TTT-Discover:用于解难题的测试时强化学习
TTT-Discover 证明了 AI 的潜力不应仅仅局限于“预训练知识的提取”,更在于其作为“研究助手”进行自我演化的能力。通过在测试阶段针对特定问题进行强化学习,AI 已经展现出在数学、编程优化和科学计算等领域超越人类顶级水平的潜力。正如论文引言所说,人类解决难题需要“试错、学习、再尝试”,TTT-Discover 正是赋予了 AI 这种从失败中内化新思路的能力。
这篇论文名为《Learning to Discover at Test Time》(在测试时学习如何发现),由斯坦福大学、NVIDIA、UC San Diego等机构的研究人员共同发表。
文章的核心思想是提出了一种名为 TTT-Discover(Test-Time Training to Discover) 的新方法。它打破了传统“冻结大模型(Frozen LLM)+ 搜索”的范式,通过在测试阶段对模型进行实时强化学习(RL),让 AI 在解决具体科学和工程难题时能够“边做边学”,从而发现超越人类现状(State-of-the-Art)的新方案。
以下是对这篇论文的详细解读:

- 图:TTT-Discover 在测试时针对单个问题持续训练大型语言模型(LLM)。πθi 表示测试时训练第 i 步具有更新后权重的策略。这里绘制了第 0、9、24 和 49 步(最终步)的奖励分布,这些数据是在 GPUMode TriMul 竞赛的测试时训练过程中记录的。每一步都会生成 512 个解决方案。随着训练的推进,LLM 会生成更好的解决方案,最终超越现有最优水平(人类最佳结果)。为进行对比,还绘制了在相同总采样预算下 “最优 N 个”(best-of-N)的奖励分布。
上图中,左侧代表模型生成的代码运行速度很慢,右侧代表速度快,目标是将分布取消向右移。灰色曲线Best-of-N表示:如果不训练模型,只是让模型重复采样25600次(512*50),从中挑一个最好的。可以清楚地看到,“Best-of-N” 的分布依然停留在左侧。这意味着如果模型不学习,仅仅靠“暴力搜索”或“盲目猜测”,永远无法达到最右侧那种极致的性能。
1. 核心挑战:科学发现的“非分布”特性
传统的科学发现难题对 AI 来说极其困难,原因有二:
- 超出训练分布(OOD): 真正的“发现”意味着要超越人类现有的知识边界,模型在预训练阶段从未见过这些解。
- 目标单一化: 传统的强化学习目标是提高“平均分”,但科学发现只需要“一个极优解”。
以往的方法(如 AlphaEvolve)通常是利用模型进行大量的采样和搜索,但模型本身是不变的。这就像一个学生在考试时只会不停地猜答案,却不会从之前的失败中总结规律。
2. TTT-Discover 的核心逻辑
TTT-Discover 的核心创新在于将**学习(Training)和搜索(Search)**深度结合。
A. 强化学习与实时演化
当给出一个具体的测试难题(比如一个复杂的数学猜想或代码优化问题)时,系统不再只是单纯调用 LLM,而是启动一个循环:
- 采样(Rollout): 模型生成成百上千个尝试性的解。
- 评估(Evaluate): 根据连续奖励(Reward)函数(如代码运行速度、数学边界的紧确度)给方案打分。
- 训练(Train): 针对这个单一问题,利用强化学习实时更新模型参数(通常使用 LoRA 这种高效微调技术)。
- 循环: 更新后的模型生成的方案会越来越好,从而进入良性循环。
B. 两个关键技术组件
- 熵目标函数(Entropic Objective): 不同于传统的 RL 追求平均分,该目标函数通过指数加权,极度偏好那些能达到“历史最高分”的动作。这意味着模型会变得非常“激进”,全心全意去冲击那个可能的新记录,而不是求稳。
- PUCT 重用策略(PUCT Reuse): 借鉴了 AlphaZero 的思想,系统维护一个方案库。在选择从哪个旧方案开始进行下一步探索时,它会平衡“高分方案”和“未被充分探索的方案”,确保模型既能深入钻研,又不会陷入局部最优。
3. 令人惊叹的实验结果
论文在四个极具挑战性的领域进行了测试,几乎全部刷新了世界纪录(SOTA):
-
数学(Mathematics):
- Erdős 最小重叠问题: 成功将该问题的上界从 0.380924 降低到 0.380876。这是一个极小的进步,但在数学界意义重大,证明了 AI 能找到人类和以往 AI 都没发现的数学构造。
- 自相关不等式: 同样刷新了相关问题的最优解边界。
-
GPU 内核工程(Kernel Engineering):
- 针对高性能计算(如 TriMul 算子),AI 编写的内核代码比人类专家编写的最优代码快了 25% 到 2 倍。
-
算法设计(Algorithm Design):
- 在知名编程竞赛平台 AtCoder 的启发式竞赛(AHC)中,TTT-Discover 编写的算法获得了第一名的成绩。
-
生物学(Biology):
- 在单细胞 RNA 测序数据的去噪(Denoising)任务中,AI 发现的算法在 MSE(均方误差)等指标上显著优于 MAGIC 等人类现有的先进算法。
4. 论文的突破性意义
- 开源模型的逆袭: 以前很多复杂的推理任务依赖于闭源的大模型(如 GPT-4, Gemini 1.5 Pro),但 TTT-Discover 使用的是开源模型(如
gpt-oss-120b或Qwen3-8B),通过测试时的训练,效果超越了那些闭源的巨型模型。 - 成本可控: 解决一个世界级难题的计算成本仅需几百美元(约 500 美元),这比传统聘请顶尖科学家团队进行数月攻关的成本要低得多。
- 可验证性: 所有的科学发现(数学边界、GPU 代码、去噪算法)都是可验证的。这解决了大模型经常“一本正经胡说八道”的幻觉问题——结果好不好,跑一下测试就知道了。
5. 总结
TTT-Discover 证明了 AI 的潜力不应仅仅局限于“预训练知识的提取”,更在于其作为“研究助手”进行自我演化的能力。
通过在测试阶段针对特定问题进行强化学习,AI 已经展现出在数学、编程优化和科学计算等领域超越人类顶级水平的潜力。正如论文引言所说,人类解决难题需要“试错、学习、再尝试”,TTT-Discover 正是赋予了 AI 这种从失败中内化新思路的能力。
TTT-Discover与普通TTRL的区别: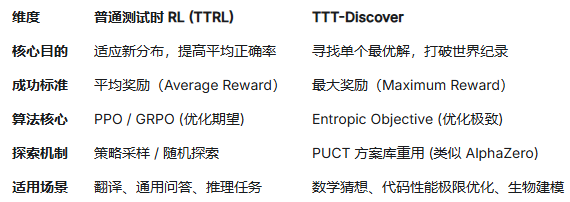

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)