深度学习项目代码实战逐步解析笔记(上)
(1) 训练集(Training Set)作用:用于训练模型,即通过反向传播和优化器不断调整参数。特点:模型“见过”的数据,直接参与损失计算和参数更新。流程输入 → 模型预测 → 计算损失 → 反向传播 → 更新参数。
目录
一、知识点总结部分
(一)一个简单的神经网络项目的组成
Data: 一般输入是文件地址,或者数据内容, 输出是一个 存储了数据X,Y的数据结构。torch中一般用dataloader来装载。
DataLoader 是 PyTorch 中自动将数据集分批、打乱并高效加载的小帮手。让模型训练更省力、更快。
Model: 定义自己的模型 输入X, 输出预测值
HyperPara:
- 是控制训练过程的“开关”和“规则”,不参与模型内部计算。
- 它们不是模型学出来的,而是由人设定的
| 超参数 | 作用 | |
|---|---|---|
| 学习率(lr) | 控制参数更新步长 | |
| 批次大小(batch_size) | 每次训练用多少样本 | |
| 优化器(optimizer) | 如何更新参数 | |
| 损失函数(loss) | 如何衡量错误,常用:
|
|
| 训练轮数(epochs) | 整体训练几次 |
训练流程
(二)训练集、测试集、验证集
1、核心原则:
- 所有数据都应从同一整体数据空间中随机划分而来,确保分布一致。
- 三者互不重叠,各司其职。
2、详细介绍
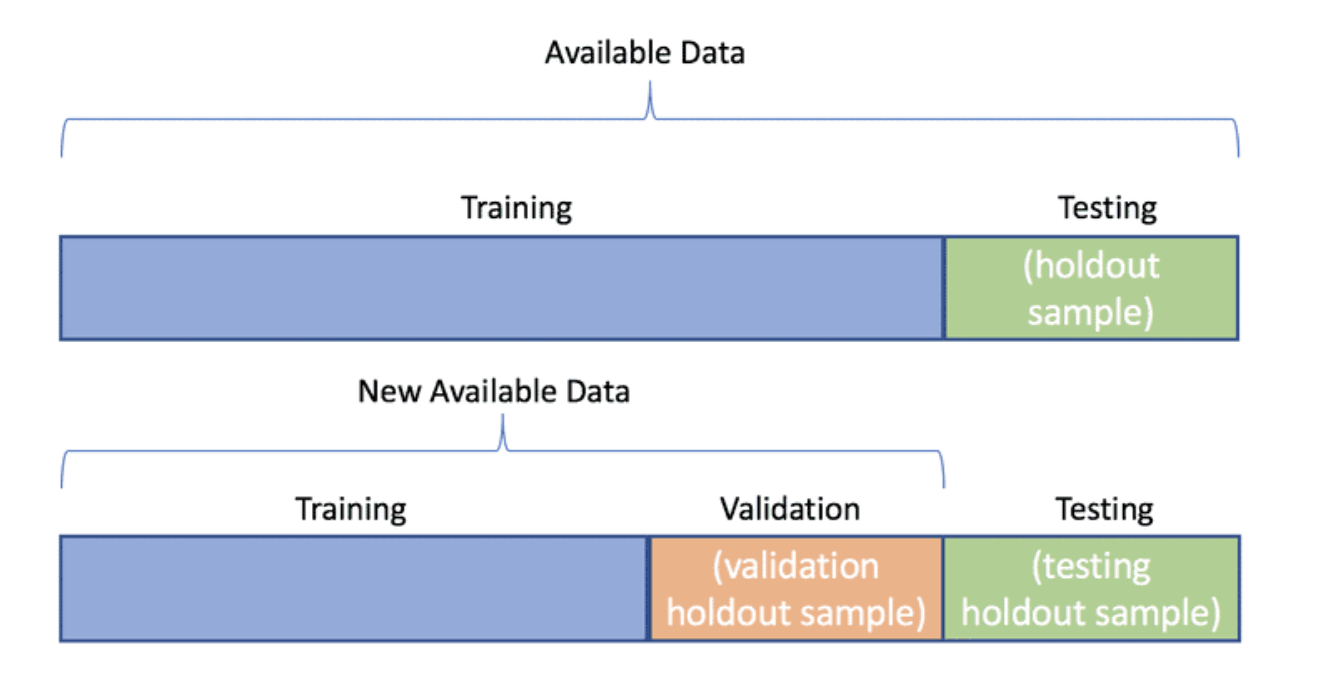
(1) 训练集(Training Set)
- 作用:用于训练模型,即通过反向传播和优化器不断调整参数。
- 特点:模型“见过”的数据,直接参与损失计算和参数更新。
- 流程:
输入 → 模型预测 → 计算损失 → 反向传播 → 更新参数
(2) 验证集(Validation Set)
- 作用:不参与训练,仅用于评估当前模型性能,辅助调参或选择模型。
- 关键点:
- 不更新模型参数
- 用于监控是否过拟合、调整超参数(如学习率、epoch 数)
- 不是用来判断最终效果的
验证集只是为了在训练中“看一眼效果”,不用于最终结论。
(3)测试集(Test Set)
- 作用:模拟模型在真实未知数据上的表现。
- 使用时机:训练完全结束后才使用,且只能用一次。
(三)batch(批次)
先来看下面几个问题:
- 全部数据得到一个loss可以吗?
- 一个数据更新一次可以吗?
答案是:都不可以,最好是一个batch(批次)更新一次模型。
具体是为什么呢???
用所有的数据算一次loss,计算出的结果是很准的,但是无法确定这一步要走多远。
此外,还有内存爆炸,计算效率低,更新频率太低的问题
那么相反,如果一个数据就更新一次,可能会收到噪声的影响,使得loss方向乱跑。
epoch(轮次):所有数据看过一次就是一个epoch
随机梯度下降SGD:随机取数据 ,“边看数据边学习”:每次只用一小批(batch)数据来估算方向,然后立刻更新模型。
batch一般取2的幂次
(四)独热编码(One-Hot Encoding)
将类别变量转为向量:每个类别对应一个长度为总类别数的向量,所属位置为1,其余为0。
例:3类 ["猫", "狗", "鸟"] → 猫=[1,0,0],狗=[0,1,0],鸟=[0,0,1]
使模型能处理分类数据
(五)数据部分
Dataset:
init:读出数据X和Y
getitem:根据下标返回数据
len:得到数据长度
二、实战-新冠病毒感染人数预测
每一个项目都包含上文第一部分提到的四个部分:Data、Model、HyperPara、训练流程
(一)导入库函数
import torch
import matplotlib.pyplot as plt #画图
import matplotlib
import numpy as np #矩阵相关
import csv #处理csv文件
import pandas #处理csv文件
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from torch import optim
import timecsv文件:一种用逗号把数据隔开的简易表格文件。
(二)数据处理
class CovidDataset(Dataset):
def __init__(self, file_path, mode):
with open(file_path, "r") as f: #读取文件
ori_data = list(csv.reader(f))
#把数据转换为矩阵,并且不要第一行和第一列。列表无法做到切片
csv_data = np.array(ori_data)[1:, 1:].astype(float)
#切分训练集和验证集:
#逢五取1,但是不推荐,一般是随机取
if mode == "train": #训练集:如1、2、3、4..
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
elif mode == "val": #验证集,如5、10..
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
elif mode == "test":#测试集,取所有数据,这是另一个文件的内容,把所有题目都做了
indices = [i for i in range(len(csv_data))]
数据标准化
X = torch.tensor(csv_data[indices, :93])
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
self.X = (X - X.mean(dim=0, keepdim=True)) / X.std(dim=0, keepdim=True)
self.mode = mode𝑋标准化=𝑋−𝜇𝜎X标准化=σX−μ
其中:
- 𝜇μ 是该特征的均值
- 𝜎σ 是该特征的标准差
- 标准化 = 对每个特征减去均值、除以标准差,使数据均值为0、标准差为1,提升模型训练稳定性和速度。
总体来看,CovidDataset 继承了 Dataset,类中一定包含下面三个函数:
- __init__ : 这是类实例化时最先运行的部分,负责把数据从硬盘读到内存里。
- __getitem__ : 根据索引返回单个样本。其中,测试集没有y,不用返回。
- __len__ : 简单直接,返回
len(self.X),即数据集中有多少条记录。
def __getitem__(self, item):
if self.mode == "test":
return self.X[item].float()
else:
return self.X[item].float(), self.Y[item].float()
def __len__(self):
return len(self.X) #有的数据没有y(三)模型函数
init:初始化
forward:计算
class myModel(nn.Module):
def __init__(self, inDim):
super(myModel, self).__init__()
self.fc1 = nn.Linear(inDim, 128) # 输入层 → 隐藏层(128 个神经元)
self.relu1 = nn.ReLU() # 激活函数,引入非线性
self.fc2 = nn.Linear(128, 1) # 隐藏层 → 输出层(1 个输出)
def forward(self, x):
x = self.fc1(x) #全连接层
x = self.relu1(x) #激活函数
x = self.fc2(x) #输出层
if len(x.size()) > 1:
x = x.squeeze(1) #如果维度大于1, 就去掉第二个维度
return x此处__init__函数中,只定义了两层全连接:
linear(inDim,128)-> Relu() -> linear(128,1)
文件中indim为93,即93维投影到128维,经过激活函数,将128维汇总计算出一个代表性的具体数值。 最终返回预测结果x,也就是y_pred.
调用部分看下一章节

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)