Docker+NVIDIA Container Toolkit+Ray+vLLM单卡3090单容器分布式联合运行Qwen3-4B-Instruct-2507模型
Docker+NVIDIA Container Toolkit+Ray+vLLM单卡3090单容器分布式联合运行Qwen3-4B-Instruct-2507模型
·
文章目录
零 实验软硬件环境说明
- 📋 实验环境配置表
| 分类 | 项目 | 配置详情 | 备注 |
|---|---|---|---|
| 硬件环境 | CPU | e5 2696V3(逻辑核心数>=16) | 启动时分配8 cores 给 Ray |
| 物理内存 (RAM) | 32 GB | 关键瓶颈,需要精细规划共享内存 | |
| GPU | NVIDIA GeForce RTX 3090 x 2 | 单卡 24GB VRAM | |
| 网络 | 无线网卡 (USB) | wlxe0ad47220334 |
|
| 操作系统 | OS 发行版 | Ubuntu 24.04 LTS | 内核版本 6.14.0-37-generic |
| 宿主机 IP | 10.193.195.59(机器正常活动网卡) | 无线网络 IP,作为集群通信地址 | |
| 基础软件 | Docker 管理 | 1Panel | 开源 Linux 服务器运维管理面板 |
| NVIDIA 驱动 | 570.211.01 | 支持 CUDA 12.8 | |
| Docker 网络 | Host 模式 (--network host) |
容器与宿主机共享网络栈,性能最优 | |
| 核心环境 | 基础镜像 | ray-vllm:3090-cuda12.8 |
包含 Ray, vLLM, CUDA 12.8 |
| Python | 3.12.3 | Ray 脚本路径显示 | |
| 集群配置 | Ray 版本 | 2.53.0 | 支持 ray metrics launch-prometheus |
| 集群架构 | Head Node + Worker Node (双容器) | ray-node-0 (Head), ray-node-1 (Worker) |
|
| 通信端口 | 6379 (GCS), 8265 (Dashboard), 8080 (Metrics) | 确保 6379 未被 Redis 占用 | |
| 资源分配 | GPU 策略 | 独占模式 | --gpus all + NVIDIA_VISIBLE_DEVICES=0/1 |
| 共享内存 | 12 GB / 容器 | 物理内存 32GB 下的折中方案 | |
| 内存优化 | Memfd 启用 | 环境变量 VLLM_USE_MEMFD=1 绕过 /dev/shm 限制 |
|
| 监控栈(未成功实践) | Prometheus | v3.9.1 | 由 ray metrics 自动安装,运行于宿主机 |
| Grafana | Latest (Docker) | 运行于宿主机,数据源连接 Prometheus | |
| Dashboard | Ray Dashboard | http://10.193.195.59:8265 |
一 核心架构
- 宿主机(Ubuntu24.04+双3090)部署2个Docker容器,单容器独占1张3090,通过
--gpus device=N精准绑定显卡;容器内搭建Ray分布式集群(1主1从),基于vLLM实现4B大模型的分布式推理/部署,全程保留宿主机3090的可视化使用,无需GPU直通,兼顾开发操作与算力利用。 - 适配性:单张3090(24G显存)满足8B模型(FP16约16G/INT4约4G)的显存要求,vLLM的PagedAttention技术进一步降低显存占用,双容器分布式可提升推理吞吐量/并发量。
前置条件
- 宿主机已装Ubuntu24.04图形版,双3090显卡正常识别,开启基础虚拟化(BIOS的VMX)。
- 宿主机已装NVIDIA官方驱动(≥535,建议545/550),验证:
nvidia-smi能正常显示双3090。 - 宿主机网络正常,能拉取Docker镜像,建议换国内镜像源。
二 Docker和NVIDIA Container Toolkit准备
2.1 Docker环境准备
- 运行安装1panel脚本,以root用户身份运行一键安装脚本,自动完成1Panel的下载和安装。安装过程会顺带安装docker相关组建,方便省事,同时还可以可视化管理服务器。更详细设置参看1Panel文档。
bash -c "$(curl -sSL https://resource.fit2cloud.com/1panel/package/v2/quick_start.sh)"
- 可以在1panel容器管理面板添加镜像代理。
https://docker.1ms.run
https://swr.cn-north-4.myhuaweicloud.com
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04 docker.io/nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04
2.2 NVIDIA Container Toolkit环境准备
- NVIDIA Container Toolkit的配置主要参考以下两片文章。
# 1 安装依赖
sudo apt-get update
sudo apt-get install -y curl
# 2 添加密钥和仓库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 3执行安装
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# 4更新Docker配置
sudo nvidia-ctk runtime configure --runtime=docker
# 5 重启Docker服务
sudo systemctl restart docker
三 定制化Docker镜像
- 基于
nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04基础镜像(适配 3090,兼容 Ubuntu24.04),构建包含Python3.10+Ray+vLLM + 依赖库的定制镜像,确保双容器环境一致,避免版本冲突。
3.1 构建镜像存放位置,保持和1panel存放位置一致。
cd /opt/1panel/apps/
mkdir RayCuda
3.2 创建 Dockerfile文件
cd RayCuda
vim Dockerfile
# 基础镜像:CUDA 12.8.1 + CUDNN+ Ubuntu 24.04(适配3090,兼容vLLM/Ray)
FROM nvidia/cuda:12.8.1-cudnn-devel-ubuntu24.04
# 第一步:修复NVIDIA GPG密钥警告,刷新apt缓存
# 备注:迁移NVIDIA GPG密钥到新的keyring,消除弃用警告,同时刷新官方源缓存
RUN mkdir -p /etc/apt/trusted.gpg.d && \
cp /etc/apt/trusted.gpg /etc/apt/trusted.gpg.d/nvidia-cuda.gpg && \
apt update && \
apt clean && \
rm -rf /var/lib/apt/lists/*
# 第二步:安装基础依赖
RUN apt update && apt install -y --no-install-recommends \
python3-dev python3-pip \
git wget vim net-tools iputils-ping \
&& rm -rf /var/lib/apt/lists/*
# 第三步:直接配置国内PyPI源
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 第四步:安装Ray(分布式核心,2.53.0稳定版,兼容Python3.11/CUDA 12.8)
RUN pip install ray[default,serve]==2.53.0 -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages
# 第五步:安装vLLM(大模型推理,适配CUDA 12.8,添加--break-system-packages解决ubuntu24.4报错)
RUN pip install vllm[all] -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages
# 第六步:安装PyTorch(适配CUDA 12.8,使用官方whl包)
RUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128 --break-system-packages && \
pip install transformers accelerate sentencepiece -i https://pypi.tuna.tsinghua.edu.cn/simple --break-system-packages
# 第七步:设置CUDA 12.8环境变量,确保依赖能找到CUDA路径
ENV CUDA_HOME=/usr/local/cuda-12.8
ENV PATH=$CUDA_HOME/bin:$PATH
ENV LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH
# 工作目录
WORKDIR /root/ray-vllm
3.3 构建 Docker 镜像
- 进入Dockerfile所在目录,执行构建命令,镜像命名为ray-vllm:3090-cuda12.8。构建时间约10分钟,全程无报错即成功。
cd /opt/1panel/apps/RayCuda
docker build -t ray-vllm:3090-cuda12.8 .
3.4 启动双 Docker 容器(单容器单3090,桥接网络)
- 创建2个容器,分别绑定3090-0(第1张)和3090-1(第2张)显卡,使用桥接网络(容器与宿主机/容器间同一网段,Ray集群通信必备),同时映射端口(Ray仪表盘/LLM推理端口)。
- 启动主节点容器(ray-node-0)绑定 GPU 0;启动从节点容器(ray-node-1)绑定 GPU 1。执行以下命令,创建并启动主从节点容器,分别独占 3090-0和3090-1,桥接网络,映射 Ray(6379/8265)和 vLLM(8000)端口。
# 容器 1 - 使用第一张卡 (GPU 0)
docker run -itd \
--name ray-node-0 \
--gpus device=0 \
--network host \
--privileged \
--shm-size=12g \
-e VLLM_USE_MEMFD=1 \
-e NVIDIA_VISIBLE_DEVICES=0 \
-v /opt/1panel/apps/RayCuda/ray-vllm-data-0:/root/ray-vllm/data \
ray-vllm:3090-cuda12.8 /bin/bash
# 容器 2 - 使用第二张卡 (GPU 1)
docker run -itd \
--name ray-node-1 \
--gpus device=1 \
--network host \
--privileged \
--shm-size=12g \
-e VLLM_USE_MEMFD=1 \
-e NVIDIA_VISIBLE_DEVICES=1 \
-v /opt/1panel/apps/RayCuda/ray-vllm-data-1:/root/ray-vllm/data \
ray-vllm:3090-cuda12.8 /bin/bash
3.5 验证容器状态
- 说明:由于NVIDIA Container Toolkit的特殊机制,在但容器内使用nvidia-smi命令可以查看到两个GPU,这是正常现象,但通过
env | grep NVIDIA可以验证可以使用的GPU,重点以此来验证容器内GPU隔离的成功。 - 主节点容器状态验证
docker exec -it ray-node-0 bash
# 在容器内重新设置可用GPU变量才生效
export CUDA_VISIBLE_DEVICES=0
python3 -c "import torch; print('Node0:', torch.cuda.device_count())"
env | grep NVIDIA
exit
(base) root@yang-server:/opt/1panel/apps/RayCuda# docker exec -it ray-node-0 bash
root@yang-server:~/ray-vllm# python3 -c "import torch; print('Node0:', torch.cuda.device_count())"
Node0: 2
root@yang-server:~/ray-vllm# export CUDA_VISIBLE_DEVICES=0
root@yang-server:~/ray-vllm# python3 -c "import torch; print('Node0:', torch.cuda.device_count())"
Node0: 1
root@yang-server:~/ray-vllm# env | grep NVIDIA
NVIDIA_VISIBLE_DEVICES=0
- 从节点容器状态验证。
docker exec -it ray-node-1 bash
# 在容器内重新设置可用GPU变量才生效
export CUDA_VISIBLE_DEVICES=1
python3 -c "import torch; print('Node1:', torch.cuda.device_count())"
env | grep NVIDIA
exit
(base) root@yang-server:~# docker exec -it ray-node-1 bash
root@yang-server:~/ray-vllm# export CUDA_VISIBLE_DEVICES=1
root@yang-server:~/ray-vllm# python3 -c "import torch; print('Node1:', torch.cuda.device_count())"
Node1: 1
root@yang-server:~/ray-vllm# env | grep NVIDIA
NVIDIA_VISIBLE_DEVICES=1
四 搭建 Ray 分布式集群
- 分布式集群为双容器(1 主 1 从),每个容器内只有一张GPU可以使用。
4.1 确定宿主机IP(集群通信地址)
- 在宿主机终端执行ip地址查看命令。
ip addr
(base) root@yang-server:~# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp5s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 00:e0:21:9d:65:a0 brd ff:ff:ff:ff:ff:ff
3: wlxe0ad47220334: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e0:ad:47:22:03:34 brd ff:ff:ff:ff:ff:ff
inet 10.193.195.59/17 brd 10.193.255.255 scope global dynamic noprefixroute wlxe0ad47220334
valid_lft 75329sec preferred_lft 75329sec
inet6 fe80::5076:b18f:9e57:fbdc/64 scope link noprefixroute
valid_lft forever preferred_lft forever
10.193.195.59(网卡wlxe0ad47220334)- 状态:
state UP(正在运行) - 类型:无线网卡 (以
wl开头) - 理由:处于 UP 状态且拥有正常互联网 IP 地址**的网卡。Ray 集群的节点之间需要通过这个 IP 进行通信。
- 状态:
192.168.x.x(有线网卡enp5s0)- 状态:
state DOWN(已断开) - 理由:有线网卡目前没有连接网线或者没有获取到 IP,所以无法使用。
- 状态:
4.2 主节点启动Ray Head节点
- 注意关闭宿主机上6379端口Redis的服务。
- 进入主节点容器,启动 Ray Head 节点。
node-ip-address请根据实际情况使用上一步,查询到的可用IP。
# 进入主节点容器
docker exec -it ray-node-0 bash
# 启动Ray Head节点
ray start --head \
--node-ip-address=10.193.195.59 \
--port=6379 \
--dashboard-host=0.0.0.0 \
--num-cpus=8 \
--num-gpus=1
- 启动成功标志:终端输出Ray runtime started.,并显示从节点连接命令。
4.3 从节点容器加入Ray集群
- 进入从节点容器,加入 Ray 集群,
address需要填写主节点给出的连接IP10.193.195.59:6379。
# 进入从节点容器
docker exec -it ray-node-1 bash
# 启动Ray从节点
ray start --address='10.193.195.59:6379' --node-ip-address='10.193.195.59' --num-cpus=8 --num-gpus=1
- 成功标志:终端输出
Worker node connected to head node。
4.4 验证Ray集群状态
- 在主节点容器内,查看ray集群状态。
# 进入主节点容器
docker exec -it ray-node-0 bash
# 查看集群节点
ray status
# 输出:2个节点(head+worker),每个节点1个GPU,总计2个GPU/32个CPU
root@yang-server:~/ray-vllm# ray status
======== Autoscaler status: 2026-01-29 05:14:29.925034 ========
Node status
---------------------------------------------------------------
Active:
1 node_b4f370771c977c241f30a026e0c9ddfb4ee38a38d01eb731f9f72efd
1 node_802f333067990b56926977df9b233c5fa021783653ba92413e0a36ca
Resources
---------------------------------------------------------------
Total Usage:
0.0/16.0 CPU
0.0/2.0 GPU
0B/42.89GiB memory
0B/18.38GiB object_store_memory
4.5 查看Ray仪表盘
- 可视化验证:宿主机浏览器打开
http://localhost:8265,进入 Ray 仪表盘,在Cluster能看到 2 个节点,GPUs 显示 2,即集群搭建成功。(每个节点虽然显示两个GPU,但实际只使用一个GPU)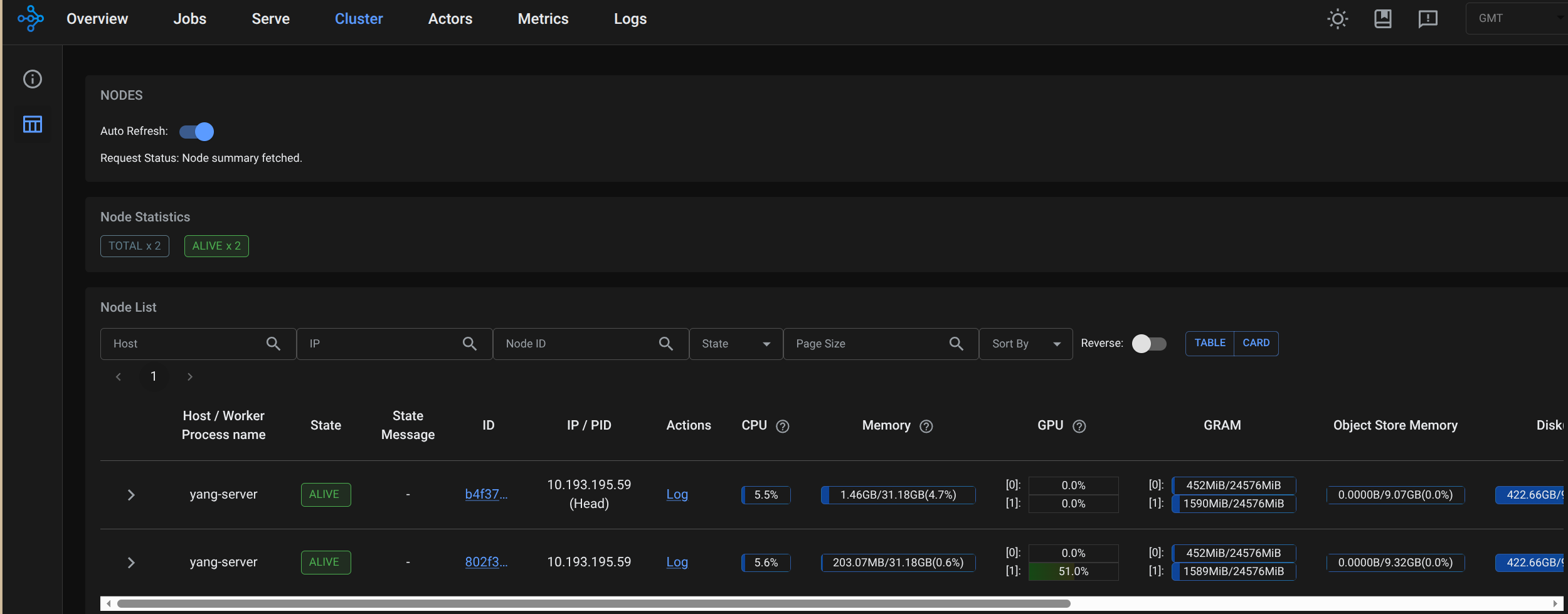
4.6 节点内验证Ray集群状态
- 在主节点挂在目录
/opt/1panel/apps/RayCuda/ray-vllm-data-0/,创建测试脚本。
cd /opt/1panel/apps/RayCuda/ray-vllm-data-0/
vim check_resources.py
- 填入脚本内容。
import ray
# 连接到 Ray 集群
ray.init(address='auto', _node_ip_address='10.193.195.59')
# 获取集群资源
cluster_resources = ray.cluster_resources()
available_resources = ray.available_resources()
print("--- 集群总资源 ---")
for resource, value in cluster_resources.items():
print(f"{resource}: {value}")
print("\n--- 可用资源 ---")
for resource, value in available_resources.items():
print(f"{resource}: {value}")
# 获取所有节点
nodes = ray.nodes()
print(f"\n--- 节点数量: {len(nodes)} ---")
for node in nodes:
print(f"节点 ID: {node['NodeID']}")
print(f"节点 IP: {node['NodeManagerAddress']}")
print(f"节点资源: {node['Resources']}")
print("---")
# 断开连接
ray.shutdown()
- 执行脚本,可以清楚地看到每个容器内的GPU数量为1。
root@yang-server:~/ray-vllm/data# python3 check_resources.py
2026-01-29 05:35:34,420 INFO worker.py:1821 -- Connecting to existing Ray cluster at address: 10.193.195.59:6379...
2026-01-29 05:35:34,434 INFO worker.py:1998 -- Connected to Ray cluster. View the dashboard at http://10.193.195.59:8265
/usr/local/lib/python3.12/dist-packages/ray/_private/worker.py:2046: FutureWarning: Tip: In future versions of Ray, Ray will no longer override accelerator visible devices env var if num_gpus=0 or num_gpus=None (default). To enable this behavior and turn off this error message, set RAY_ACCEL_ENV_VAR_OVERRIDE_ON_ZERO=0
warnings.warn(
--- 集群总资源 ---
object_store_memory: 19738098892.0
GPU: 2.0
CPU: 16.0
accelerator_type:G: 2.0
memory: 46055564084.0
node:10.193.195.59: 2.0
node:__internal_head__: 1.0
--- 可用资源 ---
object_store_memory: 19738098892.0
GPU: 2.0
CPU: 16.0
node:10.193.195.59: 2.0
accelerator_type:G: 2.0
memory: 46055564084.0
node:__internal_head__: 1.0
--- 节点数量: 2 ---
节点 ID: b4f370771c977c241f30a026e0c9ddfb4ee38a38d01eb731f9f72efd
节点 IP: 10.193.195.59
节点资源: {'memory': 22714964788.0, 'object_store_memory': 9734984908.0, 'node:__internal_head__': 1.0, 'accelerator_type:G': 1.0, 'GPU': 1.0, 'CPU': 8.0, 'node:10.193.195.59': 1.0}
---
节点 ID: 802f333067990b56926977df9b233c5fa021783653ba92413e0a36ca
节点 IP: 10.193.195.59
节点资源: {'memory': 23340599296.0, 'object_store_memory': 10003113984.0, 'accelerator_type:G': 1.0, 'GPU': 1.0, 'CPU': 8.0, 'node:10.193.195.59': 1.0}
---
五 模型下载和运行
5.1 下载Qwen3-4B模型
- 在宿主机base环境下,执行命令下载模型Qwen3-4B-Instruct-2507
cd /opt/1panel/apps/RayCuda/ray-vllm-data-0/
pip install modelscope
modelscope download --model Qwen/Qwen3-4B-Instruct-2507 --local_dir ./Qwen3-4B-Instruct-2507
- 验证容器内可访问模型
docker exec -it ray-node-0 bash
cd /root/ray-vllm/data
ls -l
5.2 Ray+vLLM分布式运行Qwen3-4B大模型
- 进入主节点容器,切换到模型目录。
docker exec -it ray-node-0 bash
cd /root/ray-vllm/data
- 执行vllm运行模型。
vllm serve ./Qwen3-4B-Instruct-2507 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.75 \
--max-model-len 4096 \
--host 0.0.0.0 \
--port 8000
5.3 查看GPU运行状态
- 在宿主机安装
nvitop监视gpu情况。
pip install nvitop
nvitop -m full
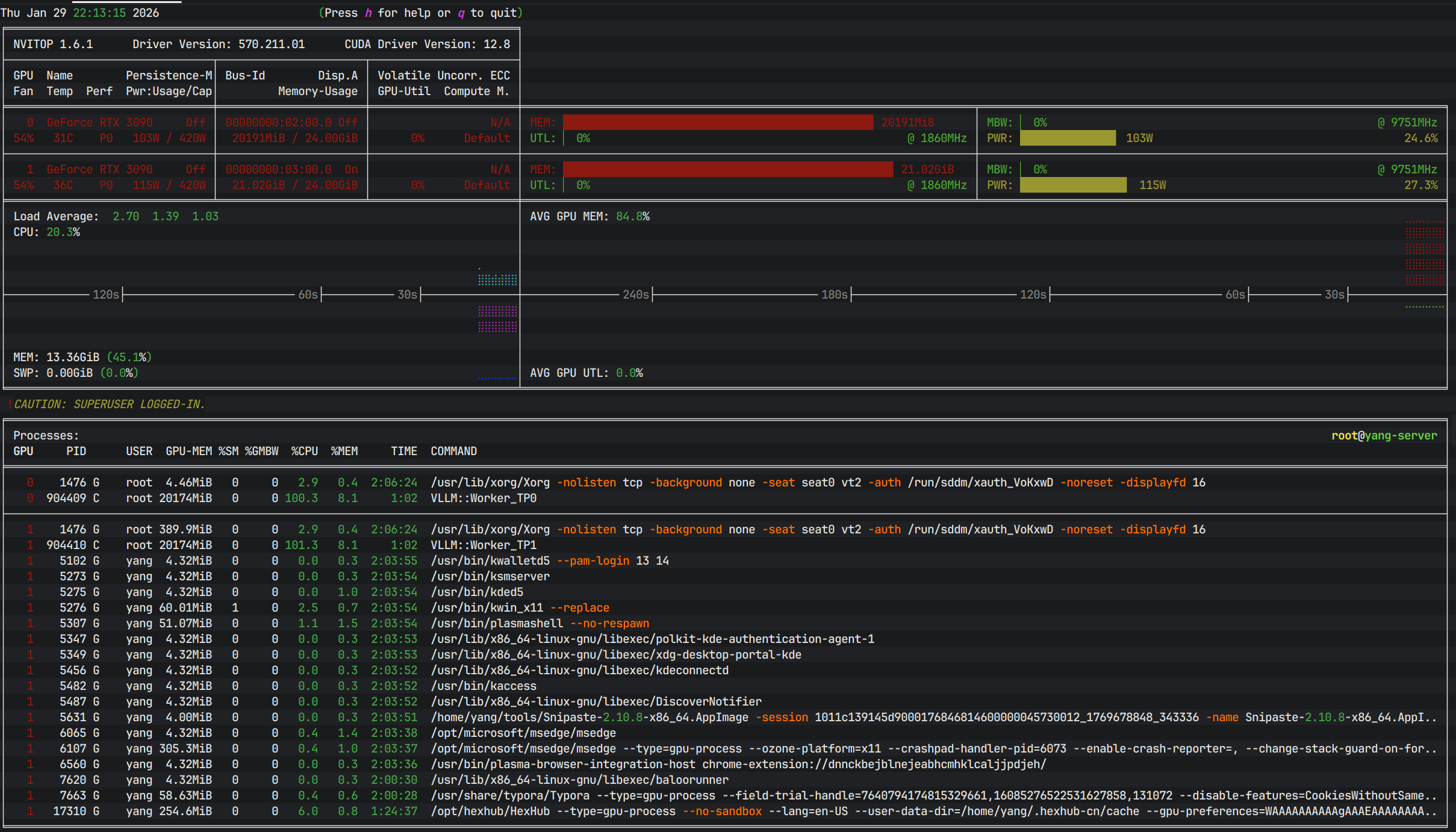
六 交互式分布式推理(快速测试)
6.1 脚本测试
- 进入主节点容器,切换到模型目录。
docker exec -it ray-node-0 bash
cd /root/ray-vllm/data
- 创建并编辑测试脚本。
vim test.py
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8000/v1", # vLLM OpenAI 兼容地址
api_key="dummy" # 本地 vLLM 一般不校验,随便填
)
stream = client.chat.completions.create(
model="./Qwen3-4B-Instruct-2507",
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "请写一首七言绝句,赞美伟大的领袖。要求:磅礴大气,情感深厚。"}
],
# messages=[
# {"role": "system", "content": "你是一个文学大师,精通各种诗词歌赋。"},
# {"role": "user", "content": "请写一首七言绝句(四句,每句七个字)。\n1. 主题是赞美“人工智能”。\n2. 每一句的第一个字必须连起来读是“未来已来”这四个字。\n3. 韵脚要统一,读起来要朗朗上口。"}
# ],
# messages=[
# {"role": "system", "content": "你是一名经验丰富、外冷内热的外科主治医生。你刚连续工作了 20 个小时,非常疲惫,但你对病人依然负责。"},
# {"role": "user", "content": "(扮演一名紧张的病人家属)医生!我都等了三个小时了!为什么我爸爸还在手术室里没出来?你们是不是搞砸了?我要投诉你!"}
# ],
# messages=[
# {"role": "system", "content": "你是一个擅长跨学科科普的老师。"},
# {"role": "user", "content": "请将大语言模型(LLM)中的“注意力机制”解释给一位 18 世纪的蒸汽机车工程师听。请完全使用蒸汽机、齿轮、活塞、杠杆等那个时代的机械概念来进行类比,不要使用任何电子相关的术语。"}
# ],
# messages=[
# {"role": "system", "content": "你是一个科幻小说作家,风格类似刘慈欣。"},
# {"role": "user", "content": "请写一个短篇故事的开头(约 500 字):\n背景:人类在一颗围绕着红矮星运行的行星上发现了巨大的外星遗迹。\n情节:主角是一名地质学家,他刚刚触摸了遗迹表面发光的几何纹路,意识突然被拉入了一个四维空间视角。请重点描写这种四维空间视角下的视觉奇观和心理震撼。"}
# ],
# messages=[
# {"role": "system", "content": "你是一个逻辑严密的数学家。请仔细思考后再回答,不要掉进陷阱。"},
# {"role": "user", "content": "一个球拍和一个球总共卖 1.10 美元。球拍比球贵 1.00 美元。请问球多少钱?请先给出直觉上的答案,然后通过建立方程组来验证你的直觉是否正确,最后给出最终结论。"}
# ],
temperature=0.7,
max_tokens=3072,
stream=True, # 关键:开启流式
)
# 逐块打印生成内容
for chunk in stream:
# 每个 chunk 里可能有 choices[0].delta.content
if chunk.choices and chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 最后换行
- 执行脚本获得输出。
python3 test.py
万里江山披赤帜,
千秋伟业铸雄魂。
风雷激荡开新纪,
一炬长明照乾坤。
——此诗以“万里江山”“千秋伟业”展现宏阔气度,以“风雷激荡”“一炬长明”抒发深沉敬意,赞颂领袖胸怀天下、扭转乾坤的非凡气魄,情感磅礴,气象雄浑。
- 主节点终端日志如下:
(APIServer pid=1217) INFO: 127.0.0.1:50880 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1217) INFO 01-29 14:14:23 [loggers.py:257] Engine 000: Avg prompt throughput: 4.0 tokens/s, Avg generation throughput: 14.7 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%
6.2 网页对话交互测试
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI 对话助手 (vLLM)</title>
<style>
:root {
--primary-color: #4f46e5; /* 靛蓝色 */
--primary-hover: #4338ca;
--bg-color: #f3f4f6;
--chat-bg: #ffffff;
--text-main: #111827;
--text-secondary: #6b7280;
--border-color: #e5e7eb;
--user-bubble-bg: #4f46e5;
--user-bubble-text: #ffffff;
--ai-bubble-bg: #f9fafb;
--ai-bubble-text: #1f2937;
--shadow-sm: 0 1px 2px 0 rgba(0, 0, 0, 0.05);
--shadow-md: 0 4px 6px -1px rgba(0, 0, 0, 0.1), 0 2px 4px -1px rgba(0, 0, 0, 0.06);
}
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Helvetica, Arial, sans-serif;
background-color: var(--bg-color);
color: var(--text-main);
height: 100vh;
display: flex;
flex-direction: column;
overflow: hidden; /* 防止整个页面滚动 */
}
/* 顶部导航 */
header {
background: var(--chat-bg);
padding: 1rem 1.5rem;
border-bottom: 1px solid var(--border-color);
display: flex;
justify-content: space-between;
align-items: center;
flex-shrink: 0;
z-index: 10;
}
.brand {
font-size: 1.25rem;
font-weight: 700;
color: var(--text-main);
display: flex;
align-items: center;
gap: 0.5rem;
}
.brand svg {
color: var(--primary-color);
}
.settings-toggle {
background: transparent;
border: 1px solid var(--border-color);
padding: 0.5rem;
border-radius: 0.5rem;
cursor: pointer;
color: var(--text-secondary);
transition: all 0.2s;
}
.settings-toggle:hover {
background: var(--bg-color);
color: var(--text-main);
}
/* 设置面板(可折叠) */
#settings-panel {
background: var(--chat-bg);
border-bottom: 1px solid var(--border-color);
padding: 1rem 1.5rem;
display: none; /* 默认隐藏 */
grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));
gap: 1rem;
animation: slideDown 0.3s ease-out;
flex-shrink: 0;
}
#settings-panel.open {
display: grid;
}
@keyframes slideDown {
from { opacity: 0; transform: translateY(-10px); }
to { opacity: 1; transform: translateY(0); }
}
.input-group {
display: flex;
flex-direction: column;
gap: 0.25rem;
}
.input-group label {
font-size: 0.75rem;
font-weight: 600;
color: var(--text-secondary);
text-transform: uppercase;
letter-spacing: 0.05em;
}
.input-group input {
padding: 0.5rem;
border: 1px solid var(--border-color);
border-radius: 0.375rem;
font-size: 0.875rem;
outline: none;
transition: border-color 0.2s;
}
.input-group input:focus {
border-color: var(--primary-color);
box-shadow: 0 0 0 2px rgba(79, 70, 229, 0.1);
}
/* 聊天主区域 */
#chat-container {
flex: 1;
overflow-y: auto;
padding: 1.5rem;
display: flex;
flex-direction: column;
gap: 1.5rem;
scroll-behavior: smooth;
}
.message-wrapper {
display: flex;
gap: 1rem;
max-width: 800px;
margin: 0 auto;
width: 100%;
animation: fadeIn 0.3s ease-out;
}
@keyframes fadeIn {
from { opacity: 0; transform: translateY(5px); }
to { opacity: 1; transform: translateY(0); }
}
.avatar {
width: 36px;
height: 36px;
border-radius: 6px;
flex-shrink: 0;
display: flex;
align-items: center;
justify-content: center;
font-size: 1.2rem;
}
.user-msg .message-wrapper {
flex-direction: row-reverse;
}
.user-msg .avatar {
background: var(--user-bubble-bg);
color: white;
}
.ai-msg .avatar {
background: #10a37f; /* ChatGPT 绿色风格 */
color: white;
}
.message-content {
padding: 0.75rem 1rem;
border-radius: 12px;
font-size: 1rem;
line-height: 1.6;
position: relative;
word-wrap: break-word;
max-width: 85%;
white-space: pre-wrap;
}
.user-msg .message-content {
background: var(--user-bubble-bg);
color: var(--user-bubble-text);
border-top-right-radius: 2px;
}
.ai-msg .message-content {
background: var(--ai-bubble-bg);
color: var(--ai-bubble-text);
border: 1px solid var(--border-color);
border-top-left-radius: 2px;
}
/* 打字动画 */
.typing-indicator {
display: flex;
gap: 4px;
padding: 4px 0;
}
.typing-dot {
width: 6px;
height: 6px;
background: #9ca3af;
border-radius: 50%;
animation: bounce 1.4s infinite ease-in-out both;
}
.typing-dot:nth-child(1) { animation-delay: -0.32s; }
.typing-dot:nth-child(2) { animation-delay: -0.16s; }
@keyframes bounce {
0%, 80%, 100% { transform: scale(0); }
40% { transform: scale(1); }
}
/* 底部输入区 */
.input-area {
background: var(--chat-bg);
padding: 1.5rem;
border-top: 1px solid var(--border-color);
flex-shrink: 0;
}
.input-box-wrapper {
max-width: 800px;
margin: 0 auto;
position: relative;
background: #fff;
border: 1px solid var(--border-color);
border-radius: 0.75rem;
box-shadow: var(--shadow-sm);
transition: box-shadow 0.2s, border-color 0.2s;
display: flex;
align-items: flex-end;
padding: 0.5rem;
}
.input-box-wrapper:focus-within {
border-color: var(--primary-color);
box-shadow: var(--shadow-md);
}
textarea {
flex: 1;
border: none;
resize: none;
padding: 0.75rem;
font-size: 1rem;
font-family: inherit;
max-height: 200px;
min-height: 24px;
outline: none;
background: transparent;
line-height: 1.5;
}
.send-btn {
background: var(--primary-color);
color: white;
border: none;
border-radius: 0.5rem;
width: 36px;
height: 36px;
display: flex;
align-items: center;
justify-content: center;
cursor: pointer;
margin-bottom: 2px;
margin-right: 2px;
transition: background 0.2s;
}
.send-btn:hover {
background: var(--primary-hover);
}
.send-btn:disabled {
background: #d1d5db;
cursor: not-allowed;
}
/* 滚动条美化 */
#chat-container::-webkit-scrollbar {
width: 8px;
}
#chat-container::-webkit-scrollbar-track {
background: transparent;
}
#chat-container::-webkit-scrollbar-thumb {
background-color: #d1d5db;
border-radius: 4px;
}
#chat-container::-webkit-scrollbar-thumb:hover {
background-color: #9ca3af;
}
/* 响应式调整 */
@media (max-width: 640px) {
header { padding: 0.75rem 1rem; }
#chat-container { padding: 1rem; }
.message-wrapper { max-width: 100%; }
.message-content { max-width: 90%; font-size: 0.95rem; }
.input-area { padding: 1rem; }
}
</style>
</head>
<body>
<header>
<div class="brand">
<svg width="24" height="24" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round">
<path d="M12 2a10 10 0 1 0 10 10H12V2z"></path>
<path d="M12 12 2.1 12a10.1 10.1 0 0 0 10 10V12z"></path>
<path d="M12 12 21.9 12a10.1 10.1 0 0 0-10-10V12z"></path>
</svg>
<span>vLLM Chat</span>
</div>
<button id="settings-toggle" class="settings-toggle" title="设置">
<svg width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round">
<circle cx="12" cy="12" r="3"></circle>
<path d="M19.4 15a1.65 1.65 0 0 0 .33 1.82l.06.06a2 2 0 0 1 0 2.83 2 2 0 0 1-2.83 0l-.06-.06a1.65 1.65 0 0 0-1.82-.33 1.65 1.65 0 0 0-1 1.51V21a2 2 0 0 1-2 2 2 2 0 0 1-2-2v-.09A1.65 1.65 0 0 0 9 19.4a1.65 1.65 0 0 0-1.82.33l-.06.06a2 2 0 0 1-2.83 0 2 2 0 0 1 0-2.83l.06-.06a1.65 1.65 0 0 0 .33-1.82 1.65 1.65 0 0 0-1.51-1H3a2 2 0 0 1-2-2 2 2 0 0 1 2-2h.09A1.65 1.65 0 0 0 4.6 9a1.65 1.65 0 0 0-.33-1.82l-.06-.06a2 2 0 0 1 0-2.83 2 2 0 0 1 2.83 0l.06.06a1.65 1.65 0 0 0 1.82.33H9a1.65 1.65 0 0 0 1-1.51V3a2 2 0 0 1 2-2 2 2 0 0 1 2 2v.09a1.65 1.65 0 0 0 1 1.51 1.65 1.65 0 0 0 1.82-.33l.06-.06a2 2 0 0 1 2.83 0 2 2 0 0 1 0 2.83l-.06.06a1.65 1.65 0 0 0-.33 1.82V9a1.65 1.65 0 0 0 1.51 1H21a2 2 0 0 1 2 2 2 2 0 0 1-2 2h-.09a1.65 1.65 0 0 0-1.51 1z"></path>
</svg>
</button>
</header>
<div id="settings-panel">
<div class="input-group">
<label>API Base URL</label>
<input id="base-url" type="text" value="http://127.0.0.1:8000/v1">
</div>
<div class="input-group">
<label>模型名称</label>
<input id="model-name" type="text" value="./Qwen3-4B-Instruct-2507">
</div>
<div class="input-group">
<label>API Key</label>
<input id="api-key" type="text" value="dummy">
</div>
</div>
<main id="chat-container">
<!-- 欢迎消息 -->
<div class="message-wrapper ai-msg">
<div class="avatar">
<svg width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><path d="M21 15a2 2 0 0 1-2 2H7l-4 4V5a2 2 0 0 1 2-2h14a2 2 0 0 1 2 2z"></path></svg>
</div>
<div class="message-content">
你好!我是 vLLM 助手。有什么我可以帮你的吗?
</div>
</div>
</main>
<footer class="input-area">
<div class="input-box-wrapper">
<textarea id="user-input" rows="1" placeholder="输入消息... (Shift + Enter 换行)"></textarea>
<button id="send-btn" class="send-btn" disabled>
<svg width="18" height="18" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><line x1="22" y1="2" x2="11" y2="13"></line><polygon points="22 2 15 22 11 13 2 9 22 2"></polygon></svg>
</button>
</div>
</footer>
<script>
const chatContainer = document.getElementById('chat-container');
const userInput = document.getElementById('user-input');
const sendBtn = document.getElementById('send-btn');
const settingsToggle = document.getElementById('settings-toggle');
const settingsPanel = document.getElementById('settings-panel');
const baseUrlInput = document.getElementById('base-url');
const modelNameInput = document.getElementById('model-name');
const apiKeyInput = document.getElementById('api-key');
// 切换设置面板
settingsToggle.addEventListener('click', () => {
settingsPanel.classList.toggle('open');
});
// 输入框自动增高
userInput.addEventListener('input', function() {
this.style.height = 'auto';
this.style.height = (this.scrollHeight) + 'px';
sendBtn.disabled = this.value.trim() === '';
});
// 创建消息 DOM 结构
function createMessageElement(role) {
const wrapper = document.createElement('div');
wrapper.className = `message-wrapper ${role === 'user' ? 'user-msg' : 'ai-msg'}`;
const avatar = document.createElement('div');
avatar.className = 'avatar';
if (role === 'user') {
avatar.innerHTML = `<svg width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><path d="M20 21v-2a4 4 0 0 0-4-4H8a4 4 0 0 0-4 4v2"></path><circle cx="12" cy="7" r="4"></circle></svg>`;
} else {
avatar.innerHTML = `<svg width="20" height="20" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><rect x="3" y="11" width="18" height="10" rx="2"></rect><circle cx="12" cy="5" r="2"></circle><path d="M12 7v4"></path><line x1="8" y1="16" x2="8" y2="16"></line><line x1="16" y1="16" x2="16" y2="16"></line></svg>`;
}
const content = document.createElement('div');
content.className = 'message-content';
wrapper.appendChild(avatar);
wrapper.appendChild(content);
return { wrapper, content };
}
// 添加“正在思考”动画
function showTypingIndicator(wrapper) {
const content = wrapper.querySelector('.message-content');
const indicator = document.createElement('div');
indicator.className = 'typing-indicator';
indicator.id = 'typing-indicator';
indicator.innerHTML = `
<div class="typing-dot"></div>
<div class="typing-dot"></div>
<div class="typing-dot"></div>
`;
content.appendChild(indicator);
}
// 移除“正在思考”动画
function removeTypingIndicator(wrapper) {
const indicator = wrapper.querySelector('#typing-indicator');
if (indicator) indicator.remove();
}
// 获取历史消息(排除欢迎语)
function getMessages() {
const msgs = [];
const wrappers = chatContainer.querySelectorAll('.message-wrapper');
wrappers.forEach(w => {
// 如果有 id 且是欢迎语逻辑(这里简单判断,实际可以用 class 过滤)
if(w.querySelector('.message-content').textContent === "你好!我是 vLLM 助手。有什么我可以帮你的吗?") return;
const isUser = w.classList.contains('user-msg');
const text = w.querySelector('.message-content').textContent;
if (text && !text.includes('...')) {
msgs.push({ role: isUser ? 'user' : 'assistant', content: text });
}
});
return msgs;
}
async function doChat() {
const question = userInput.value.trim();
if (!question) return;
const baseUrl = baseUrlInput.value.replace(/\/+$/, '');
const modelName = modelNameInput.value;
const apiKey = apiKeyInput.value;
// UI 状态更新
userInput.value = '';
userInput.style.height = 'auto'; // 重置高度
sendBtn.disabled = true;
// 1. 添加用户消息
const { wrapper: userWrapper } = createMessageElement('user');
userWrapper.querySelector('.message-content').textContent = question;
chatContainer.appendChild(userWrapper);
// 2. 添加助手消息占位符(带动画)
const { wrapper: aiWrapper, content: aiContent } = createMessageElement('assistant');
chatContainer.appendChild(aiWrapper);
showTypingIndicator(aiWrapper);
chatContainer.scrollTop = chatContainer.scrollHeight;
// 构建消息列表
const messages = [
{ role: 'system', content: '你是一个有用的助手。' },
...getMessages(),
{ role: 'user', content: question }
];
const url = `${baseUrl}/chat/completions`;
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
},
body: JSON.stringify({
model: modelName,
messages: messages,
temperature: 0.7,
max_tokens: 3072,
stream: true
})
});
if (!response.ok) {
const errText = await response.text();
throw new Error(`请求失败:${response.status} ${errText}`);
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = '';
let firstChunk = true;
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split(/\r?\n/);
buffer = lines.pop() || '';
for (const line of lines) {
if (!line.trim() || line.startsWith(':')) continue;
if (line.trim() === 'data: [DONE]') continue;
if (line.startsWith('data: ')) {
if (firstChunk) {
removeTypingIndicator(aiWrapper);
aiContent.textContent = '';
firstChunk = false;
}
const jsonStr = line.slice(6);
try {
const data = JSON.parse(jsonStr);
const delta = data.choices && data.choices[0] && data.choices[0].delta;
const content = delta && delta.content;
if (content) {
aiContent.textContent += content;
chatContainer.scrollTop = chatContainer.scrollHeight;
}
} catch (e) {
console.warn('解析行失败', e);
}
}
}
}
} catch (err) {
removeTypingIndicator(aiWrapper);
aiContent.textContent += `\n[错误: ${err.message}]`;
aiContent.style.color = '#ef4444';
} finally {
sendBtn.disabled = userInput.value.trim() === '';
userInput.focus();
}
}
sendBtn.addEventListener('click', doChat);
// 支持回车发送(Shift+Enter 换行)
userInput.addEventListener('keydown', (e) => {
if (e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
doChat();
}
});
</script>
</body>
</html>



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)