没显卡都能搞,Langchain-Chatchat 快速基于LLM构建本地智能知识库!
今天我们分享一个开源项目,帮助你快速构建基于Langchain 和LLM 的本地知识库问答,在GitHub已经获得27K star,它就是:Langchain-Chatchat
觉得搞一个AI的智能问答知识库很难吗?那是你没有找对方向和工具,
今天我们分享一个开源项目,帮助你快速构建基于Langchain 和LLM 的本地知识库问答,在GitHub已经获得27K star,它就是:Langchain-Chatchat

👉CSDN大礼包🎁:Langchain-Chatchat 已下载并打包,免费分享**(安全链接,放心点击)**👈

Langchain-Chatchat 是什么
Langchain-Chatchat基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
本项目利用 langchain 思想实现的基于本地知识库的问答应用,目前langchain可以说是开发LLM应用的首选框架,而本项目的目标就是建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。

依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
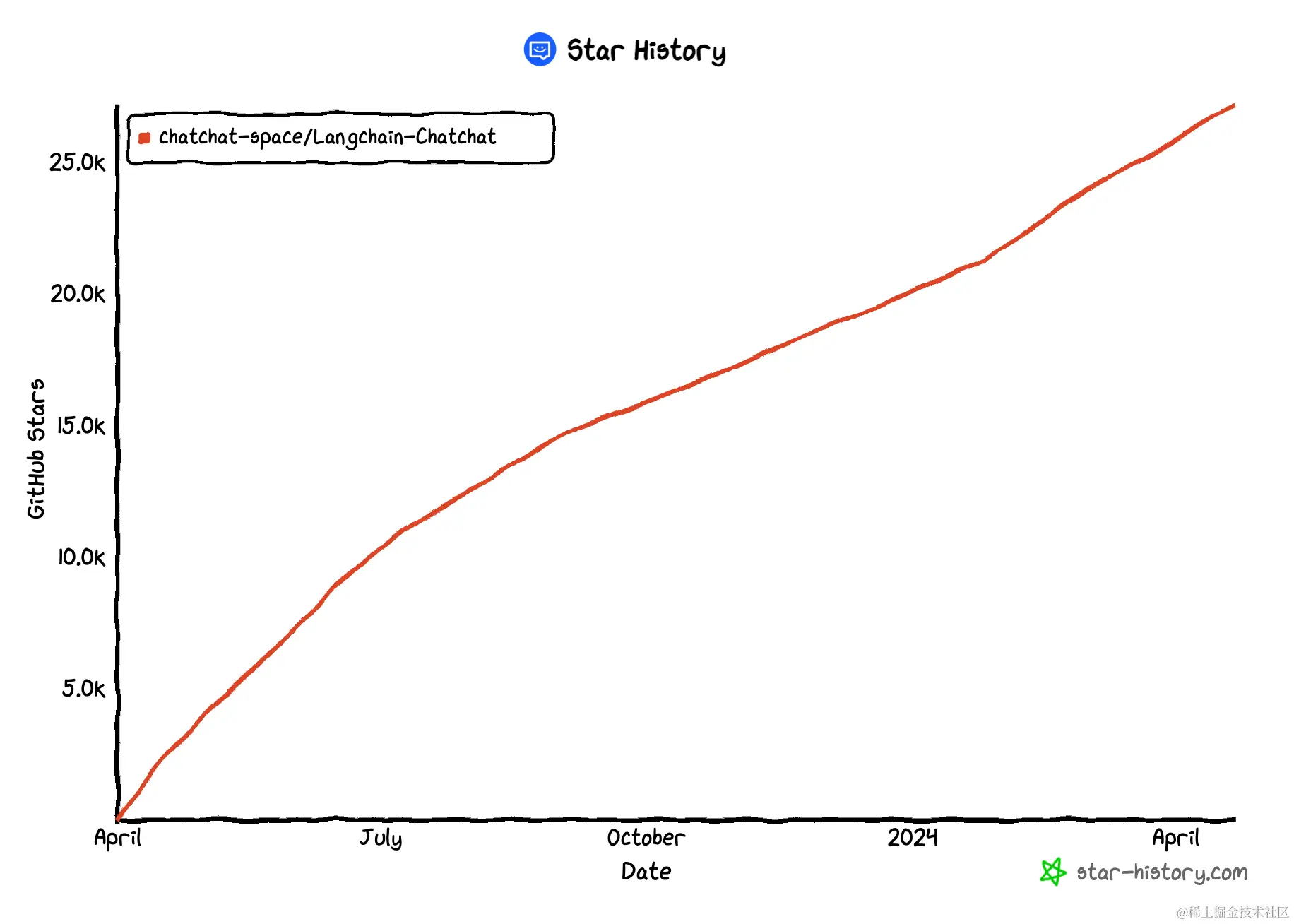
实现原理
本项目全流程使用开源模型来实现本地知识库问答应用,最新版本中通过使用 FastChat 接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
可以通过下面的图来直观看到的整个流程的执行过程,非常值得参考学习。
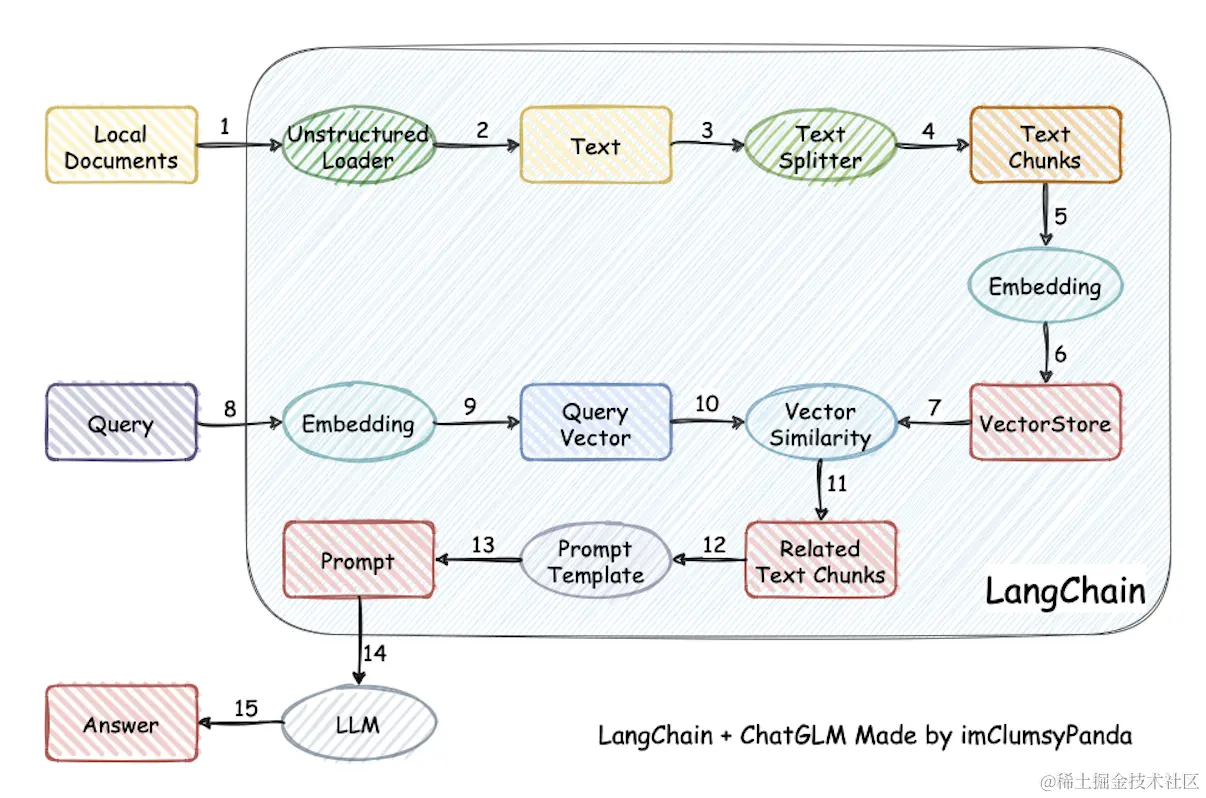
再从从文档处理角度来看,实现流程如下:
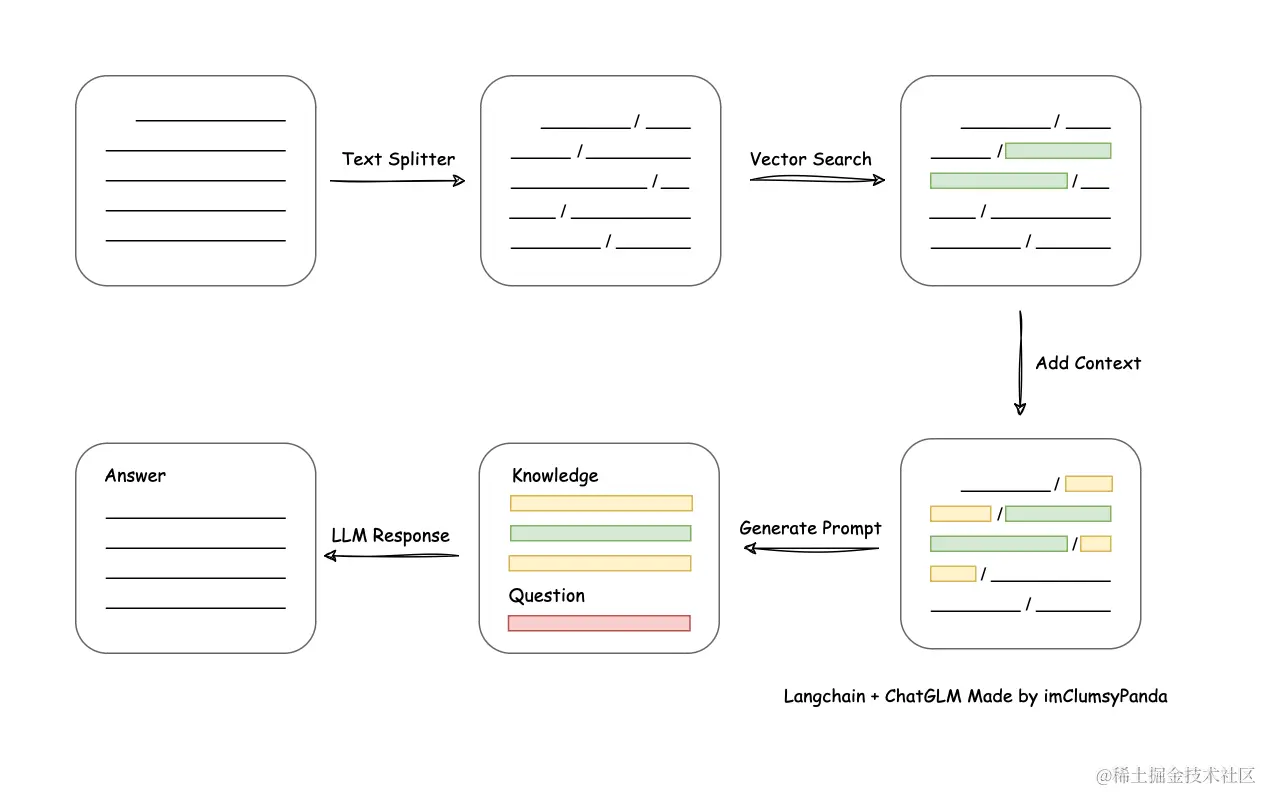
这里需要注意,本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
部署要求
软件要求:
操作系统
- Linux Ubuntu 22.04.5 kernel version 6.7
其他系统可能出现系统兼容性问题。
最低要求
该要求仅针对标准模式,轻量模式使用在线模型,不需要安装torch等库,也不需要显卡即可运行。
- Python 版本: >= 3.8(很不稳定), < 3.12
- CUDA 版本: >= 12.1
推荐要求
开发者在以下环境下进行代码调试,在该环境下能够避免最多环境问题。
- Python 版本 == 3.11.7
- CUDA 版本: == 12.1
硬件要求:
如果想要顺利在GPU运行本地模型的 FP16 版本,你至少需要以下的硬件配置,来保证在我们框架下能够实现 稳定连续对话
- ChatGLM3-6B & LLaMA-7B-Chat 等 7B模型 最低显存要求: 14GB 推荐显卡: RTX 4080
- Qwen-14B-Chat 等 14B模型 最低显存要求: 30GB 推荐显卡: V100
- Yi-34B-Chat 等 34B模型 最低显存要求: 69GB 推荐显卡: A100
- Qwen-72B-Chat 等 72B模型 最低显存要求: 145GB 推荐显卡:多卡 A100 以上
实际部署配置示例
处理器: Intel® Core™ i9 processor 14900K
内存: 256 GB DDR5
显卡组: NVIDIA RTX4090 X 1 / NVIDIA RTXA6000 X 1
硬盘: 1 TB
操作系统: Ubuntu 22.04 LTS / Arch Linux, Linux Kernel 6.6.7
显卡驱动版本: 545.29.06
Cuda版本: 12.3 Update 1
Python版本: 3.11.7
部署 Langchain-Chatchat
Docker 部署
开发组为开发者们提供了一键部署的 docker 镜像文件懒人包。开发者们可以在 AutoDL 平台和 Docker 平台一键部署。
docker run -d --gpus all -p 80:8501 isafetech/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 ccr.ccs.tencentyun.com/chatchat/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.10
- 该版本镜像大小 50.1GB,使用 v0.2.10,以 nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 为基础镜像
- 该版本为正常版本,非轻量化版本
- 该版本内置并默认启用一个 Embedding 模型:bge-large-zh-v1.5,内置并默认启用 ChatGLM3-6B
- 该版本目标为方便一键部署使用,请确保您已经在 Linux 发行版上安装了 NVIDIA 驱动程序
- 请注意,您不需要在主机系统上安装 CUDA 工具包,但需要安装 NVIDIA Driver 以及 NVIDIA Container Toolkit,请参考安装指南
本地部署方案
- 安装python环境
# 首先,确信你的机器安装了 Python 3.8 - 3.10 版本
$ python --version
Python 3.8.13
$ conda create -p /your_path/env_name python=3.8
$ source activate /your_path/env_name
$ conda create -n env_name python=3.8
$ conda activate env_name # Activate the environment
# 更新py库
$ pip3 install --upgrade pip
- 安装项目相关的依赖
# 拉取仓库
$ git clone --recursive <https://github.com/chatchat-space/Langchain-Chatchat.git>
# 进入目录
$ cd Langchain-Chatchat
# 安装全部依赖
$ pip install -r requirements.txt
# 默认依赖包括基本运行环境(FAISS向量库)。以下是可选依赖:
- 如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果要开启 OCR GPU 加速,请安装 rapidocr_paddle[gpu]
- 如果要使用在线 API 模型,请安装对用的 SDK
- 模型下,如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
$ git lfs install
$ git clone <https://huggingface.co/THUDM/chatglm2-6b>
$ git clone <https://huggingface.co/moka-ai/m3e-base>
- 初始化知识库,当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库
#如果您已经有创建过知识库
$ python init_database.py --create-tables
#如果您是第一次运行本项目
$ python init_database.py --recreate-vs
- 一键启动,一键启动脚本 startup.py, 一键启动所有 Fastchat 服务、API 服务、WebUI 服务
$ python startup.py -a
启动界面
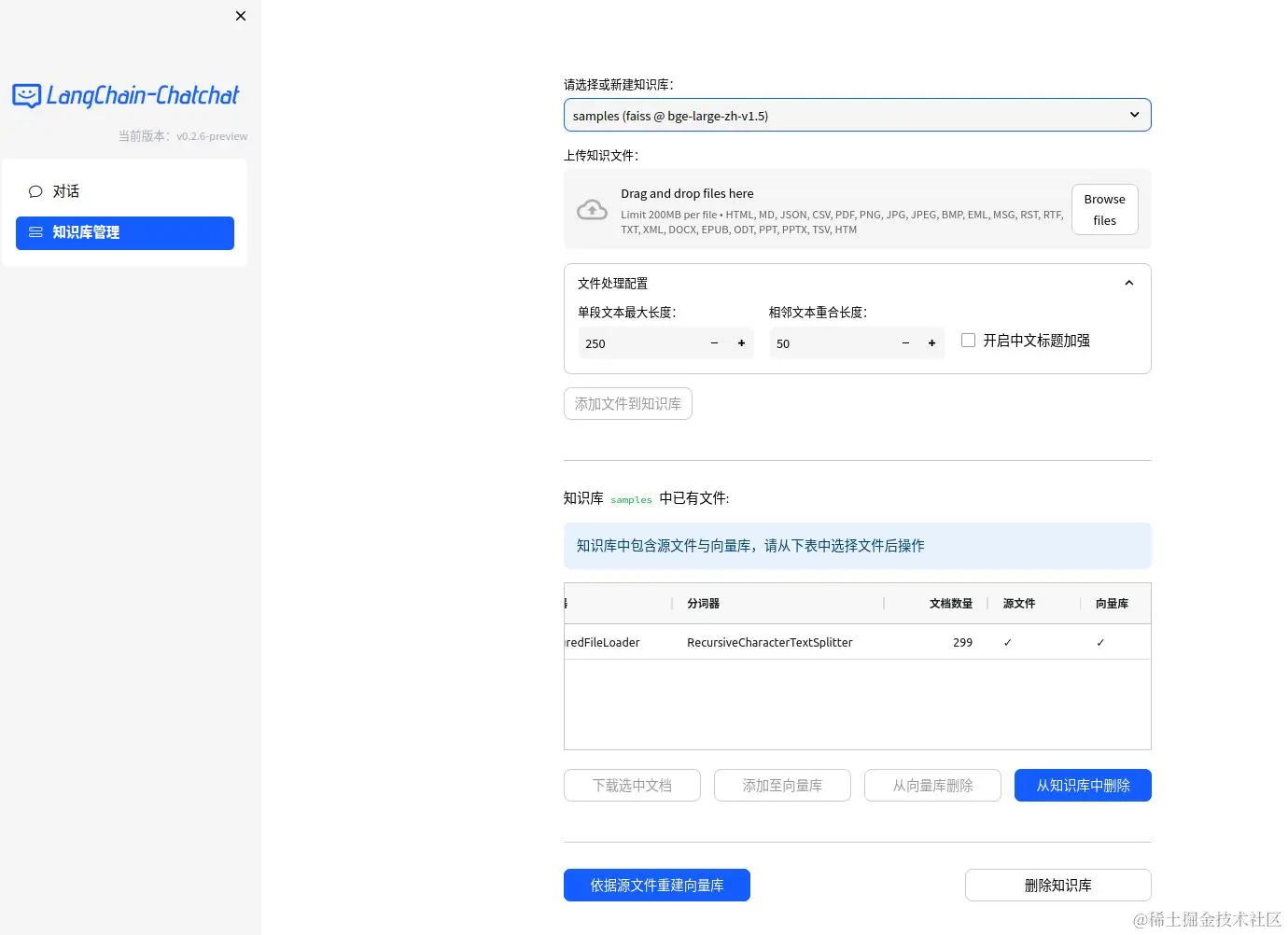
正常启动后,会有两种使用界面,一种是webui,如下:
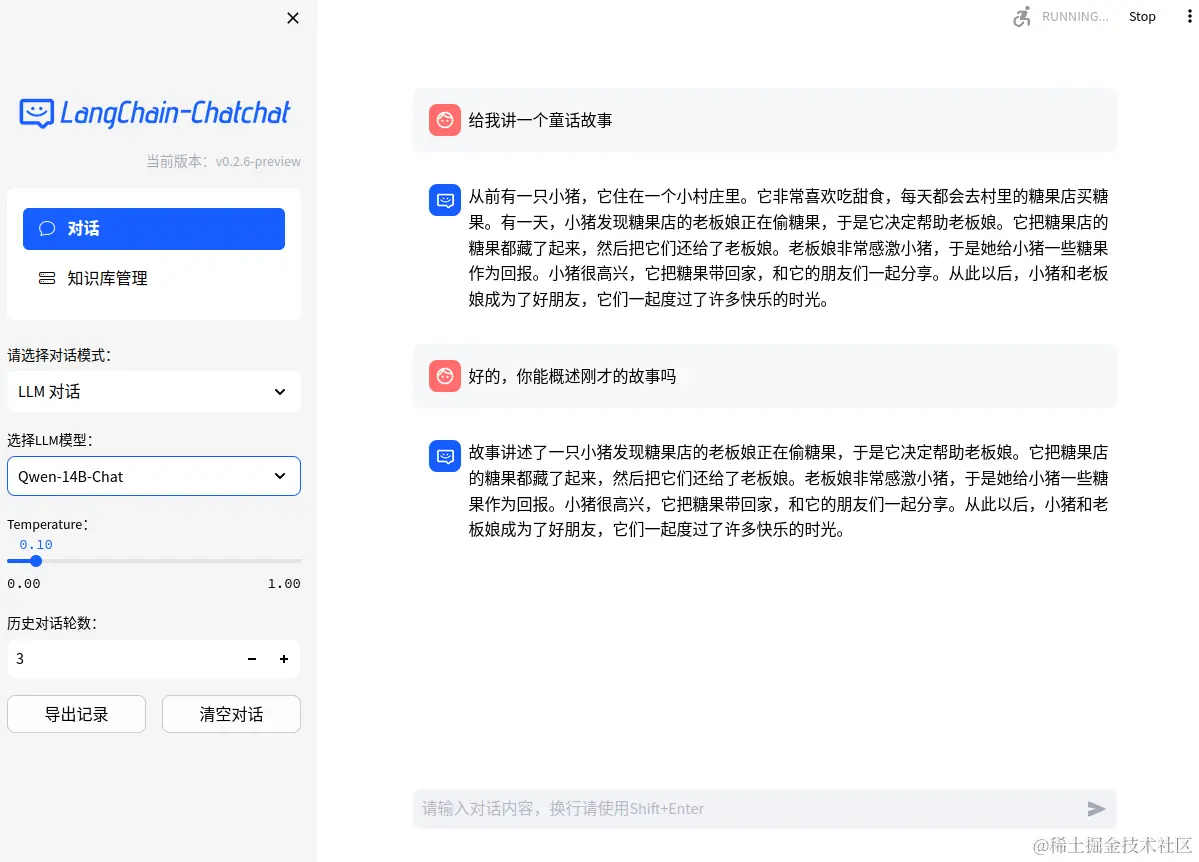
Web UI 知识库管理页面
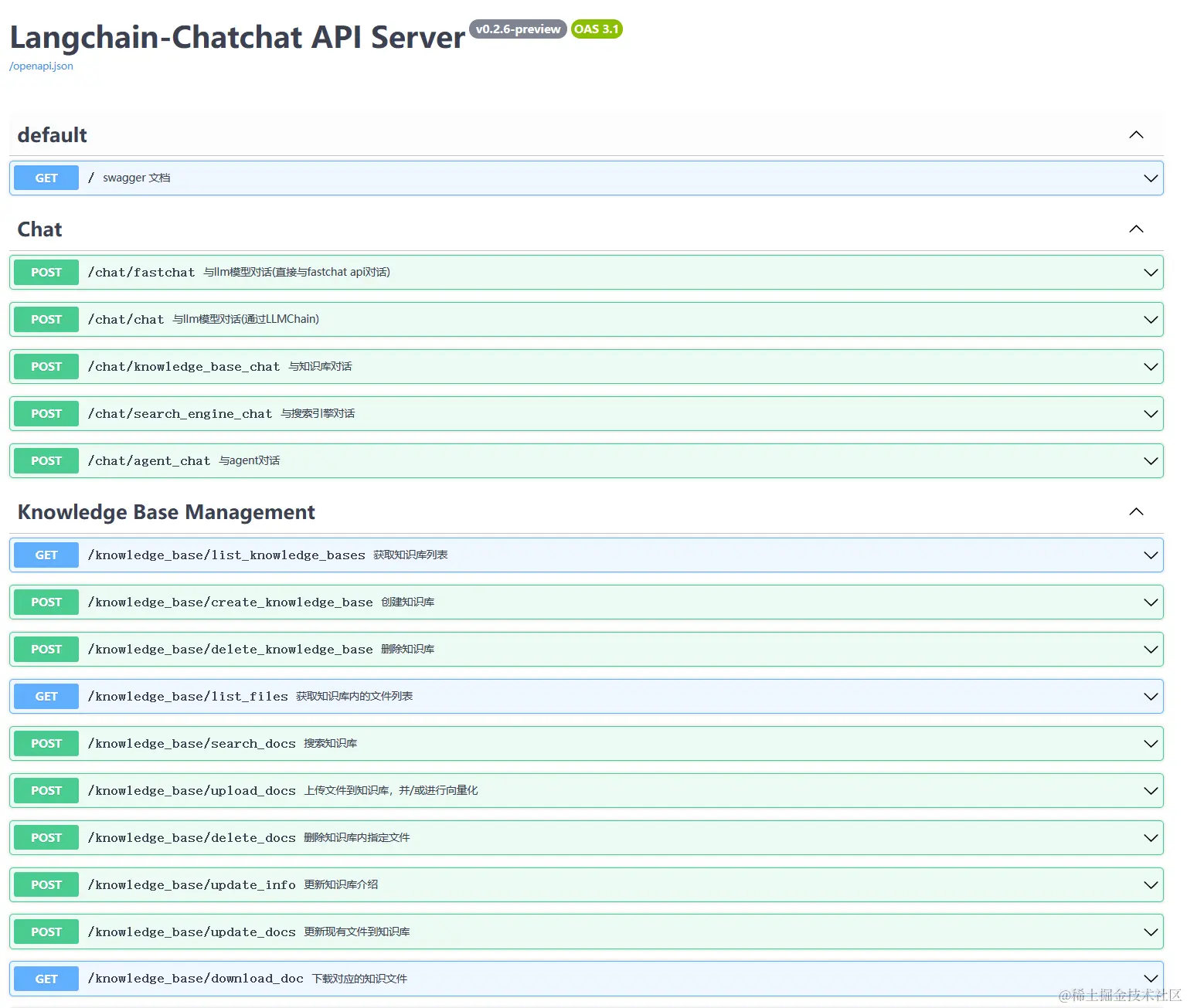
另一种使用方式是API,以下是查看提供的API。
最轻模式
以上的部署方式是需要显卡的,对于我们这些没卡的一族来说,就很尴尬。但是项目很贴心,提供一个lite模式,该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线API实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
$ pip install -r requirements_lite.txt
$ python startup.py -a --lite
该模式支持的在线 Embeddings 包括:
- 智谱AI
- MiniMax
- 百度千帆
- 阿里云通义千问
在 model_config.py 中 将 LLM_MODELS 和 EMBEDDING_MODEL 设置为可用的在线 API 名称即可
总结
项目的结构非常不错,针对当前热门的AI知识库给出一种非常好的构建方式,而且还做到了全链条的开源产品,所以无论你是希望直接使用它来构建知识库,还是希望通过本项目学习和实现自己的解决方案,都会是非常好的选择。
我也建议大家不要单纯的伸手党,还是要自己去研究一下项目的架构,因为这类项目实际上最精华的就是架构设计。

项目信息
- 项目名称: Langchain-Chatchat
- GitHub 链接:github.com/chatchat-sp…
- Star 数:27K
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2026 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2026 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献621条内容
已为社区贡献621条内容

所有评论(0)