九、模型微调的基本概念与流程
总体介绍
微调只训练一部分,冻结大部分。遇到特定行业,原有开源大模型,设计整体调整,一般情况下,目前的大模型已经成熟了,只训练下游任务
微调是指在预训练模型的基础上,通过进一步的训练来适应特定的下游任务。BERT模型通过预训练来学习语言的通用模式,然后通过微调来适应特定任务,如情感分析、命名实体识别等。微调过程中,通常冻结BERT的预训练层,只训练与下游任务相关的层。本课件将介绍如何使用BERT模型进行情感分析任务的微调训练。
我们前面写过一个程序textclass1
import numpy as np
from langchain_community.vectorstores import FAISS
from langchain_huggingface import ChatHuggingFace, HuggingFacePipeline, HuggingFaceEmbeddings
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
pipeline
)
from langchain_huggingface import ChatHuggingFace
# 创建嵌入模型
#:bert-base-chinese 编码器模型
# model_name = r'D:\大模型\RAG_Project\BAAI\bge-large-zh-v1.5'
model_name = r'D:\本地模型\google-bert\bert-base-chinese'
from transformers import AutoModelForSequenceClassification, AutoTokenizer, pipeline
# 加载模型和分词器
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 使用加载的模型和分词器创建分类任务的 pipeline
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer)
# 执行分类任务
output = classifier("你好,我是一款语言模型")
print(output)
'''你遇到的这个提示核心是:bert-base-chinese 是基础预训练模型,没有针对「文本分类」任务的下游微调权重,因此分类头(classifier.bias/classifier.weight)是随机初始化的,直接用于预测会导致结果无意义。下面我会帮你理解提示含义 + 给出两种解决方案(快速测试 / 实际微调),让模型能正常做文本分类。
一、提示信息深度解读
关键内容 含义
Some weights were not initialized BertForSequenceClassification 包含两部分权重:
✅ BERT 基础编码器权重(从bert-base-chinese加载,有效);
❌ 分类头权重(classifier层,随机初始化,无效);
You should probably TRAIN this model on a down-stream task 必须在具体的分类数据集(如情感分析、文本标签)上微调分类头,才能用于预测;
Device set to use cpu 模型已成功加载到 CPU,这是正常提示,无需处理;
简单说:你用的是 “裸的 BERT 骨架”,没有分类任务的 “大脑”,直接分类会得到随机结果。'''输出结果
[{'label': 'LABEL_1', 'score': 0.5192461609840393}] 没有被训练过的模型,只能识别中文,不能实现二分类,下游任务参与训练,bert本身不参与
一、为什么需要模型微调?
在深度学习领域,模型微调 是连接通用预训练模型与特定下游任务的关键技术桥梁。随着BERT、GPT等大规模预训练模型的兴起,微调已成为自然语言处理、计算机视觉等领域的主流范式。
1.1 核心价值
-
数据效率:利用少量标注数据即可获得高性能,做细微调整
-
时间效率:避免从头训练,大幅缩短开发周期,需要高硬件,时长
-
性能优越:在多数任务上超越传统机器学习方法
简言之,节约成本,基于别人训练好的模型的基础上,调整的是模型的能力
二、模型微调的基本概念
2.1 什么是模型微调?
模型微调 是指在预训练模型的基础上,通过使用特定任务的标注数据进行额外的训练,使模型能够适应目标任务的过程。其核心思想是迁移学习——将通用知识迁移到特定领域。
2.2 预训练 vs 微调
|
阶段 |
数据量 |
目标 |
计算成本 |
|---|---|---|---|
|
预训练 |
海量无标注数据 |
学习通用特征表示 |
极高 |
|
微调 |
少量标注数据 |
适配特定任务 |
相对较低 |
2.3 微调的优势
-
知识迁移:保留预训练模型学到的语言/视觉通用知识
-
快速适配:只需少量任务特定数据即可获得良好性能
-
可扩展性:同一预训练模型可适配多种下游任务
三、模型微调的技术流程
3.1 整体流程概览


3.2 详细步骤分解
步骤1:预训练模型选择
根据任务需求选择合适的预训练模型:
-
NLP任务:BERT、RoBERTa、DeBERTa等
-
CV任务:ResNet、ViT、CLIP等
-
多模态任务:VL-BERT、UNITER等
步骤2:任务数据准备(有没有数据)
-
数据收集:获取任务相关的标注数据
-
数据预处理:适配预训练模型的输入格式(清洗,整理)
-
数据增强:通过回译、随机掩码等方式扩充数据
注意
- 需求陷阱:警惕不切实际的AI需求(如全自动视频生成系统)
- 数据壁垒:医疗等敏感领域数据获取困难可能终止项目
- 数据预处理:原始数据需经过清洗、标注、格式转换(如文本编码为词向量)
- 技术选型:根据任务复杂度选择微调策略(全参数/部分参数微调)
开源数据集:
- 开源数据集是指经过他人整理、清洗和标注的现成数据集,可直接用于模型训练。
- 使用场景:适用于快速验证模型效果或教学演示场景,但实际项目中往往需要从原始数据开始处理,
- 数据集格式必须与模型结构严格匹配,在需求分析阶段就需确定数据格式要求。
- 实例说明:如电商图片生成项目,需确保AI生成的宣传图片与实物商品保持高度一致
步骤3:模型架构适配
为下游任务设计适配层:
# 以BERT情感分类为例
from transformers import BertModel, BertPreTrainedModel
import torch.nn as nn
class BertForSentimentAnalysis(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# 添加分类层
self.classifier = nn.Linear(config.hidden_size, 3) # 3个情感类别
def forward(self, input_ids, attention_mask, labels=None):
outputs = self.bert(input_ids, attention_mask=attention_mask)
pooled_output = outputs[1] # [CLS] token的表示
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, 3), labels.view(-1))
return loss, logits
return logits步骤4:微调训练策略
关键训练策略:
-
分层学习率:底层使用较小学习率,顶层使用较大学习率
-
渐进解冻:从顶层开始逐步解冻预训练层
-
早停机制:监控验证集性能防止过拟合
训练配置示例:
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
learning_rate=2e-5, # 较小的学习率
warmup_steps=500,
weight_decay=0.01,
evaluation_strategy='epoch',
save_strategy='epoch',
load_best_model_at_end=True
)步骤5:模型评估与优化
-
评估指标:准确率、F1分数、AUC等
-
错误分析:识别模型的主要错误类型
-
迭代优化:基于分析结果调整模型或数据
- 模型训练的三种状态:
- 欠拟合:模型过于简单,训练集和测试集表现均不佳
- 拟合:模型复杂度适中,达到最佳泛化效果
- 过拟合:模型过度记忆训练数据,测试集表现显著下降
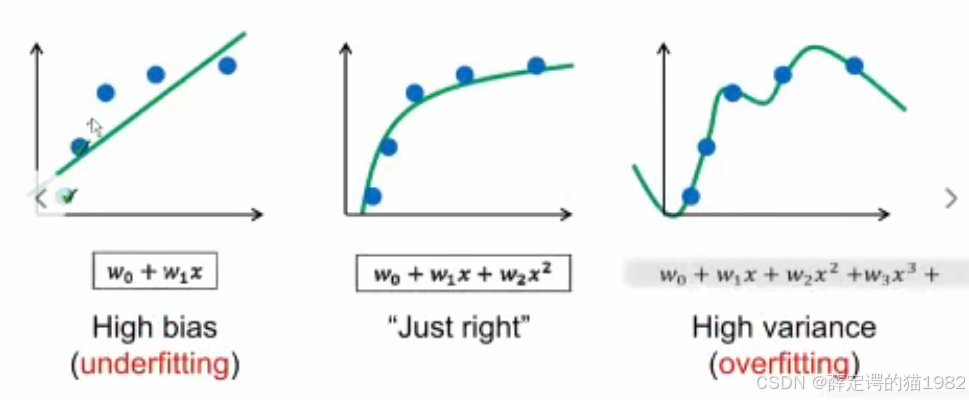
- 欠拟合:模型"还没学好"
- 过拟合:模型"学过了
- "拟合:模型"学好了"
- 过拟合会丧失泛化性
- 拟合保持适当的泛化能力
- 泛化性定义:
- 模型对新数据的适应能力
- 过拟合问题:
- 描述过于细致,包含不必要特征
- 导致对新数据匹配度降低
-
- 正确特征:
- 核心特征:尾巴、基本花色、五官、耳朵、爪子
- 无关特征:
- 绿色毯子、花瓶、胡须长度
- 过拟合后果:
- 模型依赖无关特征(如毯子、花瓶)
- 遇到无这些特征的新猫图片时识别失败
- 泛化性原理:
- 描述过头导致新数据匹配度降低
- 应关注本质特征而非偶然特征
- 正确特征:
判断是否拟合,用损失曲线
损失的判断
- 判断方法
- 数据集划分:
- 训练集:占70%-80%,用于模型训练
- 验证集:占10%,用于训练过程中评估模型状态
- 测试集:占10%-20%,用于最终模型评估
- 现代简化划分:
- 训练集:80%
- 验证/测试集:20%(合并使用)
- 验证集作用:训练过程中评估模型是否出现过拟合
- 测试集作用:训练完成后出具最终评估报告
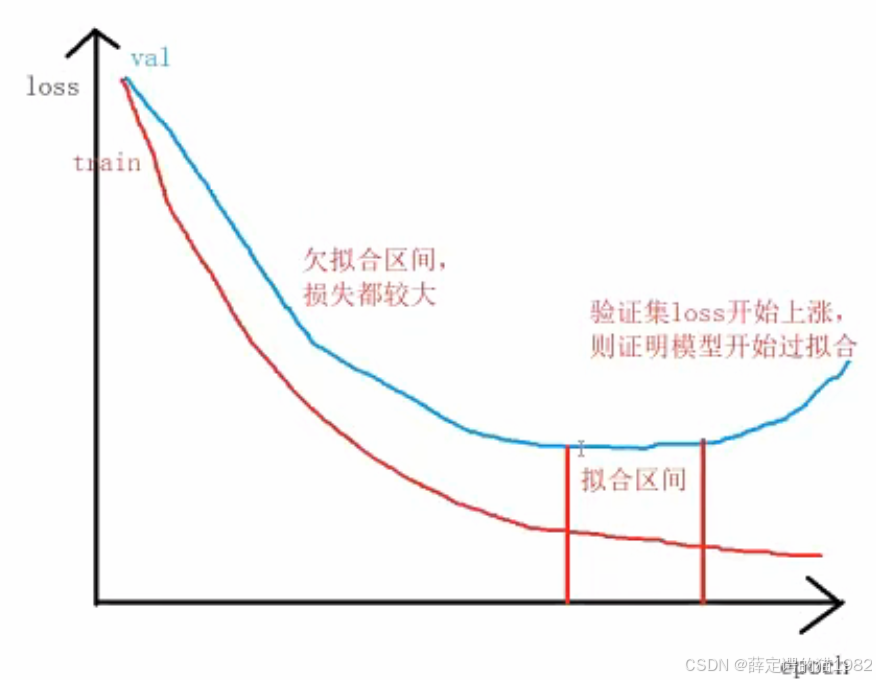
- 也就是说在拟合区间开始可以拿来用,测试
- 数据集划分:
- 损失曲线分析:
- 验证集损失(蓝色):先降后可能上升
- 训练集损失(红色):持续下降
- 关键判断点:
- 欠拟合区间:损失值较大且下降明显
- 拟合区间:验证集损失趋于平缓
- 过拟合点:验证集损失开始上升
- 训练状态判断
- 欠拟合特征:
- 训练集和验证集损失都较大
- 模型尚未学习到数据特征
- 拟合特征:
- 验证集损失达到最低点后趋于稳定
- 模型泛化能力最佳
- 过拟合特征:
- 验证集损失开始上升
- 训练集损失继续下降
- 模型开始记忆训练数据特征
- 训练策略:
- 欠拟合时:继续训练
- 拟合时:可停止训练进行测试
- 过拟合时:应停止训练,考虑正则化或调整模型
- 欠拟合特征:
欠拟合解决方案
- 改进方法:
- 增加模型复杂度(如添加神经网络隐藏层)
- 引入更多有效特征
- 调整超参数(如增大学习率)
过拟合解决方案
- 应对策略:
- 使用正则化技术
- 增加训练数据量
- 采用早停法(Early Stopping)
- 简化模型结构
四、微调策略详解
4.1 冻结策略对比
|
策略 |
训练参数 |
计算成本 |
适用场景 |
|---|---|---|---|
|
完全微调 |
所有参数 |
高 |
数据量充足,任务差异大 |
|
部分冻结 |
仅适配层 |
低 |
数据稀缺,任务相似度高 |
|
渐进解冻 |
分层解冻 |
中 |
平衡性能与效率 |
4.2 学习率策略
# 分层设置学习率示例
optimizer = AdamW([
{'params': model.bert.parameters(), 'lr': 1e-5}, # 预训练层小学习率
{'params': model.classifier.parameters(), 'lr': 5e-4} # 适配层大学习率
])4.3 正则化技术
-
Dropout:防止过拟合
-
权重衰减:控制模型复杂度
-
标签平滑:提高模型鲁棒性
五、实践案例:BERT情感分析微调
5.1 数据准备
from datasets import load_dataset
from transformers import AutoTokenizer
# 加载IMDb电影评论数据集
dataset = load_dataset('imdb')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True, max_length=512)
tokenized_datasets = dataset.map(tokenize_function, batched=True)5.2 模型训练
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test']
)
trainer.train()5.3 模型评估
import numpy as np
from sklearn.metrics import accuracy_score
def compute_metrics(p):
preds = np.argmax(p.predictions, axis=1)
return {'accuracy': accuracy_score(p.label_ids, preds)}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets['train'],
eval_dataset=tokenized_datasets['test'],
compute_metrics=compute_metrics
)六、微调中的常见问题与解决方案
6.1 过拟合问题
-
症状:训练集性能好,验证集性能差
-
解决方案:
-
增加正则化强度
-
使用早停机制
-
数据增强
-
6.2 灾难性遗忘
-
症状:模型忘记预训练学到的通用知识
-
解决方案:
-
使用较小的学习率
-
部分冻结预训练层
-
在预训练目标上联合训练
-
6.3 训练不稳定
-
症状:损失值波动大,梯度爆炸
-
解决方案:
-
梯度裁剪
-
学习率预热
-
使用更稳定的优化器
-
七、进阶微调技术
7.1 参数高效微调
-
Adapter:在预训练层间插入小型适配模块
-
LoRA:通过低秩分解更新权重矩阵
-
Prefix Tuning:在输入前添加可训练的前缀向量
7.2 多任务微调
-
优势:提高模型泛化能力
-
策略:共享底层参数,任务特定顶层
7.3 领域自适应微调
-
目标:适配特定领域(如医疗、法律)
-
方法:在领域无标注数据上继续预训练后再微调
八、模型微调的未来发展趋势
-
更高效的微调方法:降低计算和存储需求
-
自动化微调:自动选择最优微调策略
-
可解释性微调:理解微调过程中的知识变化
-
多模态统一微调:统一处理文本、图像、语音等多模态任务
九、总结
模型微调是连接通用人工智能与具体应用场景的核心技术。通过合理的微调策略,我们可以在保持预训练模型通用能力的同时,赋予其解决特定任务的能力。随着技术的不断发展,微调方法将变得更加高效、智能和可解释,推动人工智能技术在更多领域的落地应用。
关键要点:
-
微调是迁移学习的核心实现方式
-
选择合适的微调策略对性能至关重要
-
数据质量与模型架构同等重要
-
持续监控和优化是微调成功的关键
掌握模型微调技术,将使你能够充分利用现有预训练模型的能力,快速构建高性能的AI应用系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)