近半年,无人机 + 大模型的 8 大 “出圈” 硬核研究
在野外让无人机做 3D 扫描,真正难的不是“飞起来”,而是“飞得像个懂事的人”。作者认为未来的人机交互会从工程师预设的固定流程,走向用户驱动的个性化任务设计,但现实卡点也很直白:用户说的是自然语言,无人机懂的是动作与约束,两者缺一套“共同语言”,所以复杂任务经常落到“要么说不清,要么执行跑偏”。:这篇工作提出 VLA-AN,把“视觉-语言-动作(VLA)”这套大模型能力,真正塞进一台资源紧张的无人

「近半年最热的方向...」
目录
Chat with UAV – Human-UAV Interaction Based on Large Language Models
AdaptFly: Prompt-Guided Adaptation of Foundation Models for Low-Altitude UAV Networks
最近刷无人机相关论文,会有个很明显的变化:越来越多工作开始把“大模型”当成标配往系统里塞。
以前大家更习惯卷感知、卷规划、卷控制,现在则多了一条新主线:
让无人机听得懂人话、看得懂开放世界、还能在复杂场景里做更聪明的决策。
于是“大模型 + 无人机”这条线一下子热起来,paper 也肉眼可见地密集。
所以这期我们干脆做一个大模型无人机盘点,把近期有代表性的研究集中列出来,给大家一张“现在到底在做什么”的地图,方便各位读者按方向继续深挖。
这次盘点里选到的几篇论文,主要是为了把“大模型怎么和无人机结合”这件事讲清楚,所以我们更关注它们展示的思路和系统做法,而不是追求把所有相关工作一网打尽。受限于篇幅和检索范围,这份清单难免有遗漏,也不代表我们认为“没被选到的就不重要”,更不等同于任何形式的排名或好坏评价。如果你觉得某些工作同样值得放进来,欢迎在评论区补充,我们也会把高质量补充整理成后续更新版本。
VLA-AN: An Efficient and Onboard Vision Language-ActionFramework for AerialNavigation in Complex Environments
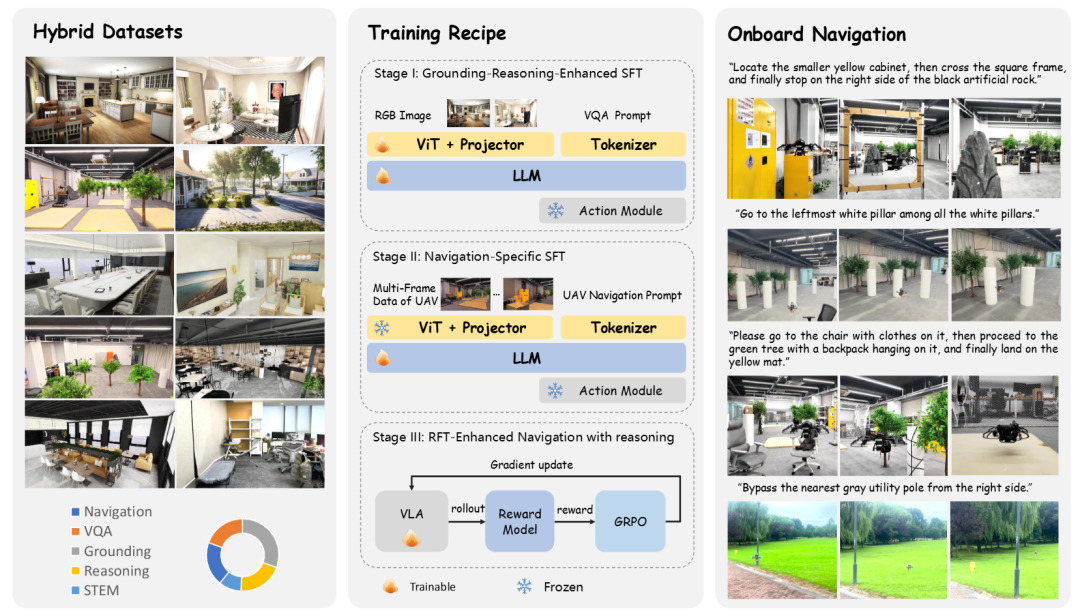
机构:浙江大学,微分智飞
主要内容:这篇工作提出 VLA-AN,把“视觉-语言-动作(VLA)”这套大模型能力,真正塞进一台资源紧张的无人机里,让它在复杂环境里闭环自主导航,而不是停留在“能看懂、能说对,但飞不稳/跑不动”的阶段。
它的核心思路是:大模型负责理解与推理(看场景、对齐语言、做长期决策),但动作输出不完全交给生成式策略,而是加了一套轻量实时的动作模块,并用几何层面的安全校正把“可能很聪明但偶尔乱来”的生成动作拉回可执行、可避障的范围。
为了让大模型不被真实飞行数据稀缺卡死,他们还用 3D Gaussian Splatting(3D-GS)构建高保真数据来补齐“仿真/数据域差”,再用一个三阶段渐进训练,从“看懂场景”到“掌握飞行基础技能”再到“长时序复杂导航”,一步步把能力堆上去。最终在机载算力受限条件下,仍能做到 2–3 Hz 的实时推理,把 VLA 做成可落地的航行系统。
链接:https://arxiv.org/pdf/2512.15258
拓展阅读:成功率98.1%!浙大高飞团队最新:VLA-AN构建“数据+安全+算力”闭环,实现真·实时导航
AirHunt: Bridging VLM Semantics and Continuous Planning for Efficient Aerial Object Navigation
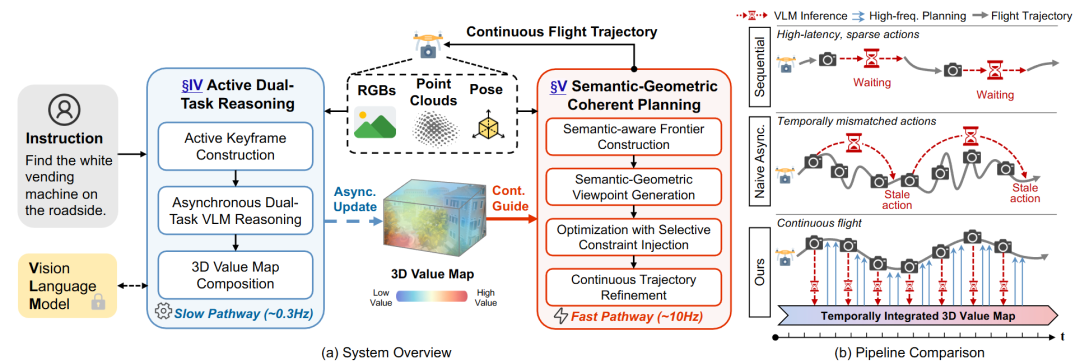
机构:南方科技大学(周博宇团队)
主要内容:这篇 AirHunt 解决的是“大模型无人机落地”里最典型、也最致命的矛盾:VLM 很慢,飞行规划很快。AirHunt 的核心突破是把 VLM 的角色重新定位为高层语义生成器,而不是实时控制器,并用一个能持续读写的 3D 语义-几何记忆(3D value map)把“慢推理”变成“可持续利用的语义势场”。具体做法是一个双通路异步架构:
-
推理通路(低频):VLM 根据语言指令提取语义先验,异步写入并更新 3D value map;
-
规划通路(高频):路径规划器以高频持续运行,实时从这个 value map “取语义”,生成连续轨迹。
这样两边都能按各自的天然频率工作,不会互相卡住,还能做到“飞行不中断、语义引导会随运动逐步演化”。为了进一步省掉不必要的 VLM 调用,AirHunt 还做了一个主动双任务推理模块,利用几何与语义的冗余关系进行选择性查询;同时在规划层引入语义-几何一致的统一优化,在不同环境异质性下动态平衡“语义优先级”和“运动效率”。
链接:https://arxiv.org/pdf/2601.12742
拓展阅读:南科大周博宇团队新突破:AirHunt 实现无人机连续语义导航,飞行效率提升59%!
FlyCo: Foundation Model-Empowered Drones for Autonomous 3D Structure Scanning in Open-World Environments
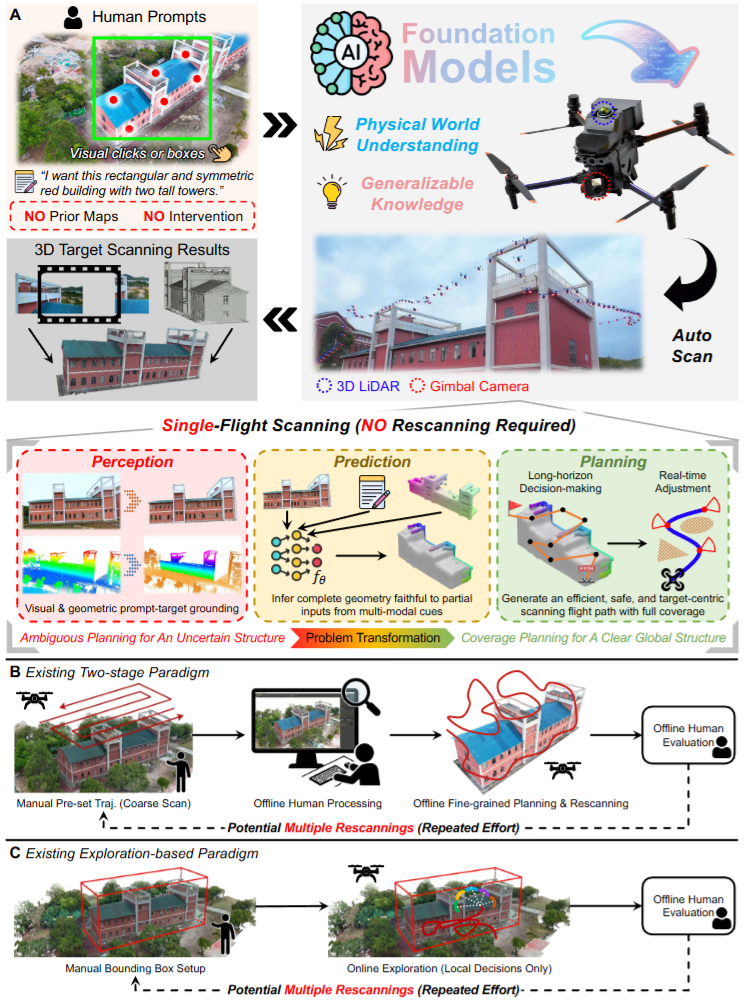
机构:香港科技大学,南方科技大学
主要内容:
在野外让无人机做 3D 扫描,真正难的不是“飞起来”,而是“飞得像个懂事的人”。你说一句“扫那座山谷里的城堡”,人类飞手会立刻找对目标、脑子里补出它没被看到的背面轮廓,然后边飞边绕开树和障碍,把该扫的地方一遍到位。现有系统往往做不到这么省心:要么依赖很重的人工先验(例如框 3D 范围、手工分割、预设飞行样式),要么在复杂几何和遮挡面前效率和完整性一起掉线。
香港科技大学沈劭劼团队、南方科技大学周博宇团队、中山大学等机构联合发布FlyCo:把基础模型(Foundation Models)的“常识”和“语义理解”真正接进无人机系统里,形成一个感知-预测-规划的闭环,让无人机从“按模板飞”变成“边理解边推演边规划”,实现仅靠文本 + 少量 2D 标注就能在未知开放环境里完成目标结构的自动三维扫描。
链接:https://arxiv.org/pdf/2601.07558
拓展阅读:沈劭劼&周博宇等团队|仅需文本+少量2D标注!实现未知开放环境下的自动三维扫描
MM-UAVBENCH: How Well Do Multimodal Large Language Models See, Think, and Plan in Low-Altitude UAV Scenarios?

机构:清华大学,南开大学
主要内容:这篇 MM-UAVBENCH 也是“基准/评测”路线,但它盯得更准:不是泛泛测大模型会不会答题,而是专门针对低空无人机视角的那堆麻烦事,系统性评估多模态大模型(MLLM)的“通用智能”到底够不够用。
现有 MLLM benchmark 很少覆盖低空场景的独特视觉挑战(俯视、小目标、视角变化、遮挡密集、尺度极不稳定),而 UAV 相关评测又常常只测某个单点任务(定位/导航),缺少一个能同时覆盖“看懂 + 想明白 + 做决策”的统一框架。于是他们做了一个三维度评测体系,把 MLLM 在低空 UAV 场景里的能力拆成 感知(Perception)- 认知(Cognition)- 规划(Planning) 三大块,并设计了 19 个子任务、5700+ 人工标注问题,全部来自真实无人机数据(公开数据集)。
这里的大模型不是直接开飞控,而是作为空中视角的通用理解与决策引擎,需要从真实航拍图中完成理解、推理、到任务规划的链路。评测结果显示:当前 16 个开源/闭源 MLLM 在低空复杂视觉与认知需求上依然吃力,作者还点名了两类关键瓶颈:空间偏置(spatial bias)和多视角/多视图理解能力不足,这两点会直接卡住 MLLM 在真实 UAV 场景里的可用性。
链接:https://arxiv.org/pdf/2512.23219v1
UAVBench: An Open Benchmark Dataset for Autonomous and Agentic AI UAV Systems via LLM-Generated Flight Scenarios
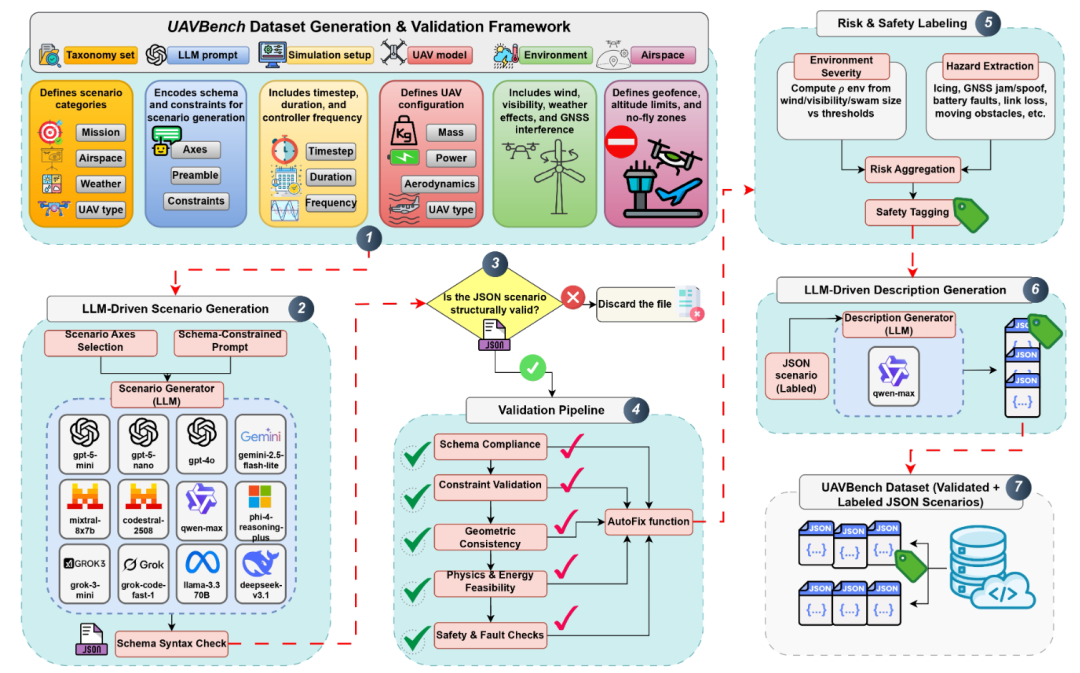
机构:哈利法科学技术大学
主要内容:这篇 UAVBench 走的不是“再提一个更强的飞行策略”,而是先给“大模型无人机”补上一把统一的标尺。现在越来越多无人机系统开始把 LLM 用在任务规划、感知解释和决策上,但大家评测各用各的场景、各写各的任务描述,缺少“物理上站得住”的标准化基准,导致很难系统比较模型到底会不会“懂飞行”。
于是他们做了两件事:一是用taxonomy 引导的提示词让 LLM 批量生成 5 万条可验证的飞行场景,并通过多阶段安全校验把不合理、不安全、不物理的场景筛掉;二是把每个场景都编码成统一的 JSON 结构,里面包含任务目标、机型配置、环境条件,以及量化的风险标签。基于这套场景库,作者又扩展了 UAVBench_MCQ,把场景变成 5 万道多选题,覆盖从空气动力学、导航到多机协同、混合推理,甚至伦理相关的推理风格,用“可解释、可机检”的方式去测 LLM 的 UAV 专用推理能力。最后他们对 32 个主流大模型做了评测,整体结论是:在感知与策略推理上表现不错,但在伦理约束和资源受限条件下的取舍决策上仍然容易翻车。
链接:https://arxiv.org/pdf/2511.11252
Chat with UAV – Human-UAV Interaction Based on Large Language Models
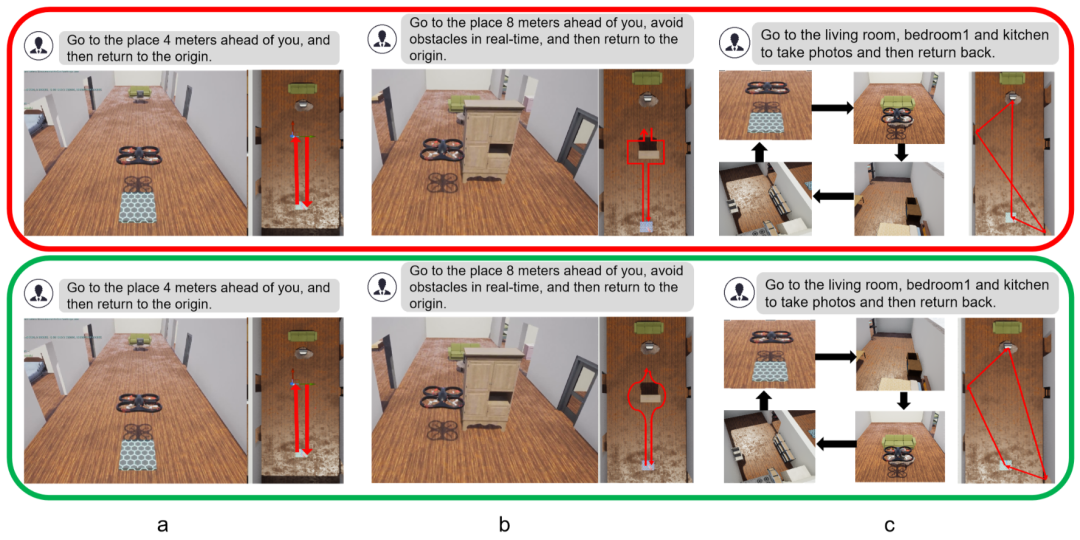
机构:浙江工商大学,英国萨塞克斯大学工程与信息学院
主要内容:这篇工作瞄准的是“让普通用户用自然语言就能指挥无人机”这件事。作者认为未来的人机交互会从工程师预设的固定流程,走向用户驱动的个性化任务设计,但现实卡点也很直白:用户说的是自然语言,无人机懂的是动作与约束,两者缺一套“共同语言”,所以复杂任务经常落到“要么说不清,要么执行跑偏”。
他们的解法是把大模型“拆开用”,提出一个双智能体(dual-agent)HUI 框架:
-
一个任务规划智能体 专门负责“理解用户意图 + 生成可执行的任务步骤/子任务顺序”;
-
一个执行智能体 专门负责“把步骤落到飞行行为上”,在执行过程中结合状态反馈去处理混合任务(比如既要巡航拍照又要避障、再返航)。
关键点不在“换个更大模型”,而在用不同的 Prompt Engineering 把理解/规划/执行分工隔离,避免一个 LLM 又要想全局又要管细节,结果在复杂场景里容易卡在“混合任务规划与执行”上。为了验证效果,作者还搭了一个覆盖四类典型无人机应用的任务库,用三项指标量化表现,并对不同 LLM 作为控制核心的表现做了对比;用户研究显示这种分工能让交互更顺、执行更灵活,更贴近“用户想要的那种无人机”。
链接:https://arxiv.org/pdf/2512.08145
AdaptFly: Prompt-Guided Adaptation of Foundation Models for Low-Altitude UAV Networks
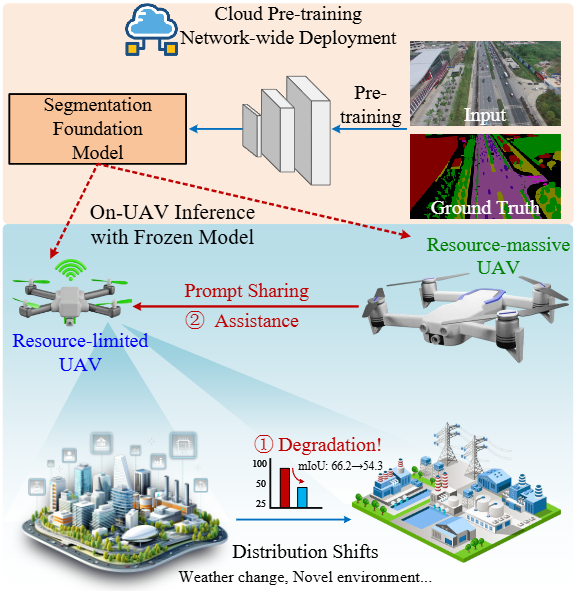
机构:华南理工大学,桂林电子科技大学
主要内容:这篇 AdaptFly 走的是“低空无人机网络”的务实路线:不是让无人机更会聊天、更会规划,而是先把一个更底层的能力做稳,语义分割。它把“自适应”从“改权重”改成“改提示(prompt)”,提出一个无权重更新(weight-free)、由 prompt 驱动的 TTA 框架。也就是:分割模型本体不动,靠提示去把模型在当前环境里“拨回正轨”。并且它专门考虑网络里异构无人机的现实,设计了两种互补模式:
-
资源受限 UAV:不做优化,只做轻量 token prompt 检索,从一个共享的全局记忆里取回“在类似天气/光照/视角下有效的提示”;
-
资源充足 UAV:用一种梯度无关的稀疏视觉 prompt 优化方法(CMA-ES 进化策略)在线搜索更合适的 prompt,但仍然不改模型权重。
系统还配了一个激活统计检测器,当检测到性能可能在掉(分布漂移信号)才触发适配;更关键的是它搞了一个跨 UAV 知识池,把各机学到的 prompt 经验汇总成“共享提示库”,让整个机群协作适配,而且带宽开销很小。整体看,这篇把“大模型”用在一个非常落地的方式上:模型不动,prompt 作为可交换、可共享的适配参数,让低空网络的感知鲁棒性变得可维护、可协作。
链接:https://arxiv.org/pdf/2511.11720
CoDrone: Autonomous Drone Navigation Assisted by Edge and Cloud Foundation Models
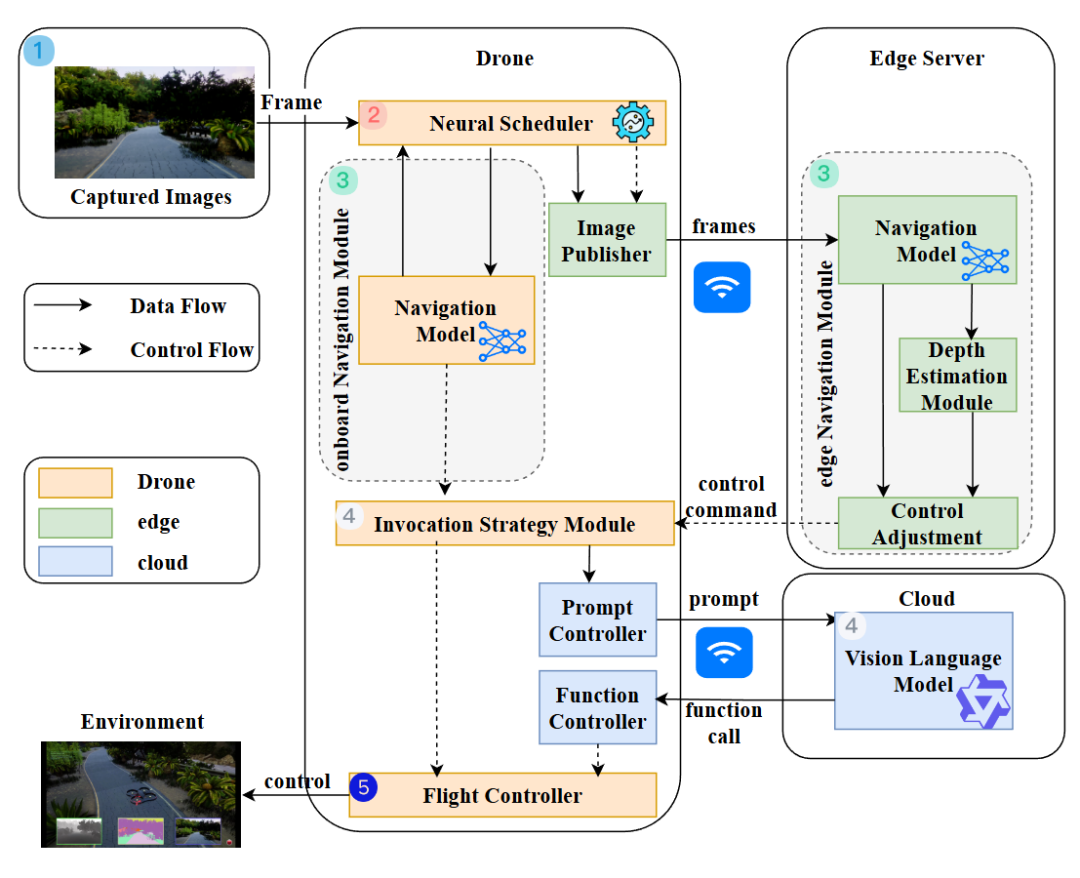
机构:中山大学,鹏城实验室
主要内容:无人机机载算力有限,很多时候只能跑“瘦身版网络”,一进复杂环境就不够聪明;但把任务全扔到云端/边缘又会遇到网络延迟,决策变慢甚至失控,于是系统设计天然卡在“算力 vs 时延”的跷跷板上。CoDrone 提出一个 端-边-云协同(end-edge-cloud)的计算框架,目标是在不把无人机拖死的前提下,把 foundation model 的能力引进来,专门服务于无人机的巡航导航场景。
它把“大模型怎么用”拆成了几块非常具体的落点:
-
机载端尽量轻:为了降低计算与传输开销,导航模型只用灰度图作为输入,先保证“能实时飞”。
-
需要更强理解时再叫外援:当环境更复杂、需要更精细的几何感知时,系统会调用边缘端的基础模型 Depth Anything V2 做深度估计,把“重活”放到边缘算力上。
-
把深度变成更易用的导航表示:他们提出一种一维占据栅格(1D occupancy grid)的导航方法,用更简单的表示承接深度信息,既提升理解的细粒度,又让表示更省、更适合导航决策。
-
用 DRL 做调度与融合:核心还有一个 DRL 神经调度器,负责在不同网络条件、不同动态环境下,决定何时需要深度增强、如何把深度与导航动作决策融合起来,实现实时自适应。
-
VLM 做开放集推理的“交互层”:更进一步,它引入了一个 UAV 领域的视觉语言交互模块,把“云端 foundation model / VLM 的推理结果”对接到无人机可执行的低层飞行原语上,让系统在未知场景下具备更强的开放集推理与应对能力。
链接:https://arxiv.org/pdf/2512.19083
总结
无人机正在从“工程师预设的自动化设备”,走向“面向用户意图的开放式智能体”,而大模型是推动这件事的关键语言接口与认知引擎。
但真正决定能不能落地的,不是模型能答对多少题,而是系统能不能把大模型的能力变成可持续、可实时、可安全的飞行闭环。于是我们看到越来越多“正确的姿势”:用异步架构和语义记忆消化推理频率差,用结构化场景与基准把能力测准,用提示/轻量适配提升鲁棒性,用端-边-云协同把算力延迟的跷跷板压到可用范围,用双智能体或工具链把自然语言意图稳稳落到飞行原语。
下一阶段的竞争点也会更清晰:谁能在真实低空环境里长时间稳定运行,谁能把不确定性、资源约束与安全边界纳入决策,谁就更接近“把大模型真正装进无人机”这件事。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)