LangChain开发框架
LangChain是一个简化大语言模型(LLM)应用开发的框架,提供统一接口连接各类LLM组件。其核心包括提示词模板、多类型模型集成、记忆存储、文档索引、链式调用和智能体等功能模块,支持从开发到部署的全生命周期管理。通过模块化设计,开发者可以快速构建复杂的LLM应用,如个人助手、文档问答系统、聊天机器人等场景。LangChain的特色在于简化了LLM应用开发的各个环节,并提供生产化工具链支持。
一、LangChain简介
创建于22年10月,核心理念就是为各种LLM实现通用的接口,把LLMs相关的组件"链接"在一起,简化LLMs应用的开发难度。方便开发者快速地开发复杂的LLMs应用。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
-
开发:使用 LangChain 的开源组件和第三方集成构建应用程序。使用 LangGraph 构建具有一流流式和人机交互支持的状态智能体。
-
生产化:使用 LangSmith 检查、监控和评估应用程序,方便持续优化和部署。
-
部署:使用 LangGraph平台 将应用程序转变为可用于生产的 API 和助手。
二、核心组件
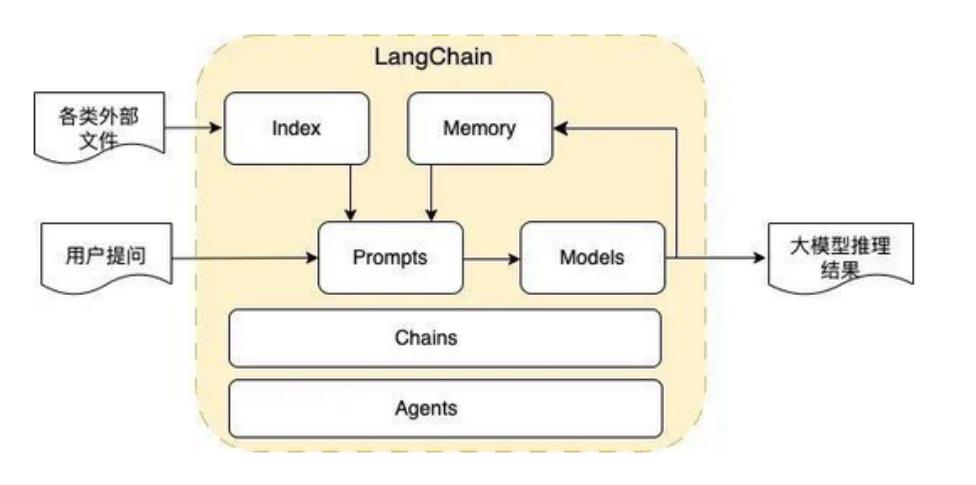
①Prompt Templates:提示词模板
用户输入信息时,给模型添加提示模板,
可以是zero-shot:直接使用,构建一个PromptTemplate,不需要example。相当于字符串.format
也可以是few-shot:需要提供example,先构建PromptTemplate,再构建FewShotPromptTemplate,需要传入下面参数
examples:(列表+dict格式)
example_prompt = example_prompt
prefix:前缀,eg:"给出每个单词的反义词"
sufix:后缀eg:"单词: {input}\\n反义词:"
让模型更好理解复杂场景,以便更好地解决问题
②Models:模型
各种类型的模型和模型集成,比如OpenAI、Llama、qwen等,提供统一接口,便于在不同模型之间切换。
目前支持三种类型模型:
-
LLMs (大语言模型):
大模型的下载库:https://huggingface.co/models
接收文本字符的输入,返回的也是文本字符
-
Chat Models (聊天模型):
基于LLMs,不同的是它接收聊天消息,返回的也是聊天消息(一种特定格式的数据,包含角色划分)
聊天消息包含下面几种类型:
AIMessage: 就是 AI 输出的消息.
HumanMessage: 用户提示词
SystemMessage: 系统提示词,指定模型所处环境和背景,如角色扮演
ChatMessage: Chat 消息可以接受任意角色的参数,但我们平时大多数使用上面三种。
-
Embeddings Models(嵌入模型):
接收文本作为输入,返回的是文本对应的向量,将数据进行文本向量化
③Memory:记忆
用来存储对话的上下文信息,分为:
短期记忆:当前对话的上下文,实例化会话链ConversationChain,自动保存历史内容
长期记忆:比如通过ChatMessageHistory对象存储对话信息,结合向量数据库,持久化存储对话信息,便于未来检索,每个对象都有序列化和反序列化
④Indexes:索引组件
用来结构化文档,以便和模型交互,就是让LangChain具备处理文档处理的能力,包含文档加载、分割、向量化、检索。
文档加载器
文本分割器
VectorStores
检索器
⑤Chains:链式调用
一系列对各种组件的调用,Chains描述了将LLM与其他组件结合起来完成一个应用程序的过程。
支持
单步任务:LLMChain,单个节点,执行完就结束
多步任务:SimpleSequentialChain,简单序列Chain,将上一步的输出作为下一步输入,依次循环,每一步都需要一个LLMChain单节点。
使得复杂任务处理更加模块化,可复用。
⑥Agents:智能体
通过Reaect框架,Agent可以根据用户输入选择合适的工具来完成任务。更加灵活。
决定模型采取哪些行动,执行并且观察流程,直到完成为止
循环【思考 (Think) → 执行 (Act) → 观察 (Observe)】
实现步骤:
实例化模型→定义工具→构建Agent对象,传入Agent类型→准备提示词→执行Agent,传入提示词
本质:
React提示词和用户输入的拼接执行
三、使用场景
-
个人助手
-
基于文档的问答系统
-
聊天机器人
-
Tabular数据查询
-
API交互
-
信息提取
-
文档总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)