从0到1:手把手教你构建MCP应用(上)
本文介绍了ModelContextProtocol(MCP)的基本概念和实践指南。MCP是一种标准化协议,通过Resources(资源)、Tools(工具)和Prompts(提示词)三大核心原语,实现AI应用与外部系统的安全集成。文章详细演示了如何从零开始构建MCP应用,包括环境搭建、简单示例实现、数据库查询案例开发,以及如何与ClaudeDesktop集成。同时提供了MCPInspector调试
"如果你听过也玩过MCP"
“那你就会觉得这不就是AI时代的USB-C”
确实,这就是我要写的主题——Model Context Protocol(MCP),一个正在改变AI集成方式的标准协议。
今天这篇文章,我不讲大道理,就教你从0到1,亲手构建一个MCP应用。
准备工作:环境搭建
开始之前,得先把环境准备好。别担心,很简单,三步搞定。
第一步:安装Python环境
MCP官方SDK支持TypeScript和Python两种语言。作为Python用户,我用Python版本演示。
确保你安装了Python 3.9或更高版本:
python --version如果没装,去python.org下载安装就行。
第二步:创建项目目录
mkdir mcp-demo
cd mcp-demo
python -m venv venv
source venv/bin/activate # Windows用 venv\Scripts\activate创建虚拟环境是个好习惯,避免污染全局环境。
第三步:安装MCP SDK
pip install mcp这个包包含了构建MCP Server所需的所有工具。
安装完成后,可以用以下命令验证:
python -c "import mcp; print(mcp.__version__)"如果能打印出版本号,说明安装成功了。
Step 1:创建最简单的MCP Server
让我们从最简单的例子开始——一个能返回当前时间的MCP Server。
创建一个文件 time_server.py:
#!/usr/bin/env python3
"""
最简单的MCP Server示例:获取当前时间
"""
import asyncio
from datetime import datetime
from mcp.server import Server
from mcp.server.stdio import stdio_server
# 创建Server实例
app = Server("time-keeper")
# 注册一个Tool
@app.tool()
async def get_current_time() -> str:
"""获取当前的精确时间,包含时区信息"""
return datetime.now().isoformat()
# 主函数
async def main():
async with stdio_server() as (read_stream, write_stream):
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
if __name__ == "__main__":
asyncio.run(main())就这几行代码,一个MCP Server就完成了。
运行它:
python time_server.py等等,现在它只是在运行,但没有人连接它。我们需要一个Client来测试。
用MCP Inspector测试
MCP官方提供了一个调试工具叫MCP Inspector,专门用来测试和调试MCP Server。
安装:
npm install -g @modelcontextprotocol/inspector运行:
mcp-inspector python time_server.py你会看到一个Web界面,左边是可用工具列表,右边是执行结果。
点击 get_current_time 工具,应该能看到类似这样的输出:
2026-01-29T14:53:32.123456
成功!你的第一个MCP Server已经工作了。
Step 2:理解核心概念
刚才的例子虽然简单,但已经展示了MCP的核心概念。让我详细解释一下。
什么是MCP Server?
MCP Server本质上是一个程序,它通过标准化协议向AI应用暴露功能。
它可以:
• 提供数据访问(如文件系统、数据库)
• 提供工具调用(如发送邮件、执行命令)
• 提供提示词模板(如帮助用户更好地使用AI)
MCP的三大核心原语
MCP协议定义了三种核心对象,我称之为"三大核心原语":
1. Resources(资源)
Resources是服务器向客户端公开的只读数据,类似于文件。
每个资源有唯一的URI标识,比如:
• file:///home/user/documents/report.pdf
• postgres://database/customers/schema
• memory://user-preferences
客户端通过以下方式使用资源:
• resources/list:列出所有可用资源
• resources/read:读取指定资源内容
• resources/templates/list:列出资源模板
举个例子,文件系统MCP Server可以这样定义资源:
@app.resource("file:///{path}")
async def read_file(path: str) -> str:
"""读取指定路径的文件内容"""
with open(path, 'r') as f:
return f.read()2. Tools(工具)
Tools是可执行的函数,这是AI"能做事"的关键。
每个工具有:
• 唯一的name
• 描述description(AI会根据描述选择何时调用)
• 输入参数的JSON Schema
客户端通过以下方式使用工具:
• tools/list:列出所有可用工具
• tools/call:调用指定工具
我们在Step 1中已经见过一个例子:
@app.tool()
async def get_current_time() -> str:
"""获取当前的精确时间,包含时区信息"""
return datetime.now().isoformat()这个工具的name是 get_current_time,AI会根据描述"获取当前的精确时间"来决定何时调用它。
3. Prompts(提示词)
Prompts是预定义的提示词模板,帮助用户更好地与AI交互。
服务器可以提供写好的prompt,比如:
• Git Server提供 review_diff prompt:自动获取当前变更并进行代码审查
• Sentry Server提供 analyze_error prompt:自动分析报错堆栈
客户端通过以下方式使用提示词:
• prompts/list:列出所有可用提示词
• prompts/get:获取指定提示词内容
举个例子:
@app.prompt("analyze-code")
async def analyze_code_prompt() -> str:
"""代码分析提示词模板"""
return """
请分析以下代码:
1. 检查潜在的bug
2. 评估代码质量
3. 提供改进建议
4. 评估性能影响
请保持客观,提供具体的改进方案。
"""
MCP的架构:三层设计
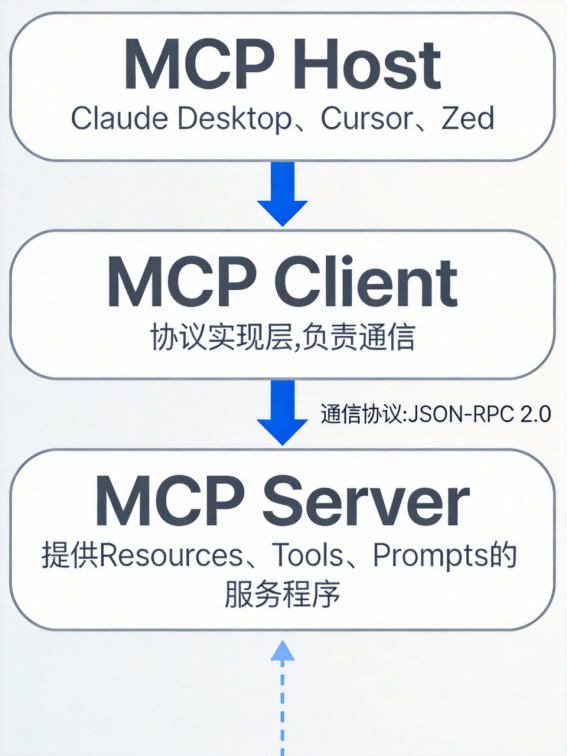
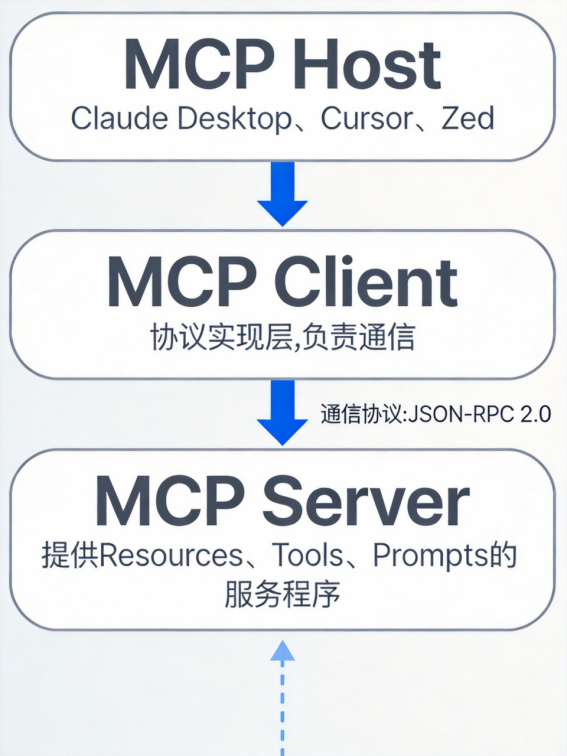
理解了三大原语,我们来看MCP的整体架构。
MCP采用客户端-服务器架构,包含三个核心组件:
1. MCP Host(宿主应用)
◦ 用户直接交互的AI应用
◦ 比如:Claude Desktop、Cursor、Zed、各种AI IDE
◦ 发起请求,协调多个MCP Server
2. MCP Client(客户端)
◦ 在Host内部运行,负责与Server通信
◦ 每个Server有一个对应的Client(1:1连接)
◦ 处理协议细节、安全、认证
3. MCP Server(服务器)
◦ 提供特定功能的程序
◦ 连接各种数据源(数据库、文件系统、API等)
◦ 通过MCP协议暴露Resources、Tools、Prompts
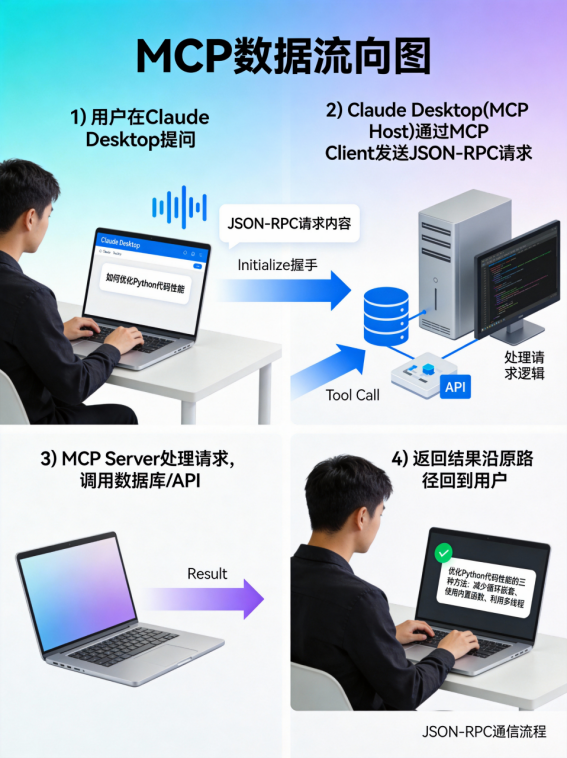
通信协议:JSON-RPC 2.0
MCP使用JSON-RPC 2.0作为通信协议。这是一个轻量级的远程过程调用协议,使用JSON格式传输数据。
典型的JSON-RPC消息格式:
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "get_current_time",
"arguments": {}
}
}响应:
{
"jsonrpc": "2.0",
"id": 1,
"result": "2026-01-29T14:53:32.123456"
}传输方式:stdio 和 SSE
MCP支持两种主要的传输方式:
1. stdio(标准输入输出)
• 最简单的方式
• 通过子进程启动Server
• 通过stdin/stdout通信
• 适合本地开发
2. SSE(Server-Sent Events)
• 基于HTTP的长连接
• 适合远程部署
• 支持实时推送
stdio更简单、安全;SSE更灵活、适合云端。
Step 3:实现一个实际案例
理论讲完了,让我们实现一个更实际的案例——数据库查询MCP Server。
这个场景很常见:AI需要访问企业数据库来回答用户问题。
准备工作
先创建一个SQLite数据库用于测试:
# create_test_db.py
import sqlite3
# 创建内存数据库
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# 创建用户表
cursor.execute('''
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE,
department TEXT,
join_date DATE
)
''')
# 插入测试数据
test_users = [
(1, "张三", "zhangsan@example.com", "技术部", "2024-01-15"),
(2, "李四", "lisi@example.com", "市场部", "2024-03-20"),
(3, "王五", "wangwu@example.com", "技术部", "2024-05-10"),
(4, "赵六", "zhaoliu@example.com", "人事部", "2024-07-01"),
]
cursor.executemany('''
INSERT INTO users (id, name, email, department, join_date)
VALUES (?, ?, ?, ?, ?)
''', test_users)
conn.commit()
conn.close()
print("测试数据库创建完成")运行一下:
python create_test_db.py实现MCP Server
创建 database_server.py:
#!/usr/bin/env python3
"""
数据库查询MCP Server
支持安全、受限的SQL查询
"""
import sqlite3
import asyncio
from typing import List, Dict, Any
from mcp.server import Server
from mcp.server.stdio import stdio_server
from mcp.types import Tool, TextContent
# 创建Server实例
app = Server("database-connector")
# 数据库连接
DB_PATH = "test_users.db"
def get_db_connection():
"""获取数据库连接"""
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row # 返回字典形式
return conn
# Tool 1: 列出所有表
@app.tool()
async def list_tables() -> str:
"""列出数据库中所有表名"""
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = cursor.fetchall()
conn.close()
table_names = [row[0] for row in tables]
return f"数据库中的表: {', '.join(table_names)}"
# Tool 2: 查询表结构
@app.tool()
async def describe_table(table_name: str) -> str:
"""
查询指定表的结构信息
Args:
table_name: 表名
"""
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute(f"PRAGMA table_info({table_name})")
columns = cursor.fetchall()
conn.close()
result = f"表 '{table_name}' 的结构:\n"
for col in columns:
result += f" - {col[1]} ({col[2]})\n"
return result
# Tool 3: 安全执行SELECT查询
@app.tool()
async def execute_select(query: str) -> str:
"""
安全执行SELECT查询(仅允许SELECT语句)
Args:
query: SQL查询语句,必须是SELECT开头
"""
# 安全检查:只允许SELECT查询
query = query.strip()
if not query.upper().startswith('SELECT'):
raise ValueError("仅允许SELECT查询,出于安全考虑")
try:
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute(query)
rows = cursor.fetchall()
conn.close()
if not rows:
return "查询结果为空"
# 格式化结果
result = f"查询返回 {len(rows)} 行结果:\n\n"
# 表头
headers = rows[0].keys()
result += "| " + " | ".join(headers) + " |\n"
result += "|" + "|".join(["---" for _ in headers]) + "|\n"
# 数据行
for row in rows:
result += "| " + " | ".join(str(val) for val in row) + " |\n"
return result
except Exception as e:
return f"查询出错: {str(e)}"
# Tool 4: 统计各部门人数
@app.tool()
async def count_by_department() -> str:
"""统计各部门人数"""
conn = get_db_connection()
cursor = conn.cursor()
cursor.execute('''
SELECT department, COUNT(*) as count
FROM users
GROUP BY department
ORDER BY count DESC
''')
results = cursor.fetchall()
conn.close()
result = "各部门人数统计:\n"
for row in results:
result += f" {row['department']}: {row['count']}人\n"
return result
# 主函数
async def main():
async with stdio_server() as (read_stream, write_stream):
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
if __name__ == "__main__":
asyncio.run(main())这个Server提供了4个工具:
1. list_tables:列出所有表
2. describe_table:查看表结构
3. execute_select:执行SELECT查询(有安全检查)
4. count_by_department:统计部门人数
测试Server
用MCP Inspector测试:
mcp-inspector python database_server.py尝试调用各个工具:
5. 调用 list_tables,应该看到 users 表
6. 调用 describe_table,传入 table_name="users",应该看到表结构
7. 调用 execute_select,传入 query="SELECT * FROM users LIMIT 3",应该看到前3条记录
8. 调用 count_by_department,应该看到部门统计
Step 4:客户端集成(Claude Desktop示例)
现在Server已经准备好了,让我们把它集成到Claude Desktop中,让真正的AI模型来使用它。
Claude Desktop配置
Claude Desktop是Anthropic官方的AI聊天应用,原生支持MCP。
在macOS上,配置文件位于:
~/Library/Application Support/Claude/claude_desktop_config.json在Windows上,配置文件位于:
%APPDATA%\Claude\claude_desktop_config.json编辑这个文件,添加你的MCP Server配置:
{
"mcpServers": {
"time-keeper": {
"command": "python",
"args": ["/path/to/mcp-demo/time_server.py"]
},
"database": {
"command": "python",
"args": ["/path/to/mcp-demo/database_server.py"]
}
}
}注意要把路径改成你自己的实际路径。
重启Claude Desktop
保存配置后,重启Claude Desktop。
现在,在Claude的对话中,你可以直接说:
"现在几点了?"
Claude会自动调用 get_current_time 工具,然后回答你。
"统计一下各部门有多少人"
Claude会自动调用 count_by_department 工具,然后给你结果。
"帮我查询技术部的所有员工"
Claude会:
1. 先调用 describe_table 了解表结构
2. 然后调用 execute_select 执行 SELECT * FROM users WHERE department='技术部'
3. 把结果整理成人类可读的格式回答你
这就是MCP的强大之处——AI模型会根据需要自动选择和调用工具,不需要你写任何集成代码。
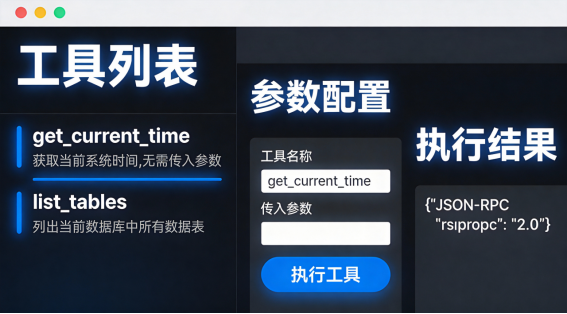
Step 5:测试与调试(MCP Inspector)
在开发过程中,MCP Inspector是你的好朋友。它提供了:
1. 可视化工具列表:看到所有可用的Tools、Resources、Prompts
2. 交互式测试:直接点击调用工具,查看结果
3. 请求/响应日志:看到底层的JSON-RPC消息
4. 连接状态监控:确认Server是否正常连接
使用技巧
技巧1:快速验证Server启动
mcp-inspector python your_server.py如果能看到工具列表,说明Server启动成功,协议握手正常。
技巧2:测试工具参数
在Inspector中,每个工具都有参数表单。你可以填入参数值,点击"Call"来测试。
对于复杂参数,可以先在Inspector中测试好,再交给AI调用。
技巧3:查看原始消息
Inspector的"Logs"标签页会显示原始的JSON-RPC消息。
当工具调用失败时,查看原始消息能帮你快速定位问题。
比如,如果看到参数格式错误,可能是你的JSON Schema定义有问题。
技巧4:调试能力交换
连接建立时,Client和Server会进行"能力交换"(Capability Exchange)。
Inspector会显示Server声明的能力:
• 支持哪些Resource
• 支持哪些Tool
• 支持哪些Prompt
• 支持哪些协议特性
如果你的工具没有出现,检查一下装饰器是否正确使用。
最佳实践与注意事项
开发MCP Server时,有一些最佳实践值得遵守。
1. 安全第一
永远不要盲目信任输入。
即使AI调用你的工具,也要进行参数验证:
@app.tool()
async def delete_file(path: str) -> str:
"""删除指定文件"""
# 路径验证:防止路径遍历攻击
if ".." in path or path.startswith("/"):
raise ValueError("非法路径")
# 扩展名白名单:防止误删重要文件
allowed_extensions = [".tmp", ".log"]
if not any(path.endswith(ext) for ext in allowed_extensions):
raise ValueError("只允许删除临时文件")
# 执行删除
os.remove(path)
return f"文件 {path} 已删除"2. 错误处理友好
提供清晰的错误信息,帮助AI理解问题:
try:
result = database.query(sql)
return format_result(result)
except sqlite3.OperationalError as e:
if "syntax error" in str(e):
return f"SQL语法错误: {e}\n建议检查SQL语句格式"
elif "no such table" in str(e):
return f"表不存在: {e}\n请先用list_tables查看可用表"
else:
return f"数据库操作失败: {e}"3. 工具描述要准确
AI会根据工具描述来决定何时调用。描述要准确、具体:
# ❌ 不好:太模糊
@app.tool()
async def get_data() -> str:
"""获取数据"""
...
# ✅ 好:明确说明了功能和适用场景
@app.tool()
async def get_user_by_email(email: str) -> str:
"""
根据邮箱地址查询用户信息。
仅用于查询用户详情,不支持批量查询。
Args:
email: 用户的邮箱地址,必须包含@符号
"""
...4. 性能优化
对于耗时操作,考虑异步处理:
import asyncio
@app.tool()
async def analyze_large_dataset(dataset_id: str) -> str:
"""
分析大型数据集(可能需要几分钟)
Args:
dataset_id: 数据集ID
"""
# 启动后台任务
task_id = asyncio.create_task(
perform_analysis(dataset_id)
)
# 返回任务ID,让用户可以稍后查询结果
return f"分析任务已启动,任务ID: {task_id.get_name()}"
@app.tool()
async def check_task_status(task_id: str) -> str:
"""检查任务执行状态"""
...5. 日志记录
添加详细的日志,方便调试:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@app.tool()
async def complex_operation(param: str) -> str:
logger.info(f"开始执行复杂操作,参数: {param}")
try:
result = do_something(param)
logger.info(f"操作成功完成,结果: {result}")
return result
except Exception as e:
logger.error(f"操作失败: {e}", exc_info=True)
return f"操作失败: {e}"
本篇内容还未结束下期再见!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)