AI大模型机器学习:python二手车数据分析可视化系统 requests爬虫 Echarts可视化 Django框架(源码)
本文介绍了一个基于Python+Django框架开发的二手车数据分析可视化系统。系统采用MySQL数据库存储数据,通过requests爬虫技术从汽车之家平台获取二手车信息,并利用Echarts实现多维度数据可视化展示。核心功能包括:车辆品牌统计、会员注册年份分析、里程区间分布、全国车辆分布地图等可视化图表。项目特色在于整合爬虫技术与数据可视化,为用户提供直观的二手车市场分析工具,降低数据获取与分析
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
python语言、Django框架、MySQL数据库、requests爬虫技术、汽车之家二手车、Echarts可视化
二手车数据分析可视化系统项目介绍
本项目是一款基于Python+Django框架开发的二手车数据分析可视化系统,核心技术栈涵盖MySQL数据库、requests爬虫技术及Echarts可视化库,数据来源聚焦汽车之家二手车平台,为用户提供高效的二手车数据获取与可视化分析服务。
系统核心功能分为数据采集与数据可视化两大模块:通过requests爬虫技术精准爬取汽车之家二手车平台的各类数据,经整理后存储至MySQL数据库,保障数据安全可靠;支持用户通过Web界面输入条件查询所需二手车数据,并借助Echarts实现多维度可视化展示,包括全国各地车辆分布、会员注册年份与等级分布、品牌数据统计、会员占比、里程区间分析及车辆购买日期分析等。
项目依托Django框架快速搭建稳定的Web应用,用户无需复杂操作即可直观获取二手车数据洞察,为购车决策、市场分析等需求提供数据支撑,兼具实用性与易用性,有效降低了二手车数据获取与分析的门槛。
2、项目界面
(1)中国地图–全国各地车辆数据

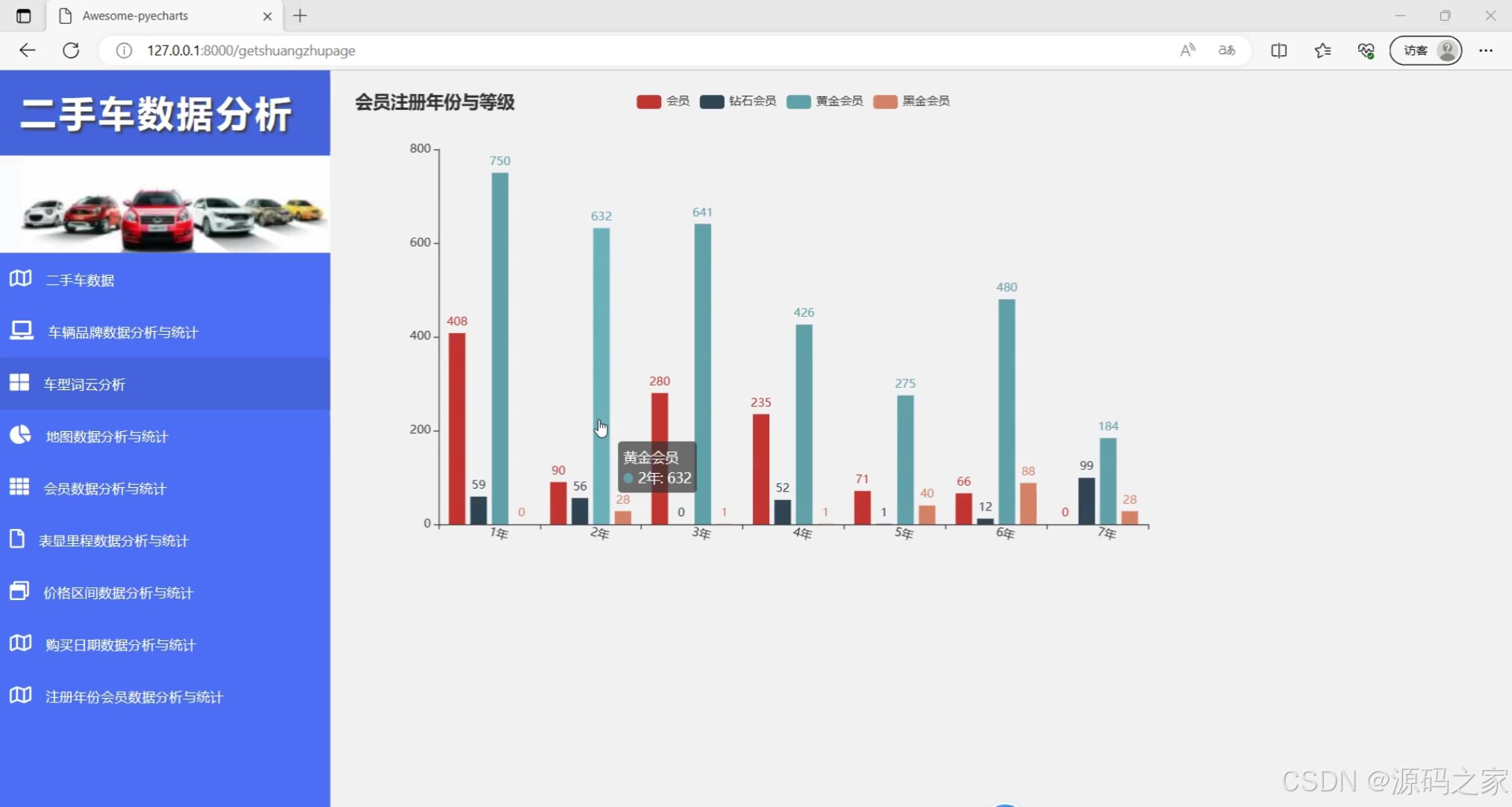
(2)会员注册年份与等级
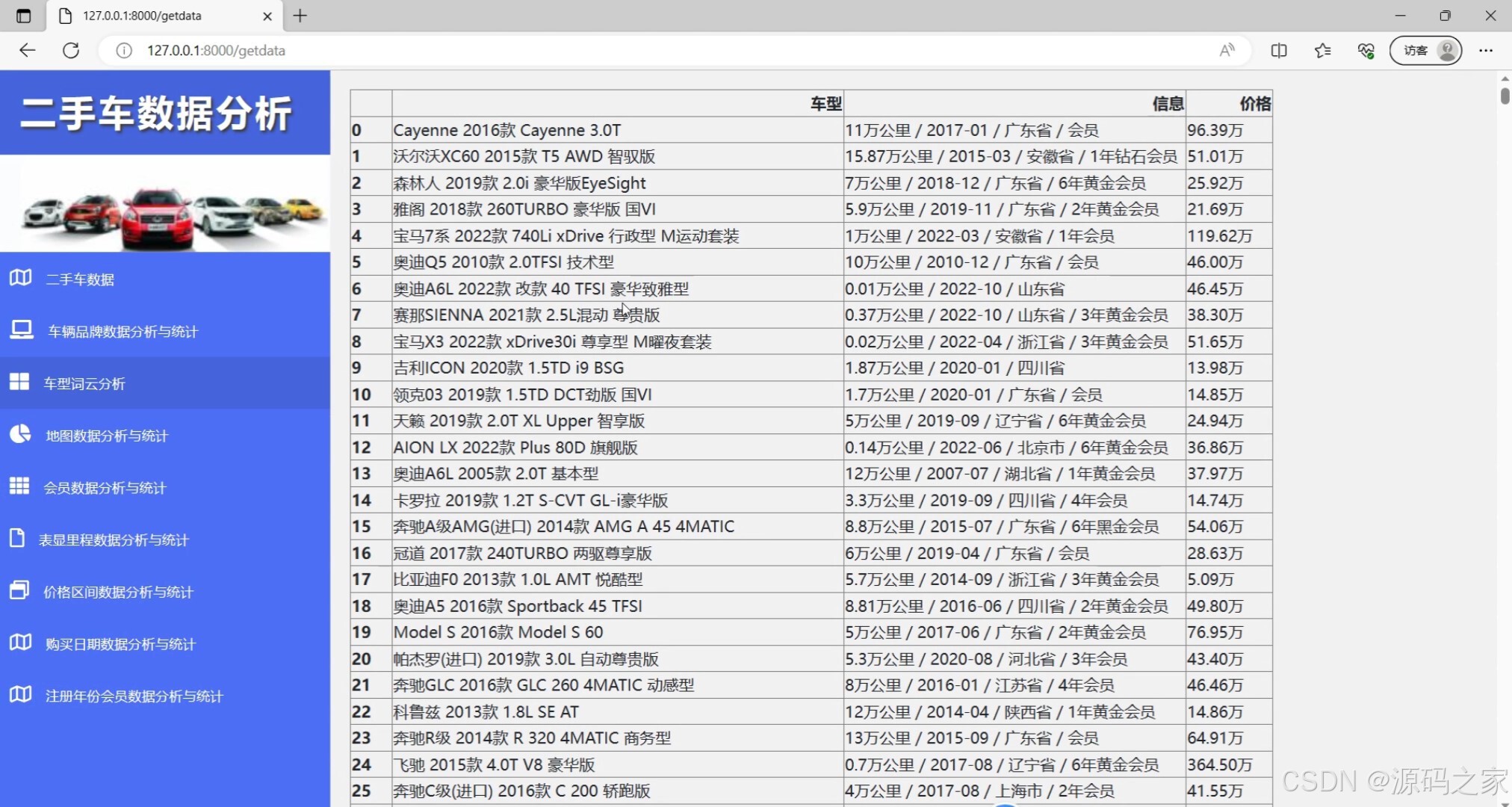
(3)二手车数据
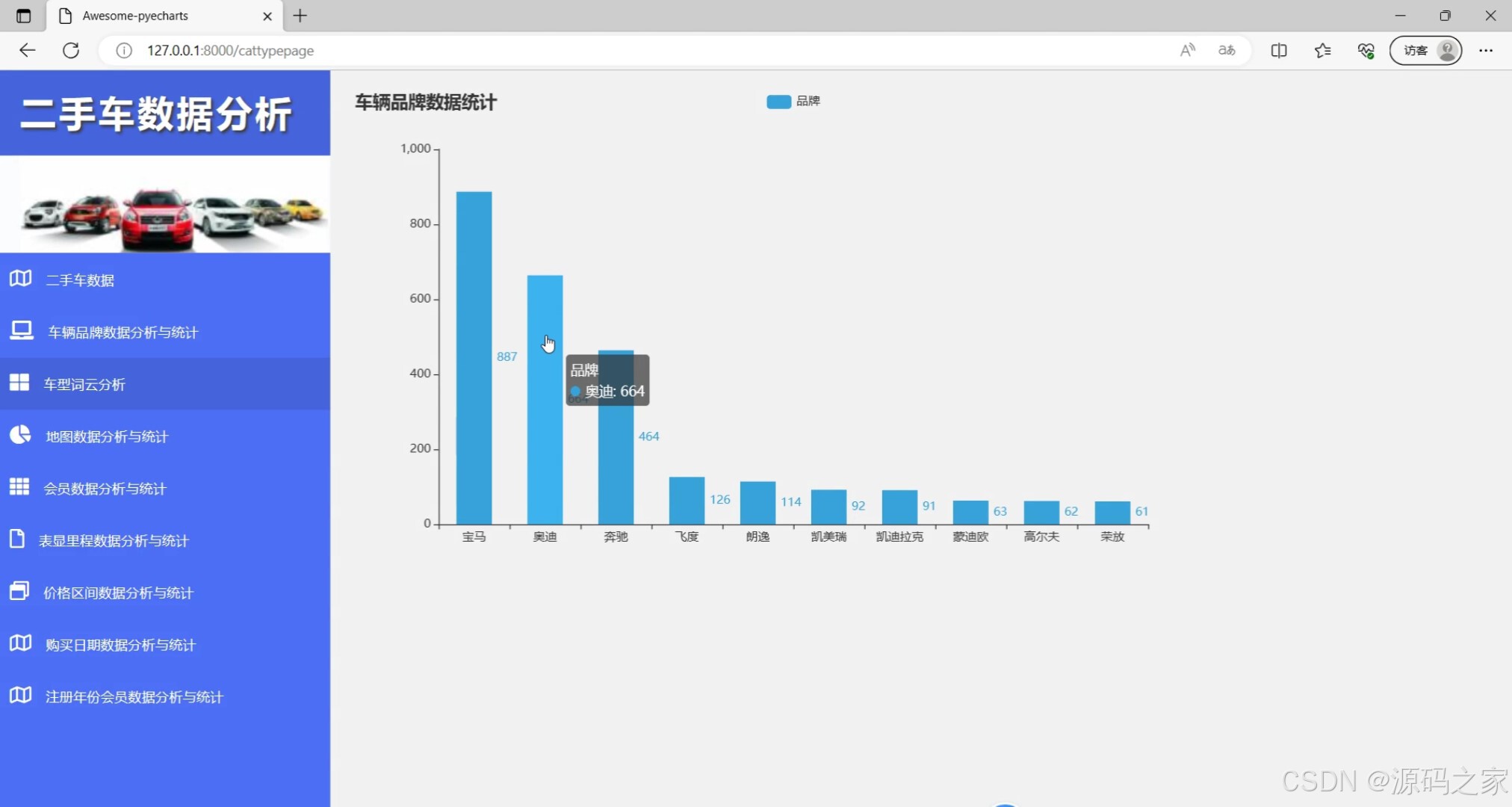
(4)车辆品牌数据统计
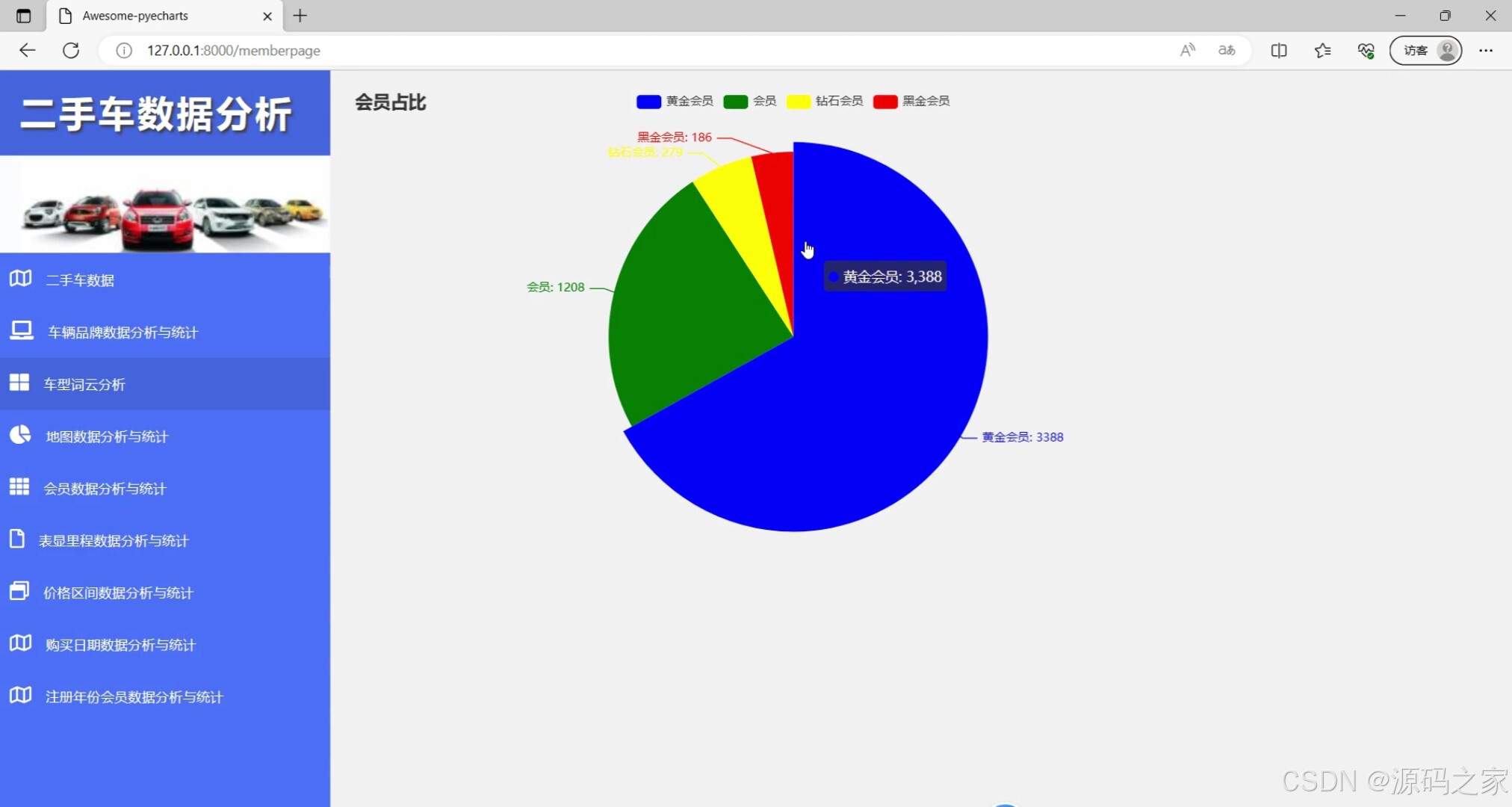
(5)会员占比
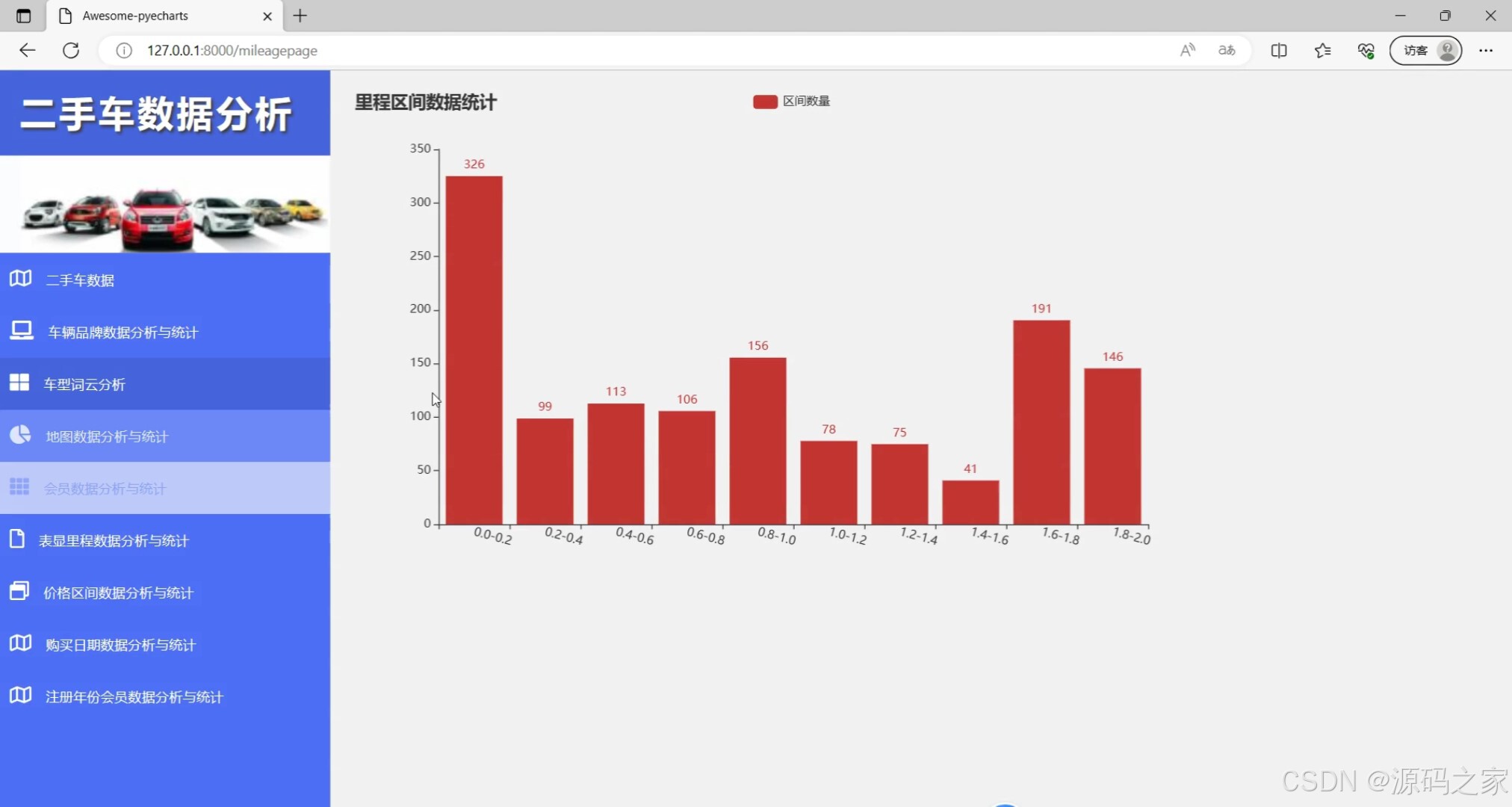
(6)里程区间数据统计分析
(7)车辆购买日期分析
3、项目说明
二手车数据分析可视化系统项目介绍
本项目是一款基于Python+Django框架开发的二手车数据分析可视化系统,核心技术栈涵盖MySQL数据库、requests爬虫技术及Echarts可视化库,数据来源聚焦汽车之家二手车平台,为用户提供高效的二手车数据获取与可视化分析服务。
系统核心功能分为数据采集与数据可视化两大模块:通过requests爬虫技术精准爬取汽车之家二手车平台的各类数据,经整理后存储至MySQL数据库,保障数据安全可靠;支持用户通过Web界面输入条件查询所需二手车数据,并借助Echarts实现多维度可视化展示,包括全国各地车辆分布、会员注册年份与等级分布、品牌数据统计、会员占比、里程区间分析及车辆购买日期分析等。
项目依托Django框架快速搭建稳定的Web应用,用户无需复杂操作即可直观获取二手车数据洞察,为购车决策、市场分析等需求提供数据支撑,兼具实用性与易用性,有效降低了二手车数据获取与分析的门槛。
这是一个使用Python语言和Django框架开发的二手车数据分析可视化系统,主要技术栈包括:
Python语言:作为开发语言,用于编写爬虫和后端程序。
Django框架:作为Web框架,提供了丰富的工具和组件,用于快速搭建Web应用。
MySQL数据库:用于存储二手车相关的数据。
requests爬虫技术:用于从汽车之家网站上获取二手车数据。
汽车之家二手车:作为数据来源,提供了大量的二手车信息。
Echarts可视化:用于将二手车数据进行可视化展示,以便用户更加直观地了解数据。
该系统的主要功能包括爬取汽车之家网站上的二手车数据、将数据存储到MySQL数据库中、根据用户输入的条件查询二手车数据、使用Echarts将数据进行可视化展示。用户可以通过Web界面进行操作和查询,轻松获取所需的二手车数据和分析结果。
4、核心代码
from pyecharts.charts import WordCloud
from pyecharts.globals import ThemeType
from pyecharts.charts import Pie
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.charts import Map
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
# 词云图表
def getciyun(data):
c=(
WordCloud()
.add(series_name="车型词云", data_pair=data, word_size_range=[6, 66])
.set_global_opts(
title_opts=opts.TitleOpts(
title="车型词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
# .render("map3d_with_bar3d.html")
)
# 渲染的html保存为png图片
# make_snapshot(snapshot, c.render(), "词云图表.png")
return c
# 品牌图表
def getchex(data):
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(["宝马","奥迪","奔驰","飞度","朗逸","凯美瑞","凯迪拉克","蒙迪欧","高尔夫","荣放"])
# .add_xaxis(xaxis)
.add_yaxis("品牌", data, stack="stack1", category_gap="50%")
.set_series_opts(
label_opts=opts.LabelOpts(
position="right",
# formatter=JsCode(
# "function(x){return Number(x.data.percent * 100).toFixed() + '%';}"
# ),
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="车辆品牌数据统计"),#, subtitle="经过统计分析,发现BBA的二手车品牌居多,因此购买BBA可以考虑二手车的市场"
)
)
# make_snapshot(snapshot, c.render(), "品牌图表.png")
return c
def getmemberpage(data):
c = (
Pie()
.add("", data)
.set_colors(["blue", "green", "yellow", "red", "pink", "orange", "purple"])
.set_global_opts(title_opts=opts.TitleOpts(title="会员占比"))#, subtitle="经过统计分析,发现黄金会员占据网站的主体,高级会员人数偏少,网站可以改边营业策略以增加高级会员人数提高用户粘度"
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
# .render("pie_set_color.html")
)
# make_snapshot(snapshot, c.render(), "会员占比图表.png")
return c
#里程图表
def getmileage(data):
c = (
Bar()
.add_xaxis(
data['fw']
)
.add_yaxis("区间数量 ", data['count'])
# .add_yaxis("商家B", [20, 10, 40, 30, 40, 50])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="里程区间数据统计"),#, subtitle="经过统计分析,发现二手车的使用里程1万公里以下,其中0-2千公里的车辆占比46%,对于想要买来用来代步的买家可以考虑二手的市场"
)
# .render("bar_rotate_xaxis_label.html")
)
# make_snapshot(snapshot, c.render(), "里程图表.png")
return c
# pass
#价格图表
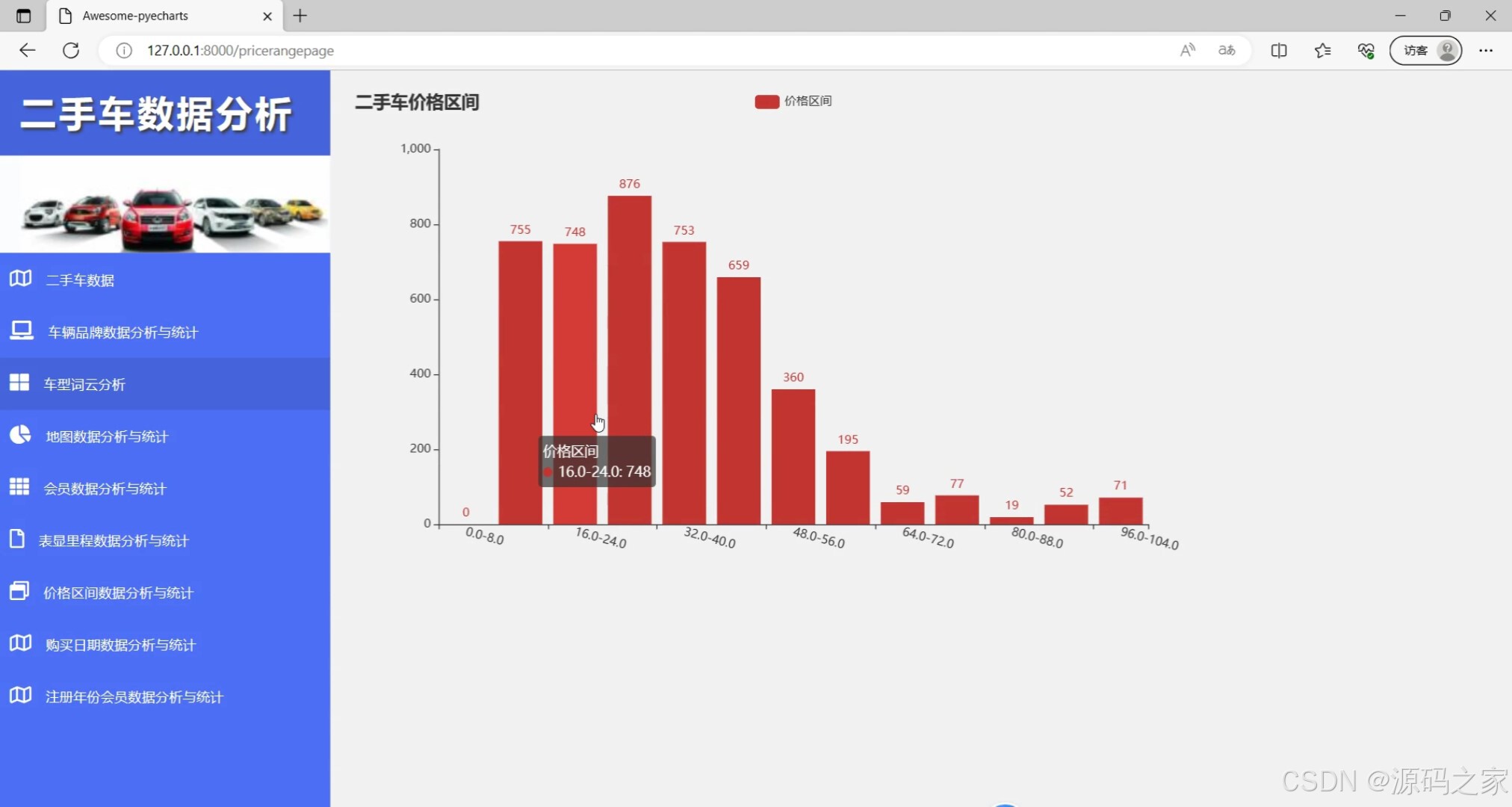
def getjiage(data):
c = (
Bar()
.add_xaxis(
data['fw']
)
.add_yaxis("价格区间", data['count'])
# .add_yaxis("商家B", [20, 10, 40, 30, 40, 50])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="二手车价格区间"),#, subtitle="经过统计分析,发现价格在0-48万的价格的二手车居多,因此考虑低端和中端车的买家可以关注二手车市场"
)
# .render("bar_rotate_xaxis_label.html")
)
# make_snapshot(snapshot, c.render(), "价格图表.png")
return c
# getmemberpage(None)
def getshuangzhu(data):
# print(data.columns)
datasplit=data.信息.str.split('/').apply(lambda x:pd.Series(x))
# print(type(datasplit))
datasplit.columns=['表显里程','上牌时间','车辆所在地','会员']
datasplit=datasplit.会员.str.split('年')
data=[]
for i in datasplit:
try:
if type(i) is list and len(i)>1:
data.append(i)
except BaseException as e:
print(e)
print(i)
data=pd.DataFrame(data)
data.columns=['年','类型']
print(data)
data=data.groupby(['类型','年'])
xaxis={}
会员=[]
钻石会员=[]
黄金会员=[]
黑金会员=[]
print(f'ffdaf:{type(data)}')
for i in data:
print(i[0])
xaxis[f'{i[0][1]}年']=0
print(f'年:{i[0][1]} 会员类型:{i[0][0]} 个数:{len(i[1])}')
htype=i[0][0]
index=int(i[0][1])-1
year=int(i[0][1])
# index=year
if htype=='会员':
会员.extend([0 for i in range(year)])
print(会员)
print(index)
# 会员.append(len(i[1]))
会员[index]=len(i[1])
print('添加会员')
if htype=='钻石会员':
钻石会员.extend([0 for i in range(year)])
# 钻石会员.append(len(i[1]))
print(钻石会员)
钻石会员[index]=len(i[1])
print('添加钻石会员')
if htype=='黄金会员':
黄金会员.extend([0 for i in range(year)])
# 黄金会员.append(len(i[1]))
# 黄金会员.append(len(i[1]))
黄金会员[index]=len(i[1])
print('添加黄金会员')
if htype=='黑金会员':
黑金会员.extend([0 for i in range(year)])
# 黑金会员.append(len(i[1]))
# 黑金会员.append(len(i[1]))
黑金会员[index]=len(i[1])
print('添加黑金会员')
c = (
Bar()
.add_xaxis(list(xaxis.keys()))
.add_yaxis("会员", 会员)
.add_yaxis("钻石会员",钻石会员)
.add_yaxis("黄金会员", 黄金会员)
.add_yaxis("黑金会员", 黑金会员)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="会员注册年份与等级"),#, subtitle="经过统计分析,注册年份与会员等级的的关系不大,注册一年62%用户可以成为黄金会员,即使使用\n多年的用户成为高级别会员也很少。因此可以改变会员等级评估形式,吸引用户提高用户粘度"
)
# .render("bar_rotate_xaxis_label.html")
)
# make_snapshot(snapshot, c.render(), "价格图表.png")
return c
def getmap(data):
fileName='data.csv'
data=pd.read_csv(fileName)
# print(data.columns)
datasplit=data.信息.str.split('/').apply(lambda x:pd.Series(x))
# print(type(datasplit))
datasplit.columns=['表显里程','上牌时间','车辆所在地','会员']
print(datasplit.columns)
mapdata=datasplit.groupby('车辆所在地').车辆所在地.count().to_dict()
print(mapdata)
data=[]
for key,value in mapdata.items():
data.append([
# key.replace('市','').replace('省',''),value
key,value
])
from pyecharts.faker import Faker
# data=[list(z) for z in zip(Faker.provinces, Faker.values())]
c = (
Map()
.add("二手车数量",data , "china")
.set_global_opts(title_opts=opts.TitleOpts(title="全国各地车辆数据"))#, subtitle="经过统计分析,发现沿海和川渝地区的二手车市场比较庞大,因此可以在这两个地区的朋友可以考虑二手车,同时侧面反映出地区的经济情况"
# .render("map_base.html")
)
print(data)
# make_snapshot(snapshot, c.render(), "地图.png")
return c
def getdategrouby(data):
print(f"data['month']:{data['month']}")
c = (
Bar()
.add_xaxis(
data['month']
)
.add_yaxis("购买数量", data['count'])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="车辆购买日期"),#, subtitle="经过统计分析,发现1、3、9月份的车辆购买月份居多,侧面反映出这几个月份为最佳购买汽车时间"
)
)
# make_snapshot(snapshot, c.render(), "车辆购买日期图表.png")
return c
5、源码获取方式
biyesheji0005 或 biyesheji0001 绿泡泡
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)