刚刚,DeepSeek开源新模型!
是时候准备面试和实习了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。年底了,DeepSeek又开始发力了,刚刚开源了新模型DeepSeek-OCR 2:首创双流(双向+因果)注意力架构,model&paper一同发布。开源地址:https://hug
是时候准备面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

年底了,DeepSeek又开始发力了,刚刚开源了新模型DeepSeek-OCR 2:首创双流(双向+因果)注意力架构,model&paper一同发布。

开源地址:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
一、为什么传统 OCR “读不懂” 文档布局?
当前的视觉语言模型(VLMs)在处理图像时,无一例外地采用固定的光栅扫描顺序(从左到右、从上到下),并配合固定的位置编码将视觉 Token 输入 LLM。然而,这与人类视觉感知机制存在本质矛盾。
人类阅读文档时,视线移动遵循语义驱动的因果流(Causally-driven Flow)。比如在阅读螺旋图表或复杂表格时,我们的眼动逻辑由内容本身的结构性决定,而非简单的空间坐标顺序。
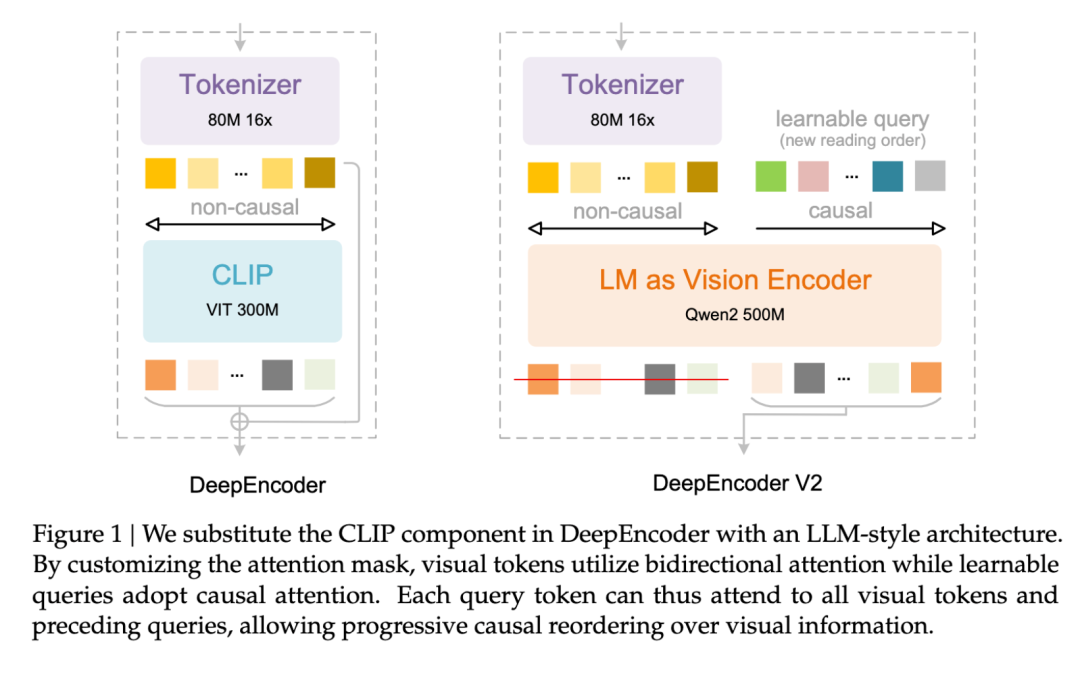
Figure 1: DeepEncoder vs DeepEncoder V2 架构对比
图 1:左图为传统 DeepEncoder(基于 CLIP ViT 的固定扫描),右图为 DeepEncoder V2(引入 LM 作为编码器实现因果流)
二、技术突破:DeepEncoder V2 的"双流"架构
DeepSeek-OCR 2 的核心创新在于完全重构了视觉编码器,提出 DeepEncoder V2。其设计理念是:通过两级级联的 1D 因果推理结构来实现真正的 2D 图像理解。
2.1 整体架构
系统延续 Encoder-Decoder 范式,但编码器部分进行了根本性升级:
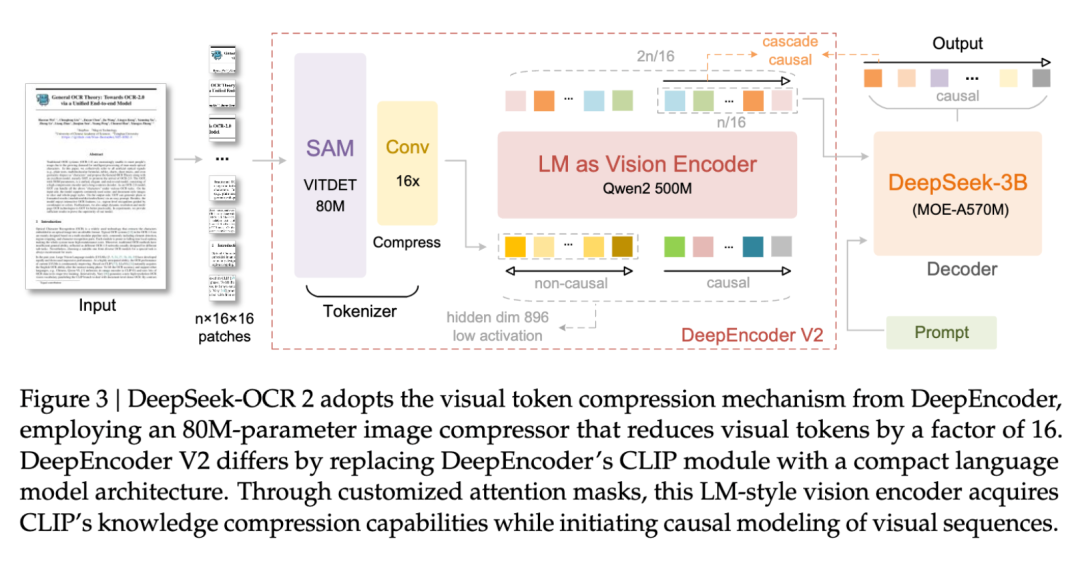
Figure 3: DeepSeek-OCR 2 整体架构图
图 3:输入图像经过 SAM ViTDet 分块 → Conv 压缩 → Qwen2-0.5B 编码器(双向注意力+因果注意力双流)→ DeepSeek-3B MoE 解码器
关键组件:
Vision Tokenizer:80M 参数的 SAM-base + 两层卷积,实现 16× Token 压缩
LM as Vision Encoder:使用 Qwen2-0.5B(500M 参数)替代传统 CLIP ViT
Causal Flow Query:可学习的因果流查询,数量与视觉 Token 相等(n=m),用于语义重排序
2.2 因果流查询(Causal Flow Query)
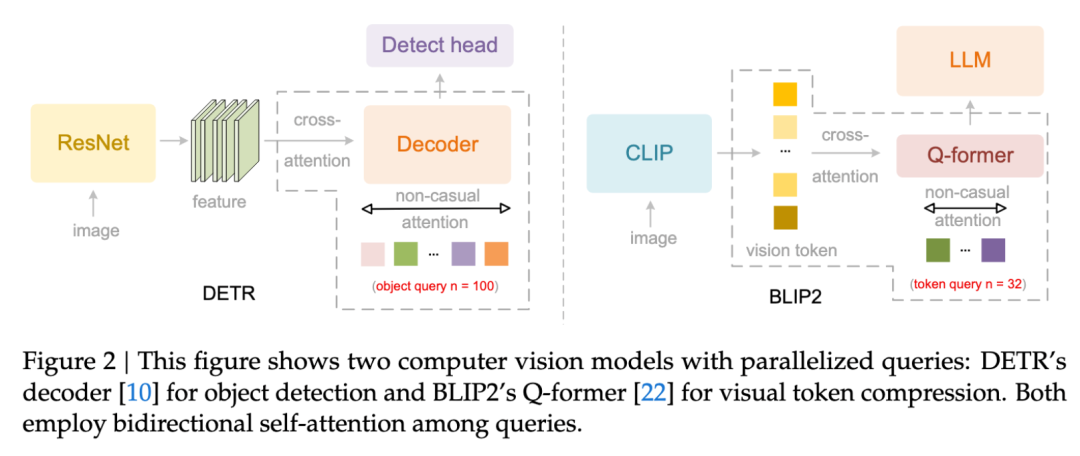
为了避免固定位置编码带来的归纳偏置,DeepEncoder V2 引入可学习的因果流 Token:
双流注意力设计:
视觉 Token(前半部分):使用双向注意力(Bidirectional Attention),保持全局视野
因果查询 Token(后半部分):使用因果注意力(Causal Attention),每个查询只能关注其之前的 Token
智能重排序机制:因果查询通过注意力机制从视觉 Token 中"提取"并"重排"信息,形成符合阅读逻辑的序列

Figure 4: 多裁剪策略与查询配置
图 4:Local View(768×768,144 个查询)与 Global View(1024×1024,256 个查询)的多裁剪策略,总 Token 控制在 256-1120 之间
2.3 精巧的 Attention Mask 设计
DeepEncoder V2 的 Attention Mask 是一个分块矩阵,完美融合了 ViT 和 LLM 的特性:
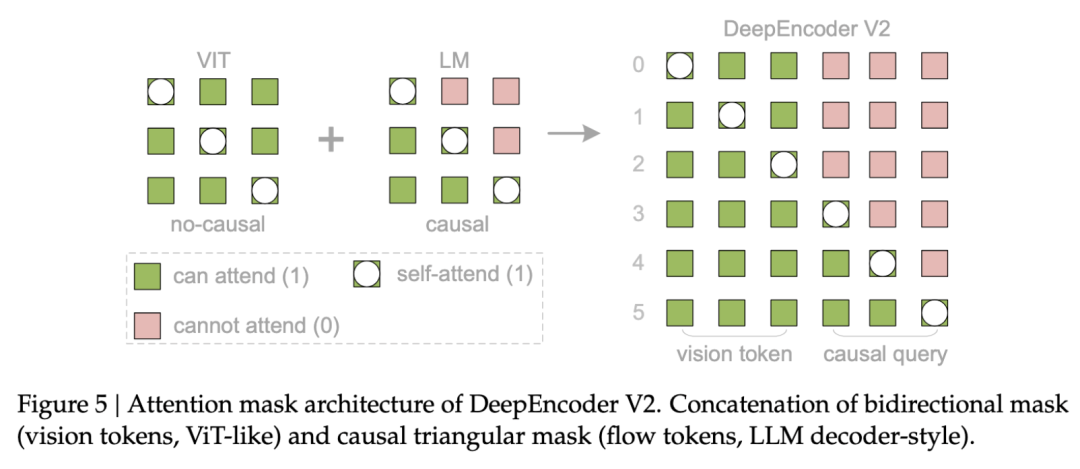
Figure 5: DeepEncoder V2 的 Attention Mask 可视化
图 5:左半部分(绿色)为视觉 Token 的双向全连接注意力,右半部分(粉色)为因果查询的三角掩码注意力
数学表达:

其中n=m(查询数等于视觉 Token 数),LowerTri为下三角矩阵。
三、训练策略:三阶段渐进式优化
DeepSeek-OCR 2 采用三阶段训练流程:
-
Encoder 预训练:使用语言建模目标,联合优化 Vision Tokenizer 和 LM-style Encoder(学习率 1e-4 → 1e-6)
-
Query 增强:冻结 Visual Tokenizer,联合优化 Encoder 和 Decoder,引入多裁剪策略统一数据加载
-
Decoder 专项训练:冻结 Encoder 全量参数,仅训练 DeepSeek-LLM 解码器,提升训练速度 2 倍以上
四、实验结果:SOTA 性能与效率的平衡
在 OmniDocBench v1.5(1,355 页文档,9 大类别)上的评测显示:
4.1 主性能指标
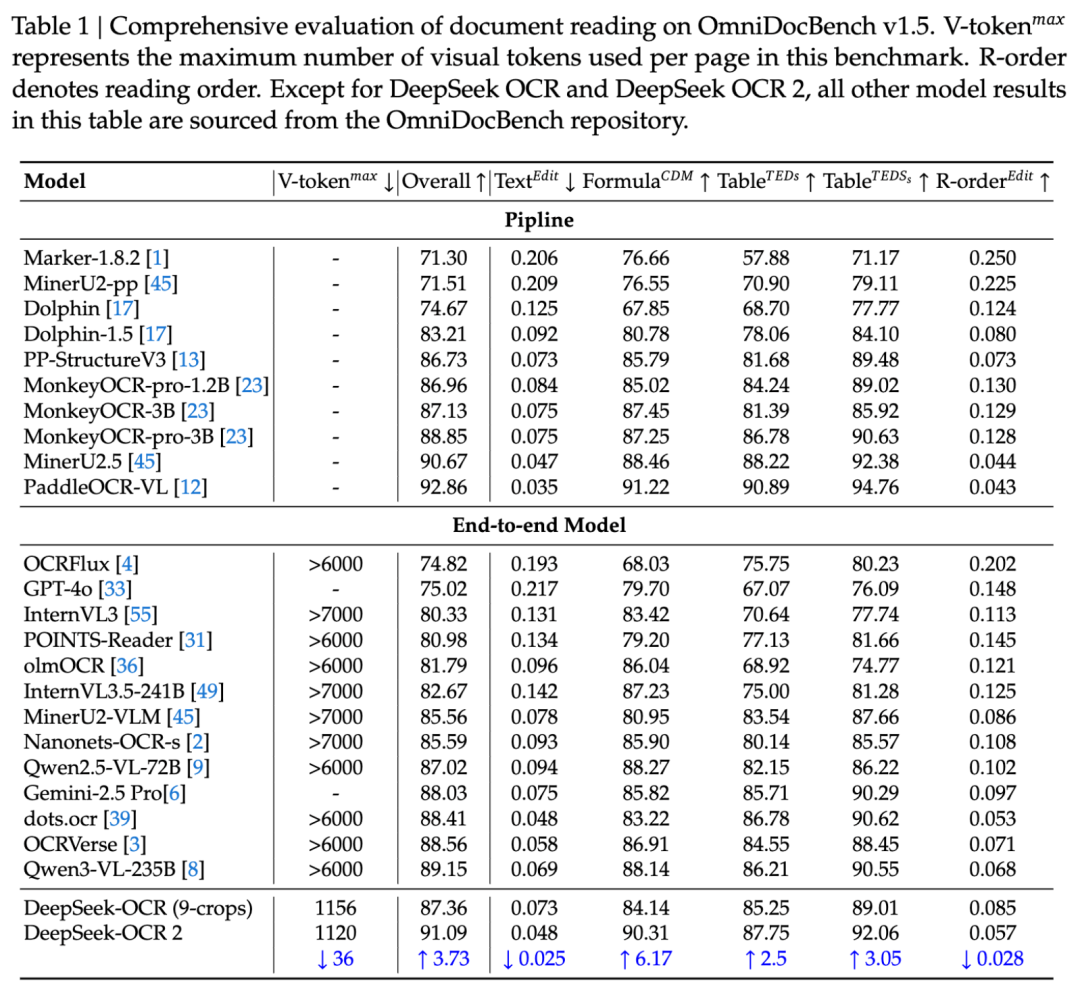
Table 1: OmniDocBench v1.5 综合评测结果
表 1:DeepSeek-OCR 2 在 V-token_max=1120 的条件下,达到 91.09% Overall 准确率,相比 DeepSeek-OCR(87.36%)提升 3.73%,且视觉 Token 预算更低(1120 vs 1156)
关键发现:
-
阅读顺序 Edit Distance 从 0.085 降至 0.057,证明因果流机制显著改善了逻辑阅读顺序
-
在公式识别(Formula CDM)上提升 6.17个百分点
-
Token 压缩率与 Gemini-3 Pro 相当(1120),但性能更优
4.2 不同视觉 Token 预算对比
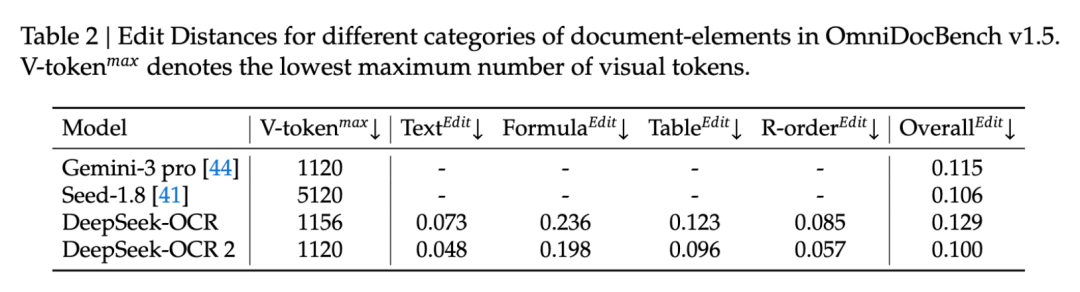
Table 2: 不同类别文档元素的 Edit Distance 对比
表 2:在相同视觉 Token 预算(~1120)下,DeepSeek-OCR 2(0.100)相比 Gemini-3 Pro(0.115)拥有更低的整体 Edit Distance
4.3 细分文档类型分析
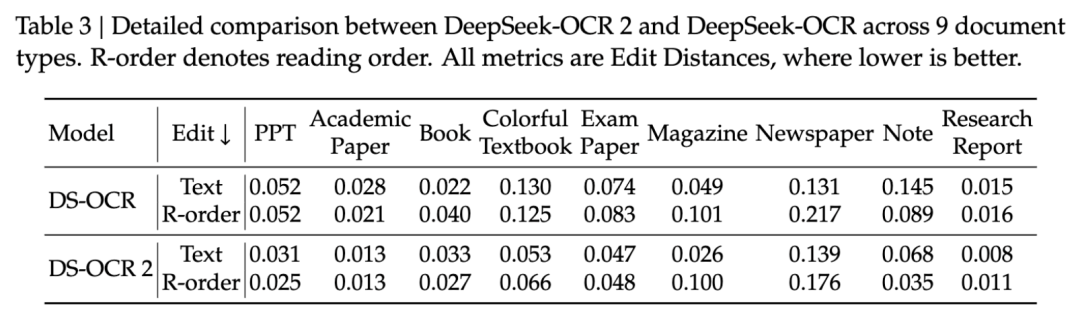
Table 3: 9 种文档类型的详细对比
表 3:DeepSeek-OCR 2 在阅读顺序(R-order)指标上全面优于前代,但在 Magazine(杂志)类文档的文本识别上仍有改进空间(ED=0.139),主要受限于训练数据不足(仅 250k 样本)
4.4 生产环境验证
在真实生产环境(在线 OCR 服务与预训练数据流水线)中:

Table 4: 生产环境性能对比
表 4:DeepSeek-OCR 2 的文本重复率(Repetition Rate)显著降低:在线用户日志从 6.25%→4.17%,PDF 数据处理从 3.69%→2.88%

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)