Spring AI 进阶:Embedding 技术原理、相似度算法与实操
Spring AI 进阶:Embedding 技术原理、相似度算法与实操
在上一篇文章中Spring AI :Java 生态原生 AI 框架入门指南,我们初步认识了 Spring AI 的核心概念与快速上手方法,体验了与 Deepseek 模型的对话交互。而在 AI 的高级场景中,如语义搜索、聚类分析、检索增强生成(RAG),Embedding 技术是不可或缺的基础。本文将深入拆解 Embedding 的核心原理与应用场景,以智普 AI 为例,带大家实操文本向量化、相似文本查找,并铺垫 RAG 技术的核心逻辑,帮助大家掌握 Spring AI 中 Embedding 模块的使用精髓。
一、什么是 Embedding?核心原理与价值
(一)Embedding 定义
Embedding 直译是 “嵌入”,在 AI 领域特指将非结构化数据(如文本、图像、视频)转换为低维稠密数字向量的技术。这些向量并非随机生成,而是通过模型学习数据的语义信息,最终在向量空间中形成有意义的分布 ——向量之间的距离越近,代表原始数据的语义相似度越高。
例如,“咖啡” 和 “美式咖啡” 的向量距离会非常近,而 “咖啡” 和 “登山鞋” 的向量距离则会很远。这种特性让计算机能够 “理解” 文本的语义,而非仅仅识别字符本身,为后续的语义相关操作提供了可能。
(二)Spring AI 中的 Embedding 优势
Spring AI 通过 EmbeddingModel 接口对 Embedding 技术进行了统一封装,带来两大核心优势:
多模型兼容:支持 OpenAI、Titan、Azure、Ollama、智普 AI 等主流 Embedding 模型,切换模型仅需修改配置,无需改动业务代码。
调用简单:开发者无需关注模型底层实现,通过简洁的 API 即可完成文本向量化操作,同时支持单文本、多文本批量向量化。
(三)Embedding 核心应用场景
Embedding 的应用场景覆盖了 AI 开发的多个核心领域,具体包括:
相似度计算 / 语义搜索:将查询文本与文档库都转换为向量,通过向量检索快速找到语义相似的文档。
聚类与分类:将文本向量输入传统机器学习算法(如 K-Means),实现文本自动分组或分类。
检索增强生成(RAG):向量化私有知识库,让大模型结合外部知识生成更准确的回答(后续重点讲解)。
推荐系统:基于用户兴趣文本的向量,推荐语义相似的内容、商品或问答。
异常检测:识别语义偏离正常范围的异常内容(如垃圾评论、违规文本)。
二、基于 Embedding 向量的文本相似度核心算法
实现相似文本检索的核心是通过算法计算两个 Embedding 向量的相似度。Embedding 向量的核心价值,正是依托相似度计算得以落地;常见的文本相似度算法有:余弦相似度、欧氏距离、曼哈顿距离 等算法方案,这些算法适配不同业务场景,下文将对各类主流算法展开详细解析:
1. 余弦相似度(Cosine Similarity)
核心逻辑:衡量两个向量在空间中的夹角余弦值,取值范围 [-1, 1],越接近 1 表示语义相似度越高。
公式:
核心优势:仅关注向量 “方向”(语义核心),忽略 “长度” 差异,适配 Embedding 向量的语义特性。
适用场景:绝大多数通用场景(语义搜索、RAG 检索、短 / 长文本匹配),是主流 Embedding 模型的默认算法。
2. 欧氏距离(Euclidean Distance)
核心逻辑:计算两个向量在空间中的直线距离,距离越小,语义相似度越高,通常归一化到 [0,1] 区间使用。
公式: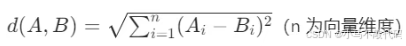
核心优势:计算逻辑直观,能反映向量空间中的绝对距离关系。
适用场景:向量维度较低(<100 维)、数据分布均匀的场景,如简单文本聚类、短文本快速筛选。
3. 曼哈顿距离(Manhattan Distance)
核心逻辑:又称 “城市街区距离”,计算向量各维度差值的绝对值之和,值越小相似度越高,归一化后适配比较场景。
公式: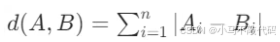
核心优势:对异常值不敏感,计算速度快,适合海量数据快速匹配。
适用场景:含噪声的文本数据(如口语化查询、不规范输入)、批量文本初步筛选。
主流 Embedding 大模型的算法选择
当前 OpenAI text-embedding-3、智普 embedding-2、通义千问 Embedding 等主流模型,默认均以余弦相似度作为核心匹配算法,部分会做工程优化:
选型建议:实际开发中优先使用余弦相似度,仅在特殊场景(如含噪声、高维稀疏数据)切换其他算法。
二、实操准备:智普 AI 环境配置
在 Spring AI 中使用 Embedding,需要选择支持该功能的 AI 模型(Deepseek 目前暂不提供 Embedding 模型)。本文选择智普 AI 的 embedding-2 模型进行演示,需先完成以下准备工作:
1. 智普 AI 账号准备
官网地址:https://open.bigmodel.cn/
API Key 获取:登录后进入「用户中心 → 项目管理 → API Keys」创建密钥。
官方文档:https://open.bigmodel.cn/dev/howuse/introduction(了解更多模型参数细节)。
2. 创建 Spring Boot 项目
项目名称:Weiz-SpringAI-Embedding
核心配置:JDK 17、Spring Boot 3.5.0、Maven
依赖选择:Spring Web(后续通过 pom.xml 补充 Embedding 相关依赖)
项目结构如下:
Weiz-SpringAI-Embedding/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── example/
│ │ │ └── weizspringai/
│ │ │ ├── WeizSpringAiEmbeddingApplication.java
│ │ │ ├── controller/
│ │ │ └── service/
│ │ └── resources/
│ │ ├── application.properties
│ └── test/
└── pom.xml
3. 配置 pom.xml 依赖
导入 Spring AI BOM 与智普 AI 相关依赖,同时引入文档处理工具包:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.example</groupId>
<artifactId>Weiz-SpringAI</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>Weiz-SpringAI-Embedding</artifactId>
<name>Weiz-SpringAI-Embedding</name>
<description>Weiz-SpringAI-Embedding</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<!-- spring-ai-client-chat 中包括 TokenTextSplitter、TextReader、Document 等工具 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>${spring-ai.version}</version>
</dependency>
</dependencies>
</project>
4. 配置 application.properties
在 src/main/resources/application.properties 中配置智普 AI 密钥、模型信息:
# 应用名称
sspring.application.name=WeizSpringAIEmbedding
server.port=8080
# 智谱 AI 地址
spring.ai.zhipuai.api-key=你的智普 AI API Key
spring.ai.zhipuai.base-url=https://open.bigmodel.cn/api/paas
spring.ai.zhipuai.embedding.options.model=embedding-2
spring.ai.zhipuai.chat.options.model=GLM-4-Flash
注意,需要替换 你的智普 AI API Key 为实际获取的密钥,配置完成后即可开始 Embedding 相关开发。
三、实操案例 1:文本向量化基础实现
1. 核心思路
通过 Spring AI 提供的 EmbeddingModel 接口,调用智普 AI 的 embedding-2 模型,将用户输入的文本转换为 1024 维的向量(embedding-2 模型默认输出维度),并返回给前端。
2. 编写 EmbeddingController
创建 com.example.weizspringai.controller.EmbeddingController 类,注入 EmbeddingModel 并提供接口:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
@RequestMapping("/ai")
public class EmbeddingController {
// 自动注入 EmbeddingModel(智普 AI 实现)
@Autowired
private EmbeddingModel embeddingModel;
/**
* 文本向量化接口
* @param message 待向量化的文本(默认值:推荐一款入门级露营装备)
* @return 包含原始文本与向量的响应
*/
@GetMapping("/embedding")
public Map<String, Object> embedding(
@RequestParam(value = "message", defaultValue = "推荐一款入门级露营装备") String message) {
// 调用 embed 方法完成文本向量化(默认返回 1024 维向量)
float[] vector = embeddingModel.embed(message);
// 返回结果(原始文本 + 向量)
return Map.of(
"message", message,
"vectorDimension", vector.length, // 向量维度
"vector", vector
);
}
}
3. 测试文本向量化接口
启动 SpringAIEmbedding 项目。
浏览器访问:http://localhost:8080/ai/embedding?message=城市周边短途游攻略。
响应结果如下(向量仅展示部分):
{
"message": "城市周边短途游攻略",
"vectorDimension": 1024,
"vector": [
0.06892345,
-0.01234567,
0.04567891,
-0.02890123,
// 省略后续 1020 个维度...
]
}
可以看到,文本 “城市周边短途游攻略” 被成功转换为 1024 维的向量。如果需要对多条文本批量向量化,可使用 embeddingModel.embed(List) 方法,例如:
List<String> texts = List.of("北京周边短途游攻略", "欧洲七天游攻略", "赛里木湖攻略");
List<float[]> vectors = embeddingModel.embed(texts);
四、实操案例 2:相似文本查找(多相似度算法)
1. 案例实现思路
准备本地知识库文本(3 条示例文本)。
项目启动时,将知识库文本批量向量化并缓存。
接收用户查询文本,将其向量化。
计算查询向量与知识库向量的余弦相似度,返回最相似的文本。
2. 编写核心工具类:相似度算法统一实现
创建 com.example.weizspringai.service.SimilarityCalculator 类,封装相似文本查找逻辑:
import java.util.HashSet;
import java.util.Set;
/**
* 基于 Embedding 向量的文本相似度计算工具类
* 整合多种核心相似度算法
*/
public class SimilarityCalculator {
// ====================== 1. 余弦相似度(默认推荐) ======================
public static double cosineSimilarity(float[] a, float[] b) {
checkVectorLength(a, b);
double dotProduct = 0.0;
double normA = 0.0;
double normB = 0.0;
for (int i = 0; i < a.length; i++) {
dotProduct += a[i] * b[i];
normA += Math.pow(a[i], 2);
normB += Math.pow(b[i], 2);
}
if (normA == 0 || normB == 0) {
return 0.0;
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}
// ====================== 2. 欧氏距离(归一化后) ======================
public static double euclideanSimilarity(float[] a, float[] b) {
checkVectorLength(a, b);
double sum = 0.0;
for (int i = 0; i < a.length; i++) {
sum += Math.pow(a[i] - b[i], 2);
}
double distance = Math.sqrt(sum);
// 归一化:1/(1+距离),将距离转换为相似度(值越大相似度越高)
return 1.0 / (1.0 + distance);
}
// ====================== 3. 曼哈顿距离(归一化后) ======================
public static double manhattanSimilarity(float[] a, float[] b) {
checkVectorLength(a, b);
double sum = 0.0;
for (int i = 0; i < a.length; i++) {
sum += Math.abs(a[i] - b[i]);
}
// 归一化:1/(1+距离)
return 1.0 / (1.0 + sum);
}
// ====================== 辅助方法 ======================
/** 校验两个向量长度一致 */
private static void checkVectorLength(float[] a, float[] b) {
if (a == null || b == null || a.length != b.length) {
throw new IllegalArgumentException("向量长度不一致,无法计算相似度");
}
}
/** 计算向量均值 */
private static double getVectorMean(float[] vector) {
double sum = 0.0;
for (float v : vector) {
sum += v;
}
return sum / vector.length;
}
/** 简化:假设协方差矩阵为单位矩阵,返回单位矩阵(实际场景需用矩阵工具计算逆矩阵) */
private static double[][] invertMatrix(double[][] matrix) {
int n = matrix.length;
double[][] inv = new double[n][n];
for (int i = 0; i < n; i++) {
inv[i][i] = 1.0;
}
return inv;
}
}
3. 编写 EmbeddingService:支持算法切换
创建com.example.weizspringai.service.EmbeddingService类,集成相似度工具类,支持灵活选择算法:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class EmbeddingService {
private final EmbeddingModel embeddingModel;
// 本地知识库文本(旅行相关场景)
private final List<String> docs = List.of(
"海边露营需准备防水帐篷、防潮垫、速干衣和便携炊具。",
"山地徒步要携带登山杖、防滑鞋、双肩包和应急医疗包。",
"城市漫游推荐骑行共享单车,打卡老街区和小众咖啡馆。"
);
// 知识库文本对应的向量(项目启动时初始化)
private final List<float[]> docVectors;
// 算法类型枚举(方便调用)
public enum SimilarityAlgorithm {
COSINE, // 余弦相似度(默认)
EUCLIDEAN, // 欧氏距离
MANHATTAN // 曼哈顿距离
}
// 构造方法注入 EmbeddingModel,初始化知识库向量
public EmbeddingService(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
this.docVectors = this.embeddingModel.embed(docs);
}
/**
* 查找与查询文本最相似的知识库文本(指定算法)
* @param query 用户查询文本
* @param algorithm 相似度算法
* @return 最相似的文本
*/
public String queryBestMatch(String query, SimilarityAlgorithm algorithm) {
float[] queryVec = embeddingModel.embed(query);
int bestIdx = -1;
double bestSim = -1;
for (int i = 0; i < docVectors.size(); i++) {
double sim = calculateSimilarity(queryVec, docVectors.get(i), algorithm);
if (sim > bestSim) {
bestSim = sim;
bestIdx = i;
}
}
return docs.get(bestIdx);
}
/**
* 重载:默认使用余弦相似度
*/
public String queryBestMatch(String query) {
return queryBestMatch(query, SimilarityAlgorithm.COSINE);
}
/**
* 统一相似度计算入口
*/
private double calculateSimilarity(float[] a, float[] b, SimilarityAlgorithm algorithm) {
return switch (algorithm) {
case COSINE -> SimilarityCalculator.cosineSimilarity(a, b);
case EUCLIDEAN -> SimilarityCalculator.euclideanSimilarity(a, b);
case MANHATTAN -> SimilarityCalculator.manhattanSimilarity(a, b);
case MAHALANOBIS -> {
// 简化示例:使用单位矩阵作为协方差矩阵(实际需根据数据计算)
double[][] covMatrix = new double[a.length][a.length];
for (int i = 0; i < a.length; i++) {
covMatrix[i][i] = 1.0;
}
yield SimilarityCalculator.mahalanobisSimilarity(a, b, covMatrix);
}
};
}
}
4. 扩展 EmbeddingController
在 EmbeddingController 增加算法参数,支持前端灵活选择相似度算法,同时,注入 EmbeddingService,添加相似文本查找接口:
import com.example.springaiembedding.service.EmbeddingService;
import com.example.springaiembedding.service.EmbeddingService.SimilarityAlgorithm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.ai.embedding.EmbeddingModel;
import java.util.Map;
@RestController
@RequestMapping("/ai")
public class EmbeddingController {
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingService embeddingService;
// 文本向量化接口(保持不变)
@GetMapping("/embedding")
public Map<String, Object> embedding(
@RequestParam(value = "message", defaultValue = "推荐一款入门级露营装备") String message) {
float[] vector = embeddingModel.embed(message);
return Map.of(
"message", message,
"vectorDimension", vector.length,
"vector", vector
);
}
/**
* 相似文本查找接口(支持指定算法)
* @param query 查询文本
* @param algorithm 相似度算法(默认 COSINE)
*/
@GetMapping("/similarity")
public Map<String, Object> findSimilarText(
@RequestParam("query") String query,
@RequestParam(value = "algorithm", defaultValue = "COSINE") String algorithm) {
// 校验算法参数合法性
SimilarityAlgorithm simAlgo;
try {
simAlgo = SimilarityAlgorithm.valueOf(algorithm.toUpperCase());
} catch (IllegalArgumentException e) {
return Map.of(
"error", "算法参数无效,支持的算法:COSINE/EUCLIDEAN/MANHATTAN/PEARSON/JACCARD/ADJUSTED_COSINE/MAHALANOBIS",
"code", 400
);
}
// 执行相似文本查找
String similarText = embeddingService.queryBestMatch(query, simAlgo);
return Map.of(
"query", query,
"algorithm", simAlgo.name(),
"answer", similarText
);
}
}
5. 测试相似文本查找
启动项目后,可通过以下 URL 测试不同算法的效果:
测试1:在浏览器中访问 http://localhost:8080/ai/similarity?query=露营准备&algorithm=COSINE,响应:
{
"query":"露营准备",
"algorithm":"COSINE",
"answer":"海边露营需准备防水帐篷、防潮垫、速干衣和便携炊具。"
}
测试2:访问 http://localhost:8080/ai/similarity?query=徒步装备&algorithm=EUCLIDEAN,响应:
{
"query":"徒步装备",
"algorithm":"MAHALANOBIS",
"answer":"山地徒步要携带登山杖、防滑鞋、双肩包和应急医疗包。"
}
测试结果分析:不同算法均能准确匹配语义相似的文本,其中余弦相似度在通用性、计算效率上表现最优,适合大多数场景;其他算法可根据数据特性(如含噪声、高维稀疏)灵活切换。
总结
本文聚焦 Embedding 技术的核心原理与实操落地,详细解析了 3 种主流文本相似度算法的逻辑、优势与适用场景,并通过智普 AI 完成了文本向量化与多算法适配的相似文本查找案例。Embedding 作为语义理解的核心技术,为 AI 高级场景提供了 “可计算的语义向量”,而 Spring AI 的统一接口封装让开发者无需关注底层细节,即可快速集成多模型、多算法的 Embedding 能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)