RAG 深度实践系列(五):RAGFlow 的部署使用与架构分析
从 RAGFlow 的微服务架构深度解析到 Docker 容器化的快速部署,再到异步任务流转与 Agent 工作流的编排,RAGFlow 为我们提供了一个构建企业级 AI 应用的强大底座。然而,真正的工程挑战往往隐藏在索引优化、多语言适配以及系统监控等细节之中。为了帮助您在 RAG 领域实现从“平台使用者”到“架构设计者”的跨越,AI大学堂精心打造了RAG工程师认证。这份证书将是你系统化掌握 AI
一、 RAGFlow 的核心价值与微服务架构深度解析
在 RAG 深度实践系列的前几篇文章中,我们从原理、架构演进到代码实战,系统地构建了对 RAG 技术的认知。然而,当我们将视角转向企业级应用场景时,手动搭建的 RAG 系统往往难以应对海量的异构数据、高并发的请求以及复杂的 Agent 工作流。
RAGFlow 作为一款领先的开源 RAG 引擎,其核心价值在于提供了一个生产就绪、可扩展、高保真的解决方案。
许多开发者在尝试将 RAG 落地到业务场景时,常会被文档解析的精度、向量数据库的扩展性以及任务队列的稳定性所困扰。为了帮你填补从懂原理到能落地的关键拼图,AI大学堂基于大量的业务实战经验,精心打磨课程,正式推出 RAG工程师认证。这份证书将是你系统化掌握 AI 落地核心能力的绝佳机会,认证现已开启,限时免费,点击文末🔗认证链接开始学习!
1.1、 RAGFlow 的技术基石:DeepDoc 与 Agent 能力
RAGFlow 的强大之处在于其两大核心技术:**深度文档理解(DeepDoc)**和 Agent 能力。DeepDoc 模块超越了传统的文本分割,它能够根据文档的结构(如标题、表格、列表)进行智能切片,甚至通过 OCR 识别图片中的文字,确保了输入 LLM 的上下文是高保真、结构化的。Agent 能力则将原本线性的“检索-生成”流程,进化为一个可定制、可编排的自动化决策与执行体系,支持多轮对话和工具调用。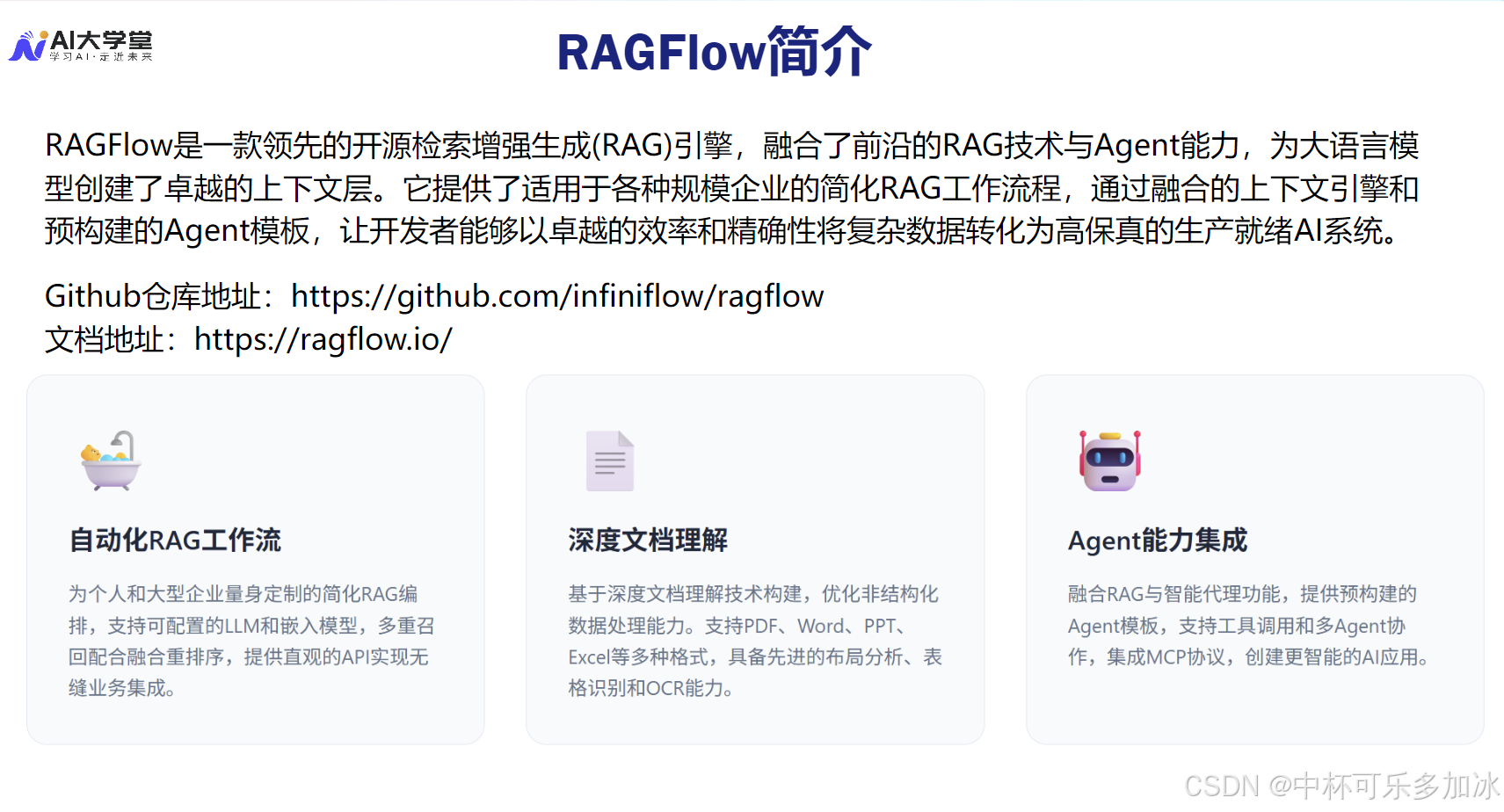
1.2、 微服务架构与组件协同机制的底层逻辑

RAGFlow 采用微服务架构,将复杂的 RAG 流程分解为多个独立的、通过消息队列解耦的组件。理解这些组件的协同机制,是进行部署和调优的基础。RAGFlow 的架构设计体现了对高并发、高可用性的追求,其核心组件包括:
| 组件模块 | 核心功能 | 关键技术栈 | 工程化意义 |
|---|---|---|---|
| API 模块 | 处理 HTTP 请求,系统入口 | Python/FastAPI | 对外提供 RESTful 接口,实现前后端分离,保障系统入口的稳定。 |
| DeepDoc 模块 | 智能文档解析与切片 | Python/Unstructured | 确保输入上下文的高保真和结构化,是 RAG 质量之源。 |
| RAG 模块 | 任务执行与向量化 | Python/LangChain | 消费消息队列任务,执行文件构建、Embedding 和索引写入。 |
| 消息队列 | 异步任务分发与解耦 | Redis | 确保系统在高并发文档上传时,仍能保持高吞吐量和响应速度。 |
| 数据存储 | 向量索引与文件存储 | Elasticsearch/MinIO | 提供高性能的向量检索和安全可靠的文档持久化存储。 |
这种架构设计使得 RAGFlow 能够轻松应对企业级应用中常见的挑战,例如在处理大量文档上传时,通过 Redis 消息队列将任务异步化,避免了 API 模块的阻塞,从而保障了用户界面的响应速度。
二、 环境准备与部署
RAGFlow 的部署不仅仅是执行几条 Docker 命令,更重要的是对生产环境下的资源规划、性能调优和高可用性保障的深度考量。
2.1、 生产环境下的资源规划与内核参数调优
RAGFlow 在处理大规模数据和 LLM 推理时对计算资源有极高要求。
在进行部署前,必须对核心组件的资源消耗进行精细规划:
Elasticsearch 的内存与内核调优:作为向量和全文检索的核心,Elasticsearch 对内存的需求极高。在生产环境中,必须配置 JVM 堆大小(通常设置为物理内存的 50% 且不超过 32GB),并启用 内存锁定(Memory Lock) 以防止操作系统将堆内存交换到磁盘,从而保证检索的低延迟。此外,Linux 内核参数 vm.max_map_count 必须调整到足够大(例如 262144),以避免 Elasticsearch 在创建大量索引时因内存映射文件数不足而崩溃。
GPU 加速配置与 Embedding 性能:Embedding 模型的向量化过程是计算密集型任务。如果采用本地部署的 Embedding 模型,强烈建议配置 NVIDIA Container Toolkit 来运行 RAGFlow 容器,以便充分利用 GPU 的并行计算能力。在 Docker Compose 文件中,需要为 RAG 模块指定 runtime: nvidia,并确保主机上已正确安装驱动和 Toolkit。这能将万级文档的索引时间从数小时缩短到数分钟。
并发与吞吐量规划:RAGFlow 的性能瓶颈通常出现在 task_executor 模块。通过调整 Docker Compose 文件中 task_executor 服务的副本数量,可以实现水平扩展,以应对高并发的文档上传和解析任务。然而,过高的并发数可能导致 Redis 队列拥塞或 Elasticsearch 写入瓶颈,因此需要通过实际压测来确定最佳的并发配置。
2.2、 Docker 容器化部署的实践步骤与高可用性保障
Docker 是官方推荐且最便捷的部署方式,它通过容器化技术,将 RAGFlow 的各个微服务运行在独立的容器中,彻底解决了环境依赖和版本冲突问题。
部署实践步骤:
- 获取源代码与环境准备:首先从 GitHub 仓库克隆 RAGFlow 的最新代码。在 Linux 环境下,确保 Docker 和 Docker Compose 版本符合要求。
git clone https://github.com/infiniflow/ragflow.git cd ragflow/docker - 内核参数配置:在启动服务前,必须调整主机系统的内核参数,以满足 Elasticsearch 的要求。
# 临时修改内核参数 sudo sysctl -w vm.max_map_count=262144 # 永久修改需编辑 /etc/sysctl.conf - 配置与启动:根据实际需求修改
.env文件,特别是端口映射、存储路径和 GPU 配置。然后使用docker compose命令启动服务。docker compose up -d
高可用性保障:在生产环境中,单点故障是不可接受的。RAGFlow 的微服务架构天然支持高可用性部署:
- Elasticsearch 集群:将 Elasticsearch 部署为多节点集群,通过分片和副本机制实现数据冗余和故障转移。
- Redis Sentinel/Cluster:将 Redis 部署为 Sentinel 或 Cluster 模式,确保消息队列服务的持续可用性。
- API 负载均衡:在 API 模块前部署 Nginx 或 Traefik 等负载均衡器,将请求分发到多个 API 实例,实现无状态服务的水平扩展。
三、 RAGFlow 核心机制与工作流深度实践
部署完成后,RAGFlow 的核心价值体现在其对文档处理和任务流转的精细化控制上。
3.1、 知识库构建与异步任务流转的全生命周期深度解析
在 RAGFlow 中,一个文档从上传到最终可检索,经历了一个严谨的异步任务流转全生命周期:
- 文档存储与任务分发:用户上传文档后,文件首先被存储到 MinIO 对象存储中。随后,RAGFlow 会将解析任务拆分为多个异步任务,并推送到 Redis 消息队列中。Redis 的高性能确保了系统在高并发文档上传时,仍能保持极高的响应速度。
- 任务消费与执行的底层逻辑:后台的
task_executor模块是整个流程的执行者。它持续从 Redis 队列中获取任务,并调用 RAG 模块中的核心函数。- 工程细节:
task_executor模块通过一个循环机制不断监听 Redis 队列。一旦获取任务,它会根据任务类型调用相应的处理函数,例如build()函数负责调用 DeepDoc 进行解析,embedding()函数负责向量化。这种异步机制是实现高吞吐量的关键,它将耗时的 I/O 操作(文件读取、网络传输)和计算密集型操作(向量化)从主 API 线程中剥离出来。
- 工程细节:
- 并发调优与 OOM 避坑:在处理超大文档时,
task_executor可能会因为内存不足而发生 OOM(内存溢出)。解决策略包括:通过 Docker 限制容器内存,以及在代码层面优化 DeepDoc 的内存使用,例如采用流式处理或分批次处理超大文件。
3.2、 DeepDoc 模块:智能解析策略与视觉理解原理
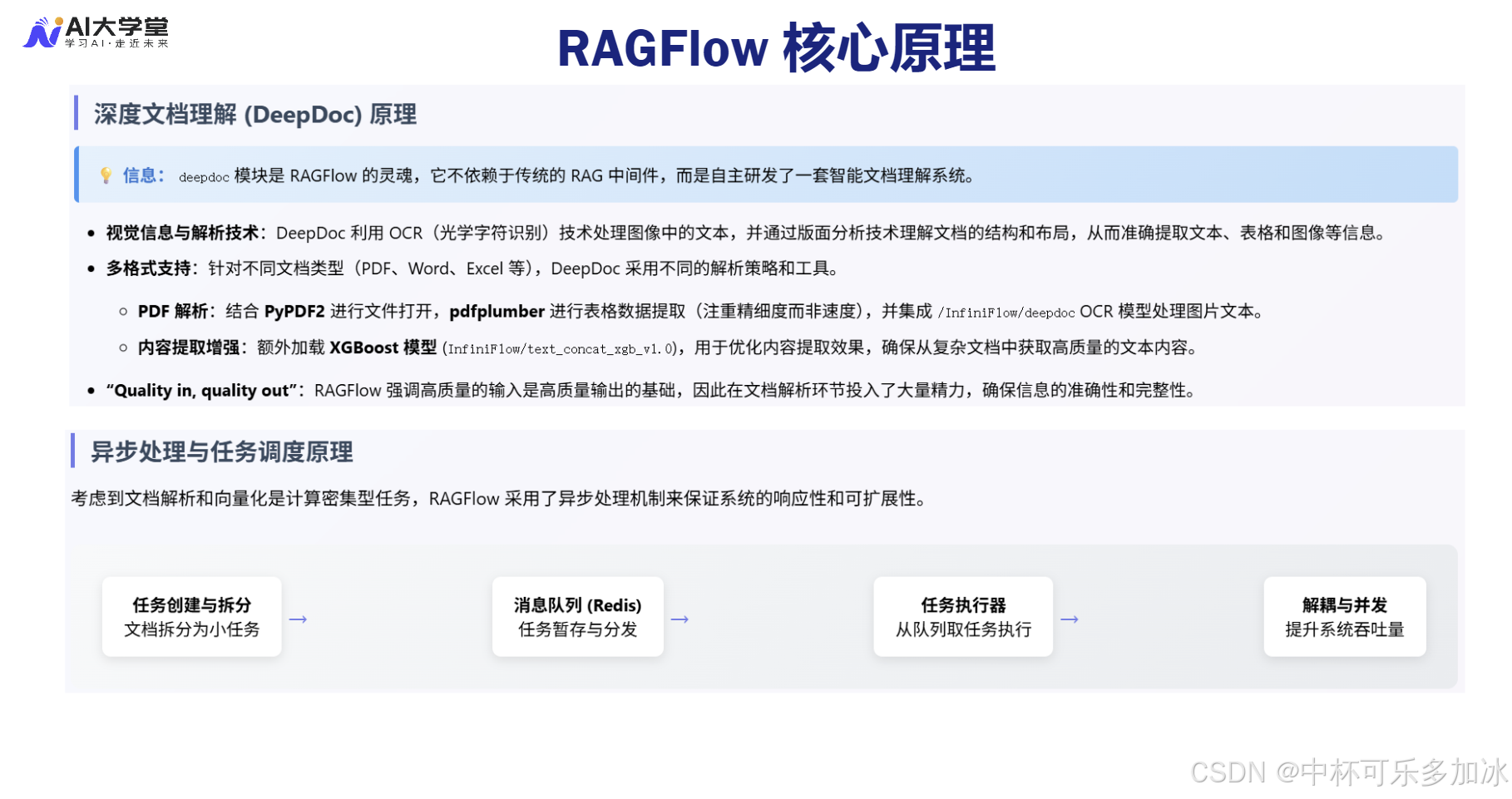
DeepDoc 模块是 RAGFlow 确保高保真上下文的关键。它超越了简单的文本分割,通过 parser_id 来选择不同的解析策略,以适应不同类型的文档结构:
视觉理解与版面分析(Layout Analysis):DeepDoc 的强大之处在于其集成了视觉理解模型,能够进行版面分析。对于复杂的 PDF 文档,它能够识别出文档中的逻辑结构,例如区分标题、正文、页眉页脚、表格和图片。这种基于视觉的结构化解析,彻底解决了传统解析器无法处理的“语义割裂”问题。
多策略解析器的底层原理:
paper解析器:针对学术论文或技术报告。它利用版面分析结果,确保切片时不会割裂语义单元,例如将标题和正文分开。它能识别出图注、表注等关键元数据,并将其与相邻的正文块进行关联,从而提升检索的上下文质量。table解析器:针对包含复杂表格的文档。它会利用 OCR 或结构化解析技术,将表格内容提取并转换为 Markdown 或 JSON 格式。这种转换确保了 LLM 能够以结构化的方式理解表格数据,避免了传统文本解析中表格信息丢失或错乱的问题。
3.3、 向量化与 Elasticsearch 索引调优的进阶实践
文档切片和向量化是 RAG 系统性能的关键。RAGFlow 利用 Elasticsearch 强大的索引能力,为大规模知识库提供了高性能的检索支持。
索引调优的进阶实践:
- HNSW 算法与内存管理:Elasticsearch 默认支持 HNSW(Hierarchical Navigable Small World)算法进行近似最近邻(ANN)搜索。HNSW 提供了极高的检索速度,但代价是较高的内存消耗。在生产环境中,需要精确计算向量索引所需的内存,并为 Elasticsearch 预留足够的堆空间。
- 混合检索(Hybrid Search)的工程实现:RAGFlow 允许开发者结合 Elasticsearch 的传统 BM25 全文检索能力和向量检索能力,实现混合检索。在工程上,通常采用 RRF(Reciprocal Rank Fusion) 算法来融合两种检索结果的排序,从而在保证召回率的同时,提升精确度。
- 索引生命周期管理(ILM):对于不断增长的知识库,RAGFlow 建议利用 Elasticsearch 的 ILM 策略,对旧的、不常访问的索引进行自动归档或删除,以优化存储成本和检索性能。
四、 总结与展望
从 RAGFlow 的微服务架构深度解析到 Docker 容器化的快速部署,再到异步任务流转与 Agent 工作流的编排,RAGFlow 为我们提供了一个构建企业级 AI 应用的强大底座。然而,真正的工程挑战往往隐藏在索引优化、多语言适配以及系统监控等细节之中。
为了帮助您在 RAG 领域实现从“平台使用者”到“架构设计者”的跨越,AI大学堂精心打造了 RAG工程师认证。
这份证书将是你系统化掌握 AI 落地核心能力的绝佳机会,认证现已开启,限时免费,点击下方链接,开启您的 RAG 进阶学习之旅:
🔗 认证链接:
https://www.aidaxue.com/course/1192?video_id=5219&ch=ai_daxue_csdn

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)