高级 RAG 技术指南助力提升生成式AI应用(介绍篇)
高级 RAG 的本质目标,不是“让模型多查点资料”,而是构建一套能够支撑企业级洞察深度、响应速度和可信度的 AI 供数体系。
一、为什么企业必须走向高级 RAG
大语言模型在企业场景中的价值,并不取决于模型本身有多强,而取决于是否能够持续、准确地获取企业内部的真实数据。
LLM 天生存在知识固化、易产生幻觉、无法感知实时变化和领域细节等问题,这决定了它不能直接作为企业知识与决策的“最终来源”。
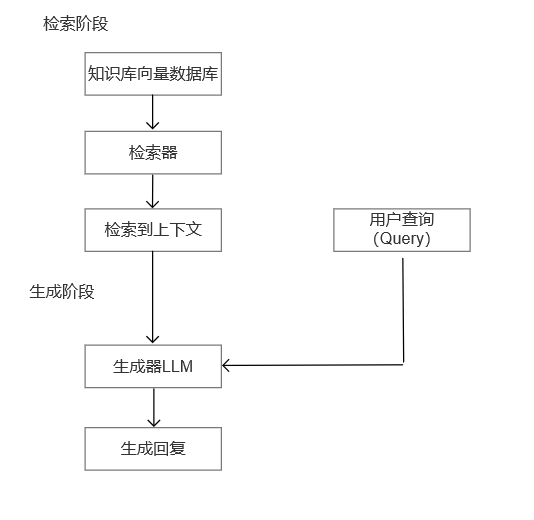
RAG(检索增强生成)通过引入外部知识库,为模型提供“可控、可追溯”的事实支撑,是企业落地大模型的基础路径。但在实际应用中,基础 RAG(仅做文档向量化 + 相似度搜索)很快就会触碰天花板。
在检索层面:
基础 RAG 容易出现信息遗漏、召回不全、排序失真,尤其在长文档、多条件、多跳(Multi-hop)推理等复杂问题下,模型往往“抓到相关但用不上”的内容,甚至出现“中间信息丢失”的问题;
在生成层面:
受限于上下文窗口和碎片化输入,模型难以对多个证据片段进行有效整合,幻觉问题并未被根本消除;
在数据层面:
如果底层数据本身过时、杂乱、缺乏结构和语义约束,再复杂的 RAG 设计也只是在放大噪声。
高级 RAG 的本质目标,不是“让模型多查点资料”,而是构建一套能够支撑企业级洞察深度、响应速度和可信度的 AI 供数体系。
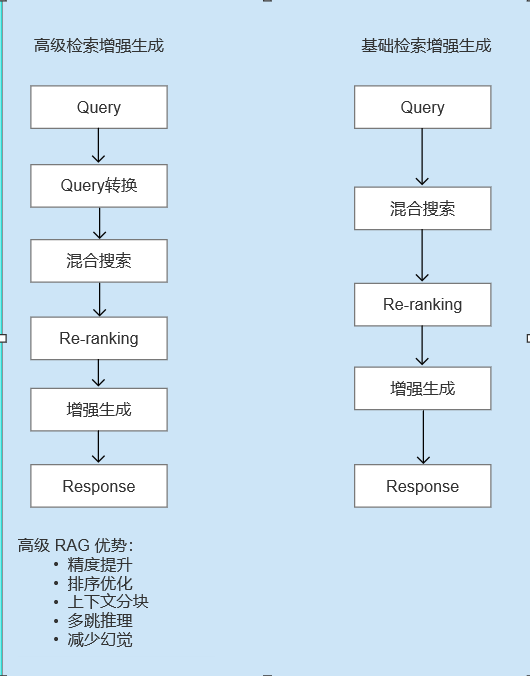
二、核心技术框架:从“能用”到“可规模化”的 RAG 演进
1、地基能力:数据预处理决定 RAG 的上限
在高级 RAG 架构中,数据预处理并不是附属环节,而是决定整体能力上限的核心工程。
这一步往往不显山露水,却直接影响后续检索、推理和生成的全部效果。
首先是数据摄入能力。企业级 RAG 必须具备打通数据孤岛的能力,支持从云存储、协作平台、业务系统等多源接入数据,并在摄入阶段同步保留作者、时间、来源、权限等关键元数据,同时支持增量更新,避免“一次性导入、长期失效”。
其次是文档结构化处理。不同于简单的全文切分,高级 RAG 会将 PDF、Word、PPT 等文档解析为段落、表格、图片等结构化元素,最大限度保留原始语义结构,避免因扁平化处理导致的信息语境丢失。
在此基础上,分块策略(Chunking)成为影响检索效果的关键变量。固定长度分块虽然实现简单,但在企业场景中往往破坏语义完整性。更优的做法是采用结构感知或语义感知分块方式,例如按标题层级、页面结构或语义相似度进行分块,在精准度和上下文完整性之间取得平衡。
为了进一步提升可检索性,高级 RAG 通常会引入增强处理机制:
1)通过为每个分块补充父文档摘要,减少碎片化带来的语义断裂;
2)通过多模态模型将图片、表格转化为可搜索的文本描述;
3)通过命名实体识别提取关键实体及其关系,为后续构建知识图谱和图检索奠定基础。
最终,这些经过治理和增强的数据会被转化为向量并建立索引,成为 RAG 可持续演进的“知识底座”。
2、能力升级:从“找到内容”到“找到正确内容”
解决基础 RAG 检索不准的问题,核心不在于“搜更多”,而在于**“更好地理解查询意图,并对候选结果进行再判断”**。
重排序机制是高级 RAG 中最具性价比的能力升级方式。通过先用向量搜索召回候选片段,再利用交叉编码器或 LLM 对结果进行精细化打分,可以有效解决“语义相似但实际无关”的问题,显著提升最终命中率。
混合搜索是对企业复杂语言环境的现实回应。向量搜索擅长捕捉语义相似性,但在缩写、专有名词、编码类字段等场景下表现有限。将向量搜索与关键词检索(如 BM25)结合,可以同时覆盖“语义理解”和“精确匹配”两类需求。
元数据过滤是企业级 RAG 中经常被低估、却极其关键的一环。通过时间范围、文档类型、组织归属、权限标签等条件进行预过滤,既可以显著压缩搜索空间、降低成本,也为后续的权限控制和审计提供基础能力。
在复杂问题场景下,父文档检索与查询转换能力尤为重要。前者通过“先精确、再补全”的方式保证答案完整性,后者则利用 LLM 对用户问题进行澄清、拆解和重写,使检索更贴合企业数据的实际表达方式。
进一步向前,高级 RAG 会引入图谱 RAG 和智能体 RAG。
图谱RAG 通过实体与关系进行检索,更适合多跳推理和因果分析;
智能体 RAG 则让模型具备“策略决策能力”,能够根据问题复杂度动态决定是否多轮检索、是否调用外部工具,从而适配开放性和探索性任务。
3、工程视角:没有“最优方案”,只有“最适组合”
高级 RAG 的建设不存在一套通吃所有场景的标准答案,关键在于根据数据形态、业务复杂度和成本约束进行组合设计。
结构化程度高的文档适合按标题或章节分块,扫描件和表单更适合按页面分块,而高度非结构化内容则需要结合基础分块与上下文增强策略。
在存储层面,单一语义检索场景可采用向量数据库,多类型查询可引入搜索引擎,复杂关系推理则需要图数据库支持。
在多数企业场景中,“元数据过滤 + 上下文分块 + 重排序”构成了一套投入产出比极高的基础组合;而 Graph RAG 与 Agentic RAG 更适合在对可解释性和复杂推理有明确需求时逐步引入。
三、RAG 正在成为企业 AI 的“供数中枢”
随着模型能力提升,RAG 的演进方向正在发生变化。
单纯扩大上下文窗口并不能解决问题,反而可能引入更多噪声和成本,精准分块和高质量检索仍然不可替代。
未来的 RAG 将与智能体深度融合,由智能体负责任务规划和决策,由 RAG 提供稳定、可信的数据支持,形成“规划—检索—生成”的闭环。
多模态检索、跨会话记忆、身份感知检索等能力,也将逐步成为企业级 RAG 的标配。
真正的分水岭在于:RAG 是否从“技术试验”走向“生产系统”。
这要求其在安全、权限、可观测性和成本控制等方面具备工程级能力,而不仅仅是模型效果的提升。
四、未来的竞争焦点
高级 RAG 的核心不在模型,而在数据治理与检索工程。它不是单点技术升级,而是一套面向企业复杂场景的系统性组合,而且工具选型必须服务于业务与数据特征,而非追逐概念。未来的竞争焦点,将从“能不能用”转向“是否真正可持续、可规模化”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)