【机械臂】【Agent】二、代码结构优化及部分通信字段调整
系列概述
临近本科毕业,考虑到未来读研的方向以及自己的兴趣方向,我选择的课题大致为“基于VLA结构的指令驱动式机械臂仿真系统的实现”。
为什么说是VLA(Vision-Language-Action)“结构”,因为就目前而言,我认为在目前剩下的几个月时间内从0实现一个正儿八经的VLA模型,所需要的时间、资金、模型资源的获取都是比较麻烦的。因此,我选择使用ROS1+LLM+视觉算法来实现一个“伪VLA”结构,就目前阶段(开题一个月)而言,我能给出的场景示意如下:
场景:指令输入“机械臂将蓝色方块夹起放到红色圆柱体上面”,系统接收指令后,先通过视觉模块确定当前系统中各个物体的坐标,再通过开源大模型,结合已知坐标信息,通过预设的prompt生成动作序列,作为参数送入ROS1架构下的启动文件中,实现动作行为在gazebo下的仿真。
当前阶段我能给出粗糙的逻辑示意图如下:
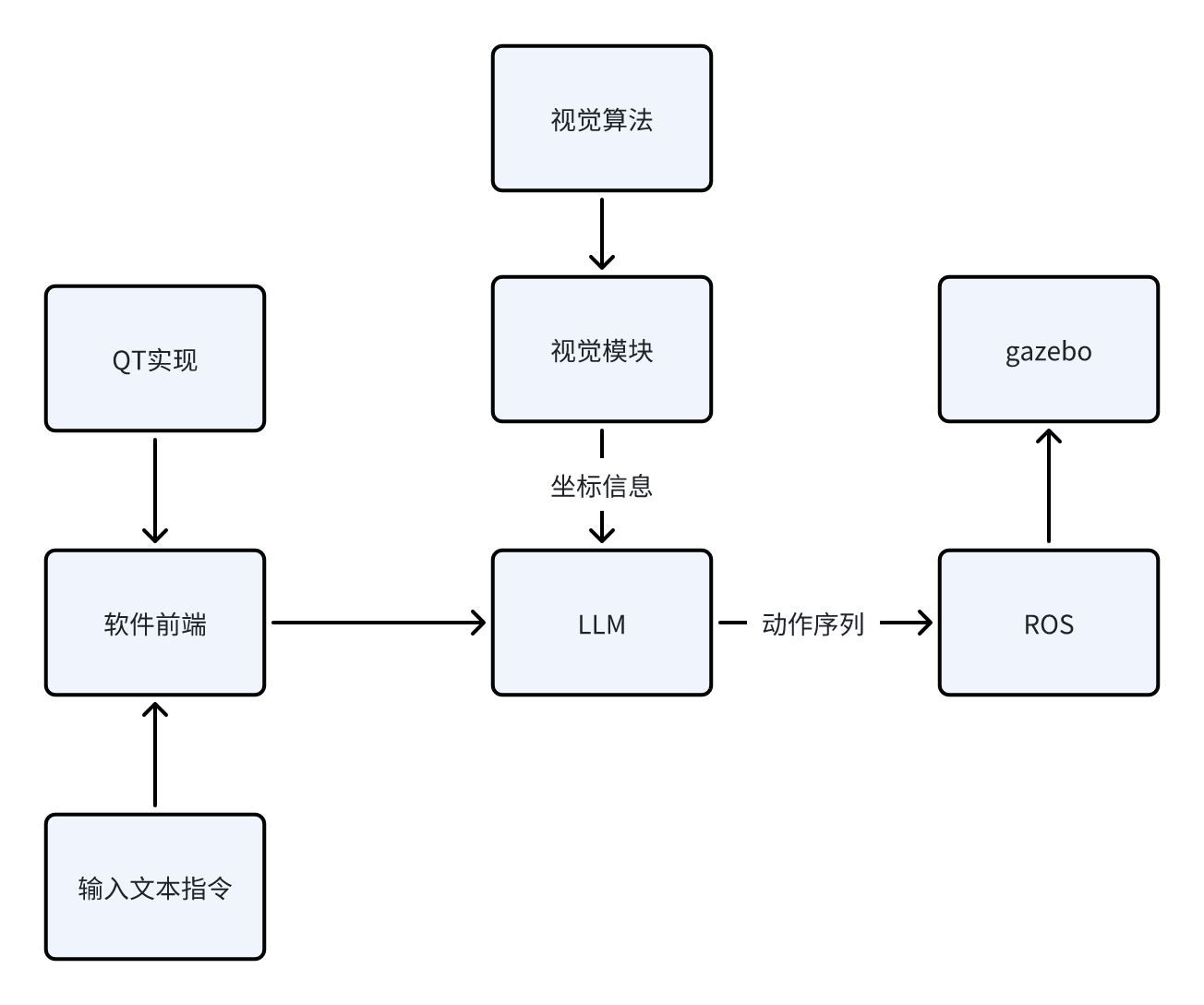
接下来,我将给出目前阶段我所计划的步骤实现,之后该系列的博客都会依照下面的框架进行更新。由于我也是初次入门ROS以及深度学习相关的内容,所以本系列博客更多的充当学习笔记的作用,在书写过程中难免会出现错误以及天真的理论理解,还请各位指正。
我将该项目的实现分成下面几个步骤(每个步骤下的博客会一步一步地更新):
1. 实现机械臂在ROS1+Gazebo环境下的控制、仿真。目标效果是给出任意坐标的方块,机械臂要能稳定的抓取,并放置到指定的坐标。
该步骤博客目录如下:
https://blog.csdn.net/m0_75114363/article/details/156164226?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75114363/article/details/156166592?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_75114363/article/details/156426200?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_75114363/article/details/156544524?spm=1001.2014.3001.5502
2. 加入视觉模块与算法。目标效果是在仿真环境下,对于随意放置的方块,视觉系统需要计算出其真实坐标给予机械臂控制模块,使得机械臂能够实现对其的抓取与放置。
该步骤博客目录如下:
https://blog.csdn.net/m0_75114363/article/details/156641634?spm=1001.2014.3001.5502
3. 加入LLM(本地部署或使用API)。目标效果是对于输入的任意文本指令,LLM能根据预设的prompt,结合视觉系统给予的信息,给予执行模块对应的动作序列,使得机械臂正确地实现输入的文本指令想达到的效果,实现V-L-A的完整交互。
该步骤博客目录如下:
4. 实现整体系统的优化与完善,包括基于QT搭建软件前端、优化模型外观、加入更复杂的机械臂、实现更复杂的指令解析与运行。
该步骤博客目录如下:
我所使用的环境如下:
1. 系统:Ubuntu20.04
2. ROS1:Noetic
项目地址:
https://github.com/Dukiyaaa/Cmd2Action_ROS1
此外,额外说明一下为什么这个项目会选择ROS1做框架而不是更现代的ROS2。其实我在初期也是用的ROS2的框架,但发现机械臂夹爪始终无法夹起物体,网上相关的机械臂开源资料基本都是基于ROS1的,加上ROS1提供了grasp_fix插件可防止物体掉落,所以最终我选择了ROS1做项目框架,同时也希望自己在后期能够在ROS2上成功迁移项目。
章节概述
在之前的文章【机械臂】【Agent】一、Agent与其它模块的通信设计-CSDN博客中,我实现了llm、agent、vision、controller模块之间的通信,简单来讲,llm与agent之间由我自己定义的msg进行话题通信,agent与vision之间由我自己定义的msg进行话题通信,agent与controller之间由我自己定义的srv进行服务通信。
在这一节中,我将对代码以及通信架构进行部分调整,具体来说,有以下几点:
1.类标准化,将负责特定功能的模块封装为单独的类,增强复用性
2.去掉agent与controller之间的服务通信,而是加入了planner,agent直接通过话题控制底层关节驱动
3.更改了llm与agent之间的msg设计,加入了更多拓展
1.类标准化
这部分的工作主要在两个包内,arm_vision和arm_application
arm_vision
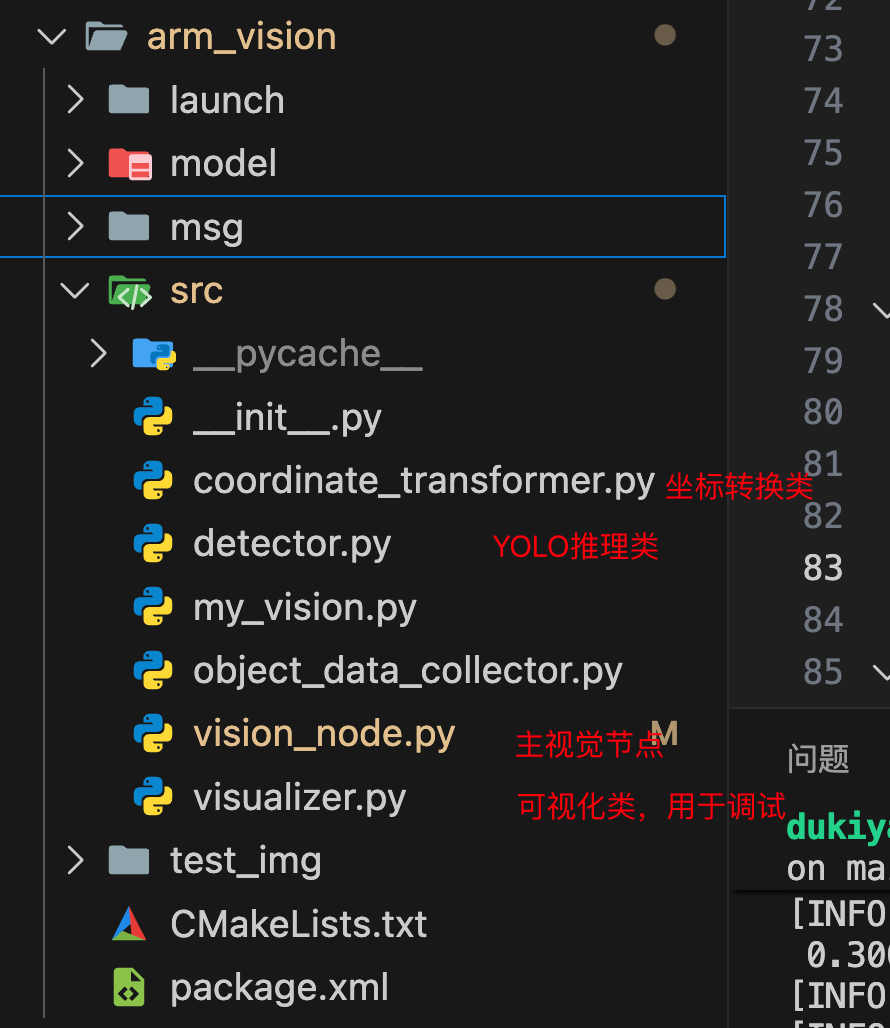
arm_application
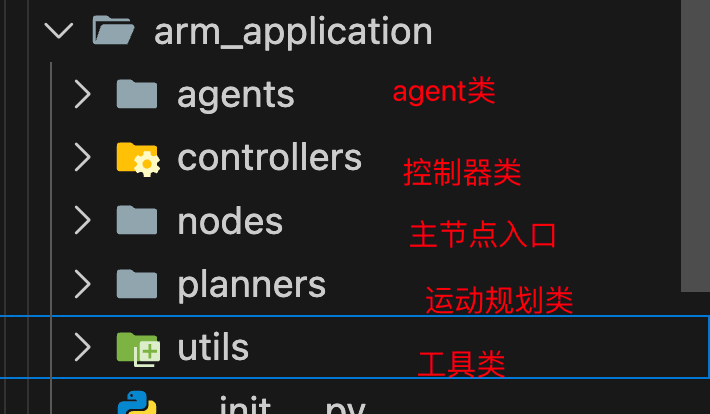
具体的代码内容可前往仓库查阅。
2.加入planner模块
在之前的设计中,llm解析自然语言后通过规定的msg将输出通过话题发布给agent,agent解析后向控制器模块发出服务请求,控制器接收请求后通过自己设计的时序控制底层驱动。
这样做有以下不足:
1.服务通信要求一问一答,在等待回答的过程中系统进入忙等待,效率不高
2.底层驱动的控制agent并不知情,不利于后期反馈机制的加入
因此,我调整了通信架构,加入了planner模块,agent接收llm输出的msg后,调用planner模块生成由原子动作组合而成的动作序列,agent再依次执行动作序列中的原子动作,通过话题发布直接控制底层驱动进行运动。
2.1.planner模块设计
# arm_application/planners/task_planner.py
"""
动作序列生成模块 由agent调用 返回原子序列 agent执行原子动作
"""
from typing import List, Tuple, Any
class TaskPlanner:
def plan(self, task: dict) -> List[Tuple[str, ...]]:
"""
输入: 结构化任务描述(由 Agent 构造)
输出: 动作序列,每个动作是 (方法名, *参数) 的元组
示例输入:
task:{"action": "pick_and_place", "object": (0.3, 0.2, 0.1), "target": (0.5, -0.1, 0.05)}
示例输出:
[
("move_to", 0.3, 0.2, 0.2),
("move_to", 0.3, 0.2, 0.1),
("close_gripper",),
...
]
"""
if task["action"] == "pick_place":
return self._plan_pick_place(task["object"], task["target"])
elif task["action"] == "pick":
return self._plan_pick(task["object"])
elif task["action"] == "place":
return self._plan_place(task["target"])
elif task["action"] == "reset":
return self._plan_reset()
elif task["action"] == "open_gripper":
return self._plan_open_gripper()
elif task["action"] == "close_gripper":
return self._plan_close_gripper()
else:
raise ValueError(f"Unsupported action: {task['action']}")
def _plan_pick_place(self, obj: Tuple[float, float, float], tgt: Tuple[float, float, float]):
return self._plan_pick(obj) + self._plan_place(tgt)
def _plan_pick(self, pose):
"""
抓取动作序列:
1.前往目标上方
2.夹爪对齐
3.降下夹爪
4.闭合夹爪
5.抬起夹爪
"""
SAFE_HEIGHT = 0.5 #夹爪初始高度
DIV = 0.187 # 夹爪合适的下降位置
x, y, z = pose
above = z + DIV
return [
("move_to", x, y, SAFE_HEIGHT),
("align_gripper_roll",),
("move_to", x, y, above),
("close_gripper",),
("move_to", x, y, SAFE_HEIGHT)
]
def _plan_place(self, pose):
"""
放置动作序列:
1.前往目标上方
2.降下夹爪
3.打开夹爪
4.抬起夹爪
"""
SAFE_HEIGHT = 0.5 #夹爪初始高度
DIV = 0.25 # 夹爪合适的下降位置
x, y, z = pose
above = z + DIV
return [
("move_to", x, y, SAFE_HEIGHT),
("move_to", x, y, above),
("open_gripper",),
("move_to", x, y, SAFE_HEIGHT)
]
def _plan_reset(self):
"""
本身属于原子操作
"""
return [
("reset",)
]
def _plan_open_gripper(self):
"""
本身属于原子操作
"""
return [
("open_gripper",)
]
def _plan_close_gripper(self):
"""
本身属于原子操作
"""
return [
("close_gripper",)
]在当前的设计中,我对"pick", "place", "pick_place", "reset", "open_gripper", "close_gripper"这六种动作进行了动作序列设计,其中"reset", "open_gripper", "close_gripper"本身就为原子动作,原子动作的设计在scara_controller.py中:
def move_to(self, x: float, y: float, z: float, duration: float = 3.0) -> bool:
"""
实现原子动作:移动到世界坐标,但目前并未考虑从任意坐标的移动
"""
theta1, theta2, d3, reachable = inverse_kinematics(x, y, z, elbow="down")
rospy.loginfo(f't1 t2 d3:{theta1, theta2, d3}')
if not reachable:
return False
rospy.loginfo(f'move to {x,y,z}')
self._move_joints(theta1, theta2, d3, duration)
return True
def open_gripper(self, duration: float = 1.0) -> None:
rospy.loginfo("open gripper")
self.finger1_pub.publish(Float64(-0.02))
self.finger2_pub.publish(Float64(0.02))
self.finger3_pub.publish(Float64(0.02))
self.finger4_pub.publish(Float64(-0.02))
rospy.sleep(duration)
def close_gripper(self, duration: float = 1.0) -> None:
rospy.loginfo("close gripper")
self.finger1_pub.publish(Float64(0.02))
self.finger2_pub.publish(Float64(-0.02))
self.finger3_pub.publish(Float64(-0.02))
self.finger4_pub.publish(Float64(0.02))
rospy.sleep(duration)
def reset(self, duration: float = 3.0) -> None:
self._move_joints(0.0, 0.0, 0.0, duration)
self.gripper_roll_pub.publish(Float64(0.0))
self.open_gripper()
def align_gripper_roll(self) -> None:
"""
对齐夹爪朝向:获取当前 yaw 角,然后旋转夹爪使其回到初始朝向(相对于世界坐标系为 0)
"""
yaw = self._get_gripper_roll_yaw()
if yaw is not None:
self.gripper_roll_pub.publish(Float64(-yaw))
rospy.loginfo("旋转夹爪以对齐初始朝向")
else:
rospy.loginfo("无法获取 gripper_roll yaw 角")可以看到在底层驱动中共设计了move_to、open_gripper、close_gripper、reset、align_gripper_roll五种原子动作,planner部分的高级动作就由这五种动作构成动作序列而成。
2.2.agent对动作序列的调用
def _llm_callback(self, msg):
rospy.loginfo("收到 LLM 指令: action='%s', class_id=%d" % (msg.action_type, msg.target_class_id))
if msg.action_type == "pick":
if msg.object_x != 0.0 or msg.object_y != 0.0 or msg.object_z != 0.0:
obj_pose = (msg.object_x, msg.object_y, msg.object_z)
rospy.loginfo(f"使用显式抓取坐标: {obj_pose}")
elif msg.object_class_id != -1:
obj_pose = self.object_detector.get_position(msg.object_class_id)
if obj_pose is None:
rospy.logerr(f"视觉未检测到 object_class_id={msg.object_class_id} 的物体!")
return
rospy.loginfo(f"从视觉获取抓取位置: {obj_pose}")
else:
rospy.logerr("pick/pick_place 动作未提供 object_class_id 或 object 坐标!")
return
# 调用 Planner 获取动作序列
task_spec = {
"action": msg.action_type,
"object": obj_pose,
"target": (-1,-1,-1)
}
action_sequence = self.task_planner.plan(task_spec)
rospy.loginfo(f'{action_sequence}')
# 执行动作序列
self._execute_action_sequence(action_sequence)
elif msg.action_type == "place":
# 1. 优先使用显式坐标
if msg.target_x != 0.0 or msg.target_y != 0.0 or msg.target_z != 0.0:
target_pose = (msg.target_x, msg.target_y, msg.target_z)
rospy.loginfo(f"使用显式放置坐标: {target_pose}")
# 2. 否则用 class_id 查询视觉(如“放到蓝色托盘上”)
elif msg.target_class_id != -1:
target_pose = self.object_detector.get_position(msg.target_class_id)
if target_pose is None:
rospy.logerr(f"视觉未检测到 target_class_id={msg.target_class_id} 的放置目标!")
return
rospy.loginfo(f"从视觉获取放置位置: {target_pose}")
else:
rospy.logerr("place/pick_place 动作未提供 target_class_id 或 target 坐标!")
return
# 调用 Planner 获取动作序列
task_spec = {
"action": msg.action_type,
"object": (-1,-1,-1),
"target": target_pose
}
action_sequence = self.task_planner.plan(task_spec)
rospy.loginfo(f'{action_sequence}')
# 执行动作序列
self._execute_action_sequence(action_sequence)
elif msg.action_type == "pick_place":
# 1. 优先使用显式坐标
if msg.object_x != 0.0 or msg.object_y != 0.0 or msg.object_z != 0.0:
obj_pose = (msg.object_x, msg.object_y, msg.object_z)
rospy.loginfo(f"使用显式抓取坐标: {obj_pose}")
# 2. 否则用 class_id 查询视觉(如“抓取红色方块”)
elif msg.object_class_id != -1:
obj_pose = self.object_detector.get_position(msg.object_class_id)
if obj_pose is None:
rospy.logerr(f"视觉未检测到 object_class_id={msg.object_class_id} 的物体!")
return
rospy.loginfo(f"从视觉获取抓取位置: {obj_pose}")
else:
rospy.logerr("pick/pick_place 动作未提供 object_class_id 或 object 坐标!")
return
# 1. 优先使用显式坐标
if msg.target_x != 0.0 or msg.target_y != 0.0 or msg.target_z != 0.0:
target_pose = (msg.target_x, msg.target_y, msg.target_z)
rospy.loginfo(f"使用显式放置坐标: {target_pose}")
# 2. 否则用 class_id 查询视觉(如“放到蓝色托盘上”)
elif msg.target_class_id != -1:
target_pose = self.object_detector.get_position(msg.target_class_id)
if target_pose is None:
rospy.logerr(f"视觉未检测到 target_class_id={msg.target_class_id} 的放置目标!")
return
rospy.loginfo(f"从视觉获取放置位置: {target_pose}")
else:
rospy.logerr("place/pick_place 动作未提供 target_class_id 或 target 坐标!")
return
# 调用 Planner 获取动作序列
task_spec = {
"action": msg.action_type,
"object": obj_pose,
"target": target_pose
}
action_sequence = self.task_planner.plan(task_spec)
rospy.loginfo(f'{action_sequence}')
# 执行动作序列
self._execute_action_sequence(action_sequence)
elif msg.action_type == "reset" or msg.action_type == "open_gripper" or msg.action_type == "close_gripper":
# 调用 Planner 获取动作序列
task_spec = {
"action": msg.action_type,
"object": (-1,-1,-1),
"target": (-1,-1,-1)
}
action_sequence = self.task_planner.plan(task_spec)
rospy.loginfo(f'{action_sequence}')
# 执行动作序列
self._execute_action_sequence(action_sequence)
def _execute_action_sequence(self, seq: List[Tuple[str, ...]]):
for action in seq:
method_name = action[0]
args = action[1:]
rospy.loginfo(f'method_name:{method_name} args:{args}')
if method_name == "move_to":
self.controller.move_to(*args)
elif method_name == "open_gripper":
self.controller.open_gripper()
elif method_name == "close_gripper":
self.controller.close_gripper()
elif method_name == "reset":
self.controller.reset()
elif method_name == "align_gripper_roll":
self.controller.align_gripper_roll()
else:
rospy.logwarn(f"Unknown action: {method_name}")在agent中,接收到llm发出的msg后进入回调函数,回调函数中对msg内容进行字符匹配,根据msg的内容来决定是否调用视觉模块获取坐标信息,之后交给planner设计动作序列,最后再按照动作序列依次调用原子动作实现控制。
3.LLM与Agent之间通信msg的更改
在之前的LLMCommands.msg中,内容较为粗略,我对这个msg进行了新的拓展,目前其结构如下:
# arm_application/msg/LLMCommands.msg
# 支持的动作类型
string action_type # "pick", "place", "pick_place", "reset", "open_gripper", "close_gripper"
# === 抓取目标 ===
int32 object_class_id # 物体类别 ID,-1 表示无(如 reset)
string object_name # 语义名称,仅用于日志/调试(如 "red_block")
float32 object_x # 显式抓取坐标(若提供)
float32 object_y
float32 object_z
# === 放置目标 ===
int32 target_class_id # 放置目标类别 ID,-1 表示无
string target_name # 语义名称,仅用于日志/调试(如 "blue_tray")
float32 target_x # 显式放置坐标(若提供)
float32 target_y
float32 target_z
# === 使用规则 ===
# - "pick": 使用 object_class_id 或 (object_x, object_y, object_z)
# - "place": 使用 target_class_id 或 (target_x, target_y, target_z)
# - "pick_place": 两者都需
# - 其他动作: 忽略所有目标字段主要有以下几点调整:
1.对于要抓取的物体(object),支持指定坐标,这样可以为“把(x,y,z)处的蓝色方块抓起来”这样的命令服务;也可以不指定坐标,那么agent会调用视觉模块进行坐标确认。
2.对于要放置的地点(target),支持指定坐标,这样可以为“把蓝色方块放到(x,y,z)”这样的命令服务;也可以不指定坐标,而是指定target_class_id,这样可以为“把蓝色方块放到绿色圆柱上”这样的命令服务。
4.下一步的优化
对于目前的系统,已经可以大体实现“把蓝色方块放到绿色圆柱上”,但是目前抓取和放置的高度逻辑,都是基于定值的,简单来说,目前的抓取和放置操作,最后都是要求夹爪下降到一个固定的高度,然后闭合/打开夹爪,对于物体高度不一致、叠放这样的操作时,显然会出现问题。因此,我计划在后续的系统中加入深度图信息的利用,尝试判断出物体的高度,将此高度信息加入到抓取放置的高度判断逻辑中,使系统更健壮。
---
1.29更新:
我尝试了加入深度相机,首先配置:
camera_d435i.urdf.xacro
<gazebo reference="camera_link">
<sensor name="depth_camera" type="depth">
<camera>
<horizontal_fov>1.518</horizontal_fov> <!-- ~87 度,D435i 深度 FOV -->
<image>
<width>848</width>
<height>480</height>
</image>
<clip>
<near>0.1</near>
<far>6.0</far>
</clip>
</camera>
<always_on>true</always_on>
<update_rate>30</update_rate>
<visualize>false</visualize>
<plugin name="depth_camera_controller" filename="libgazebo_ros_openni_kinect.so">
<alwaysOn>true</alwaysOn>
<updateRate>30.0</updateRate>
<cameraName>camera/depth</cameraName>
<depthImageTopicName>image_rect_raw</depthImageTopicName>
<cameraInfoTopicName>camera_info</cameraInfoTopicName>
<pointCloudTopicName>points</pointCloudTopicName>
<pointCloudCutoff>0.05</pointCloudCutoff>
<pointCloudCutoffMax>8.0</pointCloudCutoffMax>
<frameName>camera_depth_optical_frame</frameName>
</plugin>
</sensor>
</gazebo>深度图发布的话题为camera/depth/image_rect_raw,格式为32FC1,格式上是符合预期的。
然而,当我将彩色图与深度图同时显示时,发现:
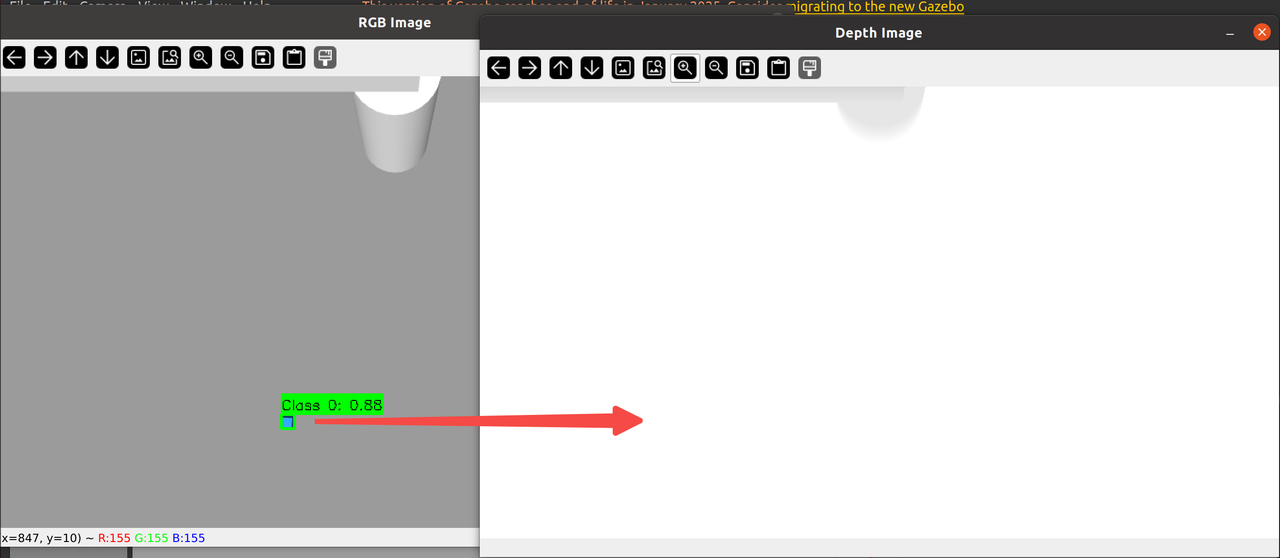
对于目前的情况(相机位于世界上方1.3m),方块在深度图中几乎完全不可见,因此其最终测算出来的z坐标基本为0,我尝试提升方块的位置,在高度为0.4时可以初步在深度图中显示,但最终测算出来的坐标误差约等于方块本身的边长,所以通过深度图算出来的z坐标基本没有参考性。
因此,对于该问题,我目前打算先跳过,仍旧采用固定高度。之后要解决该问题,我将考虑以下两个方案:
1.把深度相机迁移到夹爪下方,这样在较低高度下拍摄出的深度图会更有参考度
2.不使用深度相机,而是采用力传感器来判定夹爪有没有与物体接触到
总结
完成了项目代码结构的调整以及修改了llm、agent、controller之间的通信方式和msg设计。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)