【必看收藏】10大Agent设计模式实战指南:从ReAct到LATS,一文掌握AI智能体架构全貌
本文系统介绍了10种AI智能体设计模式,包括ReAct、Reflection、Reflexion、LATS等,针对不同应用场景提供结构化解决方案。这些模式将复杂智能体行为分解为清晰阶段,通过状态管理、条件逻辑、工具集成和质量控制机制,解决结果不一致、调试困难等开发痛点。文章详细解析了ReAct模式的原理和实现示例,展示了推理-行动的循环过程。这些设计模式为开发者构建高效可靠的AI系统提供了可复用架
本文全面介绍10种AI智能体设计模式,包括ReAct(推理-行动循环)、Reflection(生成-批判-优化)、Reflexion(从失败中学习)、LATS(语言代理树搜索)等。每种模式均详细解析其原理、适用场景、优势局限及代码实现,帮助开发者构建高效、可靠的AI智能体系统。从简单意图识别到复杂多任务规划,为不同场景提供结构化解决方案,是AI智能体开发者的必备参考资料。
总览
Agent Patterns Documentation — Agent Patterns 0.2.0 documentation
Agent设计模式是用于构建 Agent OR Workflow的可复用架构蓝图,正如软件工程中的设计模式为常见问题提供经过验证的解决方案一样,Agent设计模式为常见的 AI 智能体开发提供了结构化的方法以及底层设计方案。
构建 AI 智能体时,开发者常常面临:
- 结果不一致:单一提示方法在处理复杂任务时不可靠;
- 难以调试:整体式提示链难以排查问题;
- 复用性有限:解决方案难以跨项目迁移;
- 不可预测的行为:缺乏结构时,智能体的表现会不一致;
Agent的设计模式是一种结构化工作流,它将复杂的智能体行为分解为多个流程和阶段:
- 清晰阶段:具有特定职责的明确阶段
- 状态管理:追踪进度和中间结果
- 条件逻辑:用于路由和迭代的决策点
- 工具集成:外部交互的结构化方法
- 质量控制:内置验证与优化机制
常见类型:
与外部系统交互的Agent:适用场景:需要进行搜索、计算、查询 API 或访问外部数据
- ReAct(推理-行动):推理行动方案,使用工具执行;
- LLM Compiler:将工具调用编译为可执行代码,并行执行工具;
- REWOO(Reasoning without Observation ):将规划与工具执行分离以提高效率;
通过迭代改进输出的Agent(不断地优化输出效果,重视质量):适用场景:输出质量至关重要时(写作、编程、设计)
- Reflection(反思):生成、评估、优化;侧重于边写边改的自省机制,把当前输出变好,更注重质量主导型产出。
- Reflexion(反思加强版):从多次尝试的失败中学习;把失败经验固化为可复用记忆的学习机制,避免下次再犯,更注重失败不可接受,以稳定主导型产出。在最终的形态上,是Reflection的加强版。
- LATS(Language Agent Tree Search):探索多种解决方案路径,对可能的推理路径进行探索,不同于遵循单一解决方案链,LATS 同时探索多条路径,评估这些路径,并利用树搜索技术寻找最优解。
分解复杂任务的智能体:适用场景:任务包含多个逻辑步骤或需要策略性思考
- Plan & Solve(计划并解决): 制定计划,按顺序执行;
- Self-Discovery(自我发现):动态选择推理策略,边探索边发现”,偏向创造性、灵活、适应性强的任务。
整合多元观点的智能体:适用场景:需要全面、周详的分析
- STORM:多视角研究与综合,适合学术领域、深度分析,和deepresearch属于同源异构的两种深度研究型 AI 系统。重视结果,但成本极高,速度极慢。
- ReAct
========
LLM Agent 第一文,发表于2022年10月,现在看起来特别简单,但当时 ChatGPT还没有面世,能提出让LLM学会使用工具,具有一定的开创性:
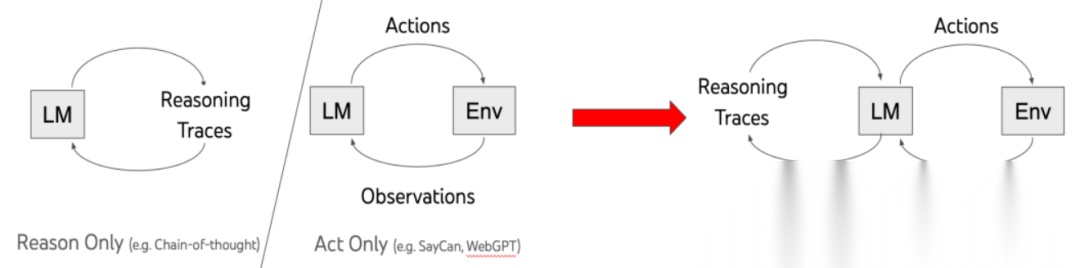
ReAct原理很简单,没有ReAct之前,Reasoning和Act是分割开来的:
举个例子,你让孩子帮忙去厨房里拿一个瓶胡椒粉,告诉它一步步来(COT提示词策略):
- Action1:先看看台面上有没有
- Observation1:台面上没有胡椒粉,执行下一步
- Action2:再拉开灶台底下抽屉里看看
- Observation2:抽屉里有胡椒粉
- Action3:把胡椒粉拿出来
人类智能的一项能力就是Actions with verbal reasoning,即每次执行行动后都有一个"碎碎念(Observaton":我现在做了啥,是不是已经达到了目的,这相当于让Agent能够维持短期记忆。
1.1 典型示例
langchain:
importjson
fromdatetimeimportdatetime
fromlangchain.agentsimportcreate_agent
fromcommon.llm_utilsimportget_free_llm_model
defget_weather(city: str, search_datetime: str) ->str:
"""Get weather for a given city.
Args:
city: 要检索的城市
search_datetime: 要检查的日期时间,格式为字符串,例如2025-12-16 21:53
"""
returnf"{city}{search_datetime}是晴天"
defget_current_datetime() ->str:
"""Get the current datetime"""
returndatetime.now().strftime("%Y年%m月%d日 %H:%M")
agent=create_agent(
model=get_free_llm_model(),
tools=[get_weather, get_current_datetime],
system_prompt="You are a helpful assistant",
)
res=agent.invoke(
input={"messages": [{"role": "user", "content": "北京明天的天气怎么样?"}]}
)
messages=res.get("messages", [])
formessageinmessages:
print(json.dumps(message.to_json(), ensure_ascii=False))
{"type": "human", "content": "北京明天的天气怎么样?"}
{"type": "ai", "content": "我需要先获取当前的日期时间,然后查询北京明天的天气情况。", "tool_calls": [
{"name": "get_current_datetime", "args": {}}
]}
{"type": "tool", "content": "2026年01月18日 22:32", "tool_call_id": "1"}
{"type": "ai", "content": "。", "tool_calls": [
{"name": "get_weather", "args": {"city": "北京","search_datetime": "2026-01-19"}}
]}
{"type": "tool", "content": "北京2026-01-19是晴天", "tool_call_id": "2"}
{"type": "ai", "content": "北京明天是晴天。"}
- 用户输入北京天气怎么样?触发 Agent;
- AI 决策(Reason + Act)
- 模型先思考(Reason):我需要先获取当前的日期时间,然后查询北京明天的天气情况。
- 模型做出行动(Act):调用工具
get_current_datetime
- 工具执行
- 工具执行
get_current_datetime() - 返回结果(Observation):
2026年01月18日 22:32
- AI 决策(Reason + Act)
- 模型先思考(Reason):今天是 2026-01-18,那么明天是 2026-01-19,我需要查询北京2026-01-19的天气。
- 模型做出行动(Act):调用工具
get_weather(city="北京", search_datetime="2026-01-19")
- 工具执行
- 工具执行
get_weather(city="北京", search_datetime="2026-01-19") - 返回结果(Observation):
北京2026-01-19是晴天
- AI 输出最终回答
- 模型先思考(Reason):我已经得到了北京明天的天气信息,可以回答用户。
- 模型生成输出(Act/Answer):
北京明天是晴天。
langgraph:
## 第一步,引入模型和工具
# 引入模型
model=get_llm_model(model_type=ModelTypes.deepseek_chat)
# 定义一下使用到的工具
@tool
defmultiply(a: int, b: int) ->int:
"""Multiply `a` and `b`.
Args:
a: First int
b: Second int
"""
returna*b
@tool
defadd(a: int, b: int) ->int:
"""Adds `a` and `b`.
Args:
a: First int
b: Second int
"""
returna+b
@tool
defdivide(a: int, b: int) ->float:
"""Divide `a` and `b`.
Args:
a: First int
b: Second int
"""
returna/b
# Augment the LLM with tools
tools= [add, multiply, divide]
tools_by_name= {tool.name: toolfortoolintools}
# 模型和工具绑定
model_with_tools=model.bind_tools(tools)
# 第二步,引入模型和工具 定义状态
classMessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add] # 消息列表,表示格式是list[AnyMessage],但是来数据了,是add操作。
llm_calls: int # 标记模型调用次数
# 第三步,定义模型节点,返回的是state值
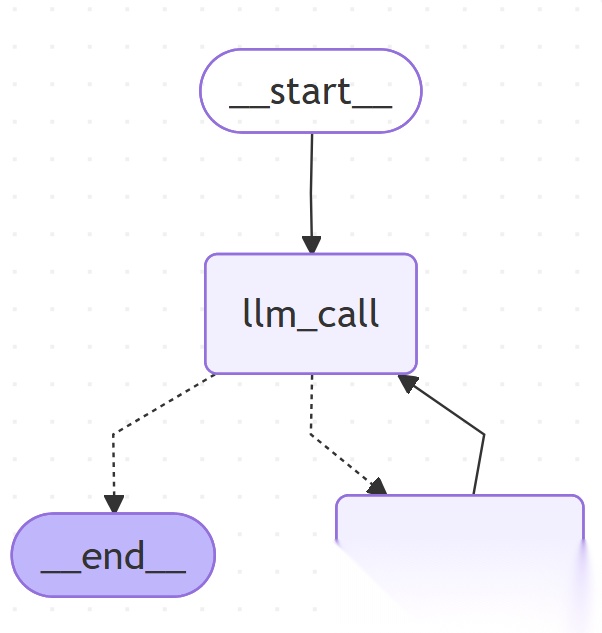
defllm_call(state: dict):
"""LLM 决定是否调用工具"""
return {
# 这个好像要和MessagesState结构完全对应上才行
"messages": [
# 使用模型和工具绑定后的对象,执行问答
model_with_tools.invoke(
[
SystemMessage(
content="你是一个有用的助手,负责对一组输入的数字,进行算术运算。"
)
] # 这个相当于sys_prompt
+state["messages"] # 历史会话
)
],
"llm_calls": state.get('llm_calls', 0) +1
}
# 第四步,定义工具节点
# 工具节点用于调用工具并返回结果
deftool_node(state: dict):
"""Performs the tool call"""
result= []
# 获取最后一个消息(也就是上一次llm问答的执行结果),里边的tool_calls存放了本次要执行的方法以及参数
fortool_callinstate["messages"][-1].tool_calls:
# 在工具列表名称里,通过方法名,找到对应的工具
tool=tools_by_name[tool_call["name"]]
# 执行工具
observation=tool.invoke(tool_call["args"])
# 将执行结果放到result里。
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
# 返回工具的执行结果
return {"messages": result}
# 第五步, 定义结束逻辑,返回的是下一个节点要执行的东西
defshould_continue(state: MessagesState) ->Literal["tool_node", END]:
"""根据 LLM 是否进行了工具调用,决定我们是否应该继续循环或停止"""
# 获取最后一次消息回复
last_message=state["messages"][-1]
# 如果最后有tool_calls
iflast_message.tool_calls:
# 呢么就要继续执行tool
return"tool_node"
# 否则表示结束了
returnEND
# 第六步,构建一个agent
# 1. 创建一个状态图
agent_builder=StateGraph(MessagesState)
# 2. 增加节点
agent_builder.add_node("llm_call", llm_call)
# 3. 增加节点
agent_builder.add_node("tool_node", tool_node)
# 4. 添加边以连接节点,入口是START,出口是llm_call
agent_builder.add_edge(START, "llm_call")
# 5. add_conditional_edges,入口是llm_call
agent_builder.add_conditional_edges(
source="llm_call",
path=should_continue,
path_map={
"tool_node": "tool_node",
END: END
}
)
agent_builder.add_edge("tool_node", "llm_call")
# Compile the agent
agent=agent_builder.compile()
print(agent.get_graph(xray=True).draw_mermaid())
messages= [HumanMessage(content="Add 3 and 4.")]
messages=agent.invoke(input={"messages": messages})
forminmessages["messages"]:
m.pretty_print()
1.2 优势与局限性
优势:
- 弥补模型自身缺陷:模型本身无法获取外部数据或执行操作,ReAct + function_call 可以巧妙弥补,同时缓解幻觉问题。
- 流程自动化、开发高效:开发者只需实现工具,模型会自主决定下一步思考与行动,整个决策流程由模型自我治理。
- 多步推理能力强:通过思考—执行—反思循环,模型能够处理复杂任务并逐步调整策略。
局限性:
- 依赖模型能力:模型是 Agent 的中枢,能力偏低会直接影响结果;反思能力也是基于模型自身,逻辑错误会被重复。
- 动作/工具管理复杂:功能多的 Agent 容易出现 function_call 爆炸,增加系统复杂性。
- 上下文依赖高:每一步都需要记录前面推理和动作,长任务容易导致上下文超出限制、信息丢失、注意力涣散,进而导致任务执行失败。
什么是function_call爆炸:
- 如果一个Agent,拥有几十个功能,呢么就是对应几十个tool,这对模型来说已经很多了,模型可能很难根据用户的问题,选中执行哪些tool;
- 可能一个agent功能不多,但是最终逻辑复杂,几个tool之间有关联、顺序作用,模型每次都要考虑调用哪个函数、哪一组合最合适,随着步骤增加,可能形成指数级组合。例如 5 个函数,每步模型都可能调用任意 1 个,2 步后就是 5×5=25种可能组合,3 步就是 125 种,依次指数增长,最终可能导致上下文超长。
为什么容易发生:
- 多工具 Agent:可选动作多,组合复杂;
- 任务不确定性高:模型无法完全判断哪一步最优,于是尝试多种函数调用策略。
- 缺乏调用策略约束:没有规则限制调用次数或顺序,模型可能陷入循环。
使用 ReAct 的建议:
- 保持 Agent 简单
- Agent 尽量颗粒度小,职责明确,不要追求功能面面俱到。
- 复杂功能可以拆分成多个独立 Agent 或工具组合。
- 工具边界明确
- 每个工具(tool)功能单一、清晰,避免重复或模糊。
- 模型能够明确判断何时调用哪个工具,减少误调用和冗余调用。
- 对模型能力有预判
- ReAct 依赖模型的推理能力,如果模型能力有限,应简化任务或降低工具复杂度。
- 可通过控制工具数量、限制调用次数或设计高层抽象接口来适配模型能力。
- IntentRecognition
====================
意图识别(Intent Recognition)是自然语言处理中的一个核心任务,旨在理解用户输入背后的真实意图,并将其映射到预定义的意图类别中。
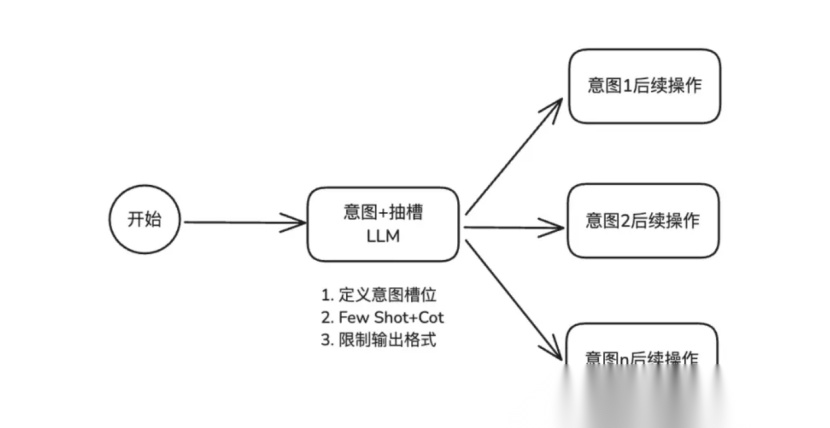
实现方式:
# 意图识别的节点
defclassify_intent(state: EmailAgentState) ->Command[
Literal["search_documentation", "human_review", "draft_response", "bug_tracking"]]:
"""使用 LLM 对电子邮件意图和紧急情况进行分类,然后相应地发送。"""
# 创建结构化 LLM,返回 EmailClassification 字典
structured_llm=model.with_structured_output(EmailClassification)
# 按需格式化提示,不存储在状态中,提示词
classification_prompt=f"""
分析这封客户电子邮件并进行分类:
Email: {state['email_content']}
From: {state['sender_email']}
提供包括意图、紧迫性、主题和总结在内的分类。
解析出来如下信息:intent、urgency、topic、summary
"""
# 结构化输出,得到了一个结果
classification=structured_llm.invoke(classification_prompt)
# 基于分类确定下一个节点
ifclassification['intent'] =='billing'orclassification['urgency'] =='critical':
goto="human_review"
elifclassification['intent'] in ['question', 'feature']:
goto="search_documentation"
elifclassification['intent'] =='bug':
goto="bug_tracking"
else:
goto="draft_response"
# 更新state的值
returnCommand(
update={"classification": classification},
goto=goto
)
意图识别更多属于 “信息抽取 + 模型决策” 的设计思想,而不是纯推理或执行循环,实际上就是 ReAct / Plan-and-Solve 中“动作选择”的前置环节:先理解意图,再决定下一步动作,整个基本流程结束。
2.1 优势与局限性
优势:
- 快速、轻量
- 对于单轮、单意图任务,意图识别非常高效,模型只需要判断类别即可,不必生成复杂输出。
- 结构化输出明确
- 输出意图类别和槽位(Slot),天然可映射到工具调用、函数执行或数据库查询。
- 适合构建任务型对话系统、问答系统、智能助手。
- 易于开发和集成
- 可以基于规则、传统 ML、深度学习或大语言模型实现,开发门槛低。
- 与工具、API、动作系统结合简单,易于快速落地。
- 可解释性较强
- 意图分类本身明确,可以清楚知道模型“理解”为哪一类任务,好理解,好排查,处理起来非常线性,和传统的编程几乎一样,只是在if\else判断之前,添加了大模型。
局限性
- 单意图假设
- 系统通常假设每条输入只对应一个意图。
- 对一句话内多意图或复杂任务支持不佳,容易导致部分意图被忽略。
- 边界模糊的意图
-
意图 A:查看订单详情
-
意图 B:查看物流编号
-
用户输入可能被合理解释为多种意图,例如:
“帮我看看XXX订单”
-
单轮分类模型难以准确判断,结果容易波动。
- 多轮对话支持弱
- 上一轮问答和本轮问答的意图边界不明确,系统可能无法判断当前输入是否是上一轮意图的延续。
- 导致同一句话在不同上下文下走不同逻辑,输出结果大相径庭。
大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

- 流程固定且线性
- 意图识别类 Agent 的整体流程偏固定,适合线性、明确的任务流程。
- 对于开放式、多意图、长尾任务或逻辑跳转场景,灵活性有限。
- LLM Compiler
===============
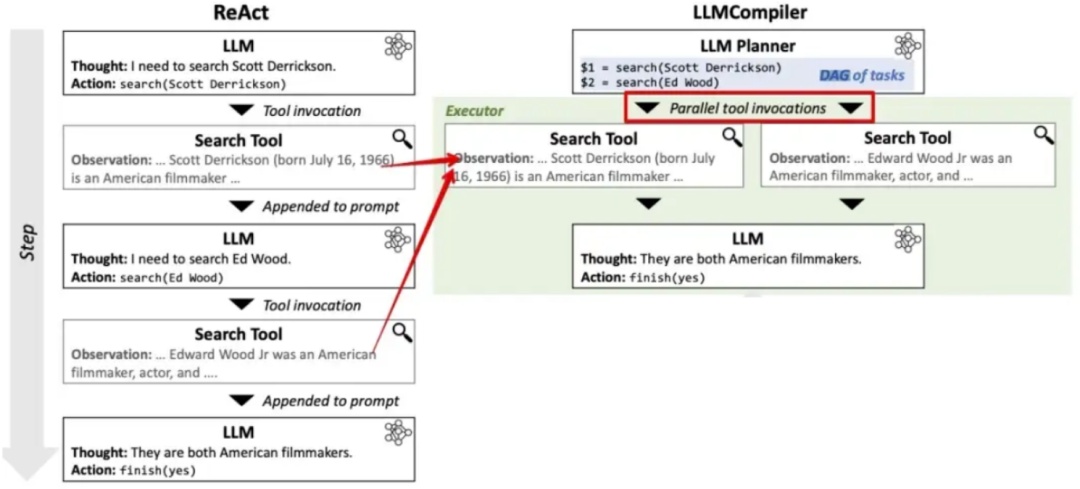
直白点讲,就是通过并行Function call来提高效率,比如用户提问“今日上海和杭州的平均气温差多少”,planner并行搜索上海和杭州的天气情况,最后合并即可。
设计思路(LLM Compiler 模式)
- Planner(规划器):将用户问题拆解为子任务,例如“获取上海平均气温”、“获取杭州平均气温”。
- Executor(执行器):并行调用工具(如
get_avg_temp(city))执行子任务。 - Joiner(连接器):汇总结果,生成最终自然语言回答。
代码示例:
importos
fromtypingimportList, Dict, Any
fromlangchain_core.toolsimporttool
fromlangchain_openaiimportChatOpenAI
fromlangchain_core.promptsimportChatPromptTemplate
fromlanggraph.graphimportStateGraph, END
fromtyping_extensionsimportTypedDict
# -----------------------------
# 1. 工具定义(模拟真实API)
# -----------------------------
@tool
defget_avg_temp(city: str) ->str:
"""获取指定城市的年平均气温(模拟数据)"""
data= {
"上海": "17.1℃",
"杭州": "16.5℃"
}
returndata.get(city, "未知")
tools= [get_avg_temp]
tool_map= {tool.name: toolfortoolintools}
# -----------------------------
# 2. 状态定义
# -----------------------------
classGraphState(TypedDict):
question: str
plan: List[str] # 子任务列表,如 ["获取上海平均气温", "获取杭州平均气温"]
results: Dict[str, str] # 工具调用结果,如 {"上海": "17.1℃"}
final_answer: str
# -----------------------------
# 3. 节点函数
# -----------------------------
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0)
# --- Planner ---
defplanner(state: GraphState) ->GraphState:
prompt=ChatPromptTemplate.from_messages([
("system", "你是一个任务规划器。请将用户问题分解为可由工具执行的明确子任务。每个子任务必须包含城市名。"),
("user", "问题:{question}")
])
chain=prompt|llm
response=chain.invoke({"question": state["question"]})
# 简单解析:假设模型输出格式为“1. 获取上海平均气温\n2. 获取杭州平均气温”
lines=response.content.strip().split('\n')
plan= []
forlineinlines:
if"上海"inline:
plan.append("上海")
elif"杭州"inline:
plan.append("杭州")
return {"plan": plan}
# --- Executor (并行调用工具) ---
defexecutor(state: GraphState) ->GraphState:
results= {}
forcityinstate["plan"]:
res=get_avg_temp.invoke({"city": city})
results[city] =res
return {"results": results}
# --- Joiner ---
defjoiner(state: GraphState) ->GraphState:
results=state["results"]
parts= [f"{city}的年平均气温是{temp}"forcity, tempinresults.items()]
final=";".join(parts) +"。"
return {"final_answer": final}
# -----------------------------
# 4. 构建图
# -----------------------------
workflow=StateGraph(GraphState)
workflow.add_node("planner", planner)
workflow.add_node("executor", executor)
workflow.add_node("joiner", joiner)
workflow.set_entry_point("planner")
workflow.add_edge("planner", "executor")
workflow.add_edge("executor", "joiner")
workflow.add_edge("joiner", END)
app=workflow.compile()
# -----------------------------
# 5. 运行示例
# -----------------------------
if__name__=="__main__":
question="上海和杭州的平均气温是多少?"
inputs= {"question": question, "plan": [], "results": {}, "final_answer": ""}
result=app.invoke(inputs)
print("最终答案:", result["final_answer"])
- REWOO
========
REWOO(Reason Without Observation)无观察推理,将规划与执行分离,其方式是让一个 Worker LLM 创建一个包含工具结果占位符的完整计划,然后执行所有工具,最后整合实际结果。这最大限度地减少了昂贵的 LLM 调用,使其具有很高的成本效益。
ReAct
- 核心是“Reasoning + Acting + Observation”循环。
- 推理(Reasoning):模型先分析任务、计划下一步动作。
- 执行(Acting):调用工具、函数或者执行某个操作。
- 观察(Observation):把工具返回的结果输入回模型,用来决定下一步。
- ReAct 的关键是每一步都有反馈循环,模型不断调整策略。适合复杂、多步骤、动态环境的任务。
REWOO
- 基本流程是“推理 + 执行”,少了Observation环节。
- 模型生成动作或调用函数,然后直接执行。
- 不会把执行结果反馈回模型用于下一步推理(或者反馈非常有限)。
- 适合单步或者明确目标的任务,任务链条短、反馈不重要。
- 可以理解为 ReAct 的简化版,但严格来说,它不是完全的“循环式 agent”,而是“一次性推理执行”的模式。
**最佳适用场景:**具有可预测依赖关系的、高性价比的多工具工作流。
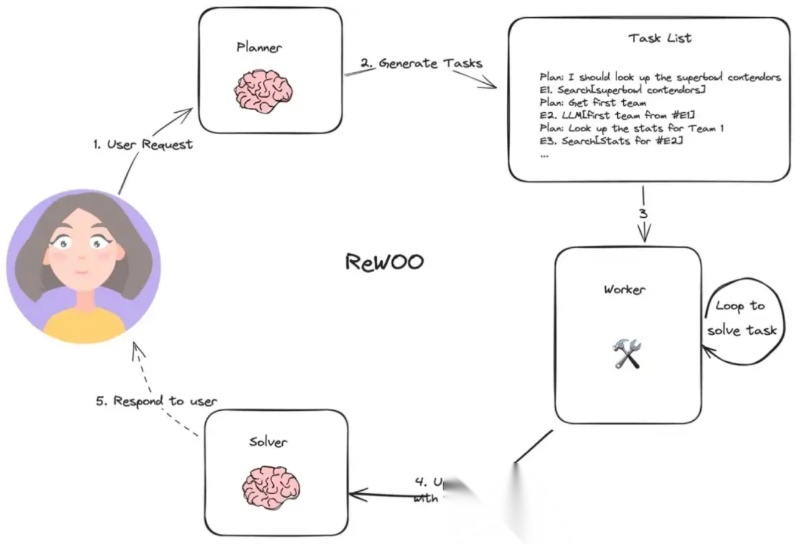
REWOO 的核心思想:
- 先规划(Plan) 所需的工具调用(不立即执行);
- 再一次性执行(Execute) 所有工具;
- 最后推理(Solve) 得出最终答案。
fromlangchain_openaiimportChatOpenAI
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_core.toolsimporttool
fromlanggraph.graphimportStateGraph, END
fromtypingimportTypedDict, List, Any
importjson
# ----------------------------
# 1. 定义状态(State)
# ----------------------------
classGraphState(TypedDict):
question: str
plan: str # 规划文本(如 "获取上海平均气温;获取杭州平均气温")
tool_calls: List[dict] # 解析后的工具调用列表,如 [{"tool": "get_avg_temp", "args": {"city": "上海"}}]
observations: dict # 工具执行结果,如 {"上海": 19.4, "杭州": 19.5}
final_answer: str
# ----------------------------
# 2. 定义工具(Tool)
# ----------------------------
@tool
defget_avg_temp(city: str) ->float:
"""获取指定城市的年平均气温(单位:℃)"""
# 模拟真实数据(来自知识库:2025年数据)
data= {
"上海": 19.4,
"杭州": 19.5,
"南京": 18.8
}
returndata.get(city, None)
tools= [get_avg_temp]
tool_map= {tool.name: toolfortoolintools}
# ----------------------------
# 3. 节点函数:Plan(规划)
# ----------------------------
llm=ChatOpenAI(model="gpt-4o", temperature=0)
plan_prompt=ChatPromptTemplate.from_messages([
("system", "你是一个规划器。请根据用户问题,生成一个清晰的执行计划,列出需要调用的工具及其参数。\n"
"格式:每行一个工具调用,形式为 `工具名(参数)`,例如:get_avg_temp(上海)"),
("user", "{question}")
])
defplan_node(state: GraphState) ->GraphState:
chain=plan_prompt|llm
response=chain.invoke({"question": state["question"]})
plan_text=response.content.strip()
state["plan"] =plan_text
returnstate
# ----------------------------
# 4. 节点函数:Parse Plan → Tool Calls
# ----------------------------
defparse_plan_to_tool_calls(state: GraphState) ->GraphState:
lines=state["plan"].split("\n")
calls= []
forlineinlines:
line=line.strip()
ifnotline:
continue
# 简单解析 get_avg_temp(上海) → {"tool": "get_avg_temp", "args": {"city": "上海"}}
ifline.startswith("get_avg_temp(") andline.endswith(")"):
city=line[len("get_avg_temp("):-1].strip('\"\' ')
calls.append({"tool": "get_avg_temp", "args": {"city": city}})
state["tool_calls"] =calls
returnstate
# ----------------------------
# 5. 节点函数:Execute All Tools(一次性执行)
# ----------------------------
defexecute_tools_node(state: GraphState) ->GraphState:
results= {}
forcallinstate["tool_calls"]:
tool_name=call["tool"]
args=call["args"]
result=tool_map[tool_name].invoke(args)
city=args["city"]
results[city] =result
state["observations"] =results
returnstate
# ----------------------------
# 6. 节点函数:Solve(生成最终答案)
# ----------------------------
solve_prompt=ChatPromptTemplate.from_messages([
("system", "你是一个解答器。根据以下信息回答原始问题:\n"
"问题:{question}\n"
"观测数据:{observations}"),
("user", "请用简洁中文回答。")
])
defsolve_node(state: GraphState) ->GraphState:
obs_str=json.dumps(state["observations"], ensure_ascii=False)
chain=solve_prompt|llm
response=chain.invoke({
"question": state["question"],
"observations": obs_str
})
state["final_answer"] =response.content.strip()
returnstate
# ----------------------------
# 7. 构建 LangGraph
# ----------------------------
workflow=StateGraph(GraphState)
workflow.add_node("plan", plan_node)
workflow.add_node("parse", parse_plan_to_tool_calls)
workflow.add_node("execute", execute_tools_node)
workflow.add_node("solve", solve_node)
workflow.set_entry_point("plan")
workflow.add_edge("plan", "parse")
workflow.add_edge("parse", "execute")
workflow.add_edge("execute", "solve")
workflow.add_edge("solve", END)
app=workflow.compile()
# ----------------------------
# 8. 运行示例
# ----------------------------
if__name__=="__main__":
result=app.invoke({
"question": "上海和杭州的平均气温是多少?",
"plan": "",
"tool_calls": [],
"observations": {},
"final_answer": ""
})
print("\最终答案:")
print(result["final_answer"])
- Reflection
=============
Reflection模式实现了生成-批判-优化的循环流程,Agent先创建初始响应,随后评估其质量,并基于自我批判进行迭代改进。适合创造性、开放性任务,而不是固定流程任务。
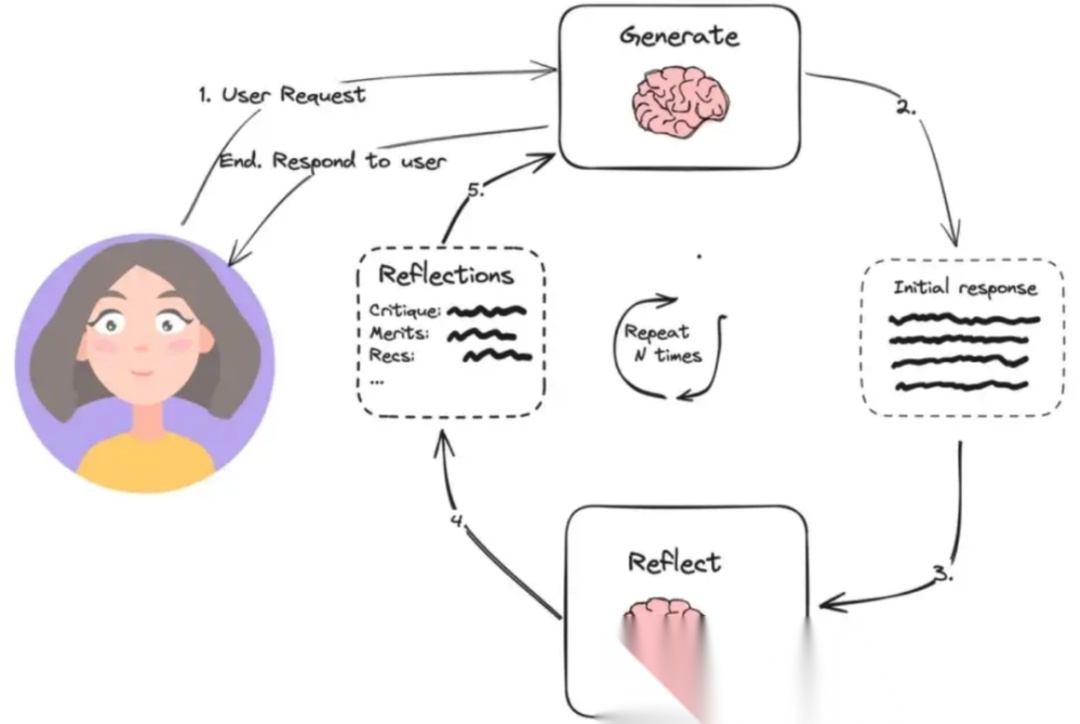
Reflection 模式通常包含以下角色:
- Generator(生成器)
- 负责执行核心任务,产生初步输出(文本、决策、计划等)。
- 类似传统 Agent 的执行器,但只负责第一轮产出,不负责优化。
- Evaluator / Critic(评估器/批判者)
-
正确性(事实、逻辑)
-
完整性(是否覆盖需求)
-
可读性/质量(语言、格式、可执行性)
-
对 Generator 的输出进行评估。
-
可以判断:
-
输出通常是反馈、改进意见或评分。
- Refiner / Optimizer(优化器/修改器)
- 根据评估器的反馈,调整或重写 Generator 的输出。
- 可以迭代多轮,形成“生成 → 反思 → 修正”的闭环。
fromtypingimportTypedDict, List
fromlangchain_openaiimportChatOpenAI
fromlangchain.promptsimportChatPromptTemplate
fromlangchain_core.output_parsersimportStrOutputParser
fromlanggraph.graphimportStateGraph, END
# ---- 定义状态 ----
classBlogState(TypedDict):
draft: str # 当前草稿
critique: str # 对草稿的批评/反思
revision_number: int # 已修订次数
max_revisions: int # 最大修订次数
# ---- 初始化 LLM ----
llm=ChatOpenAI(model="gpt-4o", temperature=0.7)
# ---- 步骤1:生成初稿 ----
draft_prompt=ChatPromptPromptTemplate.from_messages([
("system", "你是一位科技伦理博主,请撰写一篇关于 AI 伦理挑战的博客文章草稿。要求:800字左右,结构清晰,包含引言、主要问题、案例和结语。"),
("user", "主题:AI 伦理")
])
draft_chain=draft_prompt|llm|StrOutputParser()
defgenerate_draft(state: BlogState) ->dict:
draft=draft_chain.invoke({})
return {"draft": draft, "revision_number": 0}
# ---- 步骤2:反思/批评草稿 ----
critique_prompt=ChatPromptTemplate.from_messages([
("system", "你是一位资深编辑,请对以下博客草稿进行批判性评估。指出其不足之处,例如:论点是否片面?是否缺乏代表性案例?是否存在逻辑漏洞或伦理盲区?请具体说明。"),
("user", "{draft}")
])
critique_chain=critique_prompt|llm|StrOutputParser()
defcritique_draft(state: BlogState) ->dict:
critique=critique_chain.invoke({"draft": state["draft"]})
return {"critique": critique}
# ---- 步骤3:根据批评修订草稿 ----
revise_prompt=ChatPromptTemplate.from_messages([
("system", "你是一位负责任的 AI 伦理作者。请根据以下编辑意见,修订你的博客草稿。保持原意但提升质量。"),
("user", "原草稿:{draft}\n\n编辑意见:{critique}")
])
revise_chain=revise_prompt|llm|StrOutputParser()
defrevise_draft(state: BlogState) ->dict:
revised=revise_chain.invoke({
"draft": state["draft"],
"critique": state["critique"]
})
return {
"draft": revised,
"revision_number": state["revision_number"] +1
}
# ---- 决策函数:是否继续反思?----
defshould_continue(state: BlogState) ->str:
ifstate["revision_number"] <state["max_revisions"]:
return"critique"
else:
returnEND
# ---- 构建 LangGraph 状态图 ----
workflow=StateGraph(BlogState)
workflow.add_node("generate", generate_draft)
workflow.add_node("critique", critique_draft)
workflow.add_node("revise", revise_draft)
workflow.set_entry_point("generate")
workflow.add_edge("generate", "critique")
workflow.add_edge("critique", "revise")
workflow.add_conditional_edges(
"revise",
should_continue,
{
"critique": "critique",
END: END
}
)
app=workflow.compile()
# ---- 运行流程 ----
if__name__=="__main__":
initial_state= {
"draft": "",
"critique": "",
"revision_number": 0,
"max_revisions": 2 # 最多反思2次(即生成 + 2轮修订)
}
result=app.invoke(initial_state)
print("\n最终博客草稿:\n")
print(result["draft"])
实现思路(三步循环)
- 生成初稿→ LLM 作为“作者”,写出第一版关于 AI 伦理的博客草稿。
- **自我批评(反思)**→ LLM 切换角色,作为“编辑”或“伦理审查员”,指出草稿的问题(如偏见、逻辑漏洞、覆盖不全等)。
- 修订草稿→ LLM 再次作为“作者”,根据批评意见改进文章。
- **重复反思(可选)**→ 最多进行 N 轮(比如 2 轮),避免无限循环。
整个流程用 LangGraph 编排成一个状态机,控制“生成 → 批评 → 修订 → 是否继续?”的流转。
- Reflexion
============
属于是Reflection的加强版,在自反思的基础上,增加了经验固化的智能系统设计模式,更关注 从失败经验中学习,把执行过程中的“错误”或“次优决策”结构化存储并用于未来推理。它强调 长期记忆 + 经验反馈循环,适合创造性、开放性任务,而不是固定流程任务。
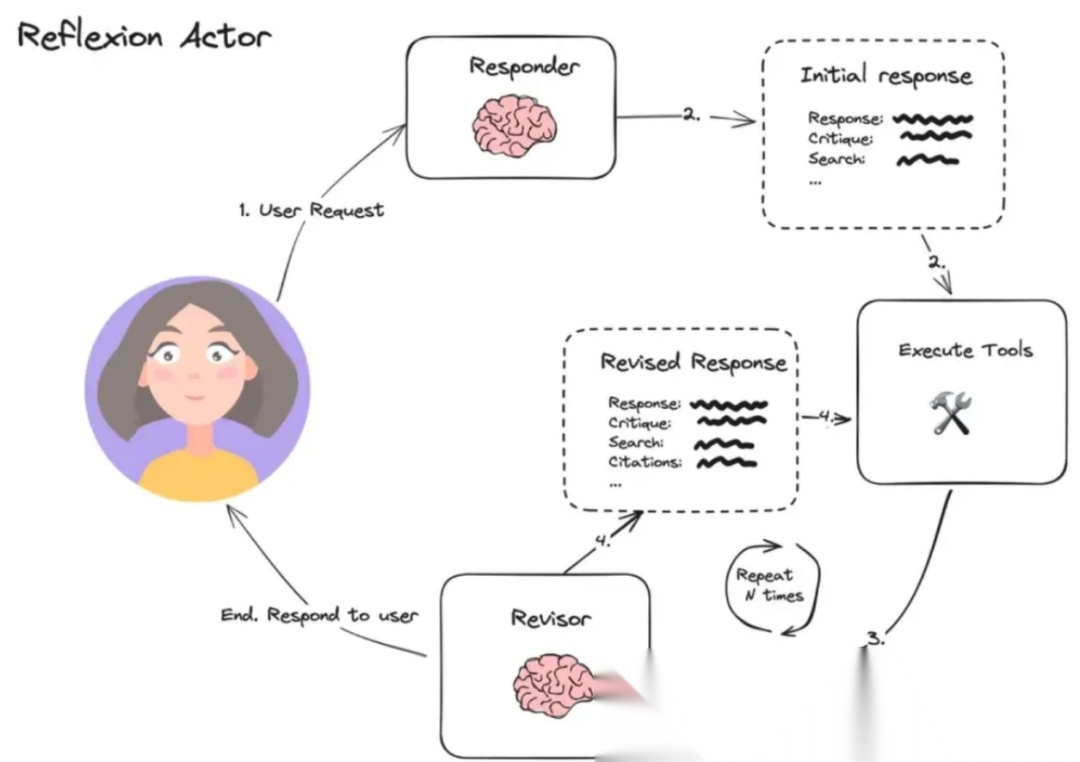
核心角色
- Agent / 执行器(Executor)
- 执行当前任务,调用工具、生成内容、处理输入。
- 本质上和普通 LLM Agent 类似,但输出会被评估并记录。
- 评估器(Evaluator)
- 对执行结果进行质量评估,可以是规则、模型打分、用户反馈等。
- 判断当前执行是成功、次优还是失败。
- 经验存储(Experience Memory / Knowledge Base)
- 保存执行历史、失败案例和改进方案。
- 结构化存储,使未来可以快速检索类似情境下的经验。
- 反思模块(Reflection / Improvement Planner)
- 基于经验存储和评估结果提出改进策略或新的执行方案。
- 可以直接指导下一次执行,或者更新执行策略模板。
流程可以理解为一个 循环反馈系统:
- 任务执行(Execute)
- Executor 对输入任务进行处理,生成结果。
- 结果评估(Evaluate)
- Evaluator 对结果打分,判断优劣。
- 经验记录(Record Experience)
- 将执行过程、评估结果、决策路径存入经验存储。
- 失败或次优的路径尤为重要,需要标记并附改进提示。
- 反思与改进(Reflect / Learn)
- Reflexion 模块分析失败原因,提炼可复用的经验或优化策略。
- 可生成新的 Prompt、工具调用顺序、或策略更新。
- 下次执行(Next Execution)
- 在新任务或相似任务中参考过去经验,提高成功率。
- 这个过程可以无限迭代,形成长期的“自我优化”闭环。
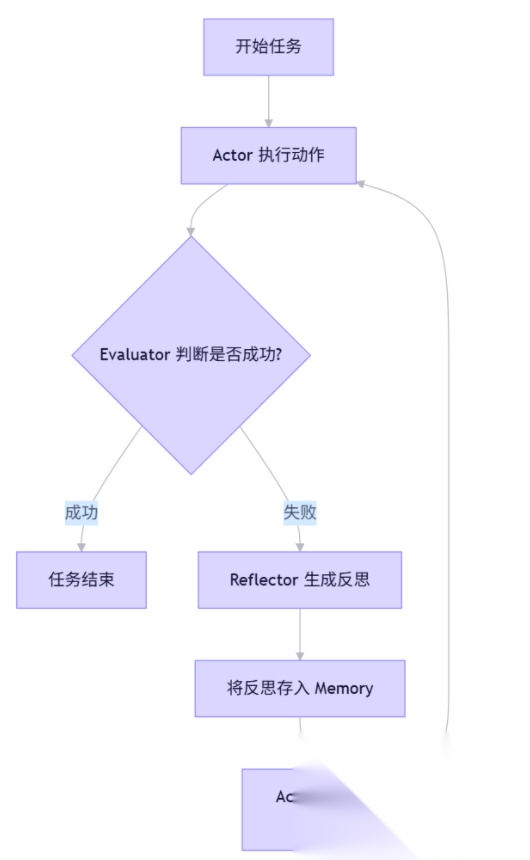
Reflexion 模式通过“执行 → 评估 → 反思 → 改进”的闭环,赋予 LLM 驱动的智能体一种类似人类的元认知能力(metacognition),是迈向真正自主智能的重要一步。
fromtypingimportTypedDict, List, Annotated
fromlanggraph.graphimportStateGraph, END
fromlangchain_openaiimportChatOpenAI
fromlangchain_core.promptsimportChatPromptTemplate
fromlangchain_core.messagesimportHumanMessage, AIMessage
importoperator
# ---- 配置 LLM ----
llm=ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
# ---- 定义状态 ----
classAgentState(TypedDict):
question: str
attempts: int
max_attempts: int
history: Annotated[list, operator.add] # 包含所有消息:用户输入、回答、反思
is_correct: bool
# ---- 节点函数 ----
defgenerate_answer(state: AgentState):
"""Actor:生成答案"""
prompt=ChatPromptTemplate.from_messages([
("system", "你是一个聪明的助手。请根据以下对话历史回答问题。"),
("placeholder", "{history}"),
("human", "{question}")
])
chain=prompt|llm
messages=state["history"] + [HumanMessage(content=state["question"])]
response=chain.invoke({
"history": messages,
"question": state["question"]
})
new_history=state["history"] + [HumanMessage(content=state["question"]), AIMessage(content=response.content)]
return {
"history": [HumanMessage(content=state["question"]), AIMessage(content=response.content)],
"attempts": state["attempts"] +1
}
defevaluate(state: AgentState):
"""Evaluator:判断答案是否合理(这里用简单规则+LLM辅助)"""
last_answer=state["history"][-1].contentifstate["history"] else""
question=state["question"]
# 简单规则:如果回答包含"0"或"没有"或"都飞走了",认为正确
ifany(kwinlast_answerforkwin ["0", "没有", "飞走", "吓跑", "全跑了"]):
return {"is_correct": True}
# 否则用 LLM 判断(可选)
eval_prompt=ChatPromptTemplate.from_messages([
("system", "你是一个严格的考官。判断助手的回答是否合理地解决了问题。只回答 'yes' 或 'no'。"),
("human", f"问题:{question}\n回答:{last_answer}")
])
eval_chain=eval_prompt|llm
eval_result=eval_chain.invoke({}).content.strip().lower()
is_correct="yes"ineval_result
return {"is_correct": is_correct}
defreflect(state: AgentState):
"""Reflector:生成反思"""
question=state["question"]
last_answer=state["history"][-1].content
reflect_prompt=ChatPromptTemplate.from_messages([
("system", "你是一个善于反思的思考者。分析为什么之前的回答可能是错的,并给出改进建议。用中文简短回答。"),
("human", f"问题:{question}\n你的回答:{last_answer}\n请反思:")
])
reflect_chain=reflect_prompt|llm
reflection=reflect_chain.invoke({}).content
# 将反思加入历史
return {
"history": [AIMessage(content=f"[反思]: {reflection}")]
}
defshould_continue(state: AgentState):
"""决定是否继续循环"""
ifstate["is_correct"]:
return"end"
ifstate["attempts"] >=state["max_attempts"]:
return"end"
return"reflect"
# ---- 构建图 ----
workflow=StateGraph(AgentState)
workflow.add_node("generate", generate_answer)
workflow.add_node("evaluate", evaluate)
workflow.add_node("reflect", reflect)
workflow.set_entry_point("generate")
workflow.add_edge("generate", "evaluate")
workflow.add_conditional_edges(
"evaluate",
should_continue,
{
"reflect": "reflect",
"end": END
}
)
workflow.add_edge("reflect", "generate")
app=workflow.compile()
# ---- 运行示例 ----
if__name__=="__main__":
question="树上4只猴,射死1只猴,还有几只猴?"
initial_state= {
"question": question,
"attempts": 0,
"max_attempts": 3,
"history": [],
"is_correct": False
}
result=app.invoke(initial_state)
print("\n=== 最终对话历史 ===")
formsginresult["history"]:
role="人类"ifisinstance(msg, HumanMessage) else"AI"
print(f"{role}: {msg.content}")
print(f"\n是否得到合理答案: {result['is_correct']}")
print(f"总尝试次数: {result['attempts']}")
结果:
人类: 树上4只猴,射死1只猴,还有几只猴?
AI: 3只。
[反思]: 我忽略了现实常识:枪声会吓跑其他猴子,所以树上可能一只不剩。下次应考虑实际情境而非纯数学。
人类: 树上4只猴,射死1只猴,还有几只猴?
AI: 枪响后其他猴子都被吓跑了,所以树上没有猴子了。
是否得到合理答案: True
总尝试次数: 2
- LATS
=======
简而言之:是一种将 树搜索(Tree Search)、ReAct 和 Plan-and-Execute 思想融合在一起的高级推理框架,用于提升大语言模型(LLM)在复杂任务中的决策能力与鲁棒性。
LATS 最早由 Princeton 和 Google Research 等团队在 2023 年底提出(论文:Language Agent Tree Search),其核心目标是让 LLM 充当“智能体(agent)”,通过模拟人类试错、回溯、评估和优化的过程,在动作空间中进行系统性探索。
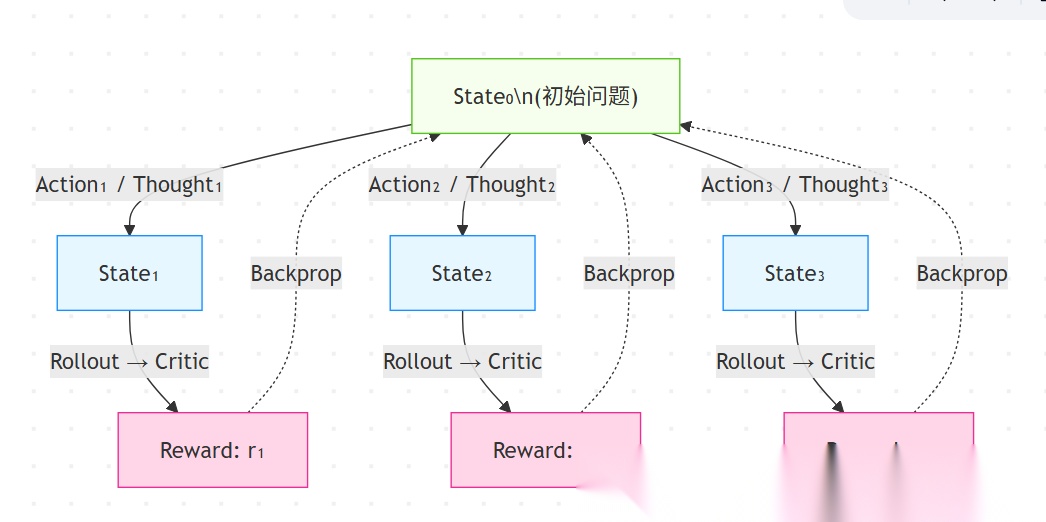
LATS 的核心思想
LATS 将任务建模为一个搜索树(search tree),其中:
- 每个节点代表一个状态(state)(如当前问题求解进度、环境上下文等);
- 每条边代表一个动作(action)(如调用工具、生成推理步骤、执行代码等);
- LLM 被用来同时扮演多个角色:推理者(reasoner)、动作提议者(proposer)、价值评估者(critic / evaluator)。
它结合了:
- ReAct:交替进行推理(Thought)和行动(Action);
- Plan & Execute:先制定高层计划,再逐步执行;
- 蒙特卡洛树搜索(MCTS) 或类似机制:通过 roll-out(模拟轨迹)和回溯(backpropagation)来优化路径选择。
LATS 中的关键角色(Components / Roles)
- Actor(动作生成器)
- 使用 LLM 生成多个可能的下一步动作(或推理步骤)。
- 类似 ReAct 中的 “Act” 部分,但支持多分支并行探索。
- Reasoner(推理模块)
- 生成对当前状态的理解、中间推理链(thoughts)。
- 可与 Actor 融合,形成 “Thought → Action” 对。
- Simulator(模拟器 / Rollout Policy)
- 对某个动作序列进行前向模拟(rollout),预测未来状态和结果。
- 通常也由 LLM 实现,快速“幻想”后续步骤直到任务完成或失败。
- Critic(评估器 / Value Function)
- 评估某个状态的好坏(如成功概率、答案质量、逻辑一致性)。
- 可基于规则、奖励模型(RM)或另一个 LLM(如 GPT-4 作为裁判)。
- 提供数值化 reward,用于指导树搜索。
- Tree Manager(树管理器)
- 维护搜索树结构(节点、边、访问次数、累计 reward 等)。
- 实现类似 MCTS 的选择(Selection)、扩展(Expansion)、模拟(Simulation)、回溯(Backpropagation)流程。
LATS 的典型流程(算法步骤)
以解决一个复杂推理问题(如数学题、代码生成、多跳问答)为例:
- 初始化
- 根节点 = 初始问题状态(如用户提问)。
- 设置最大搜索深度、预算(如 token 或时间限制)。
-
迭代搜索(每轮)
a. Selection(选择)
b. Expansion(扩展)
c. Simulation / Rollout(模拟)
d. Evaluation(评估)
e. Backpropagation(回溯)
-
将 reward 向上传播,更新路径上所有节点的统计信息(如平均 reward、访问次数)。
-
数学题:验证答案是否正确;
-
代码任务:能否通过测试用例;
-
开放问答:事实一致性、完整性。
-
调用 Critic 对 rollout 结果打分(reward),例如:
-
对每个新节点,使用轻量级策略(如 greedy ReAct)进行快速 rollout,直到终止(成功/失败/超时)。
-
得到一条完整轨迹(trajectory)。
-
调用 Actor + Reasoner,生成 K 个可能的下一步动作(如不同解题思路、工具调用)。
-
为每个动作创建新子节点(新状态)。
-
从根节点出发,使用策略(如 UCT 公式)选择最有潜力的子路径向下遍历,直到到达一个可扩展的叶节点。
- 终止与输出
- 达到预算后,选择根节点下 reward 最高 或 访问次数最多 的子动作作为最终答案。
- 可返回完整推理路径(可解释性强)。
LATS 的优势
- 系统性探索:避免 ReAct 的“贪心陷阱”,支持回溯和多路径比较。
- 利用 LLM 的多功能性:同一模型可做推理、动作生成、评估(或搭配专用 critic)。
- 可集成外部工具:如代码解释器、搜索引擎,作为动作空间的一部分。
- 适用于复杂任务:如算法题、科学推理、多步规划等。
总结:
LATS = ReAct + Plan & Solve + 树搜索(多路径探索+回溯) + LLM-as-Judge(评估反馈)
它代表了 LLM 智能体从“单次生成”向“自主探索-评估-优化”演进的重要方向,是当前 AI 推理系统(如 Devin、OpenDevin、Meta 的 CICERO 等)背后的核心思想之一。
- Plan And Solve
=================
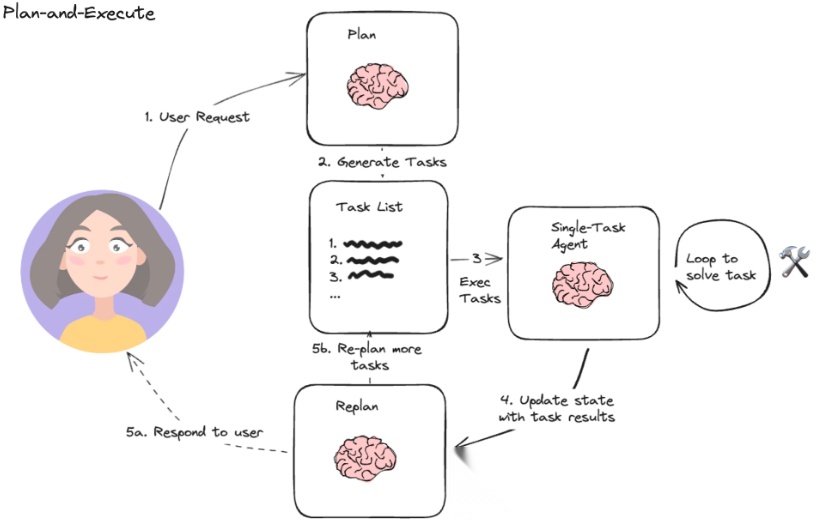
Plan-and-Execute的核心思想是首先构思一个全面的多步骤计划,然后分别执行每一步来解决复杂问题,将规划与执行分离,具体的:
- 任务分析和规划:
- 首先,系统会让模型对给定的任务进行分析,理解任务的具体目标、约束条件和执行步骤。这个阶段类似于“思考”过程,模型会对任务进行全面的梳理,并构建一个执行计划。
- 比如,如果任务是“订餐”,模型会首先分析订餐的具体流程,比如选择餐厅、选择菜品、选择配送方式等。
- 任务分解:
- 在规划阶段,模型会将一个复杂的任务分解成多个小的子任务。每个子任务都是独立且可以执行的步骤,这些子任务共同构成了实现目标的路径。
- 继续以“订餐”为例,子任务可能包括“选择餐厅”、“查看菜单”、“选择菜品”、“确认订单”等。
- 执行每个子任务:
- 接下来,系统会依照计划逐步执行每个子任务。每个子任务的执行可能涉及调用外部工具或进行计算,例如查询餐厅的菜单、计算送餐时间、获取价格等。
- 执行时模型可能还会进行实时的反馈和调整。如果某个步骤的结果不符合预期,模型会重新评估任务并调整策略。
- 反思和调整:
- 在整个过程中,模型会根据任务执行的反馈进行反思。如果某个步骤出错,模型可能会调整执行顺序或修改步骤内容。
- 这个过程类似于不断的调优和优化,确保每个环节都能顺利推进。
- 完成任务:
- 最后,所有子任务完成后,整个任务也就顺利达成了。这时系统会输出最终的结果。
通过这种思考-分解-执行-反馈的过程,Plan And Solve 可以更好地应对复杂任务,避免一次性执行时出现意外错误或遗漏,同时也能够根据环境变化进行灵活调整。
3.1 示例
from datetime import datetime
from typing import Annotated, TypedDict, Literal
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage, ToolMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
from common.llm_utils import get_llm_model
from web_app.langchain_demo.constant.qa_enums import ModelTypes
# 定义工具函数
def get_weather(city: str, search_datetime: str) -> str:
"""Get weather for a given city.
Args:
city: 要检索的城市
search_datetime: 要检查的日期时间,格式为字符串,例如2025-12-16 21:53
"""
return f"{city}{search_datetime}是晴天"
def get_current_datetime() -> str:
"""Get the current datetime"""
return datetime.now().strftime("%Y年%m月%d日 %H:%M")
# 定义状态
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
plan: str
current_step: int
total_steps: int
# 初始化模型和工具
model = get_llm_model(model_type=ModelTypes.deepseek_chat)
tools = [get_weather, get_current_datetime]
model_with_tools = model.bind_tools(tools)
# 创建工具节点
tool_node = ToolNode(tools)
# 规划节点:分析问题并制定计划
def plan_node(state: AgentState) -> AgentState:
"""分析问题并制定解决步骤"""
messages = state["messages"]
plan_prompt = f"""
请分析以下问题并制定解决计划:
问题:{messages[0].content}
可用工具:
1. get_current_datetime() - 获取当前日期时间
2. get_weather(city, search_datetime) - 查询特定城市和日期的天气
请制定详细的解决步骤(每步一行):
"""
plan_message = model.invoke([HumanMessage(content=plan_prompt)])
return {
"messages": [AIMessage(content=f"制定计划:\n{plan_message.content}")],
"plan": plan_message.content,
"current_step": 0,
"total_steps": len([line for line in plan_message.content.split('\n') if line.strip()])
}
# 执行节点:使用工具执行当前步骤
def solve_node(state: AgentState) -> AgentState:
"""执行解决方案"""
messages = state["messages"]
# 让模型决定需要调用哪些工具
solve_prompt = f"""
根据以下计划,使用可用的工具来解决问题:
计划:
{state.get('plan', '无计划')}
原始问题:{messages[0].content if messages else ''}
请使用工具来获取答案。
"""
response = model_with_tools.invoke(messages + [HumanMessage(content=solve_prompt)])
return {"messages": [response]}
# 工具调用后处理节点
def tool_result_node(state: AgentState) -> AgentState:
"""处理工具调用结果"""
return state
# 最终回答节点
def answer_node(state: AgentState) -> AgentState:
"""生成最终答案"""
messages = state["messages"]
answer_prompt = """
根据工具调用的结果,请给出最终答案。用简洁清晰的语言回答原始问题。
"""
final_response = model.invoke(messages + [HumanMessage(content=answer_prompt)])
return {"messages": [AIMessage(content=f"最终答案:\n{final_response.content}")]}
# 路由函数:决定下一步
def should_continue(state: AgentState) -> Literal["tools", "answer", "end"]:
"""判断是否需要继续调用工具"""
messages = state["messages"]
last_message = messages[-1]
# 如果最后一条消息有工具调用,继续执行工具
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
return "tools"
# 如果已经有工具执行结果,生成答案
if any(isinstance(msg, ToolMessage) for msg in messages):
return "answer"
return "end"
# 构建图
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("plan", plan_node)
workflow.add_node("solve", solve_node)
workflow.add_node("tools", tool_node)
workflow.add_node("answer", answer_node)
# 添加边
workflow.add_edge(START, "plan")
workflow.add_edge("plan", "solve")
workflow.add_conditional_edges(
"solve",
should_continue,
{
"tools": "tools",
"answer": "answer",
"end": END
}
)
workflow.add_edge("tools", "solve") # 工具执行后返回solve节点
workflow.add_edge("answer", END)
# 编译图
app = workflow.compile()
# 运行示例
def run_plan_and_solve(question: str):
"""运行 Plan and Solve 流程"""
print(f"\n{'=' * 60}")
print(f"问题:{question}")
print(f"{'=' * 60}\n")
initial_state = {
"messages": [HumanMessage(content=question)],
"plan": "",
"current_step": 0,
"total_steps": 0
}
for event in app.stream(initial_state):
for node_name, state in event.items():
print(f"\n节点:{node_name}")
if "messages" in state and state["messages"]:
last_msg = state["messages"][-1]
if hasattr(last_msg, 'content') and last_msg.content:
print(f"内容:{last_msg.content[:200]}...")
if hasattr(last_msg, 'tool_calls') and last_msg.tool_calls:
print(f"调用工具:{[tc['name'] for tc in last_msg.tool_calls]}")
print("-" * 60)
# 主函数
if __name__ == "__main__":
question = "北京明天的天气怎么样?"
run_plan_and_solve(question)
流程图:
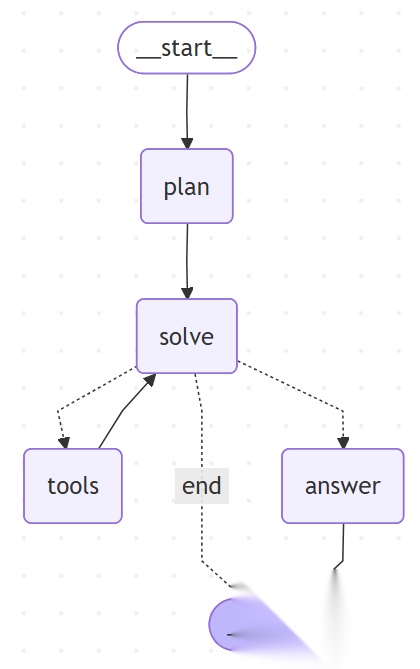
输出:
============================================================
问题:北京明天的天气怎么样?
============================================================
节点:plan
内容:制定计划:
1. 调用 get_current_datetime() 获取当前日期时间。
2. 确定目标城市为“北京”,目标日期为“明天”。
3. 根据当前日期时间计算“明天”的具体日期。
4. 调用 get_weather("北京", 计算出的明天日期) 查询天气信息。
5. 返回查询到的天气结果。...
------------------------------------------------------------
节点:solve
内容:我来按照计划逐步执行。...
调用工具:['get_current_datetime']
------------------------------------------------------------
节点:tools
内容:2026年01月19日 15:47...
------------------------------------------------------------
节点:solve
内容:现在我知道当前时间是2026年1月19日15:47,那么明天就是2026年1月20日。我需要查询北京2026年1月20日的天气。...
调用工具:['get_weather']
------------------------------------------------------------
节点:tools
内容:北京2026-01-20 15:47是晴天...
------------------------------------------------------------
节点:solve
内容:我已经按照计划执行了查询。根据查询结果:
北京明天(2026年1月20日)的天气是晴天。...
------------------------------------------------------------
节点:answer
内容:最终答案:
北京明天(2026年1月20日)是晴天。...
------------------------------------------------------------
3.1 优势与局限性
优势:
- 分离全局规划与局部执行,显著降低认知负担,稳定性高
- Planner 负责全局路径与任务拆解,Executor 只处理当前步骤。
- 每一步不需要反复回放历史推理,天然适合长链路任务,显著缓解上下文膨胀、注意力漂移和中途失控问题。
- 由于是分步操作,人工可以介入规划流程,提高Agent稳定性。
- 决策结构显式化,可控、可审计、可干预Plan 作为中间产物可以被检查、修正、裁剪或复用,使 Agent 行为从“即时反应”升级为“流程编排”,工程可控性远高于纯ReAct。
- 工具规模扩展性更好,抑制 function_call 爆炸规划阶段完成工具筛选与路径选择,执行阶段只暴露当前步骤所需工具,避免模型在单步面对过多动作选项。
劣势:
- 计划质量决定系统上限,错误具有放大效应全局理解或任务拆解一旦出错,Executor 往往会稳定地执行一个错误计划,错误不是逐步暴露,而是系统性传播,因此在Plan阶段,一般会选用性能最强的模型。
- 对动态与不确定环境适应性较弱默认假设执行环境相对稳定,一旦外部信息变化或执行结果偏离预期,必须显式引入Replan,否则系统会僵化。
- 系统架构与工程成本更高通常需要 Planner / Executor / State / Replanner 等多组件协同,设计与维护复杂度高于单体 ReAct Agent。
总结:Plan-and-Execute 的核心价值不在“更聪明”,而在把一次长思考,拆成一次重思考 + 多次轻思考。这也是它能在长任务、复杂工具、多步骤场景里稳定跑下去的根本原因。
最佳适用场景:
- 工具数量多、动作选择空间大;
- 长链路、多步骤、复杂任务。
混合方案:Plan-and-Execute + ReAct:
# 高层用 Plan-and-Execute 分解任务
plan = [
"子任务1:查询基础信息",
"子任务2:深度分析",
"子任务3:生成报告"
]
# 每个子任务内部用 ReAct 灵活执行
for subtask in plan:
result = react_agent.solve(subtask) # 灵活处理
results.append(result)
| 思想 | 核心作用 | 与 ReAct/Plan-and-Solve 的区别 |
|---|---|---|
| 意图识别 | 理解用户想做什么 | 是前置步骤,生成可操作的动作/工具调用;不做多步推理 |
| ReAct | 思考—执行—反思循环 | 模型自己选择动作并调整策略,依赖上下文 |
| Plan-and-Solve | 明确规划后逐步执行 | 强调先生成计划,再逐步执行;更适合复杂任务 |
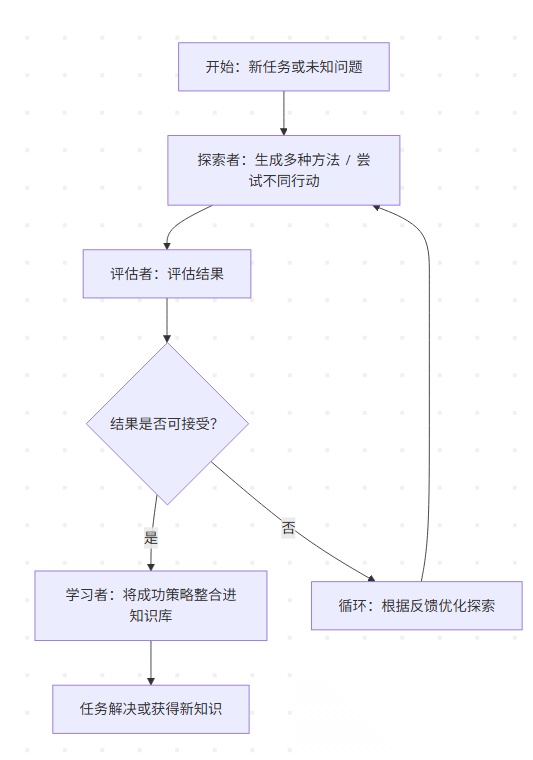
- Self-Discovery
=================
- STORM
=========
STORM Agent Pattern 是由微软研究院(Microsoft Research)在 2024 年提出的一种基于大语言模型(LLM)的自动化研究代理框架,旨在模拟人类专家进行复杂、多轮次、多视角的研究性写作(如撰写维基百科风格的文章)。
其核心思想是通过多个具有不同“角色”或“视角”的智能体(agents)协作,生成高质量、信息丰富、结构严谨的内容。
简单直白点讲:可以从零生成一篇像百度百科、长篇的学术论文呢样的文章,主要思路是先让 agent 利用外部工具搜索生成大纲,然后再生成大纲里的每部分内容。
STORM 中的核心角色(Agents)
STORM 框架中主要包含两类智能体角色:
1. Perspective Generator(视角生成器)
- 作用:从初始主题出发,自动生成多个不同的研究视角(perspectives)或子话题。
- 实现方式:通常调用 LLM,提示其扮演“头脑风暴专家”,列举与主题相关的各种角度(如历史背景、技术原理、社会影响、争议点、案例分析等)。
- 输出:一个结构化的视角列表,每个视角可视为一个采访或研究方向。
2. Interviewer–Interviewee Pairs(采访者–受访者对)
- 对于每一个生成的视角,系统会创建一对智能体:
-
扮演该领域的“专家”,回答采访者的问题。
-
回答内容应基于可靠知识(在 STORM 实现中,会结合检索增强生成 RAG,从网络或知识库中获取真实信息)。
-
基于该视角设计一系列深入、具体的问题。
-
模拟记者或研究员,追问细节、澄清概念、探索矛盾。
-
Interviewer(采访者)
-
Interviewee(受访者)
- 关键点:每对智能体聚焦一个视角,形成多轮对话,挖掘深度信息。
注意:虽然称为“多个智能体”,但在实际实现中,通常由同一个 LLM 通过不同提示(prompt)扮演不同角色,并非物理上独立的模型。
STORM 的工作流程
STORM 的完整流程可分为以下几个阶段:
阶段 1:主题输入与视角生成
- 用户提供一个主题(例如:“量子计算”)。
- 系统调用 LLM 作为 Perspective Generator,生成多样化的研究视角(如“发展历程”、“关键技术”、“主要公司”、“伦理问题”等)。
阶段 2:多视角采访(并行或串行)
- 对每个视角:
- Interviewer 生成一系列问题(可能多轮)。
- Interviewee 在检索外部信息(如维基百科、新闻、论文)的基础上回答问题。
- 整个对话被记录为该视角下的“知识片段”。
此阶段强调 信息覆盖广度 和 观点多样性,避免单一叙述偏见。
阶段 3:信息整合与文章生成
- 将所有采访对话中的关键信息提取、去重、组织。
- 调用 LLM 作为 Writer Agent,综合所有视角内容,撰写一篇结构清晰、引用充分、中立客观的长文(类似维基百科条目)。
- 可选:加入 Citation Agent 自动添加参考文献链接。
阶段 4:反思与迭代(可选)
- 系统可自我评估文章的完整性、一致性或遗漏点。
- 若发现信息不足,可回到阶段 2 补充新视角或追问。
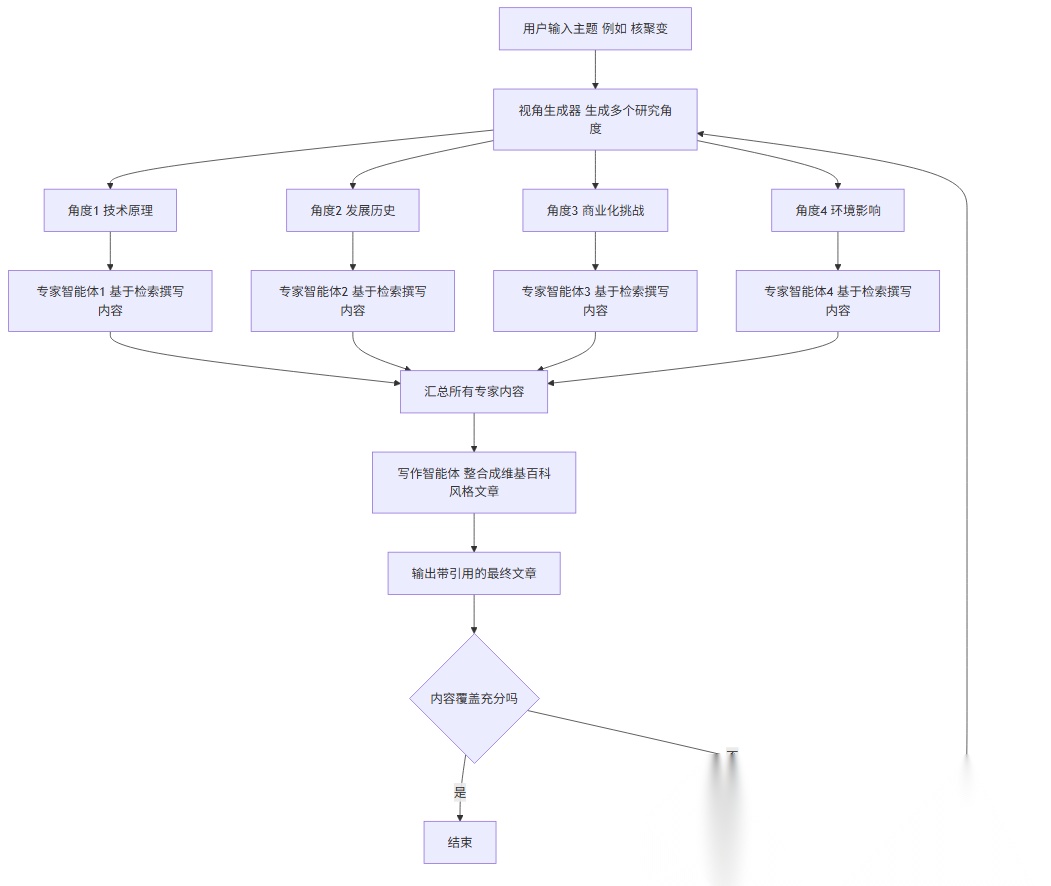
STORM 的关键创新点
- 多智能体协作:通过角色分工模拟人类研究过程。
- 视角驱动(Perspective-driven):避免传统 RAG 的“问答碎片化”,强调结构性知识构建。
- 检索增强 + 多轮对话:确保内容既准确又深入。
- 可扩展性:可集成更多角色(如事实核查员、编辑等)。
AI时代,未来的就业机会在哪里?
答案就藏在大模型的浪潮里。从ChatGPT、DeepSeek等日常工具,到自然语言处理、计算机视觉、多模态等核心领域,技术普惠化、应用垂直化与生态开源化正催生Prompt工程师、自然语言处理、计算机视觉工程师、大模型算法工程师、AI应用产品经理等AI岗位。
掌握大模型技能,就是把握高薪未来。
那么,普通人如何抓住大模型风口?
AI技术的普及对个人能力提出了新的要求,在AI时代,持续学习和适应新技术变得尤为重要。无论是企业还是个人,都需要不断更新知识体系,提升与AI协作的能力,以适应不断变化的工作环境。
因此,这里给大家整理了一份《2026最新大模型全套学习资源》,包括2026最新大模型学习路线、大模型书籍、视频教程、项目实战、最新行业报告、面试题、AI产品经理入门到精通等,带你从零基础入门到精通,快速掌握大模型技术!
由于篇幅有限,有需要的小伙伴可以扫码获取!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
5. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

为什么大家都在学AI大模型?
随着AI技术的发展,企业对人才的需求从“单一技术”转向 “AI+行业”双背景。企业对人才的需求从“单一技术”转向 “AI+行业”双背景。金融+AI、制造+AI、医疗+AI等跨界岗位薪资涨幅达30%-50%。
同时很多人面临优化裁员,近期科技巨头英特尔裁员2万人,传统岗位不断缩减,因此转行AI势在必行!

这些资料有用吗?
这份资料由我们和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


大模型全套学习资料已整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献603条内容
已为社区贡献603条内容

所有评论(0)