Deepstack论文阅读笔记
论文:https://arxiv.org/pdf/2406.04334
代码:https://github.com/MengLcool/DeepStack-VL
1、为什么要做这个研究(理论走向和目前缺陷) ?
之前做多模态融合时普遍是把图像的tokens直接输入到LLM的第一层,在图像分辨率比较高时大幅增加视觉token数目,导致计算量和显存占用直接爆炸。
2、他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
设计了deepStack的融合策略,把视觉token分为低分辨率和高分辨率两组,低分辨率的视觉token跟之前一样在LLM的第一层输入,而高分辨率的视觉token分层不同的组在LLM的后续不同层通过残差连接的方式加到中间视觉token中,从而不增加视觉token的数目,因此不怎么增加计算attension时的计算量和显存占用,但是融入了高分辨率信息。但是也有一些trick,1)高分辨率视觉token和LLM中间层中间层视觉token残差连接时需要保证有位置对应关系,避免信息扰乱。2)尽量在LLM的早期阶段融入高分辨率视觉token。
3、发现了什么(总结结果,补充和理论的关系)?
deepStack不怎么增加计算量,但是融入了更多的细节信息,因此对依赖细粒度信息的任务上变现更好。
摘要
之前的多模态大模型基本都是把所有的视觉tokens连成一个序列输入到LLM的第一层中,结构很简单增加了额外的tokens但是会导致计算量和内存占用急剧增加。本文设计了一种方法DeepStack,把高分辨率的视觉tokens逐层注入到LMM的不同层中,输入的tokens数目没有增加,计算量增加的非常少,就可以实现更好的性能,尤其是在需要细节分析的任务上,如ocr, 图表等。
1 引言
之前做多模态融合时一般是利用预训练视觉编码器(如CLIP)把图像转换成一系列视觉特征,然后再通过通过一个投影器把这些特征和language tokens对齐,一块输入到LLM中。
这种融合方式因为额外增加了visual tokens,会增加计算量和显存占用,尤其在高分辨率图像时非常显著。之前的也有一些工作尝试降低计算量和显存占用,比如空间分组(spatial pooling,即实际就是把vision tokens降采样), 或者沿特征维度连接视觉token,或者其他复杂的重采样方法(Q-Fomer,Perceiver, Abstractor),但这些方法无一例外都会牺牲细粒度信息。还有的方法是把图像裁剪多块生成更多视觉tokens来支持高分辨率图像输入,但计算量巨大。
上面说的这些方法都是把所有的图像tokens连到同一个维度,然后输入到LLM的第一层。本文提出的deepStack是把高分辨率图像的tokens分成不同的组(低分辨率图像保持原样,其token还是在llm的第一层输入),然后不同组的tokens在LLM不同layer通过残差链接加到视觉token中,这样实现不增加LLM输入的视觉token的数目的情况下把带有系列度信息的高分辨率视觉token注入到llm中。下图所示![[图片]](https://i-blog.csdnimg.cn/direct/71f587b5fbb745fba8fa584888ad4764.png)
把这种高分辨率视觉tokens的注入方式应用到LLaVA-1.5和LLaVA-Next [50]中进行验证,效果显著。
总结贡献:
- 提出DeepStack策略链接视觉和语言token,新策略不改变原有架构但是增加了LLM获得的视觉token数目。
- 基于上述连接策略提出DeepStack模型,大量实验证明在高分辨率任务上提升显著。
- 做了各类消融实验。
2 相关研究
LLM: BERT(encoder only),T5: encoder + decoder, GPT: decoder only,
Large Multi-modal Models (LMMs): CLIP, Flamingo, BLIP, BLIP-2, Instruct-BLIP. LLaVA (通过简单的投影器实现视觉预训练模型和语言预训练模型的对齐)。但上述这些对高分辨率任务不友好(如OCR)。还有方法利用混合专家MOE策略通过采用不同预训练视觉模型得到的tokens沿特征维度连接到连到一起,来解决高分辨率任务性能下降的问题。或者把高分辨率图像分成不同的patch分别提token输入到llm的第一层。
3 DeepStack
DeepStack把图像特征分成两组,一组是通过低分辨率图像得到的带有全局信息的视觉token,另外一组是通过高分辨率图像得到的带有细节信息的token。全局信息的视觉token直接在LLM的第一层输入,高分辨率的视觉token分层不同的组,每组token数目和全局信息token数目相同,然后在LLM的不同层通过残差连接加到视觉token上。
3.1 基础: Large Multimodal Model
Large Language Models (LLMs): LLM模型通常只有decoder,在大量无标注文本数据上进行自回归方式预训练的,预训练的策略就是根据输入预测下一个token的分布概率:![[图片]](https://i-blog.csdnimg.cn/direct/e9e5ae68553d4759af772fc301774ca7.png)
Language Multi-modal Models (LMMs): 预训练策略基本同LLM,但是在文本token输入的基础上增加了图像token的输入:![[图片]](https://i-blog.csdnimg.cn/direct/d95b6264de584a22a6caa8a9594e874c.png)
图像分词器(Image Tokenization):即如何把图像编码为视觉token。 一般是用预训练的视觉编码器来做,如CLIP, 然后把再用一个连接器把这些编码器出来的token转成和LLM的token同一语义的token。连接器有两类,第一类是投影器,一般就是MLP,直接把视觉encoder输出的token输入到MLP中转为LLM token, token数目和原始encoder输出的token数目相同。另外一类叫做感知重采样器(perceiver resamplers),通过设置固定数目的query和encoder输出的视觉token做交叉注意力,实现把视觉token转换为固定数目的token输入到LLM中,一般用于把密集的视觉token转换为稀疏的图像token。但是重采样的方法在空间推理任务中会有幻觉问题,因为交叉注意力会模糊局部细节和精确位置关系。本文主要专注在投影器的方法来做改进。
3.2 使用DeepStack提升图像分词效果
这一块专注在怎么把视觉编码器得到的视觉tokens更有效的喂给LLM(基于投影器)。
扩增视觉token数目或特征维度的方法。直接通过把图像提升分辨率后分成不同块分别进编码器得到视觉token,然后把视觉token连到一起,这种会直接增加tokens数目。或者通过不同的视觉专家模型得到不同的视觉token,然后把这些token沿特征维度concat到一起,这种不增加token数目,但是会增加token特征的维度。
DeepStack策略用于LLM。如下左图所示,先把输入图像按原高宽比上采样,上采样的图像和原输入图像分别进同一个视觉编码器获得高分辨率和低分辨率的视觉token。低分辨率的视觉token在LLM的第一层喂进去,而高分辨率的视觉token在llm的不同层以残差链接的方式喂进去。喂高分辨率视觉token之前需要先把他们按照空间膨胀的方式分组,保证每组中的token和低分辨率输入图像视觉token数目一致且有位置对应关系,即残差连接的高分辨率视觉token对应图像中的实际位置需要位于低分辨率token对应区域内。![[图片]](https://i-blog.csdnimg.cn/direct/6e5f6c8601c4485b83981c0bd1fd750d.png)
![[图片]](https://i-blog.csdnimg.cn/direct/48de86a5b4a04b81b18a87484651c88f.png)
DeepStack用于视觉编码器(ViT). 如上右图所示,低分辨率图和高分辨率图先做Patch Embedding, 高分辨率图得到的patch是大于低分辨率图的,然后低分辨率图的emb先进ViT的第一层,高分辨率图的patch emb再进后续层。
分组策略伪代码:![[图片]](https://i-blog.csdnimg.cn/direct/f8889e7f0c844b8dbdc1b6a0b846340d.png)
和其他的视觉token增强策略对比。之前的视觉token增强策略主要就两类,一种是增加token的数目(Sequence Concatenation),另外一种是增加token的特征维度(Dimension Concatenation)。前者会导致更多的视觉token输入到LLM,后者则需要把增强的视觉token再送到投影器中降维度,这个过程大概就相当于不同的特征经变换后直接相加。
deepStack的策略下图所示,在decoder的早期层逐block融入高分辨率视觉token,后续的layer保持不变。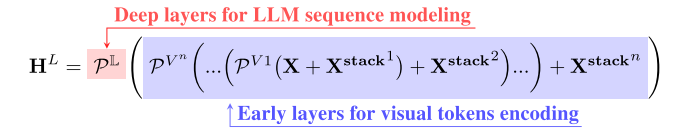
4 实验
4.1 实现细节
先预训练(PT)再监督微调(SFT),使用CLIP-large-336作为默认图像编码器,获得高分辨率图像token时,先把原图上采样,再crop成不重叠的不同的块,每一块单独进clip获取token,最后再把不同块的token拼接到一起作为整张高分辨率图的token.
预训练数据:LCS-558K,和LLaVA-1.5保持一致。
微调数据集:LLaVA-mixed-665k。
训练设置:在预训练阶段只训练投影器,在监督微调阶段,所有参数(图像编码器、投影器、LLM)都进行微调。也做了一组冻结图像编码器的实验来比较。
4.2 实验结果
主要是在一些需要高分辨率输入的任务上做比较:ChartVQA [54], DocVQA [56], InfoVQA [55], MultiDocVQA [72], TextVQA [69],
通用VQA和LMM等任务:VQAv2 [23] and GQA,SEED [40], POPE [46], MMMU [83], and MM-Vet![[图片]](https://i-blog.csdnimg.cn/direct/0345bb154a9643b6828edc10b97d5036.png)
文本导向的任务:ChartQA [54], DocVQA [56], InfoVQA [55], Multi- DocVQA [72], and TextVQA [69]. 这些任务都有高分辨率图,且需要模型捕获细节信息来回答问题。不增加token数目的情况下效果更好。![[图片]](https://i-blog.csdnimg.cn/direct/11b3c7a79cec4751920b100d1fb13494.png)
视频QA任务零样本测试:EgoSchema [52] and Next-QA [78], and MSVD-QA [10, 79] and ActivityNet-QA![[图片]](https://i-blog.csdnimg.cn/direct/0f3051ba490242049dd00d76b904037b.png)
4.3 消融实验
在deocder的早期阶段处理视觉token效果更好。之前都是在decoder的第一层插入视觉token,实验证明这种方式确实最好,下图(a)所示。如果固定低分辨率的视觉token在llm第一层插入,而在不同间隔的后续层插入高分辨率视觉token,下图(b)表明间隔大小影响不大。下图(c)表明在选择4层LLM的layer插入高分辨率视觉token效果最好。![[图片]](https://i-blog.csdnimg.cn/direct/9d09897593e5417294132d47da0a1a1c.png)
DeepStack也可以增强ViT的效果。![[图片]](https://i-blog.csdnimg.cn/direct/0703d2063e1047f58a727fb409e19d5a.png)
空间连续的采样方式更好。即高分辨率视觉token和低分辨率视觉token残差连接时,高分辨率视觉token在图像中的位置需要对应到低分辨率视觉token所在的区域内,这样才不会扰乱原有的token的语义信息。![[图片]](https://i-blog.csdnimg.cn/direct/4babeb6126d54079acc2cdb745d71b4b.png)
![[图片]](https://i-blog.csdnimg.cn/direct/240d60d4155249e4b06a0da69e6af61a.png)
并不是残差连接增强了模型的性能(并未提供额外的信息),而是高分辨率的视觉token导致性能提升。![[图片]](https://i-blog.csdnimg.cn/direct/e9f3fee234624ca6b4fb9aa4ea5d2988.png)
deepStack不增加计算量的同时带来性能提升。![[图片]](https://i-blog.csdnimg.cn/direct/703d6149244e489b868a23fdf85fe1b5.png)
可视化![[图片]](https://i-blog.csdnimg.cn/direct/2da58b92c36f4ca38872ebcb3a34f672.png)
微调叠加了deepStack的视觉编码器后效果更好。但是微调不加deepStack的视觉编码器反倒可能会在各种vqa任务上性能下降。![[图片]](https://i-blog.csdnimg.cn/direct/e2d3cd1cc32d4e009caa6b0a7c24c3cf.png)
5 结论
deepStack应用范围广,不咋加计算量,在高分辨率任务上表现好。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)