Spring AI Alibaba学习(一)—— RAG
本文深入解析了阿里巴巴开源的SpringAIAlibaba RAG框架,从架构设计、核心原理到最佳实践全面剖析。重点介绍了RAG五大核心阶段(解析、分块、知识库管理、向量化存储、检索层)和三大检索策略(并行多知识库检索、混合搜索、重排序)。特别强调了Advisor模式的创新性,它能自动完成检索和上下文构建,实现业务与检索逻辑解耦。文章还分享了512token分块策略的优化考量,以及生产环境推荐配置
博主最近深入学习了 Spring AI Alibaba的 RAG(检索增强生成)架构,这是阿里巴巴开源的企业级 AI 应用开发框架。通过源码的学习博主对 RAG 的也有了一定的认识。本文将从架构设计、核心原理、最佳实践三个维度,分享我的学习笔记。闲话少说,正片开始!!
目录
RAG 的五大核心阶段——以Spring AI Alibaba为例
一、RAG 核心概念
什么是 RAG?
大型语言模型(LLM)虽然强大,但有两个关键限制(来自于Alibaba官方文档的原文):
- 有限的上下文——它们无法一次性摄取整个语料库
- 静态知识——它们的训练数据在某个时间点被冻结
而 RAG(Retrieval-Augmented Generation) = 检索 + 增强 + 生成简单来说,就是让 LLM(大语言模型)能够访问外部知识库,从而:✅ 回答准确(基于真实文档)✅ 知识可更新(更新文档即可)✅ 可解释(显示参考来源)。
RAG 的五大核心阶段——以Spring AI Alibaba为例
1. 多模态解析阶段
├─ PDF 文档解析
├─ Office 文档解析 (DOC/DOCX/PPT/PPTX)
├─ Markdown 解析
└─ 纯文本解析
2. 文档分块阶段
├─ Token 分块(推荐 512 tokens)
├─ 正则分块
└─ Chunk Overlap(重叠 50-100 tokens)
3. 知识库管理
├─ 知识库 CRUD
├─ 文档管理
├─ 多租户隔离
└─ 缓存优化
4. 向量化存储
├─ Embedding 向量化
├─ 向量数据库存储(ElasticSearch)
├─ 向量相似度检索
└─ 混合检索(向量 + 关键词)
5. 召回层(检索核心)
├─ 并行多知识库检索
├─ 向量相似度搜索
├─ Reranking 重排序
└─ 相似度阈值过滤
二、架构设计:分层之美
Spring AI Alibaba 的 RAG 架构由多个核心类协同工作,实现知识库的高效管理与智能检索。KnowledgeBaseIndexPipeline 负责文档处理的完整流程,包括解析(Parse)、转换(Transform)和存储(Store)。KnowledgeBaseService 提供知识库的增删改查(CRUD)及文档管理功能。。
架构分层图与各层级划分
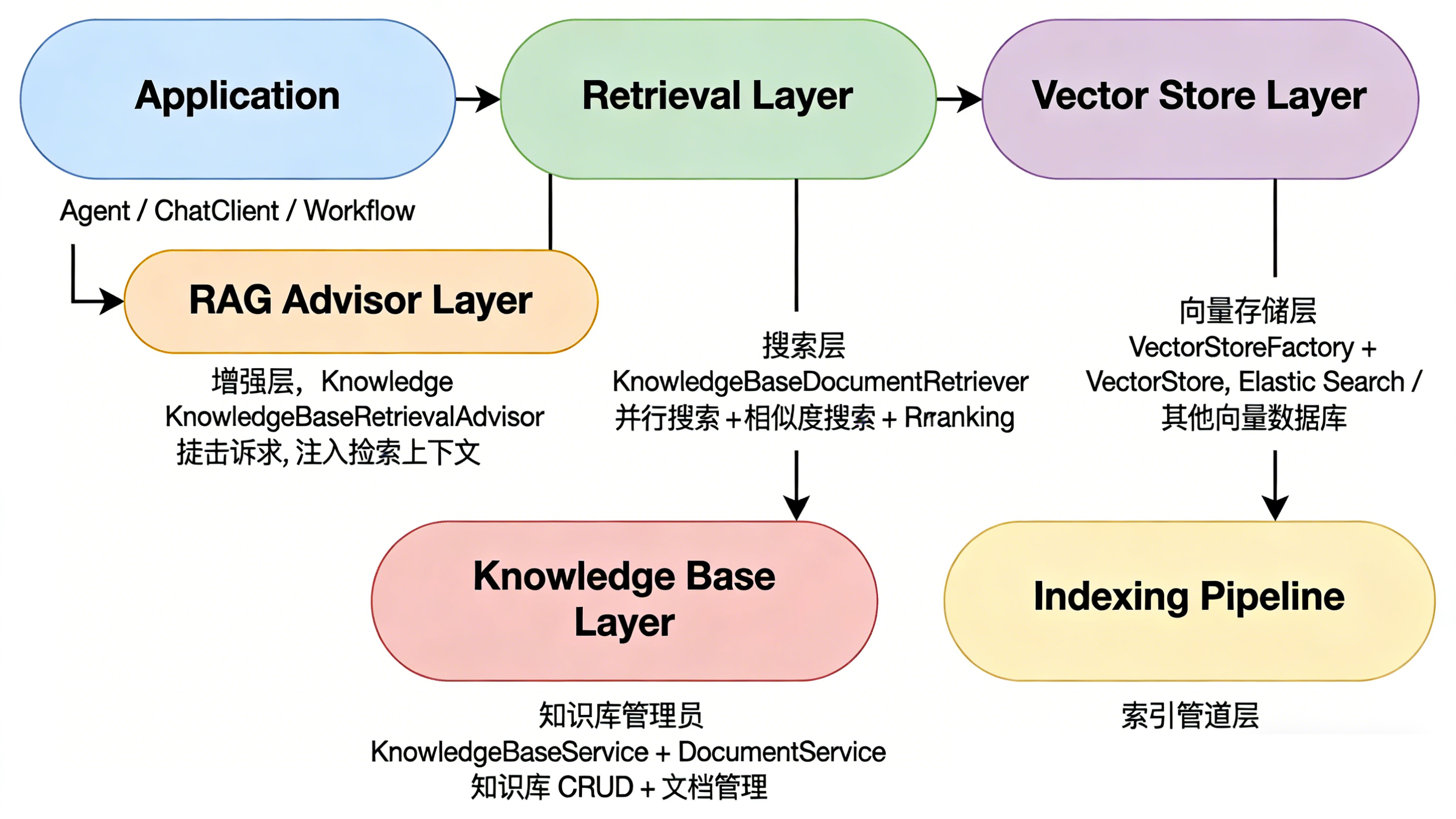
| 层级 | 核心类 | 职责 |
| 索引管道 | KnowledgeBaseIndexPipeline | Parse → Transform → Store |
| 知识库管理 | KnowledgeBaseService | 知识库 CRUD、文档管理 |
| 向量存储 | VectorStoreFactory | 管理向量数据库 |
| 检索层 | KnowledgeBaseDocumentRetriever | 执行智能检索 |
| 增强层 | KnowledgeBaseRetrievalAdvisor | 自动注入检索上下文 |
三、Advisor 模式
在Spring AI Alibaba的RAG架构中,Advisor模式是实现智能检索与业务逻辑解耦的关键设计。它如同一个“隐形的助手”,在开发者无需显式调用的情况下,自动完成检索、上下文构建和提示词增强等繁琐工作。
以声明式编程方式,将检索逻辑与业务逻辑彻底分离,实现了 RAG 的自动化注入。
| 传统 RAG 的痛点 | Advisor 解决方案 |
| ❌ 每次都要写重复代码 |
✅ 零侵入:业务代码无需关心检索逻辑/ ✅ 可复用:Advisor 可以应用到任何 Agent |
| ❌ 检索逻辑和业务逻辑耦合 |
✅ 统一管理:检索策略集中配置 ✅ 可组合:多个 Advisor 可以链式调用 |
| ❌ 难以支持流式输出 |
✅ 流式支持:完整支持 Stream 模式 |
Advisor 解决方案与原理
Advisor模式是Spring AI Alibaba提供的革命性RAG集成方案,它将传统命令式编程转变为声明式编程。开发者无需在业务代码中手动编写检索、上下文构建和提示词拼接的逻辑,而是通过简单的配置声明即可实现RAG能力的自动注入。
作为一个"智能中介",在运行时自动拦截对话请求,执行知识检索并将相关上下文动态注入到提示词中,使业务代码与检索逻辑完全解耦。这种零侵入的设计不仅消除了重复代码,还使得检索策略可以集中管理和统一调整,大幅提升了开发效率和系统的可维护性。
// 使用 Advisor:自动 RAG(优雅且强大)✅
ChatClient client = ChatClient.builder(chatModel)
.defaultAdvisors(
KnowledgeBaseRetrievalAdvisor.builder()
.documentRetriever(retriever)
.build()
)
.build();
String answer = client.prompt()
.system("""
你是智能助手。基于以下文档回答:
{documents} 👈 占位符,Advisor 自动填充
""")
.user("Spring AI 支持哪些模型?")
.call()
.content();
// 传统方式:手动 RAG(繁琐且容易出错❌)
public String traditionalRAG(String userQuery) {
// 1. 手动检索
List<Document> docs = vectorStore.similaritySearch(userQuery);
// 2. 手动构建上下文
String context = docs.stream()
.map(Document::getText)
.collect(Collectors.joining("\n\n"));
// 3. 手动拼接 Prompt
String prompt = "基于以下文档回答:\n" + context + "\n问题:" + userQuery;
// 4. 调用 LLM
return chatModel.call(prompt);
}
当用户发起对话请求时,Advisor会智能拦截并分析查询意图,识别关键实体和领域归属,为精准检索奠定基础。接着进入并行检索与上下文构建阶段,Advisor同时向所有相关知识库发起查询,采用混合搜索策略获取结果,并对返回的文档进行去重、排序和智能压缩,确保上下文的质量和完整性。最后在注入阶段,Advisor将构建好的上下文通过占位符替换或结构化注入等方式,动态嵌入到系统提示词中,然后将增强后的完整提示无缝传递给后续处理流程。整个过程完全自动化,且支持链式调用、容错降级和性能优化,为企业级RAG应用提供了稳定可靠的核心引擎。
四、Token 分块策略
为什么需要分块?
// 问题:LLM 上下文窗口有限
原始文档: 100 页 PDF(约 10 万字 ≈ 13 万 tokens)
LLM 上下文: 8K tokens(GPT-4)
// 解决:分块处理
100 页文档
↓ 分成 250 个块
每块 512 tokens
↓ 检索时只取最相关的 5-10 个块
总共 2560-5120 tokens ✅ 完全可控推荐配置
| 场景 | Chunk Size | Chunk Overlap |
Top-K |
总Context |
| 通用文档 | 512 | 50-100 | 10 | 5120 |
| 长文本(小说、论文) | 1024 | 100-200 | 15 | 15360 |
| 短文本(FAQ、对话) | 256 | 20-50 | 5 | 1280 |
为什么是 512?
具备广泛兼容性(适配多种嵌入模型且支持超过512个词元);能够高效处理长文本(在8K上下文窗口中可容纳Top-10=5120词元);通过段落级文本块实现语义粒度优化;同时保持向量数据库规模合理以确保检索效率。
五、检索层:三大核心策略
策略 1:并行多知识库检索
并行多知识库检索策略通过并发执行机制彻底改变了这一状况。当用户发起查询时,系统会同时向所有相关的知识库发起检索请求,各知识库的检索过程互不阻塞、独立进行。所有知识库的检索结果返回后,系统会进行统一的去重、合并和排序处理,最终形成一个综合的检索结果集。
这种并行化设计的核心优势在于将总检索时间从串行模式的累加值压缩为最慢那个知识库的响应时间。假设有三个知识库,每个检索耗时200毫秒,串行模式需要600毫秒,而并行模式仅需200毫秒即可完成全部检索。对于拥有更多知识库的大型系统,这种性能提升将更加显著。
// 串行检索(慢)
检索A (200ms) → 检索B (200ms) → 检索C (200ms) = 600ms
// 并行检索(快)
检索A (200ms) ┐
检索B (200ms) ├─ 并发执行 = 200ms
检索C (200ms) ┘策略 2:向量相似度搜索
SIMILARITY(纯向量搜索)
SearchRequest request = SearchRequest.builder()
.query(query.text())
.searchType(SearchType.SIMILARITY)
.topK(20)
.similarityThreshold(0.7)
.build();HYBRID(混合搜索)
// 向量相似度 + 关键词匹配(BM25)
SearchRequest request = SearchRequest.builder()
.query(query.text())
.searchType(SearchType.HYBRID)
.hybridWeight(0.5) // 向量权重 50%
.build();
优势:
✅ 专有名词精确匹配(如 "GPT-4")
✅ 长尾查询更全面策略 3:Reranking 重排序
// 问题:向量检索是"粗排"
初步检索:Top-20
↓
结果:10 个高度相关 + 5 个中度相关 + 5 个低度相关
// 解决:Reranking 是"精排"
Reranking:Top-5
↓
精选:5 个最相关的文档 ✅
// 效果:提高检索准确率 10-30%六、生产环境最佳实践
通用推荐配置(适用于 80% 场景)
// ===== 处理配置 =====
ProcessConfig processConfig = ProcessConfig.builder()
.chunkType(ChunkType.TOKEN)
.chunkSize(512) // 核心配置
.chunkOverlap(50) // 10% 重叠
.build();
// ===== 索引配置 =====
IndexConfig indexConfig = IndexConfig.builder()
.vectorStoreType(VectorStoreType.ELASTICSEARCH)
.dimension(1536) // DashScope text-embedding-v3
.similarity(SimilarityType.COSINE)
.build();
// ===== 搜索配置 =====
SearchConfig searchConfig = SearchConfig.builder()
.topK(10) // 检索 10 个块
.similarityThreshold(0.7) // 相似度阈值
.enableRerank(true) // 启用重排序
.rerankTopN(5) // 重排后取 5 个
.build();
// 总 Context = 512 * 5 = 2560 tokens
// 适用于 8K 上下文窗口的 LLM知识库设计最佳实践
✅ 好的设计
知识库A: 产品技术文档
知识库B: 用户操作手册
知识库C: 常见问题FAQ
知识库D: 政策法规文档
❌ 不好的设计
知识库X: 所有文档混在一起
性能优化清单(策略)
- Redis 缓存:知识库配置、热门查询
- 异步索引:文档上传后后台处理
- 批量处理:减少 API 调用次数
- 并行检索:多知识库并发执行
- 超时控制:防止慢查询阻塞
项目依赖
<dependencies>
<!-- Spring AI Alibaba Agent Framework -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
<version>1.1.0.0</version>
</dependency>
<!-- DashScope Chat Model -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>1.1.0.0</version>
</dependency>
<!-- Vector Store (ElasticSearch) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store</artifactId>
<version>1.0.0-M4</version>
</dependency>
<!-- Spring Boot Starter -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
</dependencies>配置文件
spring:
application:
name: spring-ai-alibaba-rag-demo # 根据自己的项目命名
# DashScope 配置
ai:
dashscope:
api-key: ${AI_DASHSCOPE_API_KEY}
chat:
options:
model: qwen-max
temperature: 0.7
embedding:
options:
model: text-embedding-v3 # 嵌入模型配置
# Redis 配置
redis:
host: localhost
port: 6379
lettuce:
pool:
max-active: 20
max-idle: 10
# ElasticSearch 配置
elasticsearch:
uris: http://localhost:9200
# 应用配置
app:
rag:
# 默认分块配置
chunk-size: 512
chunk-overlap: 50
# 默认搜索配置
top-k: 10
similarity-threshold: 0.7
enable-rerank: true
rerank-top-n: 5
server:
port: 8080七、总结
Spring AI Alibaba 与传统 RAG 集成方式在多个关键维度上展现出显著差异。Advisor 模式的自动注入能力消除了手动调用的繁琐,多知识库并行检索突破了单一检索的效率瓶颈。内置的重排策略与流式支持进一步优化了响应质量与用户体验,而原生多租户设计与完善的可观测性则为企业级应用提供了坚实基础。
| 特性 | Spring AI Alibaba | 传统RAG |
| 集成方式 | Advisor 自动注入 | 手动调用 |
| 多知识库 | ✅ 并行检索 | ❌ 单一检索 |
| Reranking(重排策略) | ✅ 内置支持 | ❌ 需自行实现 |
| 流式支持 | ✅ 完整支持 | ⚠️ 部分支持 |
| 多租户 | ✅ 原生支持 | ❌ 需自行实现 |
| 可观测性 | ✅ 完整监控 | ⚠️ 有限 |
1. Advisor 模式的精髓:将横切关注点(检索逻辑)从业务逻辑中分离,实现声明式编程。
2. 512 tokens 的平衡艺术:在语义完整性、检索效率、上下文窗口之间找到最佳平衡点。
3. 分层架构的价值:每一层职责清晰,易于扩展和维护。
4. Reranking 的重要性:从粗排到精排,提升检索质量的关键。
参考资源
如果你也在学习 Spring AI Alibaba,希望这篇笔记对你有所帮助!


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)