DeepSeek-OCR 2 核心技术摘要
DeepSeek-OCR 2:告别机械扫描,赋予AI“人类直觉”
核心创新:DeepEncoder V2

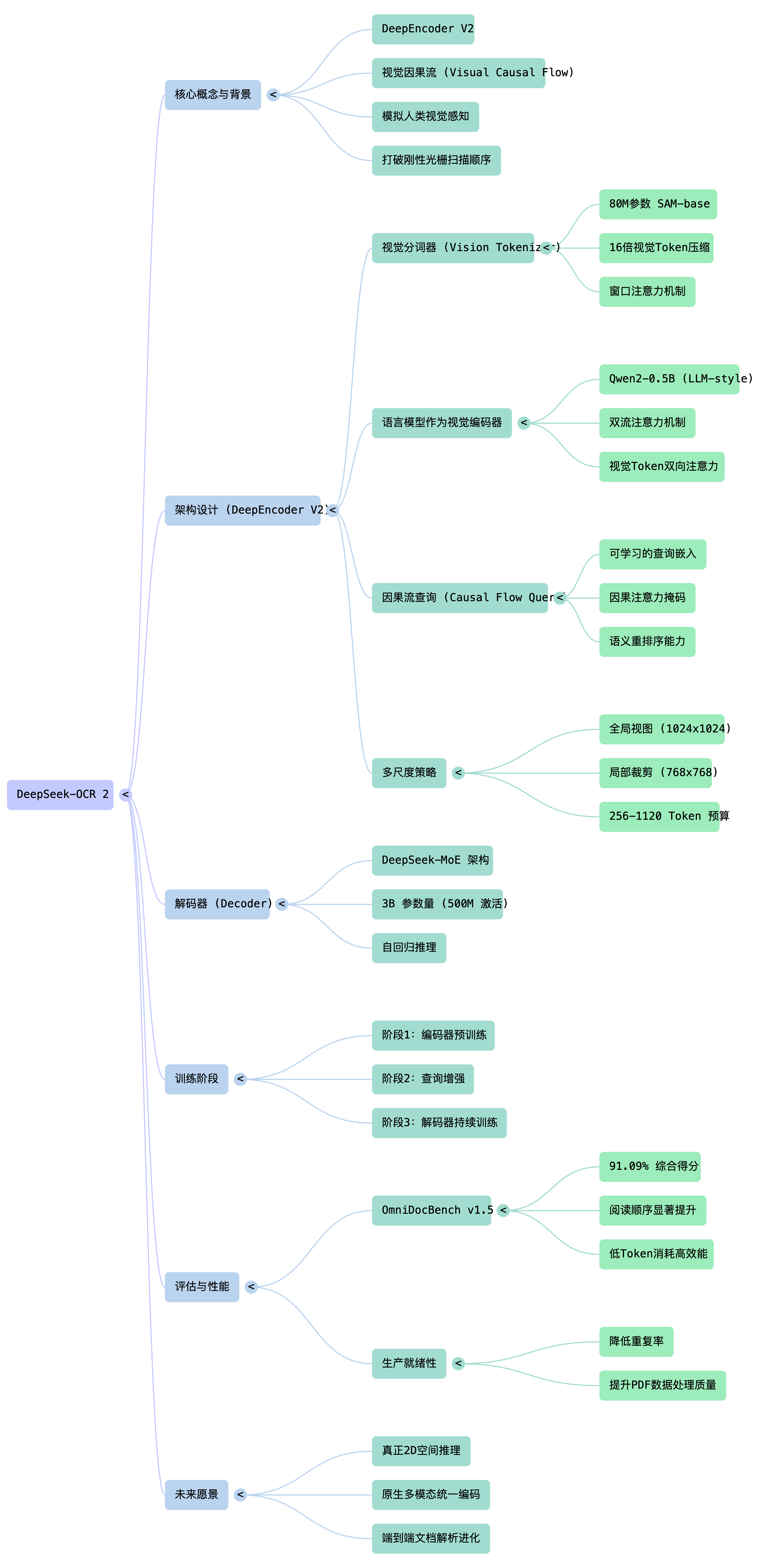
DeepSeek-OCR 2 的核心是 DeepEncoder V2,一个能够根据图像语义动态重排视觉token的新型编码器。
设计动机
传统视觉-语言模型采用固定的光栅扫描顺序(从左上到右下)处理视觉token,这与人类视觉感知矛盾。人类视觉遵循由语义理解驱动的因果流动模式,特别是在处理复杂布局(如文档、表格、公式)时,展现出因果驱动的序列处理能力。
相关工作
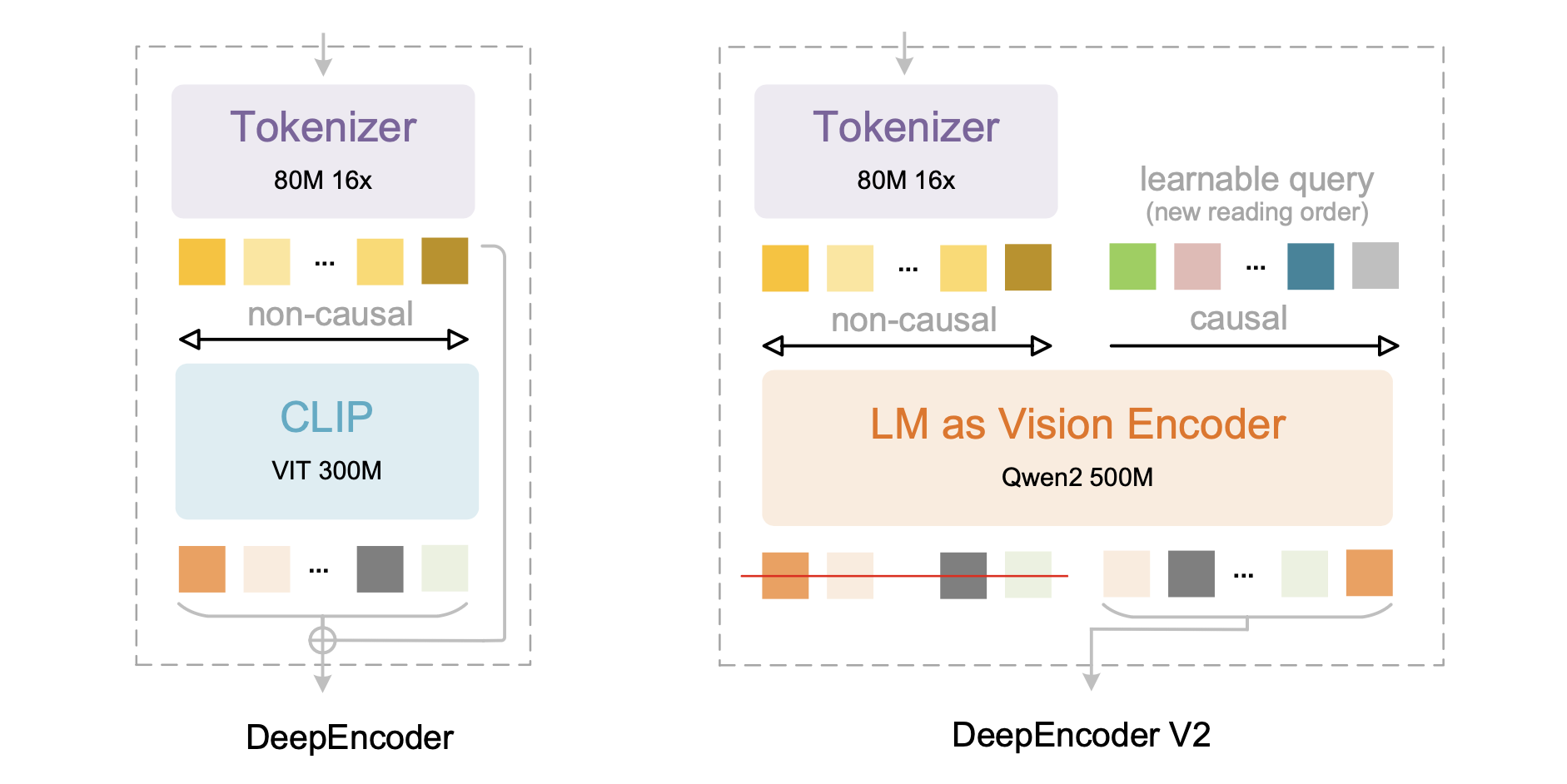
解码器中的并行查询(Parallelized Queries in Decoder)
DETR 开创性地将 Transformer 引入目标检测,通过引入100个可学习的对象查询(Object Queries),克服了串行解码的效率限制。这些查询通过交叉注意力与特征图交互,同时通过自注意力进行双向信息交换,建立了 Transformer 处理并行化 Token 的基础范式。
投影器中的并行查询(Parallelized Queries in Projector)
当前视觉-语言模型普遍采用编码器-投影器-LLM 范式。BLIP-2 的 Q-former 是典型的投影器设计,采用类BERT架构,借鉴 DETR 的对象查询思想,使用32个可学习查询通过交叉注意力与数百个 CLIP 视觉 Token 交互,实现视觉到语言空间的有效映射和 Token 压缩。
基于LLM的多模态初始化(LLM-based Multimodal Initialization)
大规模预训练的 LLM 已被证明可有效用于多模态模型初始化。冻结的 LLM Transformer 层能增强视觉判别任务。Fuyu 和 Chameleon(视觉领域)、VALL-E(语音领域)等无编码器或轻量编码器模型进一步验证了 LLM 预训练权重用于多模态初始化的潜力。
架构设计
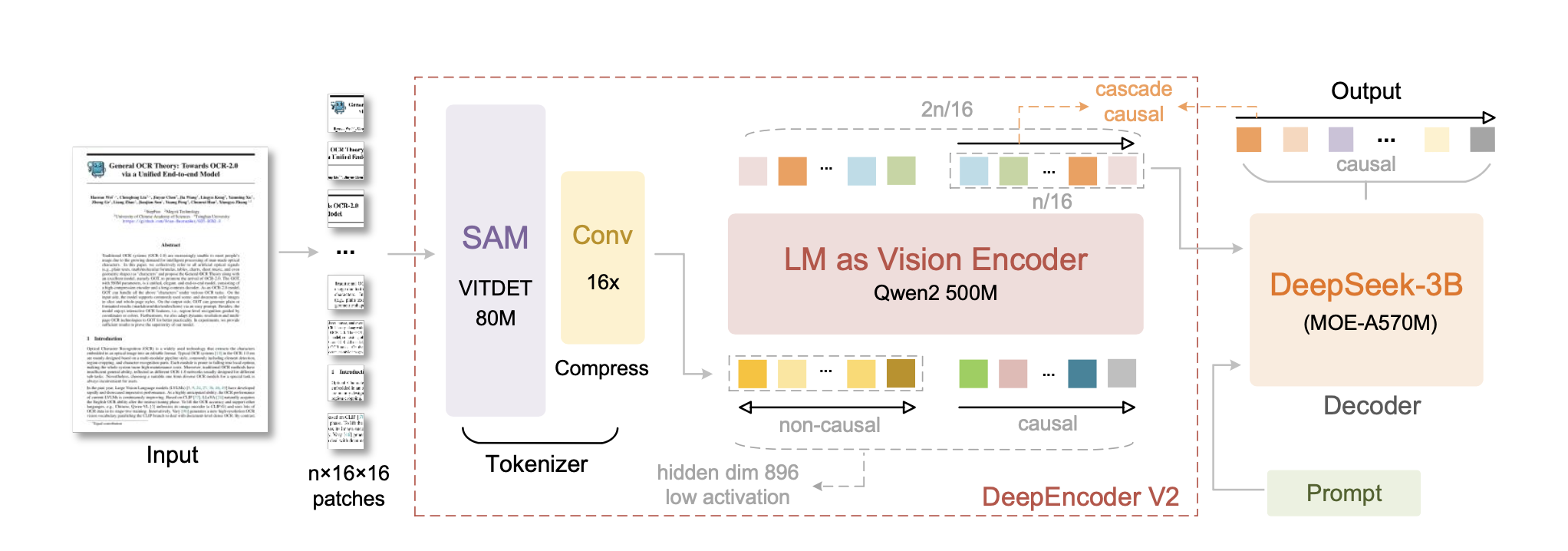
DeepEncoder V2 用紧凑型语言模型(Qwen2-0.5B,500M参数)替换了原 DeepEncoder 中的 CLIP 模块(300M参数),通过定制化的注意力掩码实现:
-
双流注意力机制
- 视觉token
:使用双向注意力,保持全局感受野
- 因果流查询token
:使用因果注意力,每个查询可关注所有视觉token和前序查询
- 视觉token
-
可学习查询(Causal Flow Query)
-
查询token数量等于视觉token数量(256-1120个)
-
采用多裁剪策略:全局视图1024×1024对应256个查询,局部裁剪768×768对应144个查询
-
只有查询token的输出被送入LLM解码器
-
-
级联因果推理
-
第一阶段:编码器通过查询token对视觉信息进行语义重排序
-
第二阶段:LLM解码器对重排后的序列进行自回归推理
-
探索"两个级联的1D因果推理结构能否实现2D图像理解"的新范式
-
技术细节
- 视觉分词器
:80M参数的SAM-base + 两个卷积层,实现16倍token压缩
- 注意力掩码
:左侧为视觉token的双向掩码,右侧为查询token的因果三角掩码
- 解码器
:保持原DeepSeek-OCR的3B参数MoE结构(约500M激活参数)
性能提升
在 OmniDocBench v1.5 基准测试上:
- 整体性能
91.09%(相比 DeepSeek-OCR 的 87.36%,提升 3.73%)
- 公式识别
90.31%(提升 6.17%)
- 表格识别
87.75%/92.06%(提升 2.5%/3.05%)
- 阅读顺序编辑距离
0.057(相比 0.085,降低 0.028),验证了视觉重排序能力
- 视觉token上限
1120(相比 1156,减少 36个),是所有端到端模型中最少的
在生产环境中:
-
在线用户图像重复率:从 6.25% 降至 4.17%(降低 2.08%)
-
PDF预训练数据重复率:从 3.69% 降至 2.88%(降低 0.81%)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)