ReAct模式详解:让大模型具备推理与行动能力,建议收藏学习
ReAct是一种将推理与行动结合在语言模型中的范式,通过Thought-Action-Observation(TAO)闭环机制实现模型与外部环境交互。该范式可减少幻觉、提高准确性和可解释性,适用于复杂决策环境、知识更新需求等场景。文章详细介绍了ReAct的背景、变体、功能、适用场景及实施方法,并通过代码示例展示如何使用LangChain框架实现ReAct代理,帮助开发者构建智能应用系统。
ReAct是一种将推理与行动结合在语言模型中的范式,通过Thought-Action-Observation(TAO)闭环机制实现模型与外部环境交互。该范式可减少幻觉、提高准确性和可解释性,适用于复杂决策环境、知识更新需求等场景。文章详细介绍了ReAct的背景、变体、功能、适用场景及实施方法,并通过代码示例展示如何使用LangChain框架实现ReAct代理,帮助开发者构建智能应用系统。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
大家好,我是爱学习的cc。会不断更新数智化的场景应用来沉淀数智化相关知识,欢迎大家一起沟通进步。
最近刷到ReAct相关的文章,看了看觉得其中的思想有点触发,虽然不是一个新概念,对我学习过程算是新知识,于是探查学习记录一下,并思考在工作中如何应用。应用不仅仅是工具技能,我深刻体会的有时方法思想是可以跨领域的。
- ReAct范式的背景
大型语言模型的发展经历了从静态生成到动态交互的演进。早期模型擅长文本生成和简单推理,但面临幻觉问题和外部交互缺失的局限。2022年前,链式思考等方法提升了推理能力,却缺乏行动验证机制。ReAct范式于2022年由普林斯顿大学和谷歌研究团队发表的论文《REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS.pdf》中提出,受人类决策过程启发,将抽象思考与具体行动融合。 该框架的背景在于桥接模型内部知识与外部环境的鸿沟,推动AI从被动响应向自主代理转型。根据原论文,该范式在实验中证明了其在多跳问答和决策任务中的优越性,标志着agentic AI的早期里程碑。 到2026年,ReAct已成为LangChain等框架的核心组件,广泛应用于工业自动化和知识检索领域。
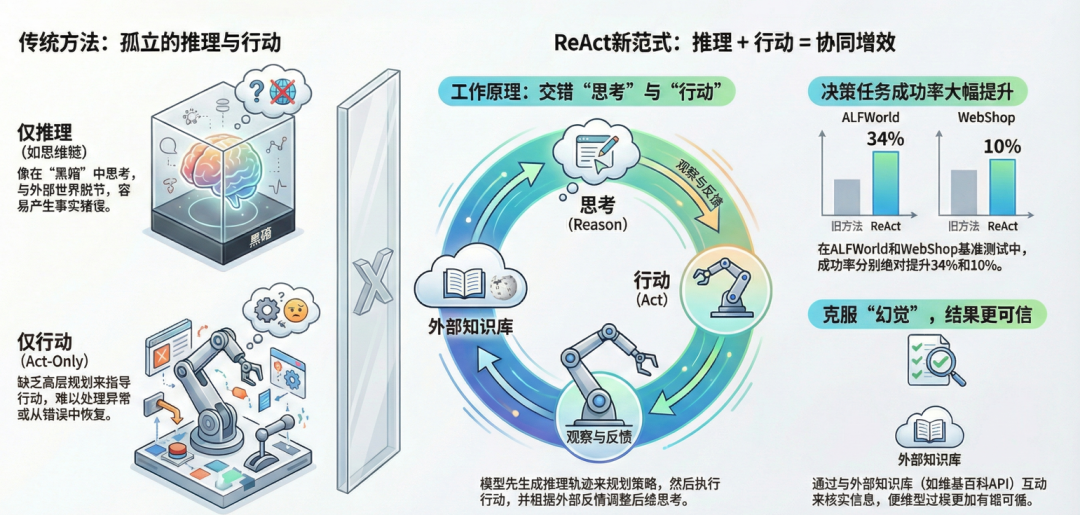
- ReAct范式的变体与发展
自2022年提出以来,ReAct范式已演变为多种变体,以适应多样化应用场景。这些发展主要聚焦于提升鲁棒性、效率和扩展性,特别是在2023-2026年间,受agentic AI趋势驱动。
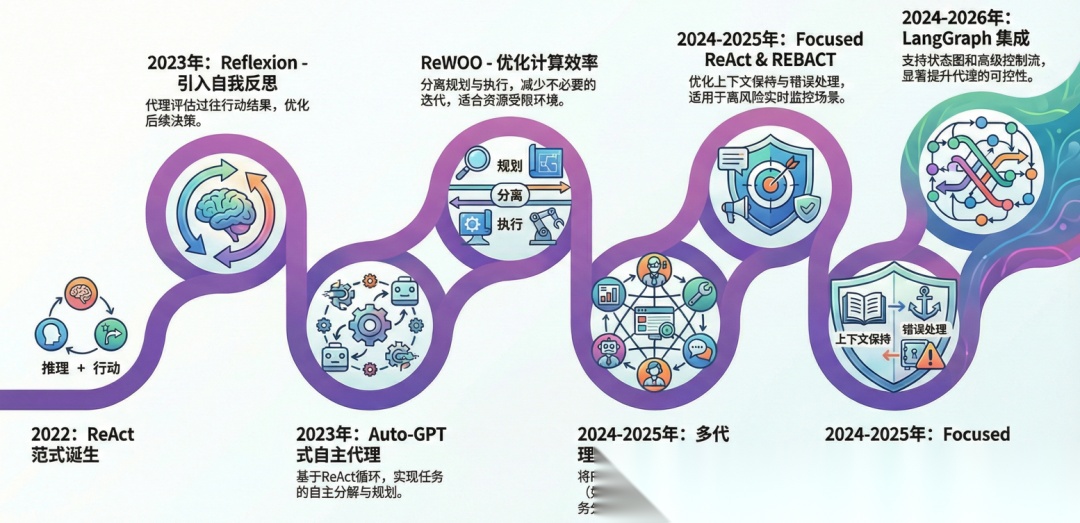
- • Reflexion (2023):引入自我反思机制,代理评估先前行动结果并优化后续步骤。该变体适用于长期任务,提升错误修正能力,并在决策环境中优于原ReAct。
- • ReWOO:优化工具调用流程,分离规划与执行,减少不必要迭代,提高计算效率。适合资源受限的应用,如移动代理。
- • 多代理协作变体:扩展ReAct至多代理系统,例如CrewAI框架中,代理分工执行TAO循环,实现复杂协作任务。 此发展于2024-2025年间流行,推动分布式AI系统。
- • Auto-GPT式自主代理 (2023):基于ReAct循环,实现任务分解与自主规划,常用于无监督环境,如自动化研究。
- • LangGraph集成 (2024-2026):在LangGraph框架中,ReAct变体支持状态图和高级控制流,允许自定义循环和条件分支,提升可控性。
- • Focused ReAct和REBACT (2024-2025):这些变体优化上下文保持和错误处理,适用于高风险场景,如实时监控。
这些变体根据应用需求定制,例如Reflexion用于反思密集任务,而多代理变体适用于协作环境。到2026年,ReAct发展融入agentic AI主流,推动从单一代理向生态系统的转型。
- ReAct范式的功能与作用
ReAct范式的主要功能在于实现推理与行动的协同,通过Thought-Action-Observation (TAO) 闭环机制处理复杂任务。其核心功能包括:
- • 推理生成:模型产生自然语言轨迹,用于问题分解和规划,提升决策的可解释性。
- • 行动执行:标准化调用外部工具,如API或数据库,获取真实数据以验证推理。
- • 观察反馈:处理行动结果,更新循环以修正错误,实现自适应学习。
这些功能的作用体现在多个方面:首先,减少幻觉和错误传播,提高任务准确率;其次,提升模型的鲁棒性,能处理不确定性和异常;最后,促进可扩展性,支持多模态集成。 在实际作用上,ReAct将语言模型转化为智能代理,适用于需要环境交互的场景,如实时监测系统。该范式的作用还延伸到伦理层面,通过外显轨迹增强透明度,降低黑箱风险。
- ReAct范式的使用时机
ReAct范式适用于大型语言模型需与外部环境交互的场景,而非纯内部推理任务。具体时机包括:
- • 复杂决策环境:当任务涉及多步规划和反馈验证时,如模拟交互或多跳问答,避免纯链式思考的孤立局限。
- • 知识更新需求:模型内部知识过时时,通过行动查询外部源补充信息。
- • 高风险应用:在需要可解释性和鲁棒性的领域,如工业安全监测,ReAct的闭环机制可减少错误后果。
- • 少样本学习:新任务中,仅需few-shot提示即可泛化,而非依赖大规模训练。
不适用于简单文本生成或无需外部数据的任务,以避免不必要的计算开销。
- ReAct范式的实施方法
ReAct的实施依赖提示工程和工具集成,无需模型微调,适合应用现有大型语言模型的开发者。步骤如下:
- • 准备阶段:选择支持提示的模型,定义行动空间。
- • 提示设计:构建few-shot示例,包括TAO序列模板,引导模型生成轨迹。
- • 循环执行:迭代生成Thought,执行Action,注入Observation,直至任务完成或达上限。
- • 工具集成:使用框架如LangChain定义自定义工具,确保行动与外部接口无缝连接。
例如,在Python环境中,可通过LangChain实现:
import pandas as pdfrom langchain_openai import ChatOpenAIfrom langchain.agents import create_react_agent, AgentExecutorfrom langchain import hubfrom langchain.tools import Tool# ================= 配置区域 =================# 替换为你的 DeepSeek API KeyAPI_KEY = "YOUR_DEEPSEEK_API_KEY"# DeepSeek 的 Base URLBASE_URL = "https://api.deepseek.com"# ================= 1. 准备阶段:模拟数据 =================defcreate_mock_gas_data(): """创建模拟的燃气使用数据""" data = { 'user_id': [f'user_{i}'for i inrange(1, 11)], 'user_type': ['居民', '商业', '工业', '居民', '商业', '工业', '居民', '居民', '商业', '工业'], 'date': ['2023-10-01', '2023-10-01', '2023-10-01', '2023-10-02', '2023-10-02', '2023-10-02', '2023-10-03', '2023-10-03', '2023-10-03', '2023-10-03'], 'usage_cubic_meters': [15.5, 120.0, 450.2, 14.2, 115.5, 460.1, 16.0, 15.8, 118.0, 455.0] } return pd.DataFrame(data)# 初始化数据gas_df = create_mock_gas_data()# ================= 2. 工具定义 =================# 定义具体的业务逻辑函数defcalculate_average_usage(user_type: str) -> str: """计算指定类型用户的平均用气量。参数 user_type: 居民/商业/工业""" try: if user_type: filtered_df = gas_df[gas_df['user_type'] == user_type] if filtered_df.empty: returnf"未找到类型为 {user_type} 的用户数据。" avg_usage = filtered_df['usage_cubic_meters'].mean() returnf"{user_type}用户的平均用气量为: {avg_usage:.2f} 立方米" else: avg_usage = gas_df['usage_cubic_meters'].mean() returnf"所有用户的平均用气量为: {avg_usage:.2f} 立方米" except Exception as e: returnf"计算平均用气量时出错: {str(e)}"defget_max_usage_record(_) -> str: """获取单次用气量最高的记录。不需要参数""" try: max_row = gas_df.loc[gas_df['usage_cubic_meters'].idxmax()] return (f"单次最高用气记录:用户ID {max_row['user_id']}, " f"类型 {max_row['user_type']}, " f"日期 {max_row['date']}, " f"用量 {max_row['usage_cubic_meters']} 立方米") except Exception as e: returnf"获取最高用气记录时出错: {str(e)}"defcount_users_by_type(_) -> str: """统计各类用户的数量。不需要参数""" try: counts = gas_df['user_type'].value_counts().to_dict() # 格式化输出字符串 result_str = ", ".join([f"{k}: {v}户"for k, v in counts.items()]) returnf"用户类型统计: {result_str}" except Exception as e: returnf"统计用户数量时出错: {str(e)}"# 将函数包装成 LangChain 的 Tool 对象tools = [ Tool( name="AvgUsage", func=calculate_average_usage, description="计算指定类型用户(如居民、商业、工业)的平均用气量。输入应为用户类型字符串。" ), Tool( name="MaxUsage", func=get_max_usage_record, description="获取系统中单次用气量最高的那条记录。不需要输入参数。" ), Tool( name="UserStats", func=count_users_by_type, description="统计系统中不同类型用户的数量。不需要输入参数。" )]# ================= 3. 模型初始化 =================# 初始化 DeepSeek 模型llm = ChatOpenAI( model="deepseek-chat", temperature=0, api_key=API_KEY, base_url=BASE_URL)# ================= 4. 提示词设计 =================# 从 LangChain Hub 拉取标准的 ReAct 提示词模板# 这一步会联网下载 prompt,如果网络不通,可以使用下面的本地 prompt 备选方案try: prompt = hub.pull("hwchase17/react") print("成功从 Hub 加载 ReAct Prompt。")except Exception as e: print(f"Hub 连接失败 ({e}),使用本地默认 Prompt。") from langchain_core.prompts import PromptTemplate template = """Answer the following questions as best you can. You have access to the following tools:{tools}Use the following format:Question: the input question you must answerThought: you should always think about what to doAction: the action to take, should be one of [{tool_names}]Action Input: the input to the actionObservation: the result of the action... (this Thought/Action/Action Input/Observation can repeat N times)Thought: I now know the final answerFinal Answer: the final answer to the original input questionBegin!Question: {input}Thought:{agent_scratchpad}""" prompt = PromptTemplate.from_template(template)# ================= 5. 创建 Agent 并执行 =================# 创建 ReAct Agentagent = create_react_agent(llm, tools, prompt)# 创建 AgentExecutor,这是实际运行 Agent 的循环控制器agent_executor = AgentExecutor( agent=agent, tools=tools, verbose=True, # 设置为 True 可以在控制台看到详细的思考过程 handle_parsing_errors=True, # 自动处理解析错误 max_iterations=5# 限制最大思考步数,防止死循环)if __name__ == "__main__": print("="*50) print("燃气数据分析智能体已启动 (基于 LangChain + DeepSeek)") print("="*50) # 测试问题 1:单步工具调用 query1 = "工业用户的平均用气量是多少?" print(f"\n用户提问: {query1}\n") response1 = agent_executor.invoke({"input": query1}) print(f"\n最终回答: {response1['output']}") print("\n" + "="*50 + "\n") # 测试问题 2:多步推理 # 这个问题需要先统计用户类型,或者先看最高记录,取决于模型如何理解 query2 = "请分析一下我们的数据,告诉我哪种类型的用户单次用气量最高?" print(f"\n用户提问: {query2}\n") response2 = agent_executor.invoke({"input": query2}) print(f"\n最终回答: {response2['output']}")
输出结果:

代码说明:
1、Tool 类:
- • 我们将普通的 Python 函数(如 calculate_average_usage)封装成了 Tool 对象。
- • description 参数非常重要。ReAct 模式下,模型完全依赖这个描述来决定何时调用该工具。描述越清晰,模型表现越好。
- 2、hub.pull(“hwchase17/react”):
- • 这是 LangChain 社区维护的标准 ReAct 提示词模板。它包含了 “Question:”, “Thought:”, “Action:” 等格式指令。
- • 代码中加入了 try-except,如果你的本地环境无法连接 LangChain Hub,它会自动切换到内置的 Prompt 模板,保证代码可运行。
- 3、AgentExecutor:
- • 这是 LangChain 的核心引擎。它负责执行 Thought -> Action -> Observation 的循环。
- • verbose=True:这是体验 ReAct 的关键。开启后,你会在终端看到模型每一步的“思考”和“行动”,而不仅仅是最终结果。
- • handle_parsing_errors=True:如果模型输出的格式不对(比如 DeepSeek 没有严格按照 “Action: …” 输出),Executor 会尝试自动修正或重试,而不是直接报错崩溃。
注:代码是ai生成,提高了生成力,所以简单把对应的代码核心内容也附加说明,这一方法强调外部实施,门槛较低,便于燃气智能体开发,这里案例是写的和我行业相关的燃气,其他场景也都是可以适用,重要的是思想。
- ReAct范式的Mermaid架构图
ReAct的架构展示TAO闭环的动态过程。
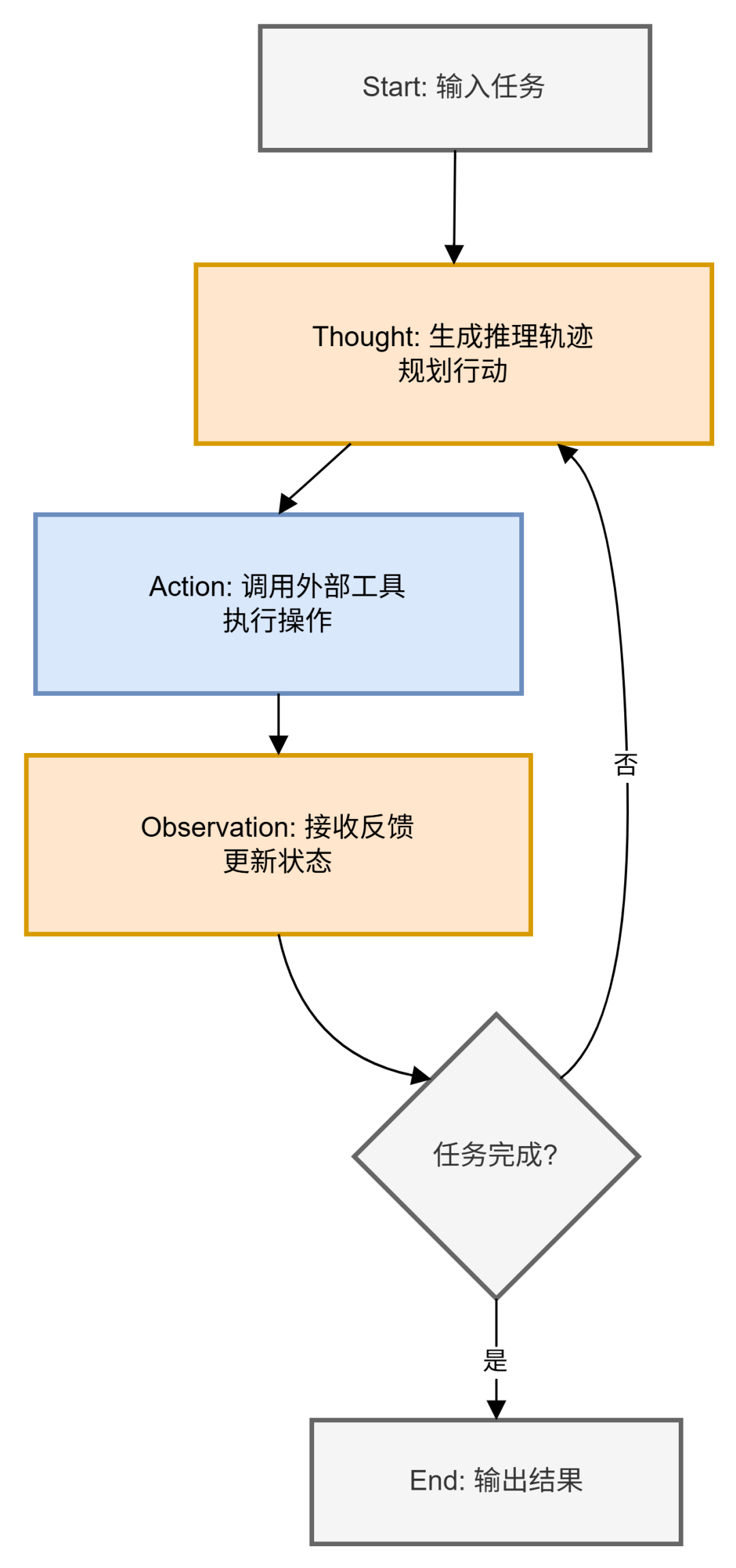
该图描绘了迭代循环:从推理开始,经行动和观察反馈,返回规划,直至终结。外部工具在Action节点集成,确保闭环的完整性。
- 总结
ReAct范式通过TAO闭环机制,提供强大的推理-行动协同功能。其作用在于提升准确性和可解释性,适用于交互密集的任务。变体发展扩展了其适应性,实施方法简洁,依赖提示和工具。总体而言,ReAct标志着AI代理发展的关键一步,提供高效框架,值得深入探索。
每日一学
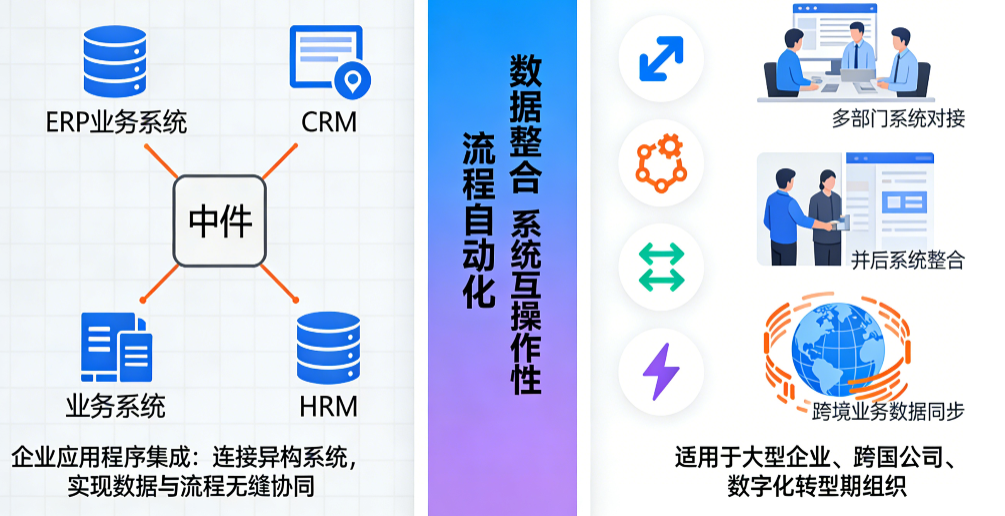
企业应用程序集成 (Enterprise Application Integration)
在企业信息化领域,EAI 是指通过技术和流程实现不同部门应用程序之间自动化的信息交换。
• 核心功能: 它的目标是连接企业内原本独立的系统(如工资管理、ERP、CRM),消除“数据孤岛”,确保数据在不同应用间自由流转,从而实现业务流程自动化并提高生产力。
• 工作模式(中心辐射型): EAI 常被视为一种“中心辐射型”(Hub-and-Spoke)集成模式。在此架构中,使用一个集中式的代理(HUB)作为中介,所有的系统都通过适配器(Adapter)连接到这个中心。HUB 负责处理消息路由、转换和重新解释。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)