【Java集合 | 第二篇】List集合总结
ArrayList基于动态数组实现,支持随机访问,插入删除效率受位置影响(尾部O(1),其他O(n));LinkedList基于双向链表,头尾操作O(1),随机访问O(n)。ArrayList扩容机制为1.5倍增长,需考虑最小容量需求。两者均非线程安全,区别在于:ArrayList空间利用率高但扩容耗性能,LinkedList每个元素占用更多空间但插入删除灵活。集合的fail-fast机制通过mo
目录
ArrayList、LinkedList插入删除操作的时间复杂度
List
ArrayList和Array的区别
ArrayList 内部基于动态数组实现,比 Array(静态数组) 使用起来更加灵活:
-
ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了。 -
ArrayList允许你使用泛型来确保类型安全,Array则不可以。 -
ArrayList中只能存储对象。对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array可以直接存储基本类型数据,也可以存储对象。 -
ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。 -
ArrayList创建时不需要指定大小,而Array创建时必须指定大小。
ArrayList、LinkedList插入删除操作的时间复杂度
1. ArrayList
插入:
-
头部插入:由于需要将所有元素都依次向后移动一个位置,因此时间复杂度是 O(n)。
-
尾部插入:当
ArrayList的容量未达到极限时,往列表末尾插入元素的时间复杂度是 O(1),因为它只需要在数组末尾添加一个元素即可;当容量已达到极限并且需要扩容时,则需要执行一次 O(n) 的操作将原数组复制到新的更大的数组中,然后再执行 O(1) 的操作添加元素。 -
指定位置插入:需要将目标位置之后的所有元素都向后移动一个位置,然后再把新元素放入指定位置。这个过程需要移动平均 n/2 个元素,因此时间复杂度为 O(n)。
删除:
-
头部删除:由于需要将所有元素依次向前移动一个位置,因此时间复杂度是 O(n)。
-
尾部删除:当删除的元素位于列表末尾时,时间复杂度为 O(1)。
-
指定位置删除:需要将目标元素之后的所有元素向前移动一个位置以填补被删除的空白位置,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
2. LinkedList
-
头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)。
ArrayList 与 LinkedList的区别
-
是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; -
底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) -
插入和删除是否受元素位置的影响:
-
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 -
LinkedList采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
-
-
是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList(实现了RandomAccess接口) 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 -
内存空间占用:
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
补充内容:RandomAccess 接口
实际上 RandomAccess 接口中什么都没有定义,RandomAccess 接口只是一个标识。标识什么? 标识实现这个接口的类具有随机访问功能。
ArrayList的扩容机制
1. 前提
ArrayList 底层基于数组实现,数组的长度是固定的,因此当向 ArrayList 中添加元素导致数组容量不足时,就需要触发扩容 —— 创建一个新的更大的数组,将原数组的元素复制到新数组中,再替换原数组。
2. 参数
-
DEFAULT_CAPACITY:默认初始容量,值为10(注意:空参构造的 ArrayList 初始数组是空数组,首次添加元素时才会扩容到 10); -
elementData:存储元素的底层数组; -
size:当前 ArrayList 中实际元素的个数; -
MAX_ARRAY_SIZE:数组最大容量,值为Integer.MAX_VALUE - 8(避免内存溢出,极少数场景下可突破)。
3.扩容时机
当调用 add()/addAll() 方法时,会先检查:size + 待添加元素个数 > elementData.length,若满足则触发扩容grow函数。
4. 扩容步骤
简化逻辑 ArrayList.grow()方法
private void grow(int minCapacity) {
// 1. 获取旧容量
int oldCapacity = elementData.length;
// 2. 计算新容量:旧容量 + 旧容量/2(即扩容1.5倍)
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 3. 修正新容量 是否大于最小需要容量 不满足就把最小需要容量当作数组的新容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 4. 检查是否超过最大容量限制(Integer.MAX_VALUE - 8)
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 5. 数组拷贝:将原数组元素复制到新容量的数组中
elementData = Arrays.copyOf(elementData, newCapacity);
}
实例 1:常规扩容(1.5 倍满足最小需求)
假设:
ArrayList 初始容量 10(
oldCapacity=10),已存 10 个元素(size=10);调用
add()添加 1 个元素,此时:
初始
minCapacity= size + 1 = 11;进入
grow(11):
oldCapacity = 10;
newCapacity = 10 + (10 >> 1) = 10 + 5 = 15;检查
15 - 11 = 4 > 0→ 无需修正,newCapacity仍为 15;15 < MAX_ARRAY_SIZE → 最终容量 15;
数组扩容为 15,满足「至少需要 11」的最低要求。
实例 2:1.5 倍扩容不足(需修正为 minCapacity)
这是
minCapacity发挥核心作用的场景:假设:
ArrayList 初始容量 10(
oldCapacity=10),已存 10 个元素(size=10);调用
addAll()批量添加 8 个元素,此时:
初始
minCapacity= size + 8 = 18;进入
grow(18):
oldCapacity = 10;
newCapacity = 10 + 5 = 15;检查
15 - 18 = -3 < 0→ 15 不够装 18 个元素,修正newCapacity = 18;18 < MAX_ARRAY_SIZE → 最终容量 18;
数组扩容为 18,保证能装下批量添加的元素。
fail-fast和fail-safe原理
-
定义
-
fail-fast(快速失败):集合在遍历 / 操作过程中,若检测到其他线程修改了集合的「结构性数据」(如增删元素、修改数组容量),会立即抛出
ConcurrentModificationException异常,终止操作,核心是「提前暴露问题,不允许并发修改」。 -
fail-safe(安全失败):集合在遍历 / 操作时,基于「原集合的拷贝」进行,即使其他线程修改原集合,遍历过程也不会抛出异常,核心是「操作拷贝,不影响原数据」。
-
-
fail-fast 原理
( ArrayList/HashMap )
-
底层依赖
modCount(修改次数计数器):集合每发生一次「结构性修改」(add/remove/clear 等),modCount就会 +1; -
遍历前(如迭代器初始化时),迭代器会记录当前的
modCount(记为expectedModCount); -
遍历过程中,每次调用
next()/remove()时,都会校验modCount == expectedModCount:-
若相等:正常遍历;
-
若不等:说明有其他线程修改了集合,立即抛出
ConcurrentModificationException。
-
-
-
fail-safe 原理
写时复制(Copy-On-Write)
保证在进行修改操作时复制出一份快照,基于这份快照完成添加或者删除操作后,将
CopyOnWriteArrayList底层的数组引用指向这个新的数组空间,由此避免迭代时被并发修改所干扰所导致并发操作安全问题,当然这种做法也存在缺点,即进行遍历操作时无法获得实时结果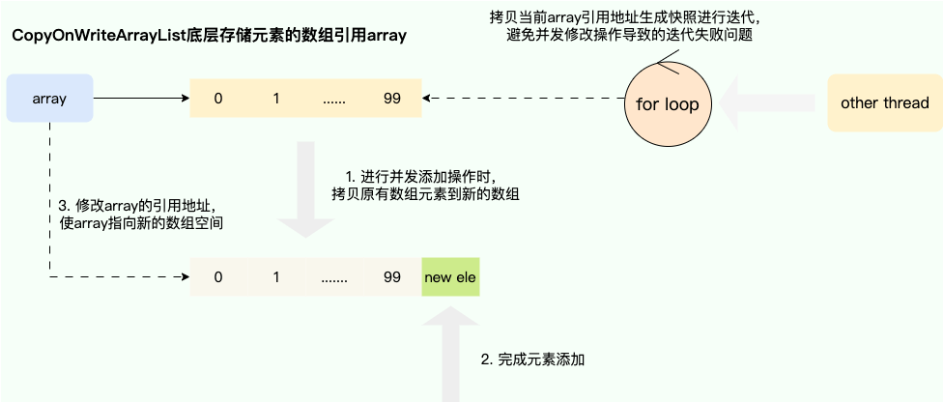
上述内容也同步在我的飞书,欢迎访问
https://my.feishu.cn/wiki/QLauws6lWif1pnkhB8IcAvkhncc?from=from_copylink
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,你们的支持就是我坚持下去的动力!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)