别再以为索引=检索了!做好RAG必须跨越的认知分水岭
索引不是“把文档直接存进去”,而是“为检索这件事专门设计出来的”。在RAG里,索引阶段多走一步,检索效果往往就能前进一大步。如果你还停留在“原文=索引”的定式思维,不妨从这四种进阶玩法里挑一个最贴近你业务痛点的开始试:先让索引变聪明,再让生成变靠谱。只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!在当前这个人工智能高速发展的时代,AI大模型
做RAG(检索增强生成)的人,大多都经历过一个阶段:把文档丢进来,分块、嵌入、进向量库,然后就开始期待“只要检索到相关块,大模型就能答得很好”。
结果呢?同样一份资料,有时回答惊艳,有时又像没看见一样;你明明“建立了索引”,却总觉得“检索不出东西”。
这里面常见的一个误解是:
“建立索引”=“检索同一份文档”。
但事实是:索引 ≠ 检索。
索引是你为“更容易被找到”而设计出来的结构;检索只是用查询去触发这个结构,把最有价值的信息拉出来。
更关键的一点在于:索引里存的内容,和最终喂给大模型的内容,可以不是同一份东西。
你完全可以用“更适合匹配”的表示去建索引,然后在召回之后再把“更完整的原文上下文”送进大模型。
这也是RAG从“能跑”到“能用”、再到“好用”的分水岭:索引要开始变聪明。
一、索引为何需要“智能化”?
最原始的分块检索,本质上是在赌两件事:
1)你的切块刚好切在合适的位置
2)用户的提问刚好和块里的语义表达方式匹配
现实往往不这么配合,于是就会遇到三类典型问题:
- 文本噪声:块里夹杂了大量无关信息(背景、套话、例子、冗余描述),相似度看起来高,但真正答案只占一小段。
- 信息割裂:块切得太碎,关键上下文散落在多个块里,召回一个不够用,召回多个又容易超上下文或引入干扰。
- 语义匹配偏差:用户问法和原文表述差异很大,比如用户问“怎么申请补贴”,原文写“补助发放流程”,向量相似度未必能稳稳对上。
智能化索引想解决的核心目标只有一个:
在“召回率”与“上下文完整性”之间找到更好的平衡,让RAG整体效果更稳、更准、更可控。
二、四大智能索引方法详解
下面这四种方法,可以理解为从“直接存原文”到“设计索引结构”的四个台阶。它们并不互斥,很多场景甚至是组合拳更好用。
1)分块索引:经典,但不够精细
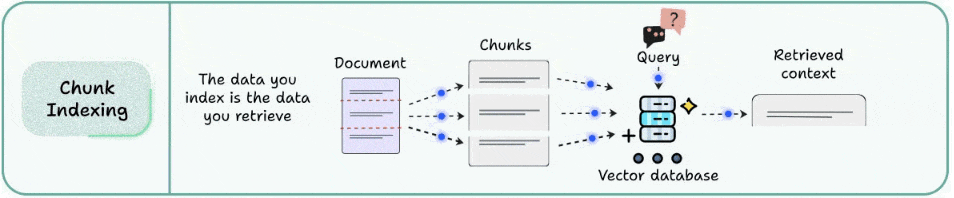
这是大家最熟的做法:
文档 → 分块 → 嵌入 → 向量存储
适用场景很明确:
结构清晰、内容连贯的通用文档,比如产品介绍、制度说明、操作手册的章节型内容。
它的问题也很典型:
- 块太大:噪声多,检索命中但答案不集中,模型容易“读错重点”。
- 块太小:信息碎片化,模型缺上下文容易答不完整,甚至出现看似合理但实际偏题的补全。
所以,分块索引是起点,但很难成为终点。只要你的内容稍微复杂一点,就会开始“靠调参续命”:调chunk大小、调overlap、调topK……效果仍然不稳定。
2)子块索引:细粒度召回,完整上下文返回
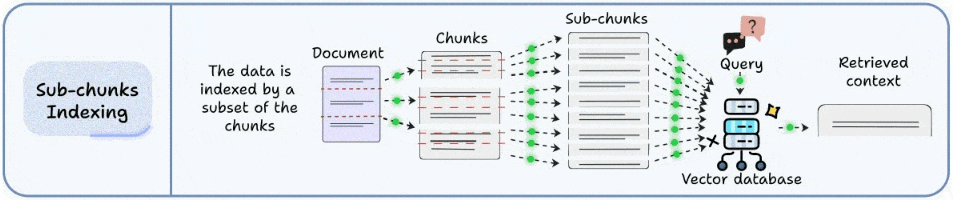
子块索引是对“切块两难”的一个很实用的解法:
让索引用更细的颗粒度去匹配,让返回给模型的上下文保持更完整。
做法可以概括为:
原始块(父块) → 进一步拆分成子块 → 对子块建索引 → 召回子块时返回父块
你可以把它想象成:
“用放大镜找位置,用整页纸给模型看。”
优势非常直接:
- 匹配更准:子块更聚焦,语义向量更干净。
- 上下文更完整:返回父块时,模型能看到必要的前因后果,不容易断章取义。
适用场景:
同一段落里包含多个主题、多个条件、多个例外情况的长文档(比如政策条款、流程说明、FAQ合集、技术设计文档的长段落)。
需要注意的点:
你要维护父子块映射关系;并且父块也别无限大,否则又把噪声带回来了。一般建议父块是“可读的一屏上下文”,子块是“可精准命中的句群/小段”。
3)查询索引:用“问题”代替“原文”匹配
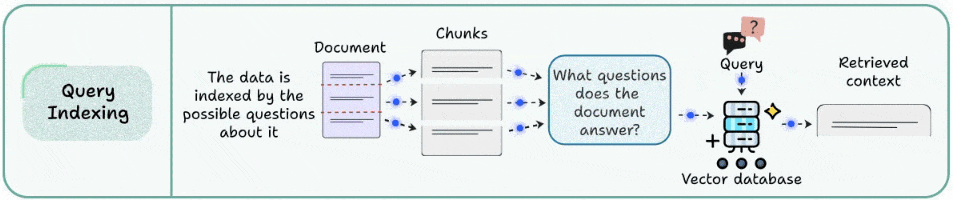
很多检索不准,不是内容没写,而是写法不一样。用户不会按文档语言去提问,他们更像在“说人话”。
查询索引的思路是:
别让用户的提问去硬碰原文,让原文先变成“可能被问到的问题”。
做法是:
为每个文本块生成若干“假设性问题” → 对这些问题建索引 → 用户查询匹配到问题 → 返回对应原文块
核心逻辑:
把检索空间从“文档表达”转成“用户提问表达”。这一步往往能显著改善问答类系统的召回。
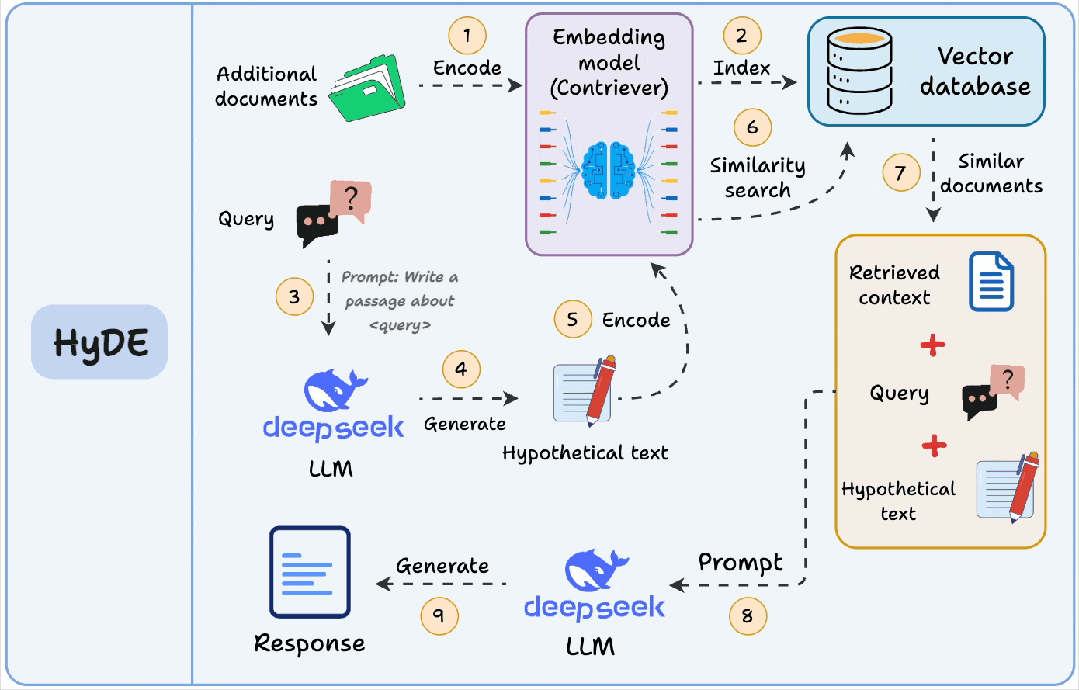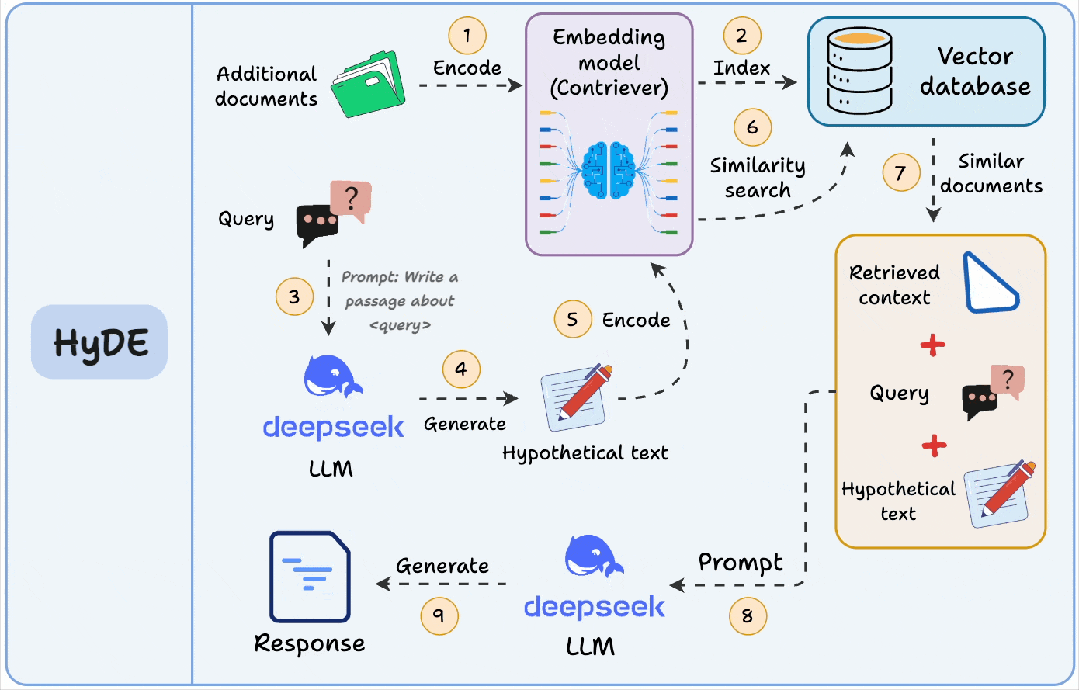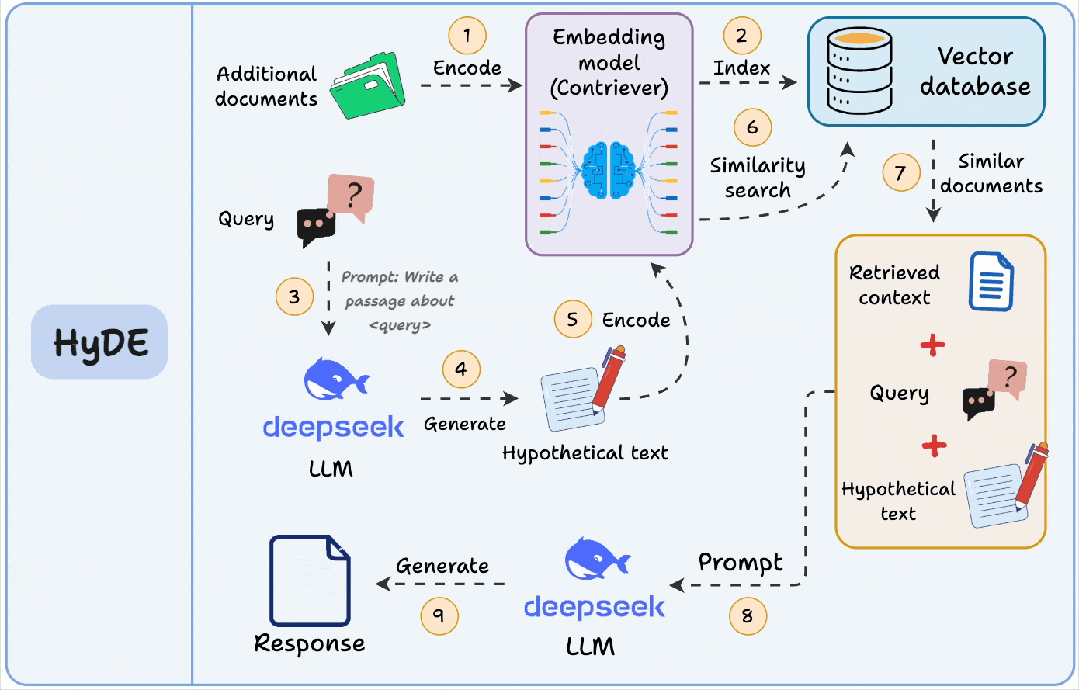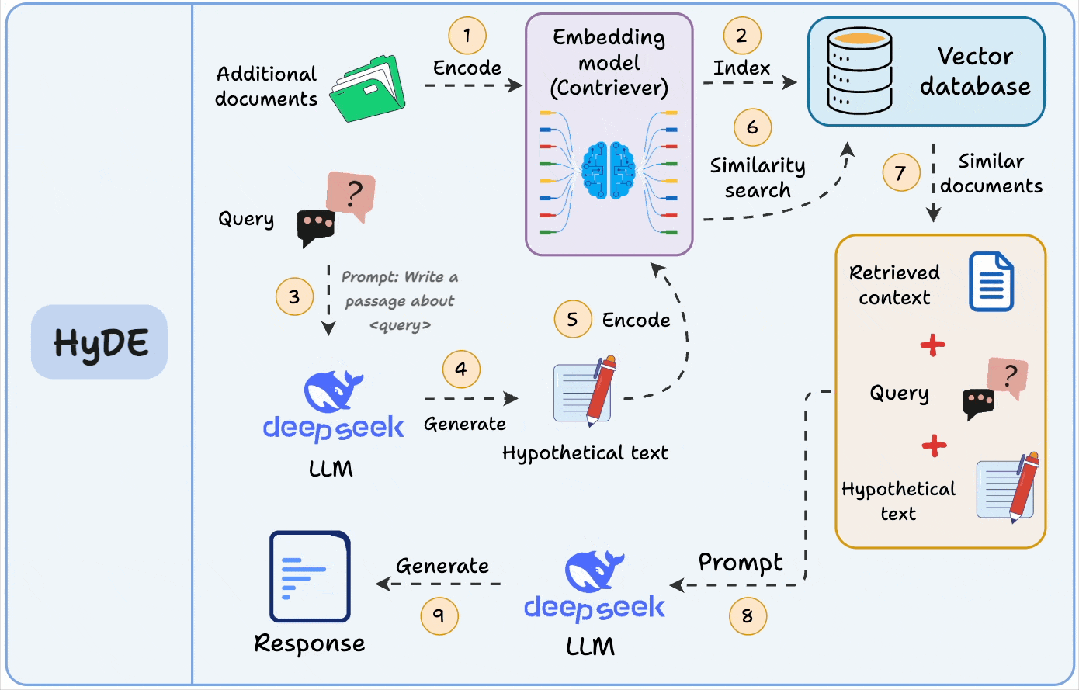
它和HyDE(Hypothetical Document Embeddings)的区别也值得一提:
- 查询索引:你为每个块提前生成“问题”,索引存的是问题向量,查询时找最像的问题。
- HyDE:查询时先生成“假设答案/假设文档”,再用这个生成内容去向量检索原文,更像是在查询侧做增强。
两者都在解决“问法和写法不一致”的问题,只是一个是离线建索引,一个是在线增强查询。实际落地时,查询索引更适合稳定、可控的知识库(尤其客服/内部FAQ),HyDE更适合开放问题、查询多变的场景,但要注意成本与时延。
最佳场景:
问答系统、客服知识库、内部制度查询、IT支持台——凡是用户问题高度口语化、文档语言偏正式的地方,都值得试。
4)摘要索引:语义浓缩,增强表征
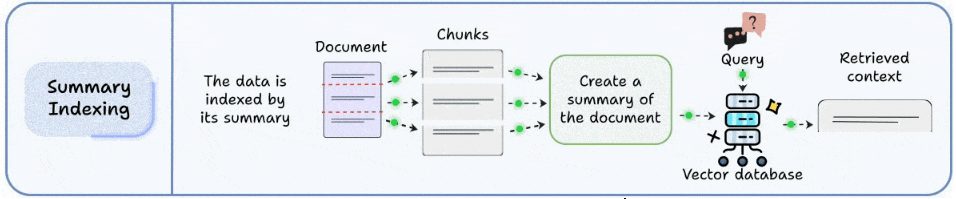
还有一种“检索老大难”是:内容非常密集或结构化,原文向量不好表示。
典型例子:表格、列表、报表、对照项、研究数据、指标说明……这些东西用原文做embedding,常常会出现“每行都像、又都不像”的尴尬。
摘要索引的做法是:
文本块 → 生成摘要 → 对摘要建索引 → 召回时返回原文
好处在于:
摘要把核心语义浓缩出来,向量表示更稳定、更可检索;而最终给模型的仍然是原文,这样不牺牲细节。
典型用例:
财务/经营报表检索、研究数据检索、结构化内容检索、长列表规则(例如权限清单、价格表、接口字段说明)等。
需要注意:
摘要必须保证语义准确,尤其是数字、条件、限制条款不能“总结丢了”。实践里建议摘要模板固定化(比如“适用范围/关键条件/结论/例外”),并对数字字段做保留策略。
三、方法对比与选择建议
为了方便你快速对号入座,这里给一个简单的选择表:
方法:分块索引
核心思路:原文直接分块建索引
适用场景:通用文档检索
注意事项:谨慎控制块大小与overlap,避免噪声或碎片化
方法:子块索引
核心思路:细粒度索引,粗粒度返回
适用场景:长文本、多主题段落
注意事项:维护父子映射;父块控制“可读”范围
方法:查询索引
核心思路:用“问题”表征原文
适用场景:问答系统、交互式检索、客服知识库
注意事项:依赖生成问题的质量;问题覆盖要足够全面
方法:摘要索引
核心思路:用“摘要”表征原文
适用场景:结构化/密集数据(表格、列表、报表)
注意事项:摘要要保真,特别是数字/条件/例外项
四、实战:怎么从0到1把索引做“聪明”?
如果你现在的RAG还在“分块→向量→topK”,建议别一下子把系统推倒重来。更现实的路径是循序渐进:
第一步:先把分块索引跑稳
把最基础的检索-生成链路跑通,确保评估方式清楚:你要衡量的是最终任务效果(回答准确率、引用正确率、可追溯性、时延、成本),而不是单纯的相似度分数。
第二步:内容一复杂就上子块
你一旦发现“命中不准但其实文档里有”,或者“模型回答总缺关键条件”,子块索引往往是性价比最高的增强手段:更准的召回 + 更完整的上下文,一般立竿见影。
第三步:问答类场景优先试查询索引
客服、制度、流程、IT支持这类问题,非常适合用“问题索引”把检索对齐到用户语言。很多团队做到这里,检索的“体感稳定性”会明显提升。
第四步:遇到表格/列表就考虑摘要索引
结构化内容别硬向量化原文,先做摘要再索引,召回更稳定,模型读原文时也更有抓手。
最后:允许混合索引
现实业务往往内容混杂,一套索引策略吃遍天下很难。常见组合包括:
- 摘要 + 子块:摘要负责“找得准”,子块负责“定位精”,返回再给父块保证上下文。
- 查询索引 + 分块索引双路召回:一条对齐用户问法,一条兜底原文语义,相互补位。
无论怎么玩,唯一的裁判永远是终端任务效果。索引策略不是“越复杂越高级”,而是“越贴合业务越有效”。
五、总结
索引不是“把文档直接存进去”,而是“为检索这件事专门设计出来的”。
在RAG里,索引阶段多走一步,检索效果往往就能前进一大步。
如果你还停留在“原文=索引”的定式思维,不妨从这四种进阶玩法里挑一个最贴近你业务痛点的开始试:
先让索引变聪明,再让生成变靠谱。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】、

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献557条内容
已为社区贡献557条内容

所有评论(0)