SpringBoot + 一致性哈希协调算法 + AI 模型毕设实战:从零搭建智能任务调度系统
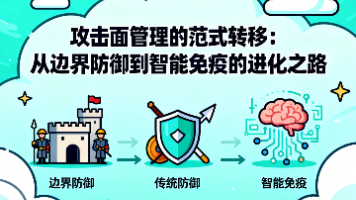
在分布式场景下,我们经常面对两个核心问题:有很多任务 / 请求,需要分配给多个节点(Server1、Server2、Server3…);后期节点可能增加 / 下线,不希望所有任务都「大洗牌」。常见方案:取模法:hash(taskId) % 节点数优点:实现非常简单;缺点:新增或下线节点时,几乎所有任务映射都会变,迁移成本高。一致性哈希(Consistent Hashing)核心思想(通俗版):把整
一、引言:为什么这套组合很适合毕设和 Java 新手?
很多同学做毕设时,停在「增删改查 + 登录权限」这一层,功能没问题,但技术亮点不够。
如果你想让自己的毕设在答辩时更「工程化」「智能化」,下面这套组合非常适合你:
-
SpringBoot:主流 Java 后端框架,模板多、资料多、上手快;
-
协调算法(本文选用:一致性哈希):让任务在多个节点之间合理分配、可扩展;
-
AI 模型(本文选用:简单逻辑回归 / 决策树思想):对任务进行智能评分或优先级判断;
-
MySQL(可选):持久化存储任务记录、预测结果、节点信息。
可直接落地到这些毕设场景:
-
分布式任务调度系统:多个执行节点,智能分配和调度任务;
-
日志 / 数据处理优化平台:根据数据类型、大小、特征路由到不同节点;
-
智能决策系统:对任务是否加急处理、是否可能失败做简单预测。
一句话总结本项目思路:
> 用 SpringBoot 搭框架,用一致性哈希做「任务分配协调」,用简单 AI 模型做「任务优先级评分」,再加上 MySQL 做持久化,形成一个可以演示、可讲解、有技术亮点的完整毕设项目。
二、核心技术铺垫:协调算法 + AI 模型 + SpringBoot
2.1 什么是协调算法?(以一致性哈希为主)
在分布式场景下,我们经常面对两个核心问题:
-
有很多任务 / 请求,需要分配给多个节点(Server1、Server2、Server3…);
-
后期节点可能增加 / 下线,不希望所有任务都「大洗牌」。
常见方案:
-
取模法:hash(taskId) % 节点数
-
优点:实现非常简单;
-
缺点:新增或下线节点时,几乎所有任务映射都会变,迁移成本高。
-
一致性哈希(Consistent Hashing)
核心思想(通俗版):
-
把整个哈希空间看成一个「环」;
-
把每个节点映射到环上的某些位置(虚拟节点);
-
任务根据 hash(taskId) 落在环上,从顺时针方向找到的第一个节点,就是负责处理它的节点;
-
新增 / 删除节点时,只会影响「环上一小段区间」的任务分配,迁移量小。
对毕设来说,一致性哈希优势:
-
概念不算太难,可画图讲解(非常适合答辩用白板或 PPT);
-
代码实现量不大,但「听起来很高级」;
-
很多中间件(如 Redis 集群、分布式缓存)都用到类似思想,老师会认可。
> 你在论文中可以写的是「基于一致性哈希思想的任务协调算法」,不必实现特别复杂的工业级版本。
2.2 选择轻量级 AI 模型:逻辑回归 / 决策树
为了降低实现难度,又能体现出「AI / 机器学习」的亮点,推荐:
-
逻辑回归(Logistic Regression)
-
输入特征:任务大小、预计耗时、历史失败率、任务类型等;
-
输出:任务是否需要高优先级(0 / 1),或高优先级概率(0~1);
-
优点:数学不算难,网上资料非常多,可以用 Python 预先训练,导出简单参数,再在 Java 中做推理。
-
简易决策树思想
-
通过 if-else / 阈值判断实现简单树结构;
-
虽然不是真正训练出的树,但足够在答辩中解释原理 + 实现;
-
也可以借助外部工具训练,再把规则固化到代码里。
在项目中,你可以采用两种方式之一:
- 本地 Java 内嵌简单模型:
-
直接在 Java 中写逻辑回归推理公式(权重 w、偏置 b 写死);
-
或用 if-else 模拟决策树。
- 调用外部 AI 服务:
-
使用 Python Flask / FastAPI 部署模型服务;
-
SpringBoot 通过 HTTP 调用该服务,拿到预测结果。
本文示例采用Java 内嵌简化逻辑回归推理,方便毕设部署和演示。
2.3 为什么要用 SpringBoot 来整合?
对 Java 后端新手和毕设同学来说,SpringBoot 的优势非常明显:
-
自动配置:少写大量 XML 配置,开箱即用;
-
生态完善:Spring Data JPA / MyBatis、Spring MVC、Spring Security 等容易集成;
-
文档 & 教程丰富:出问题几乎都能在博客 / CSDN 找到答案;
-
适合作为后端网关:对接前端、数据库、AI 服务、协调算法都在一个项目里完成。
在这个项目中,SpringBoot 的角色:
-
提供 REST 接口:接收任务提交请求 /api/task/submit;
-
调用协调算法模块:确定任务由哪个节点执行;
-
调用 AI 模块:给任务打分或确定是否加急处理;
-
持久化到 MySQL:保存任务、节点、预测结果,方便验收和演示。
三、毕设项目实战:SpringBoot + 一致性哈希 + AI + MySQL
3.1 环境搭建与依赖配置(Maven + SpringBoot)
技术栈建议:
-
JDK 8 / 11
-
SpringBoot 2.x / 3.x
-
Maven
-
MySQL 8.x(可选)
-
开发工具:IDEA / Eclipse
pom.xml 核心依赖示例:
<dependencies>
<!-- Spring Web,用于构建 REST API -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Data JPA(如果使用 JPA 操作 MySQL) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok,简化实体类 Getter/Setter(IDEA 需安装插件) -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 测试依赖(可保留默认) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
application.yml 基本配置示例:
server:
port: 8080
spring:
datasource:
url: jdbc:mysql://localhost:3306/task_scheduler?useSSL=false&serverTimezone=UTC
username: root
password: 123456
jpa:
hibernate:
ddl-auto: update *# 开发环境可用,自动建表*
show-sql: true *# 控制台打印 SQL,便于调试*
3.2 一致性哈希协调算法的实现 / 整合
简单实现一个基于虚拟节点的一致性哈希,用于任务分配到不同执行节点。
import java.nio.charset.StandardCharsets;
import java.security.MessageDigest;
import java.util.SortedMap;
import java.util.TreeMap;
public class ConsistentHashRouter {
*// 哈希环:key 为哈希值,value 为节点标识*
private final SortedMap<Long, String> circle = new TreeMap<>();
*// 每个真实节点映射多个虚拟节点,提升数据分布均匀性*
private final int virtualNodes;
public ConsistentHashRouter(Iterable<String> *nodes*, int *virtualNodes*) {
this.virtualNodes = virtualNodes;
for (String node : nodes) {
addNode(node);
}
}
public void addNode(String *node*) {
for (int i = 0; i < virtualNodes; i++) {
long hash = hash(node + "#" + i);
circle.put(hash, node);
}
}
public void removeNode(String *node*) {
for (int i = 0; i < virtualNodes; i++) {
long hash = hash(node + "#" + i);
circle.remove(hash);
}
}
*// 根据任务 key 找到对应的节点*
public String route(String *key*) {
if (circle.isEmpty()) {
return null;
}
long hash = hash(key);
*// 找到大于等于该 hash 的第一个节点(顺时针)*
SortedMap<Long, String> tailMap = circle.tailMap(hash);
Long nodeHash = !tailMap.isEmpty() ? tailMap.firstKey() : circle.firstKey();
return circle.get(nodeHash);
}
*// 简单哈希实现,可用 MD5 或其它*
private long hash(String *key*) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] bytes = md.digest(key.getBytes(StandardCharsets.UTF_8));
*// 取前 8 个字节转为 long*
long hash = 0;
for (int i = 0; i < 8; i++) {
hash = (hash << 8) | (bytes[i] & 0xff);
}
return hash & 0x7fffffffffffffffL;
} catch (Exception *e*) {
throw new RuntimeException("hash error", e);
}
}
}
\> 逻辑讲解(可直接写在论文 / PPT 中):
\> - 定义一个哈希环,将节点通过「虚拟节点」方式均匀映射到环上;
\> - 对任务 ID 做哈希,顺时针找到最近的节点即为目标节点;
\> - 新增 / 删除节点只影响少量任务的映射,具备良好的扩展性和负载均衡能力。
在 SpringBoot 中配置一些默认节点:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
@Configuration
public class RouterConfig {
@Bean
public ConsistentHashRouter consistentHashRouter() {
*// 模拟三个执行节点:nodeA、nodeB、nodeC*
return new ConsistentHashRouter(Arrays.asList("nodeA", "nodeB", "nodeC"), 100);
}
}
#### 3.3 AI 模型的嵌入与调用(本地简化逻辑回归)
这里我们用一个非常轻量的逻辑回归模型,假设已经通过 Python 训练好,得到如下权重:
- 特征:
- size:任务大小(KB)
- timeEstimate:预计执行时间(秒)
- failRate:历史失败率(0~1)
- 输出:
- score:任务为「高优先级」的概率(0~1)
简单逻辑回归推理服务:
import org.springframework.stereotype.Service;
@Service
public class SimpleLogisticRegressionModel {
*// 假设这些参数来自于训练结果(写死在代码里)*
private final double wSize = 0.002;
private final double wTime = 0.01;
private final double wFailRate = 2.0;
private final double bias = -1.0;
*// sigmoid 函数*
private double sigmoid(double *z*) {
return 1.0 / (1.0 + Math.exp(-z));
}
*/***
** 预测任务是否为高优先级*
*** *@param* *sizeKB* *任务大小(KB)*
*** *@param* *timeEstimateSec* *预计执行时间(秒)*
*** *@param* *failRate* *历史失败率(0~1)*
*** *@return* *概率(0~1),越大表示越需要优先处理*
**/*
public double predictPriority(double *sizeKB*, double *timeEstimateSec*, double *failRate*) {
double z = wSize * sizeKB + wTime * timeEstimateSec + wFailRate * failRate + bias;
return sigmoid(z);
}
}
> 在答辩时,你可以这样解释:
> - 使用逻辑回归建立了任务特征与优先级之间的概率模型;
> - 通过简单的参数组合和 sigmoid 函数输出优先级概率;
> - 阈值(如 0.5)以上标记为高优先级,从而在任务调度中给予更多资源 / 更快执行。
3.4 核心模块联调与接口示例
定义一个任务实体(可根据需要持久化到 MySQL):
import lombok.Data;
@Data
public class TaskRequest {
private String taskId;
private double sizeKB;
private double timeEstimateSec;
private double failRate;
}
任务控制器,整合一致性哈希和 AI 模型:
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
@RestController
@RequestMapping("/api/task")
public class TaskController {
@Resource
private ConsistentHashRouter router;
@Resource
private SimpleLogisticRegressionModel model;
@PostMapping("/submit")
public Object submitTask(@RequestBody TaskRequest *request*) {
*// 1. 使用一致性哈希选择执行节点*
String node = router.route(request.getTaskId());
*// 2. 使用 AI 模型预测任务的优先级概率*
double score = model.predictPriority(
request.getSizeKB(),
request.getTimeEstimateSec(),
request.getFailRate()
);
boolean highPriority = score >= 0.5;
*// 3. TODO:可在此处把任务信息、节点信息、预测结果写入 MySQL*
*// 4. 返回给前端展示*
return new java.util.HashMap<String, Object>() {{
put("taskId", request.getTaskId());
put("node", node);
put("priorityScore", score);
put("highPriority", highPriority);
}};
}
}
> 联调用词说明:
> - SpringBoot 接收到任务请求后,首先通过一致性哈希选择执行节点;
> - 然后将任务特征输入到 AI 模型中,得到优先级评分;
> - 最终把「任务 ID -> 节点 -> 优先级评分」这个映射返回并(可选)写入数据库。
四、毕设开发高频踩坑与解决方案(真香版)
4.1 协调算法数据不一致 / 任务倾斜
-
问题表现:
-
某些节点任务很多,某些几乎没有任务,负载严重不均;
-
新增 / 删除节点后,任务映射大范围变化。
-
原因排查:
-
虚拟节点数量太少,导致哈希分布不均;
-
自定义哈希函数分布不够均匀。
-
解决方案:
-
适当增加虚拟节点数(例如 50~200),在测试中观察分布情况;
-
使用稳定的哈希算法(如 MD5、CRC32);
-
在测试环境中打印一定数量任务的映射结果,画图或统计分布,写在论文中作为「实验分析」。
4.2 AI 模型加载 / 计算导致内存 / 性能问题
-
问题表现:
-
项目启动时加载大型模型,内存占用高;
-
每次请求都加载模型文件,导致延迟很大。
-
解决方案:
-
毕设场景下不建议使用超大模型,采用轻量模型(逻辑回归 / 小型决策树);
-
将模型加载放在 @Service 的构造方法或 @PostConstruct 中,只加载一次;
-
对模型推理方法做简单的性能测试,并在论文中写出「平均响应时间」。
4.3 SpringBoot Bean 注入冲突 / 循环依赖
-
问题表现:
-
启动时报错:BeanCreationException、circular reference 等;
-
典型原因:
-
AService 注入 BService,BService 也注入 AService,产生循环;
-
配置类里对同一个类型定义了多个 @Bean,没加 @Qualifier 导致 Spring 不知道注哪个。
-
解决方案:
-
合理拆分业务,避免两个 Service 强耦合,可以通过事件 / 回调或中间层解耦;
-
多个同类型 Bean 时,通过 @Qualifier(“beanName”) 明确指定;
-
使用 IDEA 的「依赖图」功能看一下 Bean 之间关系,并在论文中画出「模块依赖图」。
4.4 依赖版本不兼容 / MySQL 驱动问题
-
问题表现:
-
启动时报各种版本冲突、多重依赖问题;
-
使用 MySQL 8.x,但驱动版本过低导致连接异常。
-
解决方案:
-
尽量使用 Spring Initializr 生成项目,依赖版本由 SpringBoot 管理;
-
MySQL 8.x 推荐使用 8.x 驱动,并确保 URL 带上 serverTimezone;
-
碰到依赖冲突时,用 mvn dependency:tree 分析,必要时排除多余依赖。
五、项目效果演示与验证:如何让老师「一眼看到亮点」
可以设计一个简单的前端页面或使用 Postman / Swagger 演示以下流程:
-
提交多个任务请求(不同的 taskId、大小、时间、失败率);
-
后端返回的数据中,能清楚看到:
-
每个任务被分配到的节点(nodeA / nodeB / nodeC);
-
每个任务的优先级评分 priorityScore 以及 highPriority 标志;
- 数据库中(如 MySQL)记录每一次任务调度的结果,可展示:
-
某段时间内,各个节点任务分布情况(可导出到 Excel / ECharts 图表);
-
高优先级任务的比例,对应的平均处理延时。
对标毕设验收标准时,可以强调:
-
功能完整:任务提交、任务分配、优先级计算、结果存储完整闭环;
-
有一定算法深度:一致性哈希 + 逻辑回归;
-
代码结构清晰:Controller、Service、算法模块、模型模块、持久化模块分层明显;
-
有实验 / 数据分析:任务分布图、优先级阈值分析等。
六、总结与拓展:如何把这个项目打磨成「高分毕设」
6.1 如何进一步优化算法效率?
-
一致性哈希优化:
-
调整虚拟节点数量,找到任务分布和性能之间的平衡点;
-
对路由过程做缓存,比如对热点任务做本地缓存,减少哈希计算次数。
-
AI 模型优化:
-
减少不必要的特征,保持模型简单、可解释;
-
使用批量预测接口,一次性处理多个任务,减少重复开销。
6.2 答辩时可以重点讲哪些技术点?
-
协调算法方面:
-
用一张「哈希环」示意图介绍一致性哈希的原理、新增 / 删除节点时的影响范围;
-
对比取模法,说明为什么一致性哈希更适合分布式扩展。
-
AI 模型方面:
-
简要介绍逻辑回归的思想:线性模型 + sigmoid 输出概率;
-
说明是如何选取任务特征,并做特征归一化 / 标准化(可以简单写写,不必完全实现)。
-
系统设计方面:
-
展示系统架构图:前端 / 网关 / 协调模块 / 模型模块 / 数据库;
-
强调模块划分清晰、可扩展性好,未来可以替换不同的协调算法或 AI 模型。
6.3 后续可扩展的功能方向
-
增加任务重试 / 失败转移机制:当某个节点不可用时,自动把任务重新分配到其他节点;
-
引入 ZooKeeper / Nacos 做节点注册与健康检查,实现更真实的分布式环境;
-
将 AI 模型升级为深度学习模型(如使用 TensorFlow Serving / ONNX Runtime),通过 HTTP 或 gRPC 调用;
-
增加可视化监控:用 ECharts 做节点负载、任务分布、优先级统计图表。
七、附录:毕设答辩技术亮点提炼(可直接复制到 PPT)
-
技术栈亮点:
-
后端基于 SpringBoot 搭建,采用 REST 风格接口,结构清晰,易扩展;
-
采用 一致性哈希协调算法 实现多节点任务分配,具备良好的扩展性和负载均衡能力;
-
引入 轻量级 AI 模型(逻辑回归) 对任务进行优先级预测,提升调度智能化程度。
-
算法与工程结合:
-
将协调算法与 AI 模型嵌入实际的任务调度流程中,而不是停留在理论层面;
-
完成了从「算法设计 → 后端实现 → 数据持久化 → 可视化分析」的完整闭环。
-
可扩展性与可维护性:
-
协调模块、AI 模块、持久化模块均为独立组件,可独立替换和升级;
-
未来可以无缝接入 ZooKeeper、Nacos、TensorFlow 等更复杂的组件,具备演进空间。
-
实验与验证:
-
通过对不同任务量和节点规模的实验,验证了一致性哈希的分布均衡性;
-
对比了有无 AI 优先级预测下的任务平均响应时间,证明了模型对系统性能的正向影响。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)