0.005%参数量超越SOTA!提升模型能力无需庞大奖励模型
上海交通大学、新加坡国立大学、同济大学、伊利诺伊大学的联合研究团队提出了一种全新的轻量级奖励模型SWIFT(Simple Weighted Intrinsic Feedback Technique)。增强大模型能力,无需庞大外部奖励模型作为裁判了!上海交通大学、新加坡国立大学、同济大学、伊利诺伊大学的联合研究团队提出了一种全新的轻量级奖励模型SWIFT(Simple Weighted Intrin
上海交通大学、新加坡国立大学、同济大学、伊利诺伊大学的联合研究团队提出了一种全新的轻量级奖励模型SWIFT(Simple Weighted Intrinsic Feedback Technique)。
增强大模型能力,无需庞大外部奖励模型作为裁判了!
上海交通大学、新加坡国立大学、同济大学、伊利诺伊大学的联合研究团队提出了一种全新的轻量级奖励模型SWIFT(Simple Weighted Intrinsic Feedback Technique)。

SWIFT利用大模型隐藏状态中原本存在的线性特征,仅需训练一个极小的线性层即可在推理任务中超越庞大的主流奖励模型,实现计算效率与准确率的双重飞跃。
挖掘大模型潜意识里的直觉信号
大语言模型在生成文本时,其内部实际上一直在进行自我博弈与评估。
这种评估并非通过显式的文字输出,而是通过神经网络深层的隐藏状态(Hidden States)静默流淌。
如同人类在回答问题时,内心深处往往在开口前就已经对答案的靠谱程度有了一个预判,这种潜意识的自信度比最终说出来的漂亮话更真实。
传统的提升大模型推理能力的方法,尤其是Best-of-N采样策略,核心逻辑是让模型针对同一个问题生成多个候选答案,然后从中挑选出最好的一个。
这个挑选的过程,是决定最终效果的关键瓶颈。
目前的工业界标准做法,是训练一个独立的、庞大的奖励模型(Reward Model)来充当裁判。
这些奖励模型本身通常也是一个参数量巨大的Transformer模型,它们像批改作业的老师一样,阅读生成的文本,然后打分。
这种做法存在着显而易见的弊端。
它极度消耗计算资源,用一个70亿参数的模型去评估另一个70亿参数的模型,计算成本直接翻倍。
它极度依赖数据,训练这些奖励模型需要海量的高质量标注数据,这在逻辑推理和数学领域尤为昂贵。
这种外部裁判模式完全舍弃了生成模型在生成过程中产生的内部信号。
生成模型在推导数学公式或编写代码的每一步,其神经元的激活模式都隐含了它对当前步骤的确定性。
为了验证这一假设,研究人员设计了一个精巧而直观的实验。
他们从Llama-3.1-8B-Instruct模型中提取推理过程的隐藏状态。
对于每一个生成的token,提取其在每一层的隐藏状态向量。
将这些高维向量通过主成分分析(PCA)降维,然后使用线性判别分析(LDA)来预测该推理路径最终是否正确。
这是一个完全线性的探测管道,如果它能工作,就证明了隐藏状态中包含了线性可分的正确性信号。
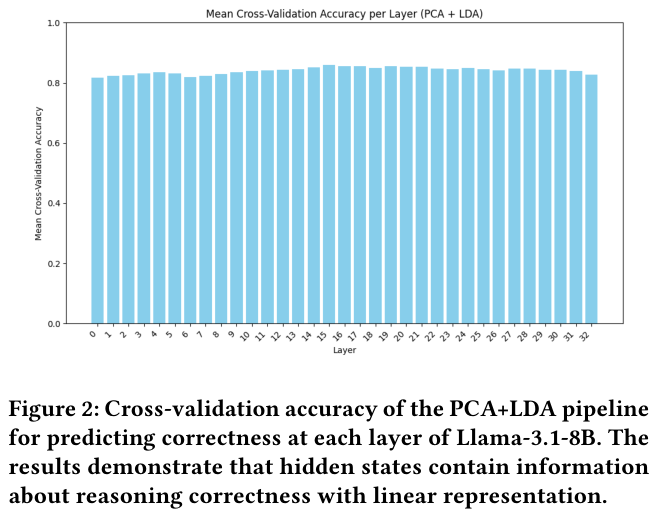
实验结果令人振奋,如上图所示。
在模型的各个层级,仅凭隐藏状态进行的线性分类,其准确率就稳定在80%左右。
这意味着模型其实知道自己在胡说八道还是在严谨推导,这种信号清晰地存在于其内部表示中。
这种线性可分性是一个极具价值的发现。
它暗示我们根本不需要训练复杂的非线性神经网络来评估生成质量。
我们只需要一把简单的手术刀,即一个线性层,就能将这些深埋的信号提取出来,转化为指导采样的奖励分数。
这就是SWIFT(Simple Weighted Intrinsic Feedback Technique)技术的理论基石。
与其外聘一个昂贵的裁判,不如直接连通模型的大脑,听听它真实的心声。
极简线性层重构奖励建模新范式
基于上述发现,SWIFT技术应运而生,它的设计哲学是极致的简约与高效。
SWIFT抛弃了传统奖励模型那种笨重的Transformer架构。
它不需要重新处理一遍生成的文本,而是直接寄生在任务模型(Task-performing LLM)之上。
当任务模型生成推理步骤时,SWIFT实时截获各层的隐藏状态。
具体来说,对于推理路径中的每一个token,SWIFT将该token在所有层(例如32层)的隐藏状态拼接起来,形成一个长向量。
这个长向量包含了该时刻模型对语义、语法以及逻辑连贯性的全部理解。
随后,SWIFT引入了一个轻量级的线性层。
这个线性层有两个输出目标:一个是门控值(Gating Value),一个是奖励值(Reward Value)。
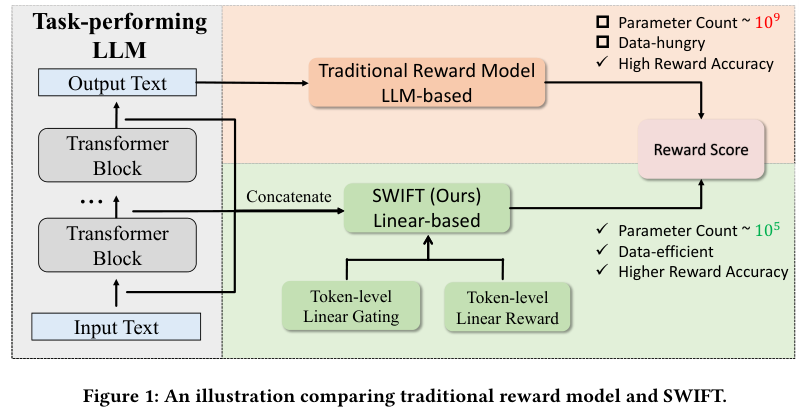
门控机制是SWIFT的点睛之笔。
并不是每一个token对最终答案的正确性都同等重要。
在一个数学证明中,关键的转折步骤、数值计算的结果、或者是最终的结论词,其重要性远超那些连接词或通用的废话。
门控值通过Sigmoid函数归一化,动态地决定当前token的权重。
奖励值则直接预测当前步骤的质量。
最终的整条推理路径的得分,就是所有token奖励值的加权平均,权重正是那些门控值。
这种设计使得SWIFT能够进行细粒度的评估,而不是像传统模型那样只能对整段文本给出一个笼统的分数。
数学表达上,这仅仅涉及几个矩阵乘法和加法,计算量几乎可以忽略不计。
为了训练这个线性层,研究人员使用了二元交叉熵损失函数(Binary Cross-Entropy)。
训练数据也很简单:正确的推理路径标记为1,错误的标记为0。
SWIFT要做的,就是让正确路径的预测得分尽可能高,错误路径的得分尽可能低。
就是这样一个简单的逻辑,在实际测试中展现出了惊人的爆发力。
让我们来看看具体的实验设置与结果。
研究在MATH、GSM8K、AQuA_RAT等多个高难度的数学推理数据集上进行了评估。
使用的基座模型包括Llama-3.2-3B、Llama-3.1-8B以及Ministral-8B。
作为对比的,是一系列开源界最强的奖励模型,包括Eurus-7B、Skywork-Reward、Starling-7B、UltraRM-13B等。
这些基线模型个个身怀绝技,都是在大规模数据集上经过专门训练的庞然大物。
比如Eurus-7B,它是专门针对数学和代码领域优化的SOTA模型。
Skywork-Reward则是基于Llama-3.1-8B训练的通用奖励模型。
这就像是让一个装备精良的正规军(基线模型)与一个仅配备了一把匕首的刺客(SWIFT)对决。
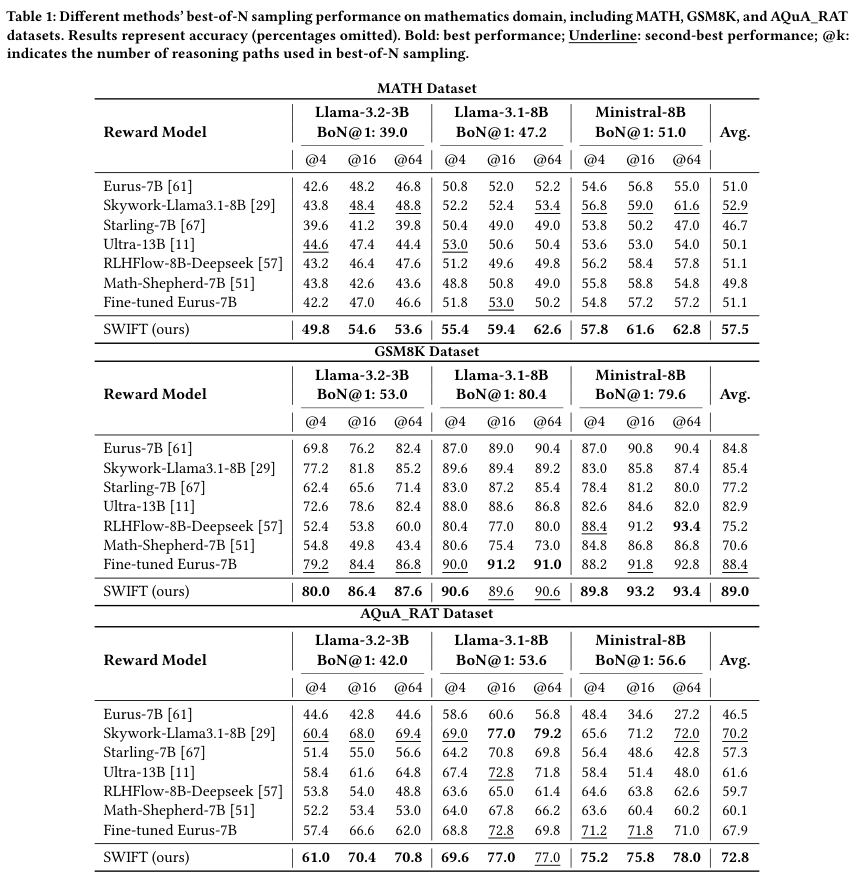
在MATH数据集上,SWIFT在所有Best-of-N设置下全面超越了这些巨型模型。
可以看到,在MATH数据集上,SWIFT的平均准确率达到了57.5%,比著名的Eurus-7B(51.0%)高出了6.5个百分点,比表现最好的基线Skywork(52.9%)也高出一大截。
在Llama-3.1-8B模型上,当采样路径数达到64条(@64)时,SWIFT将准确率从基座的47.2%拉升到了62.6%。
这是一个巨大的提升,原本答不对的问题,现在有一半以上能被正确选出。
在GSM8K和AQuA_RAT数据集上,SWIFT同样保持了这种压倒性的优势。
值得注意的是,表格中还列出了一个Fine-tuned Eurus-7B。
这是研究者为了公平起见,专门用同样的训练数据对Eurus进行了微调。
即便如此,微调后的Eurus依然无法击败SWIFT。这说明SWIFT的优势来自于它触达了信息的本质——隐藏状态。
外部观察者(传统RM)即便再敏锐,也比不上内部亲历者(SWIFT)对自我状态的感知来得直接和准确。
这种准确性并非偶然,它在不同模型尺寸、不同难度的数据集上展现出了极强的一致性。
它证明了简单的线性映射足以捕捉大模型推理过程中的置信度波动。
复杂的非线性结构在处理这种内隐信号时,反而可能因为过拟合或噪声干扰而效率低下。
参数与算力效率的降维打击
SWIFT最令人震撼的是它实现这一准确率所付出的代价极小。
通常性能提升通常伴随着算力的指数级增长。
但SWIFT打破了这一规律,它在提升性能的同时,将计算成本压缩到了几乎可以忽略不计的程度。
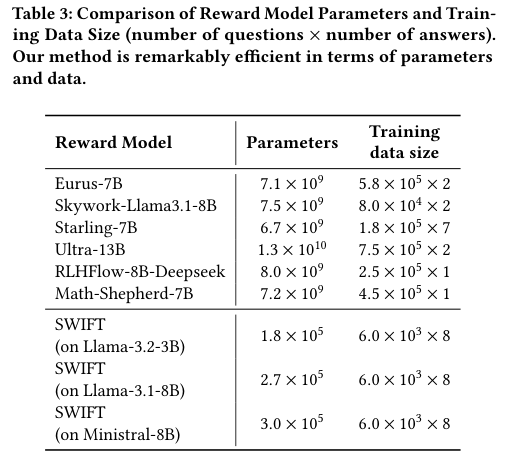
让我们先看参数量。
传统的奖励模型,动辄70亿(7B)、130亿(13B)个参数。
要部署这些模型,你需要昂贵的高端显卡,占用几十GB的显存。
而SWIFT呢?
它只有大约20万到30万个参数。
相比于Eurus-7B的71亿参数,SWIFT的参数量不到它的0.005%。
下表清晰地展示了这种悬殊的对比:
除了参数量,训练数据的需求也大幅降低。
传统模型往往需要数万甚至数十万条经过精细标注的数据。
而SWIFT仅用了6000个样本进行训练,就达到了上述的SOTA效果。
当我们需要为一个新的垂类领域(比如医疗或法律)定制奖励模型时,数据的收集成本将不再是不可逾越的障碍。
再来看推理速度和计算量(FLOPs)。
在实际应用中,Best-of-N采样的最大痛点就是慢。
每生成N个答案,就要用奖励模型跑N次前向传播,时间成本是线性的。
如果奖励模型本身很重,整个系统的延迟将无法接受。
SWIFT因为其极简的线性结构,在推理时几乎不增加额外的计算负担。
计算隐藏状态是生成过程本身就必须做的,SWIFT只是在最后加了一个极小的矩阵乘法。
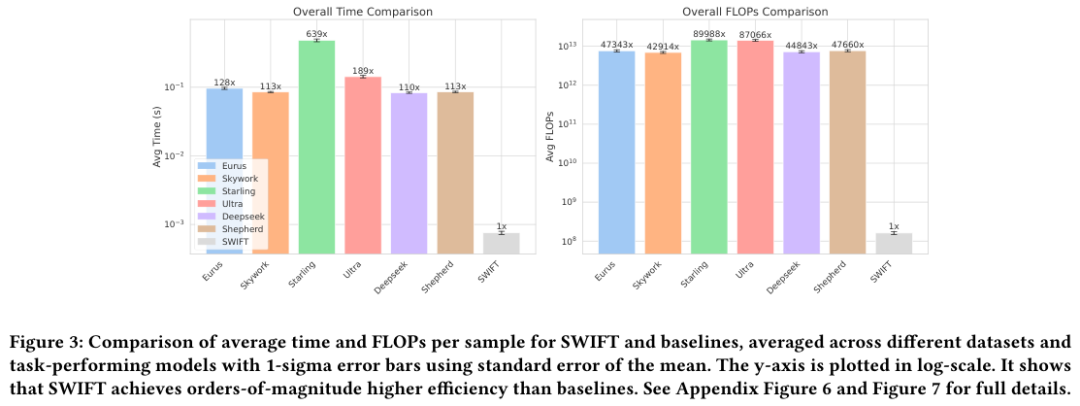
上图直观地展示了这种效率差异。
注意纵坐标是对数坐标(Log Scale)。
SWIFT的耗时和计算量比基线模型低了整整3到4个数量级。
在CoinFlip数据集的端到端测试中,使用Llama-3-3B配合Starling奖励模型,推理时间的大头都花在了奖励打分上,整个过程需要0.36秒。
而换成SWIFT后,总时间缩短到了0.05秒,速度提升了6.7倍。
这其中的差别,决定了一个功能是只能在实验室里跑Demo,还是能部署到千万用户的手机上实时运行。
研究者更进一步探索,既然每一层的隐藏状态都有用,那是不是所有层都是必须的?
实验发现,并不是。
仅使用Llama-3.1-8B的第16、24、28、32这四层的隐藏状态,SWIFT依然能保持几乎相同的性能。
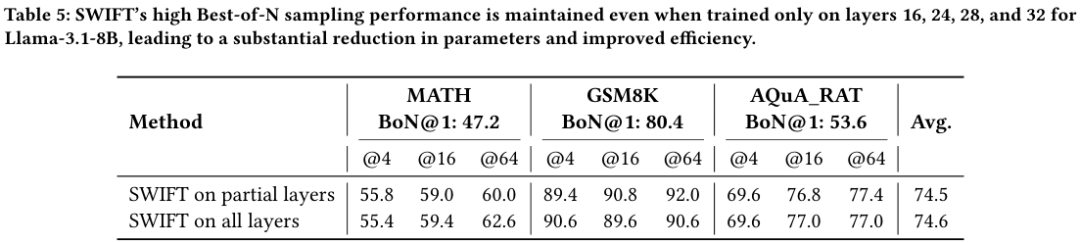
如上表所示,仅用4层信息的简化版SWIFT与全层版本的平均准确率几乎持平(74.5 vs 74.6)。
这进一步证明了有效信号在模型深层的高度冗余和集中。
特别是后几层(Later Layers),它们包含了更强的正确性信号。
这种层级选择的灵活性,为在资源受限设备上的部署提供了更多可能。
我们完全可以想象,未来在手机端运行的大模型,自带一个轻量的SWIFT模块,在用户毫无察觉的情况下,默默地过滤掉那些质量不佳的回答,只呈现最完美的结果。
跨域泛化与闭源模型的适配潜力
虽然SWIFT在数学推理上大放异彩,但它的能力远不止于此。
研究者将其应用范围扩展到了代码理解、常识推理和符号推理等多个通用领域,依然表现强劲。
在代码理解任务(Imbue Code Comprehension)中,SWIFT再次击败了所有基线模型。
在常识推理(HellaSwag)和符号推理(CoinFlip)中,它也稳居第一梯队。
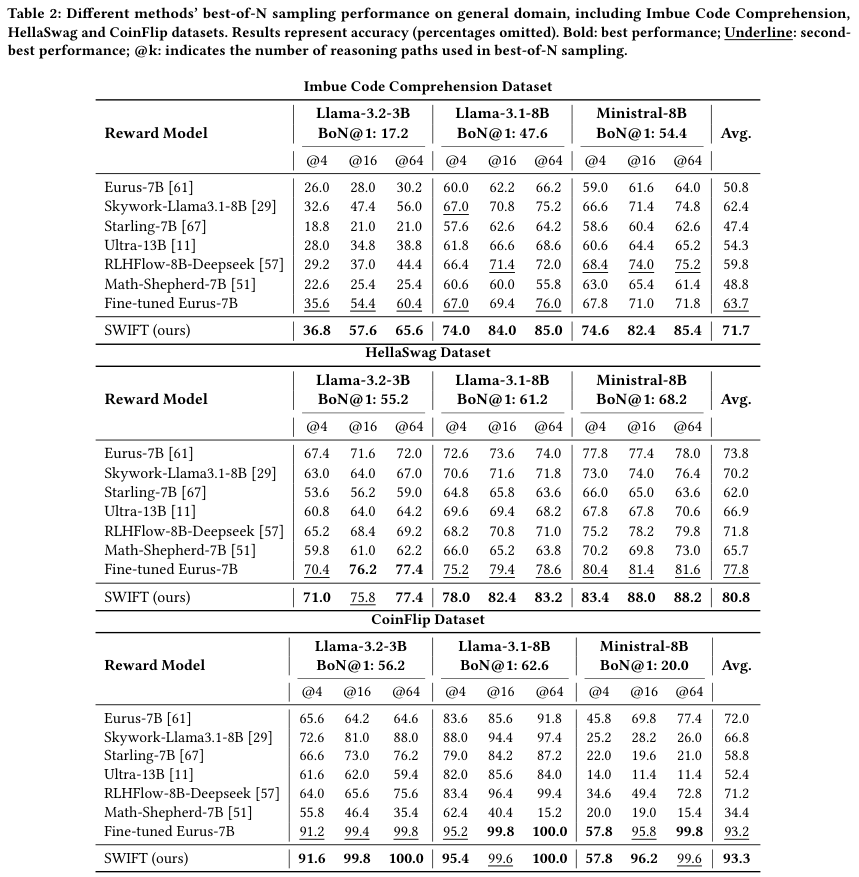
SWIFT捕捉到的不仅仅是数学题算没算对,而是一种更通用的生成质量或模型置信度信号。
无论是写代码时的逻辑闭环,还是回答常识问题时的语境匹配,模型内部的确定性信号都是相通的。
更有趣的是,SWIFT甚至可以用于安全性对齐(Safety Alignment)。
在PKU-SafeRLHF数据集的测试中,用SWIFT指导模型生成,能够显著提高回复的有用性(Helpfulness)和安全性(Safety)。
这表明隐藏状态中也编码了关于是否有害、是否违规的道德判断信号,只待我们去挖掘。
然而,SWIFT面临一个现实的挑战:它需要访问模型的隐藏状态。
对于像GPT-4这样的闭源模型,普通用户是拿不到隐藏状态的。
但这并不意味着SWIFT束手无策。
研究者发现,许多闭源模型API虽然不提供隐藏状态,但会提供Logits(即Token的输出概率分布)。
Logits虽然是隐藏状态经过最后投影后的结果,信息量有所损失,但依然保留了核心的置信度特征。
于是,研究者尝试仅利用Logits来训练SWIFT。
结果令人惊喜。
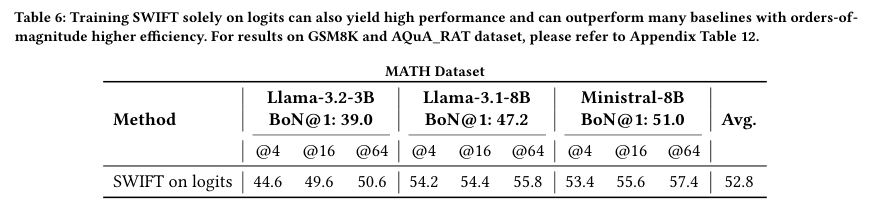
即便是在盲人摸象般的Logits模式下,SWIFT的平均表现(52.8)依然超过了Eurus-7B(51.0)等完全体模型。
这为SWIFT在闭源生态中的应用打开了一扇大门。
我们可以通过API获取的有限信息,在客户端构建一个超轻量的过滤器,优化昂贵的API调用结果。
此外,SWIFT具有极好的可扩展性(Scalability)。
随着训练样本数量的增加,以及推理时采样路径数量(N)的增加,SWIFT的性能曲线呈现出持续上升的趋势,没有明显的饱和迹象。
投入越多,回报越高,这对于工业界的大规模应用是一个非常积极的信号。
我们甚至可以将SWIFT与传统的外部奖励模型结合起来使用。
通过简单的加权平均或排名融合,SWIFT可以作为现有系统的有力补充,进一步压榨出最后一点性能提升。
SWIFT的出现,标志着大模型后训练时代的一个重要转折。
我们开始从外部强加规则转向内部挖掘潜能。
与其试图教会另一个模型什么是好,不如直接读取原模型那个虽然微弱但无比真实的自信心。
这种内省式的AI进化之路,不仅更高效,也更接近智能的本质。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献193条内容
已为社区贡献193条内容

所有评论(0)