深度学习的补充:训练模型(优化器&调度器&保存模型)&批量测试(模型加载)&残差网络(迁移学习)的引入
首先预处理,因为我们当时训练模型就是在数据标准上训练的,所以模型适应标准化的图片,这里测试输入的测试图片也要经过尺寸和标准化的处理,是为了适应模型,像之前的旋转等操作因为哪些操作是用来训练模型的,这里就不需要了。上面我们训练好并保存下了最优模型,下一步就是要测试,这里就会涉及到模型的使用,方面和模型保存进行对应,所以我们先来介绍模型的使用方法,之后再进行测试。和训练模型的时候结构是差不多的,但因为
一、接上文
上文中最后提到优化器和调度器以及模型的保存
1.优化器
优化器有很多种,通常我们使用的就是SGD和Adom,但通常都是Adom效果更好一些。
model.parameters(),返回模型所有需要训练的参数
optimizer = torch.optim.SGD(model.parameters(),lr=0.001)
optimizer = torch.optim.Adam(params_to_update, lr=0.001)(注意:由于torch版本的原因,使用优化器的时候有些不用导入模块,但有些时候必须需要 导入 import torch.optim as optim)
2.调度器
调度器分为三类:有序调整(按计划调整),自适应调整(看表现调整),自定义调整(自己写规则)。此外我们可以给不同层设置不同的学习率,使用列表实现。
1)有序调整(使用较多)
StepLR : 等间隔下降 ,每10轮减半。
上文我们使用的就是这个,里面参数含义,第一,是我们需要调整的优化器对象;第二,步长,设置多少轮调整一次学习率;第三,衰减因子,调整的倍数(新lr=旧lr * gamma)
StepLR(optimizer, step_size=10, gamma=0.5)MultiStepLR:多时间点下降,在第10、30、80轮调整。
MultiStepLR(optimizer, milestones=[10,30,80], gamma=0.1)ExponentialLR :指数衰减 ,每轮都衰减。
ExponentialLR(optimizer, gamma=0.95)CosineAnnealingLR :余弦退火 ,先降后升。
CosineAnnealingLR(optimizer, T_max=50)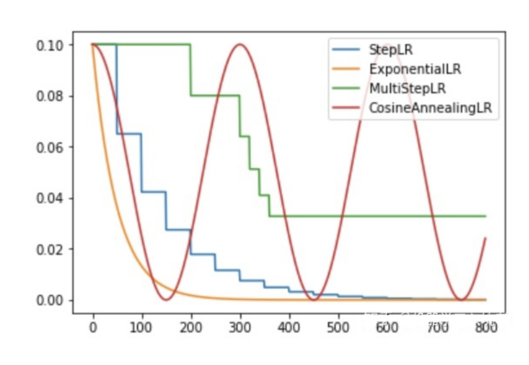
2)自适应调整
ReduceLROnPlateau :监控指标 ,当loss连续5轮不下降就调整。mode不写默认为min。是min还是max,这个是要看训练函数具体的返回值如果是损失值,那就是min,如果是正确率那就是max,所以使用这个调度器我们的的训练函数必须要有返回值。
patience:指标连续多少轮不改善才触发调整。
factor:学习率调整的倍数,就和gamma一个意思。
verbose就是让调度器打印调整信息。
ReduceLROnPlateau(optimizer, mode='max', patience=5, factor=0.1, verbose=True)注意:使用的时候,scheduler.step(指标) , 要传入监控的指标。
3)自定义调整
# LambdaLR - 自定义函数
lambda1 = lambda epoch: 0.95 ** epoch # 指数衰减
scheduler = LambdaLR(optimizer, lr_lambda=lambda1)(调度器也是一样的有时候会需要导入模块
from torch.optim.lr_scheduler import StepLR
from torch.optim.lr_scheduler import ReduceLROnPlateau。
但是调度器比优化器不同的是,如果我们使用调度器是直接用比如scheduler = StepLR(...)就需要导入模块,但是如果我们写scheduler = torch.optim.lr_scheduler.StepLR(...)就不需要导入模块,当然了ReduceLROnPlateau也是这样)
3.保存模型(两种方法)
首先我们需要知道的是一般模型文件的后缀是pt、pth、t7
1)第一种模型保存方式:path是保存到的路径包括我们给这个模型文件起的名字。
这种保存方法保存的只有模型的参数。
torch.save(model.state_dict(),path)
2)第二种模型保存方式:path和上面一样
这种保存方法是保存完整的模型不仅仅是权重w,网络模型也被保存。
torch.save(model,path)4.使用模型
上面我们训练好并保存下了最优模型,下一步就是要测试,这里就会涉及到模型的使用,方面和模型保存进行对应,所以我们先来介绍模型的使用方法,之后再进行测试
1)针对只保存了参数的模型文件,我们使用:
model = CNN() #创建模型结构
model.load_state_dict(torch.load(path)) 需要注意的是,加载模型的之前我们需要创建模型结构
2)针对保存完整的模型文件,我们使用:
model = torch.load(path)这里就不需要创建模型结构了,当然了关于使用会有一些小问题在里面,我们会在讲到具体问题的时候解决
二、批量测试
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
import torch.nn as nn和训练模型的时候结构是差不多的,但因为我们是测试所以不需要训练,关于train的一些代码可以删除,数据预处理,读取图片,测试函数
首先预处理,因为我们当时训练模型就是在数据标准上训练的,所以模型适应标准化的图片,这里测试输入的测试图片也要经过尺寸和标准化的处理,是为了适应模型,像之前的旋转等操作因为哪些操作是用来训练模型的,这里就不需要了。总的来说就可以直接用训练函数中的预处理。
#测试集预处理
data_transforms = transforms.Compose([
transforms.Resize([256, 256]), # 测试时就直接缩放到256x256
transforms.ToTensor(), # 转成张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
读取图片这个类也可以直接拿过来用,都是不变的
# 读取图片
class food_dataset(Dataset):
def __init__(self, file_path, transform=None): # 从train.txt或test.txt读取图片路径和标签
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split() for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self): # 返回数据集大小
return len(self.imgs)
def __getitem__(self, idx): # 读取图片,如果有transform就处理,返回图片和标签
image = Image.open(self.imgs[idx])
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = int(label)
label = torch.from_numpy(np.array(label, dtype=np.int64))
return image, label
测试函数就需要修改一下,为了我们之后运行能对比测试结果和真实结果我们定义两个列表用来分别存真是标签和预测标签,然后再加一些输出,就修改这些。
# 测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batchs = len(dataloader)
model.eval()#w进入测试模式,没有再被修改的权限
test_loss, correct = 0, 0
all_true_labels=[]
all_pred_labels=[]
with torch.no_grad():#上下文管理器,关闭梯度计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()
pred_labels=pred.argmax(1)#从模型输出中提取预测的类别标签
correct +=(pred_labels==y).type(torch.float).sum().item()
#这里是把在gpu上的标签收集到cpu列表中去
all_true_labels.extend(y.cpu().numpy())
all_pred_labels.extend(pred_labels.cpu().numpy())
test_loss /= num_batchs
correct /= size
accuracy = 100 * correct
print(f"Test result: \n Accuracy :{accuracy:.2f}%, Avg loss:{test_loss:.4f}")
print("\n标签对比:")
print(f"真实标签: {all_true_labels[:20]}...") # 显示前20个
print(f"预测标签: {all_pred_labels[:20]}...")
print(f"总样本数: {len(all_true_labels)}")
return accuracy然后就是CNN的定义,这里CNN的定义和我们加载模型也是有点关系牵扯的
(一)首先我们先说使用只保存参数的模型文件,那我们定义的CNN结构都要和训练函数时要完全一模一样(直接拿过来使用)这里就省略,可以参考上文
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
………………
# 数据加载
test_data = food_dataset(file_path=r'.\testda.txt', transform=data_transforms)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
# 第一种
model=CNN().to(device)
model.load_state_dict(torch.load('模型文件'))
model.eval()#固定模型参数和数据,防止后面被修改
# 损失函数
loss_fn = nn.CrossEntropyLoss()
accuracy=test(test_dataloader,model,loss_fn)输出:
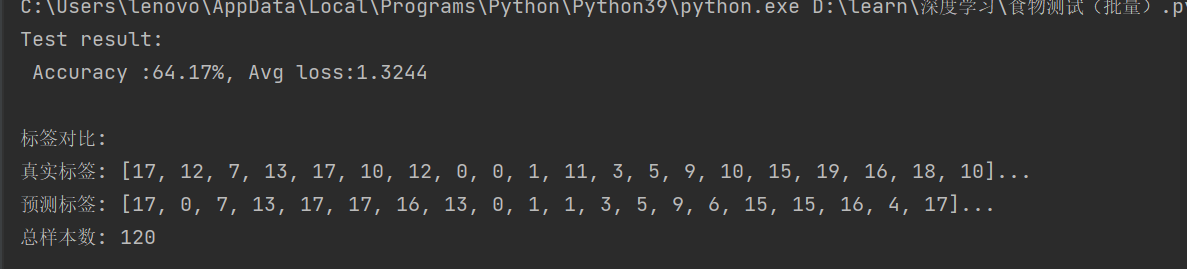
(二)如果我们使用保存完整模型的模型文件
CNN的定义就不需要全部复刻了,我们完全可以写成下面这样
是需要初始化并且保证forward和训练模型中的forward一模一样。
此外,weights_only=True, 只加载张量数据; weights_only=False 允许加载任意Python对象。这里我们要加载完整模型,不仅仅只有参数,所以要False
其次,指定加载到哪个设备: map_location='cpu' ,加载到CPU; map_location='cuda' ,加载到GPU ; map_location=device ,根据你的device变量决定
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
def forward(self, x): # 前向传播:卷积->展平->全连接
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
# 数据加载
test_data = food_dataset(file_path=r'.\testda.txt', transform=data_transforms)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
#第二种
model=torch.load("模型文件", weights_only=False, map_location=device)
model.eval()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
accuracy=test(test_dataloader,model,loss_fn)加载这个完整模型文件的时候自动就会使用其中网络结构,我们就不用再写一遍。
写也是可以的,但无论你写什么,写的和训练的时候不一致,或者多一层网络少一层都不会报错,因为根本不会识别这个网络结构。
不过要注意,初始化是不可以省略的,forward要一样的目的就是保证层数和模型文件中是一致的。这两点不对就会报错。
结果:
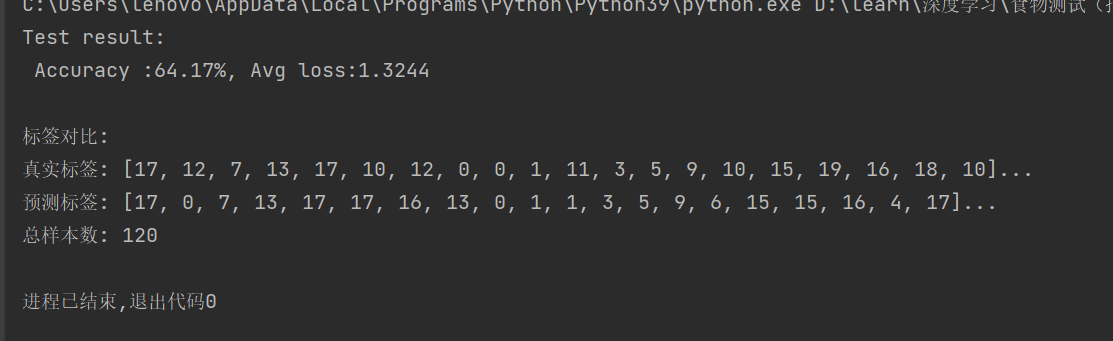
三、引入
根据上面的测试我们发现,我们的正确率60多虽然比之前好太多,但是还是有些低的,因为我们的目的是最终能用在实际生活中。
所以我们需要继续提高正确率,换一种网络模型?那就是残差网络,因为残差网络对图片的处理能力比较强。
我们也可以使用别人训练好的模型,这样我们在别人的模型基础上把所有算力都用在改善上,就不用把算力浪费在基础模型的训练上,既浪费时间正确率又不高。这里我们就要提到一种方法,迁移学习。
迁移学习和残差网络结合使用,在别人训练好的残差模型上修改适应我们的目的,这样最后得到的模型正确率就会高很多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)