基于 YOLOv8 的人脸表情检测识别系统(Python源码 + Flask+数据集)
一个基于YOLOv8的人脸情绪识别实战项目,集成了Flask框架实现前后端交互。项目支持图片、视频和摄像头三种输入方式,提供完整的训练、验证和推理流程。核心功能包括:拖拽上传图片识别、视频流式标注、摄像头实时检测等,并采用YOLOv8的持久化追踪技术提升视频场景稳定性。技术栈包含YOLOv8、Flask、Tailwind CSS等,项目结构清晰,提供一键运行脚本,适合新手快速上手。文章详细说明了数
想上手人脸情绪识别实战、玩转 YOLOv8?这款现成的成品项目直接帮你省掉所有试错成本!它以超适合新手的 YOLOv8 为核心,不仅打通前后端、支持图片 / 视频 / 摄像头多场景一键运行,还包含完整的模型训练与验证流程,高颜值、高实用性拉满,零基础也能轻松解锁目标检测全链路技能!
一、项目背景与目标
- 人脸表情识别在教育、医疗、人机交互等场景有广泛应用。本文结合 YOLOv8 与 Flask,构建一个既适合本地演示、又便于二次开发的完整系统。
- 目标:统一本地图片、视频文件与摄像头三种输入,前后端打通,一键运行,支持推理结果可视化与置信度分析。
二、功能一览
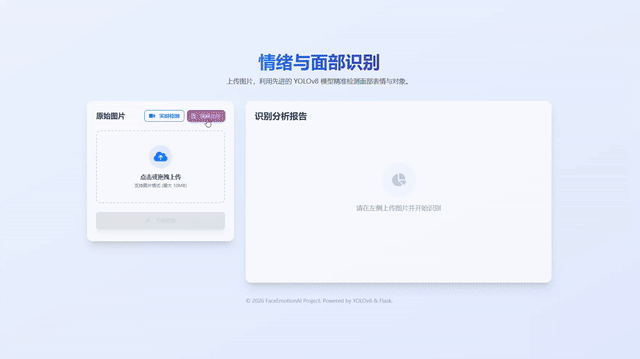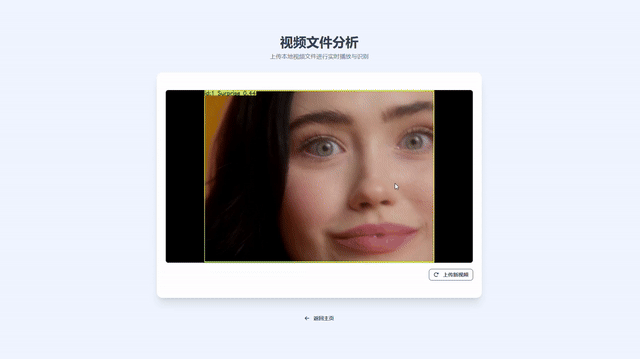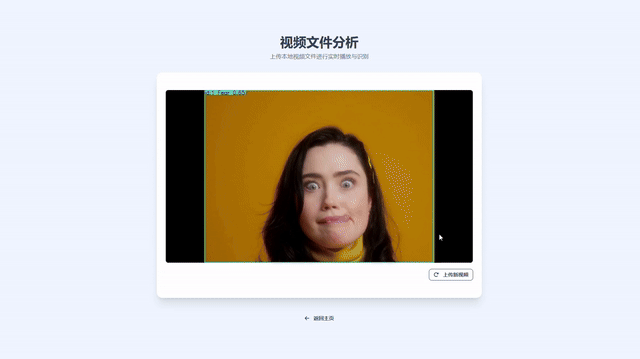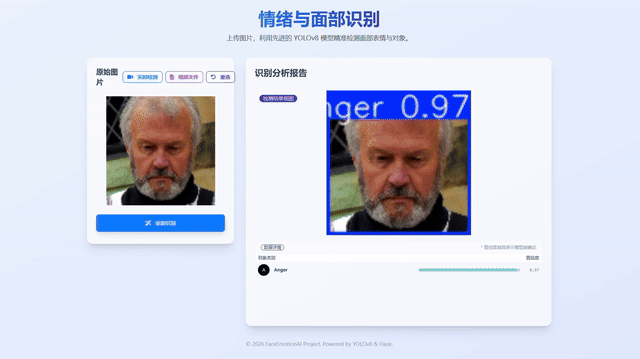
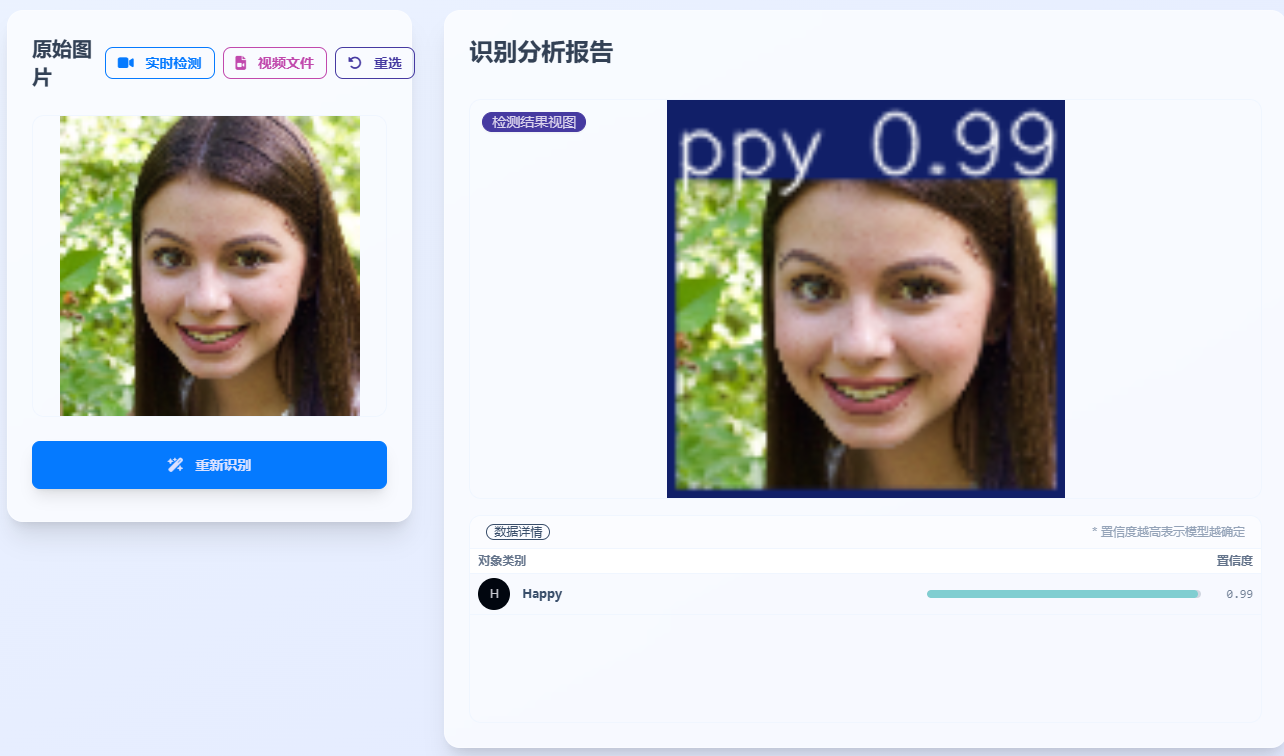
- 图片识别:上传单张图片,返回带框标注的结果图与类别置信度表格。
- 视频文件识别:上传视频并进行流式回放,边播放边显示标注结果(MJPEG)。
- 摄像头实时检测:直接调用本地摄像头,持续检测并展示结果。
- 命令行调试:一条命令即可对图片/视频/摄像头进行推理与结果保存。
三、技术栈与架构
- 后端与推理:Flask + Ultralytics YOLOv8 + OpenCV
- 前端:Tailwind CSS + DaisyUI(CDN)
- 跟踪增强:YOLOv8
track(..., persist=True)持久化追踪,提升视频场景稳定性
核心文件:
- Web 后端与路由:[app.py]
- 首页(图片识别):[index.html]
- 视频分析页:[templates/video.html]
- 实时检测页:[templates/live.html]
- 训练脚本:[train.py]
- 命令行推理:[detect.py]
四、源码获取和环境配置
我把所有代码都准备好了,你只需要 2 步无脑操作:
-
下载完整代码包
我把能直接运行的 YOLOv11 手写数字识别系统整理好了,你只需要在软件内点击【一键运行】按钮,一键获取所有文件(包含模型、前端页面、训练脚本),不用自己写一行代码、加一句注释。
-
单击【一键运行 】→ 直接玩
稍等片刻打开浏览器访问
http://127.0.0.1:5000,在画板上随便写个数字,AI 瞬间就能认出来,全程不用调试、不用改模型,5分钟就能玩上你自己部署的 AI 系统!
在「代码社区」中选择「目标检测&图像处理」:
1.首页–代码社区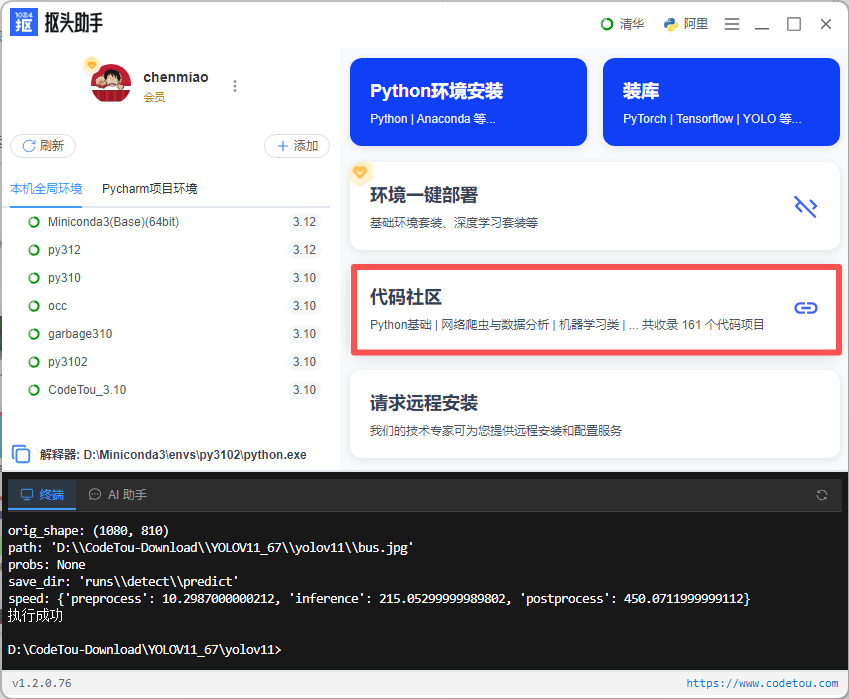
2.代码社区–目标检测&图像处理–基于yolov8的情绪识别系统,点击一键运行既可以完成代码下载和环境配置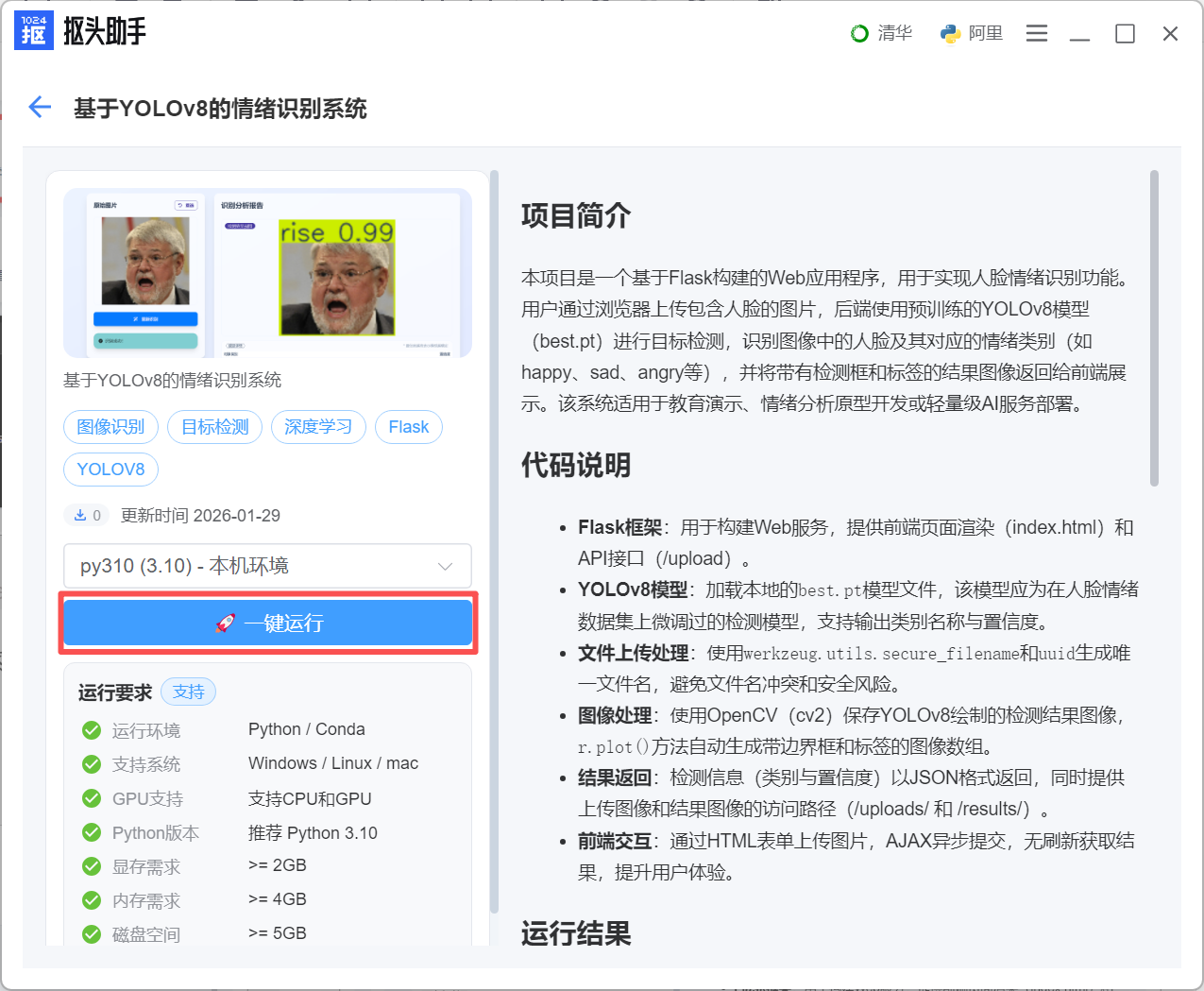
3.运行后会自动启动pycharm 打开这个项目,直接运行app.py 既可体验效果。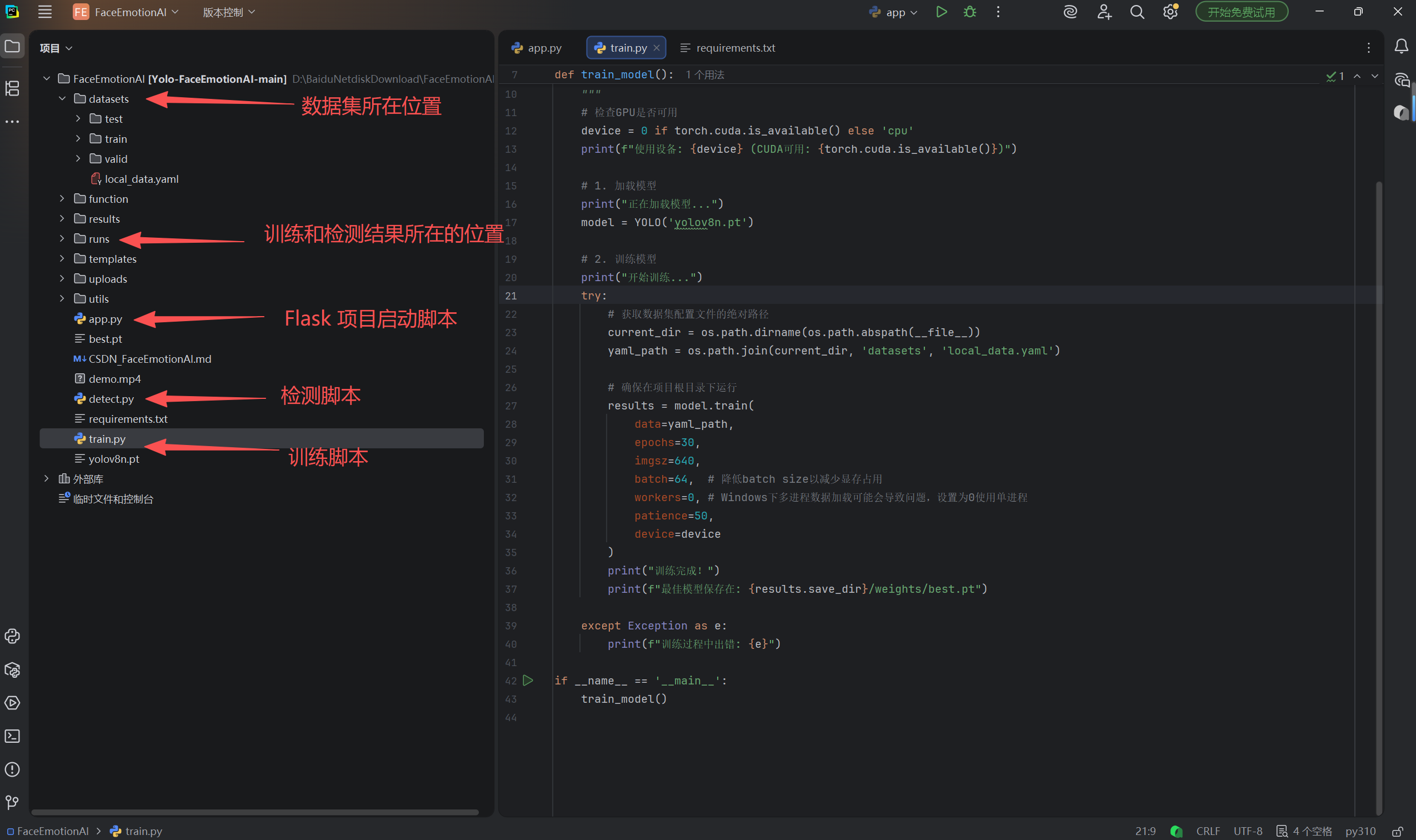
4.浏览器上输入http://127.0.0.1:5000 可以看到运行效果。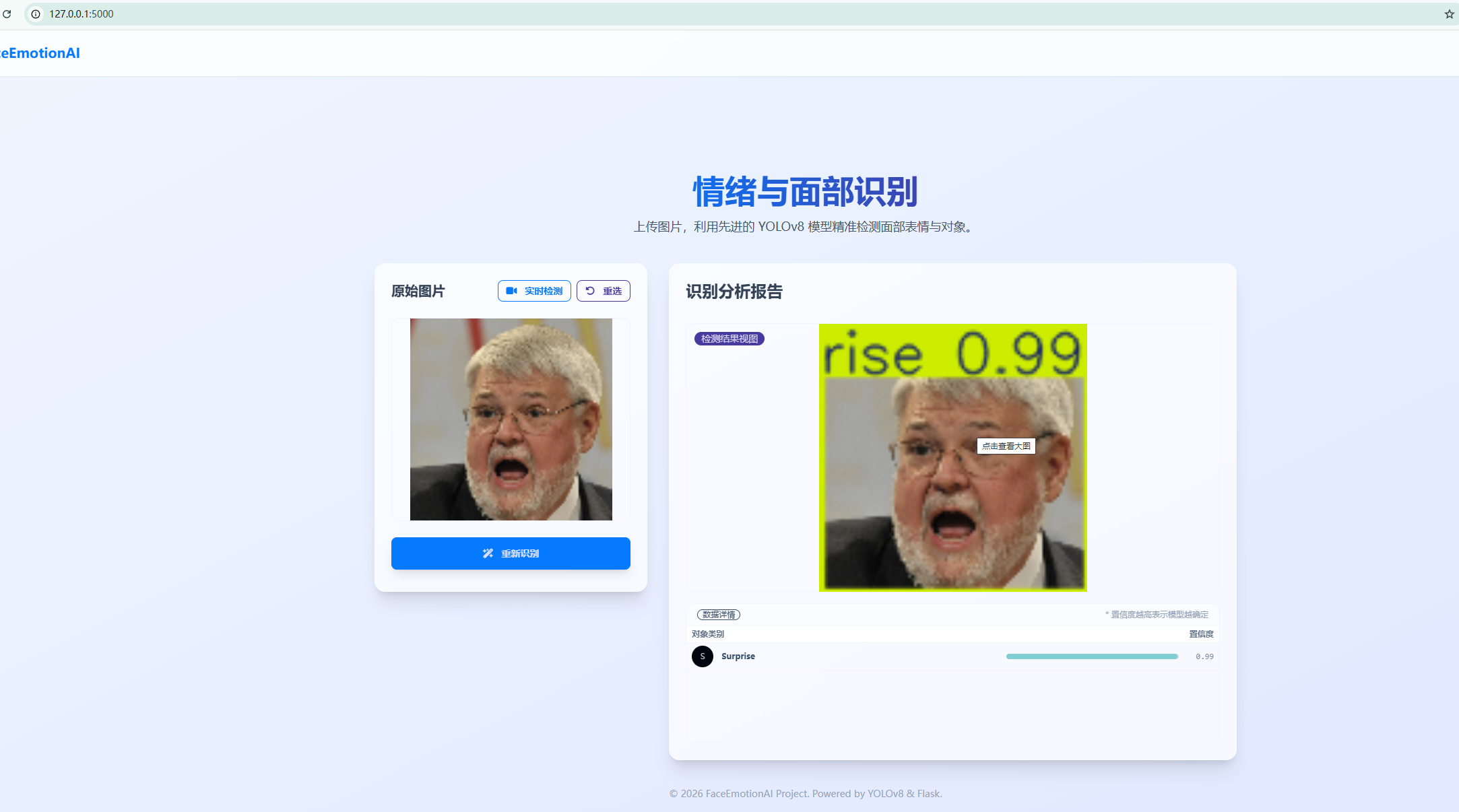
抠头助手:下载工具获取源码
五、数据集与类别定义
- 数据集来源:https://www.kaggle.com/datasets/fatihkgg/affectnet-yolo-format
- 数据集 YAML:[datasets/local_data.yaml]
- 8 类基本情绪:Anger, Contempt, Disgust, Fear, Happy, Neutral, Sad, Surprise
nc: 8
names:
0: Anger
1: Contempt
2: Disgust
3: Fear
4: Happy
5: Neutral
6: Sad
7: Surprise
六、训练与模型产出
python train.py
## 训练脚本,运行此脚本,会开始训练
from ultralytics import YOLO
import os
import torch
def train_model():
"""
训练YOLOv8模型用于情绪识别
"""
# 检查GPU是否可用
device = 0 if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {device} (CUDA可用: {torch.cuda.is_available()})")
# 1. 加载模型
print("正在加载模型...")
model = YOLO('yolov8n.pt')
# 2. 训练模型
print("开始训练...")
try:
# 获取数据集配置文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
yaml_path = os.path.join(current_dir, 'datasets', 'local_data.yaml')
# 确保在项目根目录下运行
results = model.train(
data=yaml_path,
epochs=30,
imgsz=640,
batch=64,
workers=0,
patience=50,
device=device
)
print("训练完成!")
print(f"最佳模型保存在: {results.save_dir}/weights/best.pt")
except Exception as e:
print(f"训练过程中出错: {e}")
if __name__ == '__main__':
train_model()
- 默认加载
yolov8n.pt作为初始权重,训练完成输出best.pt用于后续推理。 - Windows 下数据加载采用
workers=0以避免多进程问题。
七、Web 使用与演示流程
- 启动后端:
python app.py # 打开浏览器访问 http://localhost:5000 - 图片识别:在首页上传图片,点击“开始识别”,右侧展示结果图与置信度表。
- 视频文件识别:进入“视频文件”页面上传本地视频,即可边播放边标注。
- 摄像头实时检测:进入“实时检测”页面,调用本地摄像头持续分析。
八、命令行推理(快速验证)
python detect.py
九、关键实现细节(稳定性与体验)
- 静态图片推理使用
model.predict(...),避免复用追踪状态导致错判。 - 视频/摄像头场景使用
model.track(..., persist=True, conf=0.25),跨帧保持框稳定,观感更好。 - 在图片/视频/摄像头切换时,显式重置预测器以清理旧状态:
# app.py 片段
if hasattr(model, 'predictor') and model.predictor is not None:
model.predictor = None
十、前端交互与可视化
- 首页支持拖拽上传与进度提示,结果图可一键新窗口放大查看。
- 置信度表采用进度条视觉化,直观呈现模型确定程度。
- MJPEG 流式播放视频/摄像头标注结果,默认适配常见浏览器。
十一、评估与优化建议
- 数据增强:适度增加复杂光照、遮挡样本,提升鲁棒性。
- 置信度阈值:根据场景调节
conf,权衡召回与精度。 - 跟踪策略:视频场景优先开启
persist=True,必要时降低帧率以平衡性能。 - 可扩展:注意力机制(如 SE)与更强分割模型可在未来迭代中尝试,但需与现有接口合理串联。
十二、项目结构(简要)
FaceEmotionAI/
├─ app.py # Flask 路由与推理
├─ detect.py # 命令行推理脚本
├─ train.py # 训练脚本
├─ templates/
│ ├─ index.html # 图片识别页
│ ├─ video.html # 视频分析页
│ └─ live.html # 实时检测页
├─ datasets/
│ └─ local_data.yaml # 数据集配置
├─ uploads/ # 上传文件(运行时生成)
└─ results/ # 推理结果图(运行时生成)
十三、常见问题(FAQ)
- 问:为什么视频/摄像头下的框更稳?
- 答:开启了
persist=True的追踪与跨帧状态维护,减少抖动。
- 答:开启了
- 问:图片识别要不要开启 track?
- 答:不建议。静态图用
predict()更干净,避免历史状态干扰。
- 答:不建议。静态图用
- 问:运行时报“模型不存在”?
- 答:先运行训练脚本或把
best.pt放到项目根目录;命令行里通过--model指定路径。
- 答:先运行训练脚本或把
抠头助手:下载工具获取源码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)