【ComfyUI】Qwen Edit 人像一致性写真修图
本文介绍了一套基于Qwen系列视觉模型的人像一致性写真修图工作流。该工作流通过多模型协同(UNET、CLIP、VAE等)实现从单张人像生成连续动态场景,保持面部特征稳定的同时完成自然过渡。流程包含图像加载、视觉理解、提示词生成、条件编码、采样解码等8个阶段,利用AILab_QwenVL节点自动分析图像并生成连贯场景描述,配合LoRA强化风格表现,最终输出高质量一致性人像写真。整套方案实现了人像编辑
今天给大家演示一个基于 Qwen Image Edit 的人像一致性写真修图工作流,这个流程通过多模型协同、自动化场景描述生成、精细化条件编码和高质量采样,让原始人像在保持面部特征稳定的前提下,实现连续、多镜头、自然衔接的动态写真效果。
整个流程围绕输入照片展开,从图像分析、动作延展、场景重建到最终画面生成,都做到连贯顺滑,适合需要大量一致性输出的人像创作场景。

文章目录
工作流介绍
这个工作流围绕 Qwen 系列视觉模型构建,核心目标是从单张输入人像图像出发,通过大模型对画面进行深度理解,再生成连续的“下一秒动作场景”提示词,并驱动图像编辑模型生成高一致性的新画面。在结构上,工作流使用了 UNET、CLIP、VAE 作为基础模型组件,配合两个 LoRA 进行风格和镜头强化,再经过 AuraFlow 采样修正和 CFG 归一化保证输出的稳定性。节点上,包括图像加载、纵横比控制、视觉理解、文本拆分、条件编码、采样、解码和最终保存等环节,形成完整的生产路径。综合来看,它是一套面向人像一致性编辑的高自动化工作流,为摄影级别的动态写真创作提供了清晰、高效的解决方案。
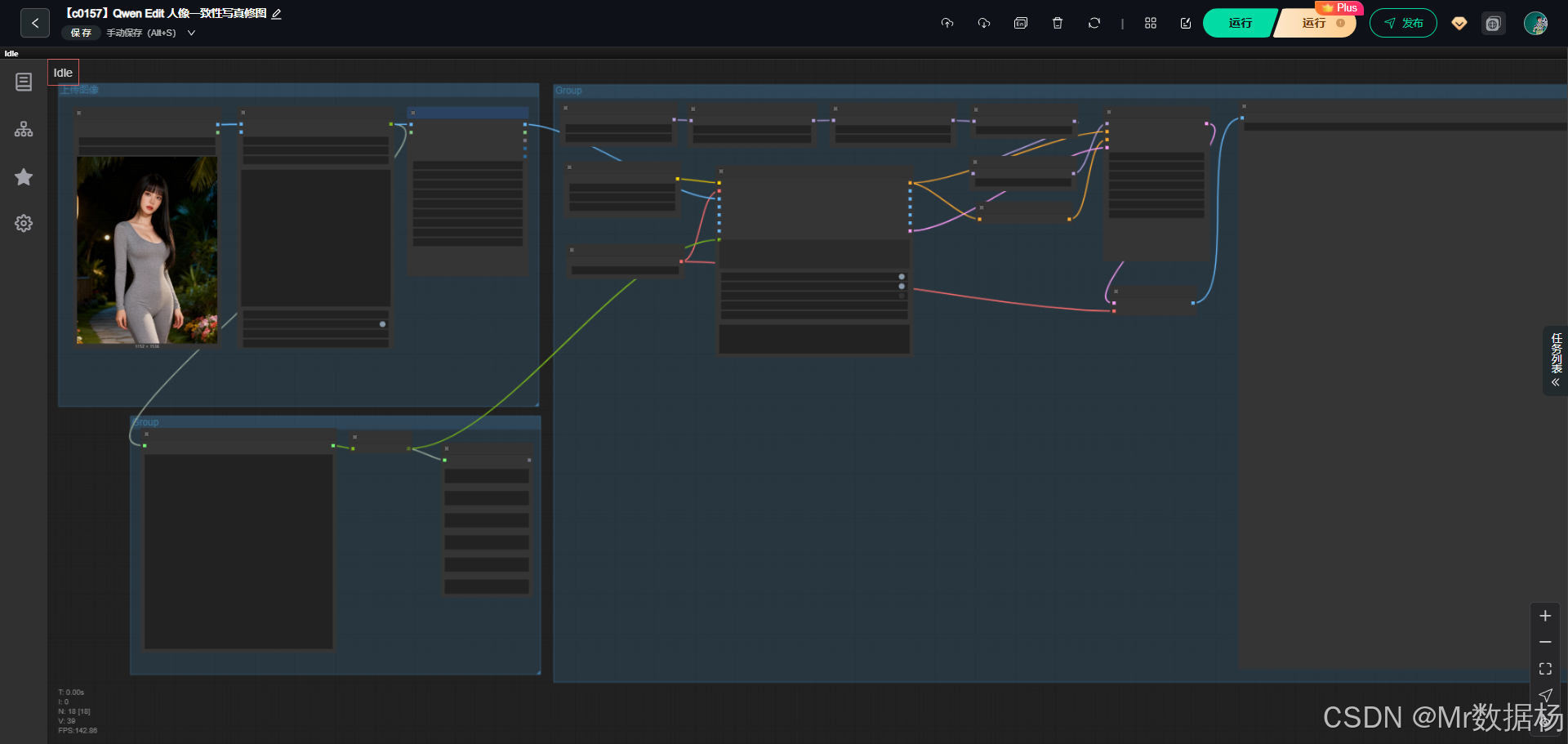
核心模型
整个工作流依靠多模型协同来保持人物一致性、镜头逻辑和最终画面的自然过渡。UNET 提供图像编辑核心能力,CLIP 负责图像与文本的双向理解,VAE 用来压缩与还原潜空间图像,LoRA 承担风格强化与镜头语义补充,而 AuraFlow 与 CFGNorm 则用于优化采样质量与一致性。这些模型组合在一起,使工作流能从输入图像中精确提取人物信息,再根据生成的下一场景提示词重建整体画面。
| 模型名称 | 说明 |
|---|---|
| UNETLoader(qwen_image_edit_2509_fp8_e4m3fn.safetensors) | 工作流的基础编辑模型,用于执行图像编辑和局部重建。 |
| CLIPLoader(qwen_2.5_vl_7b_fp8_scaled.safetensors) | 负责图像理解与提示词编码,使模型能理解照片内容并生成对应的编辑条件。 |
| VAELoader(qwen_image_vae.safetensors) | 用于潜空间图像的压缩与解压,保证生成图像的细节还原度。 |
| LoraLoaderModelOnly(Qwen-Image-Lightning 及 镜头转换 LoRA) | 强化模型的风格与镜头表现能力,支持更加一致与风格化的人像呈现。 |
| ModelSamplingAuraFlow | 调整采样特性,使输出趋于稳定光影与更自然的视觉连续性。 |
| CFGNorm | 控制 CFG 强度,提升生成稳定性与一致性。 |
Node 节点
节点之间形成清晰的处理链条:前段负责图像输入与分析,中段负责提示词生成与结构化处理,后段由条件编码、采样与解码完成最终图像输出。图像加载节点与纵横比处理节点确保输入干净统一,QwenVL 节点负责自动生成下一场景动作描述,再用 StringToList 拆解成多段提示词。接着 TextEncodeQwenImageEditPlus 将这些信息转换为模型可用的条件,再通过采样链路生成最终画面。整体节点的组合让创作过程全自动、可控且一致性强。
| 节点名称 | 说明 |
|---|---|
| LoadImage | 加载输入照片,为后续分析和编辑提供基础图像。 |
| LayerUtility: ImageScaleByAspectRatio V2 | 按比例缩放图像,保证尺寸统一与编辑兼容性。 |
| AILab_QwenVL | 自动理解图像并生成多段下一场景提示词。 |
| easy showAnything | 展示与中转节点,用于处理字符串内容。 |
| JDCN_StringToList | 将大段提示词拆分为多段结构化的文本列表。 |
| UNETLoader | 加载图像编辑基础模型。 |
| CLIPLoader | 加载视觉语言模型,解析图像与提示词。 |
| VAELoader | 加载 VAE 模型用于潜空间处理。 |
| LoraLoaderModelOnly | 加载 LoRA 文件强化风格、镜头和编辑能力。 |
| ModelSamplingAuraFlow | 处理模型采样特征,使画面更加稳定。 |
| CFGNorm | 控制 CFG 行为,增强输出一致性。 |
| TextEncodeQwenImageEditPlus_lrzjason | 核心条件编码节点,将图像与提示词结合,生成编辑引导。 |
| KSampler | 执行采样生成潜图。 |
| VAEDecode | 将潜图解码成最终图像。 |
| SaveImage | 保存输出结果。 |
工作流程
整个流程从载入参考图像开始,再通过纵横比处理确保图像尺寸适配模型需求。随后由 QwenVL 自动分析画面并生成连贯的下一场景描述,经字符串拆分后输入到文本编码节点,与原图共同构成编辑条件。模型加载链路准备好 UNET、CLIP、VAE 以及两个 LoRA,并由 AuraFlow 与 CFGNorm 调整采样特性,最终 KSampler 根据条件生成潜图,再由 VAE 解码成清晰成片。整条流程保持人物外观一致、动作自然过渡、镜头变化顺滑,最终输出稳定且富表达力的写真画面。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 输入准备 | 载入用户图像并进行适配性缩放,为后续分析打好基础 | LoadImage、ImageScaleByAspectRatio |
| 2 | 图像理解 | 由视觉大模型读取画面内容,自动生成下一场景提示词 | AILab_QwenVL |
| 3 | 文本处理 | 将长提示词拆分为多段可控文本,用于后续条件编码 | easy showAnything、StringToList |
| 4 | 模型加载 | 加载 UNET、CLIP、VAE 以及 LoRA,为图像编辑搭建核心结构 | UNETLoader、CLIPLoader、VAELoader、LoraLoader |
| 5 | 条件生成 | 将原图、提示词融为完整编辑条件,引导后续采样 | TextEncodeQwenImageEditPlus |
| 6 | 采样调优 | 调整模型采样属性与 CFG 行为,使画面更稳定自然 | AuraFlow、CFGNorm |
| 7 | 图像生成 | 采样生成潜图并解码成最终成片 | KSampler、VAEDecode |
| 8 | 输出保存 | 输出最终写真图像 | SaveImage |
大模型应用
AILab_QwenVL 图像理解与动态场景生成节点
该节点承担整个工作流的图像语义理解任务。它读取输入照片后,通过内置的视觉语言模型解析人物姿态、光线、环境与构图,再基于提供的 Prompt 生成多段“下一场景”文本。Prompt 在此节点中决定了场景延展的风格、动作变化的幅度、镜头运动的逻辑与表达密度。用户无需手动构思动作,只需依赖 Prompt,即可自动得到连续而自然的场景描述。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| AILab_QwenVL | Describe this image in detail. 你是一位专业提示词专家,根据参考图像生成6段完整的同一图像提示词,须要保持人物一致性,包括衣服,场情的一致性,不要废话。在创作时,需要严格按照如下需求: 1、分析参考图像,生成下一个2秒后的图像差异提示词,请专注于动态细节的表示,让动作更佳自然的变换, 2、核心描述为图像间的合理变化,镜头的合理变化,环境的合理变化,场景的变化,动作的合理变化, 3、如果有主体,比如是人物,动物,角色等,核心的动作变化应该以主体的变化为主,需要详细描述,每段提示词人物动态不能与前后提示词动态一样, 4、每段提示词与下一段提示司,不要分行,不要有空隔。 例如提示词展示: 下一个场景:镜头从对飞艇的紧密特写拉远,呈现出在奇幻景观中翱翔的整个舰队。 下一个场景:镜头向前跟踪并向下倾斜,将太阳和直升机拉得更近,同时强烈的镜头光晕增强。 下一个场景:镜头向右平移,移除龙和骑手的视野,同时揭示远处更多的漂浮山脉。 |
图像理解与动态提示词生成的大模型节点,通过 Prompt 决定输出内容的动作逻辑、风格一致性和镜头变化方式。 |
TextEncodeQwenImageEditPlus 文本条件编码节点
该节点负责把 Prompt、原图潜信息以及多段文本描述整合成可用于图像生成的“条件”。它不改变图像,也不生成画面,而是负责把文本语义正确传递给后续生成模型,使生成行为严格遵循 Prompt 的风格、内容、动作与质量要求。Prompt 控制图像如何修改、添加什么细节、如何保持一致性,是驱动最终画面风格与变化方式的核心指令。
| 节点名称 | Prompt 信息 | 说明 |
|---|---|---|
| TextEncodeQwenImageEditPlus_lrzjason | Describe the key features of the input image (color, shape, size, texture, objects, background), then explain how the user’s text instruction should alter or modify the image. Generate a new image that meets the user’s requirements while maintaining consistency with the original input where appropriate. | 负责将 Prompt 与图像内容融合成可供模型理解的条件,确保生成结果受 Prompt 精确控制并维持人物与画面一致性。 |
使用方法
这个工作流的运行逻辑非常直接:用户只需替换输入图像,系统就会自动完成后续所有步骤。工作流先载入照片并调整尺寸,再由 QwenVL 分析画面并生成多段下一场景的动作和镜头提示。之后系统会自动拆分文本,把这些内容送入条件编码节点,再配合模型加载链路完成采样、生成与最终解码。整个过程无需用户干预,只要替换主图并保持 Prompt 内容不变,就能自动生成一系列连贯的动态写真画面。自动化流程确保创作者无需手写提示词,也无需逐步调整动作,只需提供一张图即可得到完整的动态写真组图。
| 注意点 | 说明 |
|---|---|
| Prompt 不可随意删除关键描述 | 包含动作逻辑、镜头变化、人物一致性的部分必须保留,避免破坏自动生成结构。 |
| 输入图像需清晰且主体完整 | 模糊或遮挡会影响大模型对姿态与细节的理解,降低一致性效果。 |
| 不要在提示词中加入太多风格混杂的描述 | 文本过度复杂会导致输出不稳定。 |
| 尺寸处理节点不可移除 | 缩放保证图像能与后续模型完全兼容。 |
| 生成多段文本后勿手动插入换行 | 该工作流需要连续文本结构,否则拆分节点无法正确处理。 |
| 若人物服装发生大改动,需重新构图提示 | 否则模型会尝试“保持一致”而导致冲突。 |
应用场景
这个工作流特别适用于需要保持人物一致性又要呈现动态变化的创作需求,比如写真图拍摄延展、剧情分镜、人像短片补帧、角色连续动作描绘等。通过自动生成下一场景提示词,创作者可以轻松得到连贯的多镜头画面,而模型链路确保人物特征不漂移、镜头运动自然、环境变化连贯,让结果更接近真实摄影的运镜表现。它适合摄影师、视频制作人、角色创作者、品牌营销团队等用户,用于快速生成高质连续画面。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 写真延展创作 | 从单张图延伸出多张一致性动态写真 | 摄影师、模特工作室 | 连续动作、自然过渡、稳定外观 | 高一致性写真组图 |
| 分镜与剧情草图 | 生成角色下一秒的自然动作与镜头变化 | 视频创作者、导演 | 连贯分镜、镜头运动建议 | 快速预览场景走向 |
| 角色动态设计 | 保持角色造型稳定的动态动作图 | 角色设计师、IP 团队 | 多角度动作、环境变化 | 动态角色展示图 |
| 营销图生成 | 快速产出稳定风格的人像组图 | 品牌方、电商团队 | 系列写真、统一风格 | 高效批量生成内容 |
| AI 影像叙事 | 创造连续场景的视觉故事 | 创作者、自媒体 | 连贯叙事镜头组合 | 生成短篇视觉故事 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)