LoRA:其实就是给大模型“装插件”(内附python微调源码)
LoRA(低秩适应)是一种高效微调大模型的技术,通过训练少量额外参数(适配器)来赋予大模型新能力,而无需修改原始参数。相比全量微调,LoRA具有显存占用低、训练速度快、存储成本小等优势。技术实现包括冻结原模型、注入低秩矩阵、训练适配器、合并权重等步骤。文章提供了使用LoRA微调千问模型的完整代码流程,涵盖环境准备、数据格式化、参数配置、训练实施等环节,并强调数据质量比数量更重要。该技术特别适合个人
核心定义
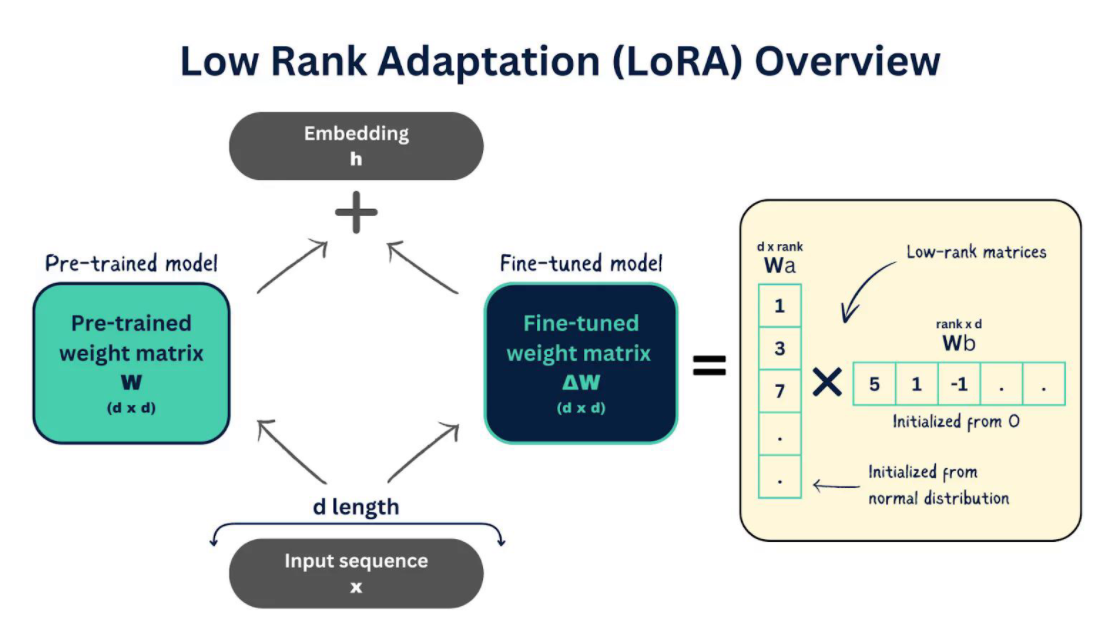
LoRA(Low-Rank Adaptation,低秩适应)是一种参数高效微调(PEFT)技术。它的核心思想是:在不修改原始大模型参数的前提下,通过训练少量的额外参数(适配器),来让大模型学会新技能。
如果我们把大模型(如千问、Deepseek)比作一个已经毕业的全能博士,那么 LoRA 就是给这位博士报了一个“短期速成班”,而不是让他回炉重造。
全量微调的痛点(重造大脑)
想象一下,千问模型是一个拥有 70 亿个旋钮(参数)的巨型黑盒。
- 操作:全量微调需要调整这 70 亿个旋钮。
- 缺点:显存爆炸(需要 80GB+),速度极慢,且容易把模型原本的通用知识(如语法、常识)学乱。
LoRA 的核心思想(打补丁)
LoRA 的核心假设是:预训练模型在适应新任务时,其参数的变化($\Delta W$)其实具有“低秩”特性。 也就是说,不需要调整所有旋钮,只需要调整其中几个关键的“组合”就能学会新技能。
它是如何工作的?(技术原理通俗版)
想象一下,大模型是一个极其复杂的神经网络,由无数个“神经元”连接而成。传统的微调(Fine-tuning)就像是把整个大脑的连接线都重新调整一遍,成本极高。
而 LoRA 的做法非常巧妙:
- 冻结(Freeze):
我们把千问模型的原始参数“冻住”。这意味着,那些庞大的、已经训练好的知识(比如语法、常识)保持不变,我们不碰它们。 - 注入(Inject):
我们在模型的某些关键层(通常是注意力机制中的 Q、V 矩阵)旁边,“挂”上两个小小的、像三明治一样的低秩矩阵( A 和 B )。这就是 LoRA 适配器。
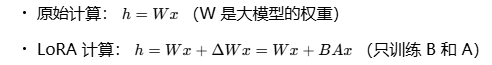
- 训练(Train):
我们只训练这两个小小的矩阵 A 和 B 。因为它们的参数量非常少(可能只占原模型的 0.1% - 1%),所以:- 显存占用极低:不需要把整个大模型的梯度都存下来。
- 速度快:计算量小。
- 成本低:你可以在单张消费级显卡(如 RTX 3090/4090)上运行。
- 合并(Merge):
训练结束后,我们可以把 BA 的结果“叠”回原来的 W 上。这样,你就得到了一个全新的、具备新技能的千问模型,而不需要每次都带着那个“小插件”运行。
具体操作步骤(全流程详解)
使用 LoRA 对千问模型进行指令微调,通常分为以下 5 个步骤:
第一步:环境与模型准备
- 操作:安装
transformers、peft、datasets等库。 - 加载模型:从 Hugging Face 或本地加载千问模型(如
Qwen-7B-Chat)。 - 关键动作:此时模型是“只读”状态。
第二步:数据准备(最关键的一步)
指令微调的数据必须是 “指令-输出” 对。
- 格式:JSON 或 JSONL 格式。
- 结构:
[ { "instruction": "你是一个资深客服,请礼貌地回答用户关于退货的问题。", "input": "我不想要这个商品了,怎么退货?", "output": "您好,非常抱歉给您带来不便。关于退货流程,您可以在订单页面点击“申请退货”..." }, { "instruction": "请将以下句子翻译成法语", "input": "今天天气真好", "output": "Il fait très beau aujourd'hui." } ] - 原理:模型会将
instruction和input拼接作为输入(Prompt),学习生成output。
第三步:配置并注入 LoRA 适配器
这是技术核心。我们需要告诉代码:“在模型的哪些位置挂上你的‘小脑’”。
- 代码逻辑:
- 冻结原模型:
model.requires_grad_(False)。 - 定义配置:指定秩
r、目标模块target_modules。 - 注入:使用
get_peft_model(model, lora_config)。
- 冻结原模型:
- 参数详解(参考之前的“速查表”):
r=64:适配器的维度,越大越强。target_modules=["q_proj", "v_proj"]:这是 Transformer 架构中负责“理解问题”和“关注重点”的部分,修改这里对指令遵循最有效。
第四步:训练循环
- 前向传播:
- 输入数据进入模型。
- 原始模型计算出一个结果。
- LoRA 适配器($B \cdot A$)计算出一个微调结果。
- 两者相加,得到最终输出。
- 计算损失:
- 比较“最终输出”和你准备的“标准答案”(
output)。 - 计算误差(Loss)。
- 比较“最终输出”和你准备的“标准答案”(
- 反向传播:
- 只更新 LoRA 矩阵 A 和 B的梯度。
- 原始模型 W0的梯度被丢弃(因为被冻结了)。
第五步:保存与推理
- 保存:只保存 LoRA 适配器的权重(通常只有几 MB 到 100MB),而不是保存整个 14GB 的模型。
- 合并(可选):你可以选择将 LoRA 权重合并回原模型,生成一个全新的、独立的模型文件。
- 推理:加载原模型 + 加载 LoRA 权重,即可进行对话。
LoRA 的核心优势
| 维度 | 传统全量微调 (Full Fine-tuning) | LoRA 微调 |
|---|---|---|
| 显存占用 | 极高(需要存储所有参数的梯度) | 极低(只存储少量适配器参数) |
| 训练速度 | 慢 | 快 |
| 存储成本 | 每微调一次,就得存一个完整的模型副本 | 极省(只存几 MB 的适配器文件) |
| 适用场景 | 有海量数据和算力集群 | 个人开发者、企业私有化部署 |
Python代码实例
需求:使用 LoRA(Low-Rank Adaptation)微调千问(Qwen)模型,可以让模型学习你公司的私有数据(如产品手册、客服问答、内部流程等)。
安装依赖包
pip install torch transformers accelerate peft datasets bitsandbytes
完整代码
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling
)
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from datasets import load_dataset, Dataset
import json
# ==========================================
# 1. 配置参数 (请根据你的环境修改)
# ==========================================
model_name = "Qwen/Qwen-1_8B-Chat" # 你可以换成 Qwen-7B 或本地路径
data_path = "company_data.json" # 你的私有数据路径
output_dir = "./qwen_company_lora" # 训练结果保存路径
# 训练超参数
batch_size = 1
gradient_accumulation_steps = 8
learning_rate = 2e-4
num_train_epochs = 3
# ==========================================
# 2. 加载模型与 Tokenizer
# ==========================================
print("正在加载模型和 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(
model_name,
trust_remote_code=True,
use_fast=False
)
# --- 可选:配置量化 (QLoRA) ---
# 如果你显存较小(如16GB),取消下面的注释,使用4-bit量化
# bnb_config = BitsAndBytesConfig(
# load_in_4bit=True,
# bnb_4bit_quant_type="nf4",
# bnb_4bit_compute_dtype=torch.bfloat16,
# bnb_4bit_use_double_quant=True,
# )
model = AutoModelForCausalLM.from_pretrained(
model_name,
# quantization_config=bnb_config, # 如果使用QLoRA,取消注释
device_map="auto",
trust_remote_code=True
)
# 如果使用了量化,需要这一步来准备模型进行k-bit训练
# model = prepare_model_for_kbit_training(model)
# ==========================================
# 3. 准备 LoRA 配置
# ==========================================
print("正在配置 LoRA 适配器...")
LoraConfig(
r=64, # 给我造一个容量中等的“小脑”
lora_alpha=16, # 给这个小脑配一个中等音量的喇叭
target_modules=["q_proj", "v_proj"], # 把这个小脑接在千问大脑的“注意力”区域
lora_dropout=0.05, # 训练时稍微偷点懒,防止死记硬背
bias="none", # 不用管那些细枝末节的偏置
task_type="CAUSAL_LM" # 我们要让它学会聊天和创作
)
model = get_peft_model(model, lora_config)
# 打印可训练参数,确认只有LoRA部分是trainable的
model.print_trainable_parameters()
# ==========================================
# 4. 准备数据集
# ==========================================
print("正在加载和处理数据...")
# 假设你的 company_data.json 是一个字典列表
# 格式示例: [{"instruction": "公司WiFi密码?", "output": "password123"}, ...]
with open(data_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 将数据转换为 Hugging Face Dataset 格式
dataset = Dataset.from_list(data)
# --- 数据处理函数 ---
# 这里我们构造一个 prompt,告诉模型这是公司的内部知识
def format_instruction(example):
# 这里构造训练文本: "final<|im_channel|>根据公司内部知识回答:{instruction}<|im_channel|>final<|im_message|>{output<|im_channel|>final<|im_message|>"
prompt = f"<|im_channel|>final<|im_message|>根据公司内部知识回答:{example['instruction<|im_message|>final<|im_message|>{example['output<|im_message|>final<|im_message|>"
example["text"] = prompt
return example
# 映射处理
dataset = dataset.map(format_instruction)
# --- Tokenization ---
def tokenize_function(examples):
return tokenizer(examples["text"], truncation=True, max_length=512, padding=False)
tokenized_datasets = dataset.map(tokenize_function, batched=True, remove_columns=dataset.column_names)
# ==========================================
# 5. 配置训练器 (Trainer)
# ==========================================
print("开始训练...")
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
learning_rate=learning_rate,
num_train_epochs=num_train_epochs,
logging_dir=f"{output_dir}/logs",
logging_steps=10,
save_strategy="epoch",
report_to="none", # 不连接wandb等外部服务
fp16=True, # 混合精度训练,节省显存
optim="paged_adamw_8bit", # 防止内存碎片,如果不用量化可以改为 "adamw_torch"
remove_unused_columns=False, # 保证数据集列名匹配
)
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
# ==========================================
# 6. 执行训练
# ==========================================
trainer.train()
# ==========================================
# 7. 保存模型
# ==========================================
print("正在保存 LoRA 适配器...")
# 保存 LoRA 权重
model.save_pretrained(output_dir)
print(f"训练完成!模型已保存至: {output_dir}")数据准备
为了让模型学习公司的私有数据,需要将数据整理成 JSON 格式。这是最关键的部分!
文件名:company_data.json
[
{
"instruction": "我们公司的名字叫什么?",
"output": "我们公司名叫 阿里巴巴。"
},
{
"instruction": "公司的年假政策是怎样的?",
"output": "员工入职满一年后,享有10天带薪年假。"
},
{
"instruction": "午休时间是几点到几点?",
"output": "午休时间是中午12:00到下午13:30。"
},
{
"instruction": "如何申请报销?",
"output": "请在OA系统中填写报销单,并附上发票照片,提交给财务部王经理审批。"
}
]如何使用训练好的模型?
训练完成后,得到的不是一个完整的新千问模型,而是一个LoRA 适配器文件夹(包含 adapter_model.bin 等文件)。在推理时,需要同时加载原始模型和 LoRA 适配器:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
# 1. 加载原始千问模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B-Chat", device_map="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1_8B-Chat", trust_remote_code=True)
# 2. 注入你的 LoRA 适配器 (让它变身)
model = PeftModel.from_pretrained(model, "./qwen_company_lora")
# 3. 开始对话
prompt = "<|im_message|>final<|im_message|>根据公司内部知识回答:公司的名字叫什么?<|im_message|>final<|im_message|>"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs, skip_special_tokens=True))建议
- 数据质量 > 数据数量:对于 LoRA,几百条高质量的、覆盖核心业务的数据,比几万条重复的数据效果更好。
- 模型选择:如果显卡显存较小(例如 16GB),请务必取消代码中关于
BitsAndBytesConfig的注释,使用 QLoRA 模式。 - 指令一致性:在推理(使用模型)时,输入的指令格式(如“|im_message|>final|im_message|>根据公司内部知识回答...|im_message|>final|im_message|>”)最好和训练时的格式保持一致,这样效果最好。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)