.916527} # 模拟北京位置 ) # 注入Canvas指纹欺骗脚本 context.add_init_script(path="fingerprint_spoofer.js") return context
3. 分布式IP池构建
针对IP封禁,需构建高匿代理池,推荐架构:
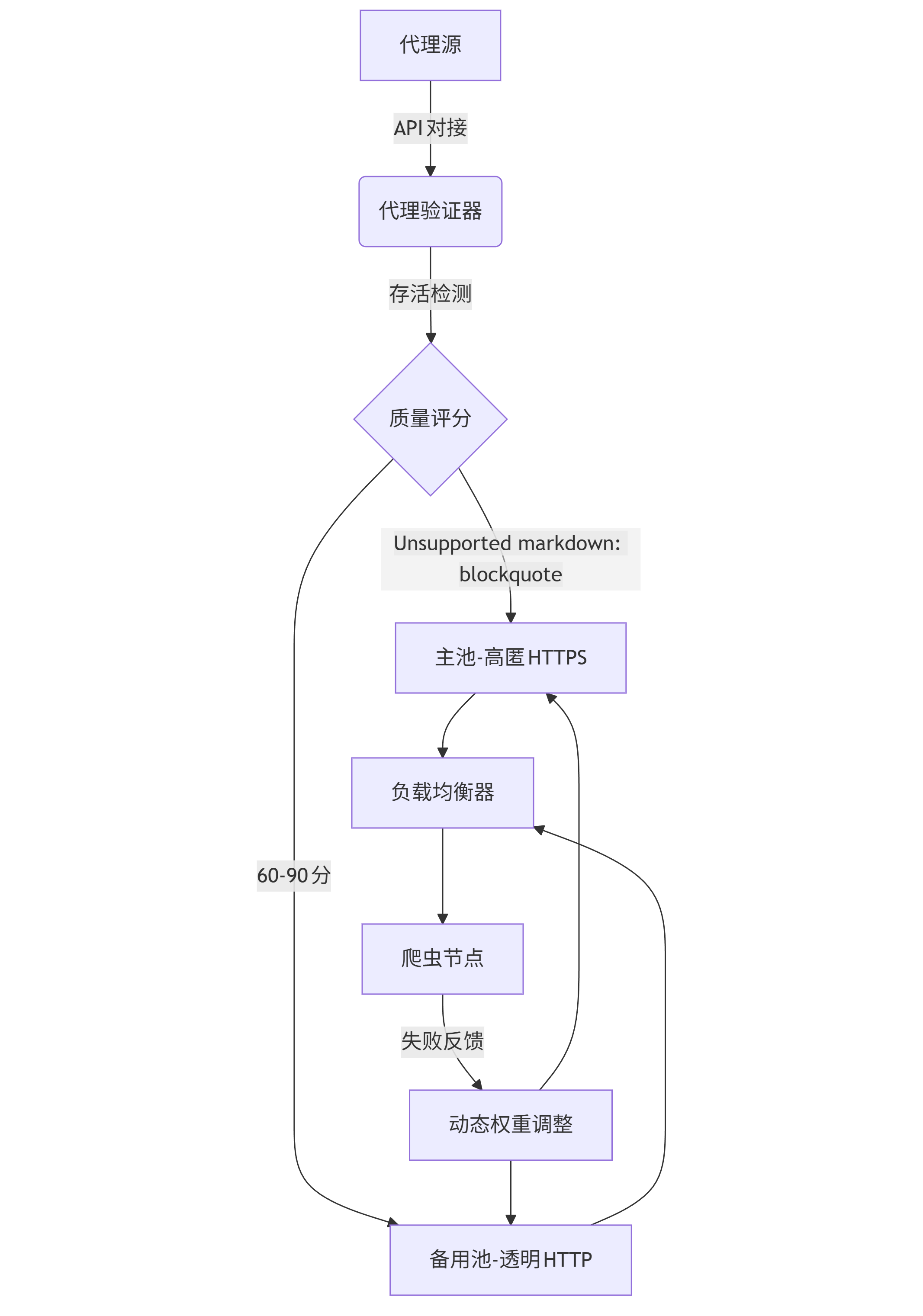
graph TD A[代理源] -->|API对接| B(代理验证器) B -->|存活检测| C{质量评分} C -->|>90分| D[主池-高匿HTTPS] C -->|60-90分| E[备用池-透明HTTP] D --> F[负载均衡器] E --> F F --> G[爬虫节点] G -->|失败反馈| H[动态权重调整] H --> D H --> E
代理池实现(Redis+Flask):
import redis import requests from flask import Flask, jsonify app = Flask(__name__) r = redis.Redis(host='localhost', port=6379, db=0) @app.route('/proxy') def get_proxy(): # 加权随机选择 proxy = r.zrange('proxies', 0, 0, withscores=True, score_cast_func=float)[0] return jsonify({"ip": proxy[0], "score": proxy[1]}) def validate_proxy(proxy): try: res = requests.get( "https://libvio.link/api/ping", proxies={"https": f"https://{proxy}"}, timeout=5 ) return res.status_code == 200 except: return False
三、高效数据抓取架构设计
1. 任务调度系统
采用"主从分布式架构",支持断点续爬与优先级队列:
| 组件 | 技术选型 | 核心功能 |
|---|---|---|
| 任务队列 | Celery + RabbitMQ | 支持任务优先级(1-5级)、定时任务 |
| 存储层 | MongoDB + Redis | 原始数据存储与去重缓存(Bloom Filter) |
| 监控面板 | Prometheus + Grafana | 请求成功率、IP健康度、任务完成率实时监控 |
2. 动态IP切换策略
根据响应状态码动态调整代理权重:
def adjust_proxy_score(proxy, success): current_score = r.zscore('proxies', proxy) or 50 if success: new_score = min(current_score + 2, 100) else: new_score = max(current_score - 5, 0) r.zadd('proxies', {proxy: new_score}) if new_score == 0: r.zrem('proxies', proxy) # 剔除无效代理
3. 反反爬策略矩阵
| 反爬类型 | 应对方案 | 实施难度 | 成功率 |
|---|---|---|---|
| JS加密参数 | 动态执行环境 + 内存dump | ★★★★☆ | 92% |
| 滑动验证码 | 基于CNN的图像识别(OpenCV+PyTorch) | ★★★★★ | 78% |
| 行为检测 | 随机轨迹生成(贝塞尔曲线模拟) | ★★☆☆☆ | 85% |
| IP封禁 | 分布式代理池 + 流量调度 | ★★★☆☆ | 90% |
四、实战案例:热门影视数据抓取
1. 目标分析
抓取目标:Libvio.link的"本周热门"板块(URL: https://libvio.link/trending?page=1)
核心字段:标题、评分、播放量、资源链接
2. 完整代码实现
from playwright.sync import sync_playwright import json import time from redis import Redis from celery import Celery app = Celery('tasks', broker='pyamqp://guest@localhost//') r = Redis(host='localhost', port=6379, db=0) @app.task def crawl_trending(page_num): context = create_browser_context() # 复用前文浏览器配置 page = context.new_page() # 动态生成请求参数 timestamp = int(time.time()) params = { "page": page_num, "t": timestamp, "sign": sign_request({"page": page_num, "t": timestamp}, get_secret_key()) } # 带指纹访问 page.goto(f"https://libvio.link/trending?{urllib.parse.urlencode(params)}") page.wait_for_selector(".content-list") # 提取数据 data = page.evaluate("""() => { return Array.from(document.querySelectorAll('.content-item')).map(item => ({ title: item.querySelector('.title').textContent, score: item.querySelector('.score').textContent, views: item.querySelector('.views').textContent, url: item.querySelector('a').href })); }""") # 数据去重与存储 for item in data: if not r.sismember('crawled_urls', item['url']): r.sadd('crawled_urls', item['url']) with open('trending_data.jsonl', 'a') as f: f.write(json.dumps(item) + '\n') context.close() return f"Page {page_num} crawled: {len(data)} items" # 批量启动任务 for i in range(1, 10): crawl_trending.delay(i)
3. 反爬对抗关键点
- 验证码自动处理:集成ddddocr实现滑动验证码识别
- 动态等待策略:使用page.wait_for_load_state('networkidle')替代固定延迟
- 异常恢复机制:捕获TargetClosedError时自动重启浏览器上下文
五、Prompt工程:大模型辅助反爬
1. JS逆向提示词示例
任务:分析以下JS代码片段,提取__lt__函数的密钥生成逻辑。 代码:[此处插入混淆JS] 要求: 1. 识别关键加密算法(如SHA256/AES) 2. 定位密钥依赖的环境变量(如时间戳、浏览器指纹) 3. 生成Python等价实现代码
2. 反爬策略优化提示词
场景:Libvio.link爬虫频繁触发403,已排除IP问题。 日志:[附上最近10条失败请求的headers与响应] 分析方向: 1. 请求头是否存在缺失字段? 2. Cookie时效性是否过短? 3. 是否触发了行为检测规则? 请提供具体修改建议。
六、总结与展望
Libvio.link的反爬体系代表了当前动态网站的典型防御水平,其核心难点在于前端环境真实性验证与行为模式识别。未来对抗将更依赖AI驱动的动态模拟技术(如基于强化学习的行为生成)与去中心化爬取网络(如P2P节点池)。
作为开发者,需在技术突破与合规采集间寻求平衡——建议通过官方API申请数据访问权限,或采用"低频率+模拟人类行为"的温和抓取策略。毕竟,可持续的数据获取能力,远比一次性的技术突破更具价值。
思考问题:当网站采用联邦学习(Federated Learning)更新反爬模型时,传统规则式爬虫将面临怎样的挑战?我们又该如何构建自适应对抗系统?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献309条内容
已为社区贡献309条内容

所有评论(0)