让 AI 越用越懂你:AgentForce 构建动态用户画像系统
AgentForce 是一个展示了GraphRAG与如何落地的优秀案例。无论你是想学习最新的 RAG 技术,还是想搭建一个私有的企业级知识库,这个项目都值得一试。如果你觉得项目不错,欢迎去 GitHub 点个 Star ⭐️ 支持一下作者!🔗项目地址。
摘要:传统的 RAG 或 Agent 系统通常只有“短期记忆”(上下文窗口)。如何让 AI 真正记住用户的偏好、技术栈和关注点?本文将分享 AgentForce 如何利用 LLM 进行实体抽取,结合 NetworkX 构建知识图谱,并通过 PageRank 算法挖掘用户核心画像。最后,我们将通过 Python 异步线程池实现无感更新,保证极致的对话体验。
项目地址👉 :https://github.com/TW-NLP/AgentForce
AgentForce的使用说明:https://blog.csdn.net/qq_43765734/article/details/157396247?spm=1001.2014.3001.5502
1. 痛点:AI 为什么总是"脸盲"?
在开发垂直领域的 AI 助手时,我们常遇到这样的问题: 用户昨天问了 "Python 的生成器怎么写?",今天问 "推荐一些好用的库"。 如果 AI 记不住用户是 "Python 开发者" 这一身份,它可能会推荐 Java 或 C++ 的库,导致体验割裂。
我们需要一个 用户画像(User Persona)系统,它需要具备:
-
自动提取:从海量对话中自动抓取关键信息。
-
关系推理:不仅知道"Python",还能通过图谱关联知道用户可能对 "PyTorch" 或 "FastAPI" 感兴趣。
-
量化权重:区分用户是"随便问问"还是"深度关注"(通过算法打分)。
2. 系统架构设计
我们的系统主要包含三个核心步骤:
-
ETL (抽取):使用 LLM 从历史对话中提取
实体(Entity)和关系(Relation)。 -
Graph Building (建图):使用
NetworkX构建有向图,用户节点指向实体节点。 -
Mining (挖掘):运行
PageRank和中心性算法,计算每个偏好的权重。
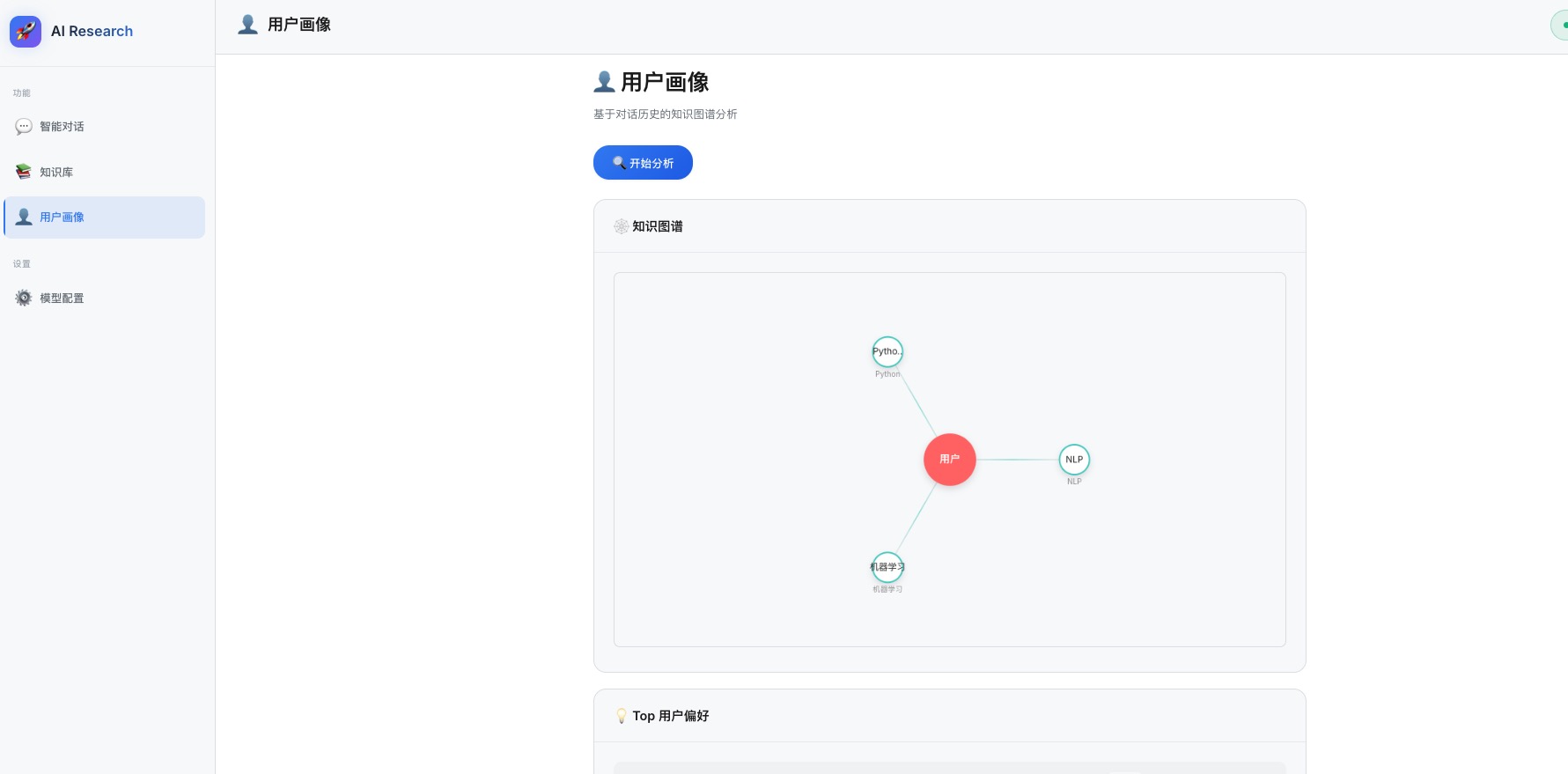
3. 核心实现:从对话到图谱
3.1 LLM 实体关系抽取
首先,我们需要设计一个 Prompt,让 LLM 充当数据清洗工,将非结构化的聊天记录转化为结构化的 JSON。
# 核心 Prompt 设计思路
prompt = """
从用户的对话中提取实体和关系,用于构建知识图谱。
请提取:
1. 实体(entities):用户提到的具体事物、技术栈、业务痛点
2. 关系(relations):用户与实体之间的关系(如:使用、关注、讨厌)
返回格式示例:
{
"entities": [{"name": "FastAPI", "type": "框架"}],
"relations": [{"source": "USER", "target": "FastAPI", "relation": "正在使用", "weight": 0.9}]
}
"""
3.2 NetworkX 图构建与 PageRank 挖掘
这是本系统的灵魂。我们不仅仅是统计词频,而是通过图算法来计算重要性。
import networkx as nx
def mine_preferences(self):
# 1. PageRank - 计算节点权威度
# 比如用户多次提到了 "AI",而 "AI" 又连接了 "RAG",那么 "RAG" 的权重也会提升
pagerank_scores = nx.pagerank(self.graph, weight='weight')
# 2. 度中心性 - 简单直接的关注点
# 用户直接提及次数最多的实体
user_neighbors = self.graph['USER']
# 3. 综合加权算法
final_scores = {}
for entity in pagerank_scores:
if entity == 'USER': continue
# 融合 PageRank (40%) + 直接连接权重 (30%) + 提及频率 (30%)
score = (pagerank_scores[entity] * 40) + \
(neighbor_weights.get(entity, 0) * 30) + \
(mentions_score * 30)
final_scores[entity] = score
return sorted(final_scores.items(), key=lambda x: x[1], reverse=True)[:10]
4. 性能优化:Fire-and-Forget 异步更新
图谱构建和 LLM 提取是非常耗时的操作(可能需要 10秒+)。如果我们在 WebSocket 对话循环中直接 await 这个任务,用户会感觉到明显的卡顿。
为了实现极致流畅的体验,我们采用了 WebSocket 断开触发 + 线程池异步执行 的策略。
优化前的代码(阻塞式 ❌)
# 糟糕的体验:用户发完消息,要等图谱更新完才能收到回复
response = await agent.chat(message)
await mining_service.person_like_save() # 卡住 5-10秒!
await websocket.send_text(response)
优化后的代码(Fire-and-Forget ✅)
我们利用 Python 的 asyncio 和 ThreadPoolExecutor,将挖掘任务扔到后台运行,主线程立即释放资源。
import asyncio
from concurrent.futures import ThreadPoolExecutor
from fastapi import WebSocket, WebSocketDisconnect
# 全局单线程池(避免并发写文件冲突)
mining_executor = ThreadPoolExecutor(max_workers=1)
@app.websocket("/ws/stream")
async def websocket_endpoint(websocket: WebSocket):
await websocket.accept()
session_id = create_session()
# 定义后台任务包装器
def run_mining_bg_task(sid):
try:
print(f"[{sid}] ⏳ 后台开始挖掘用户偏好...")
service = UserPreferenceMining()
service.person_like_save() # 耗时操作
print(f"[{sid}] ✅ 画像更新完成")
except Exception as e:
print(f"后台任务失败: {e}")
try:
while True:
# ... 正常的快速对话逻辑 ...
data = await websocket.receive_text()
await websocket.send_text(f"AI回复: {data}")
except WebSocketDisconnect:
# ✅ 关键点:连接断开时,通过 loop.run_in_executor 触发后台任务
# 这一步是非阻塞的,WebSocket 连接会立即正确关闭
loop = asyncio.get_running_loop()
loop.run_in_executor(
mining_executor,
run_mining_bg_task,
session_id
)
方案优势:
-
零延迟:用户对话过程中感受不到任何计算延迟。
-
资源利用:利用用户阅读或离开的空闲时间进行计算。
-
线程安全:通过单线程池控制写入,避免文件锁冲突。
5. 最终效果与可视化
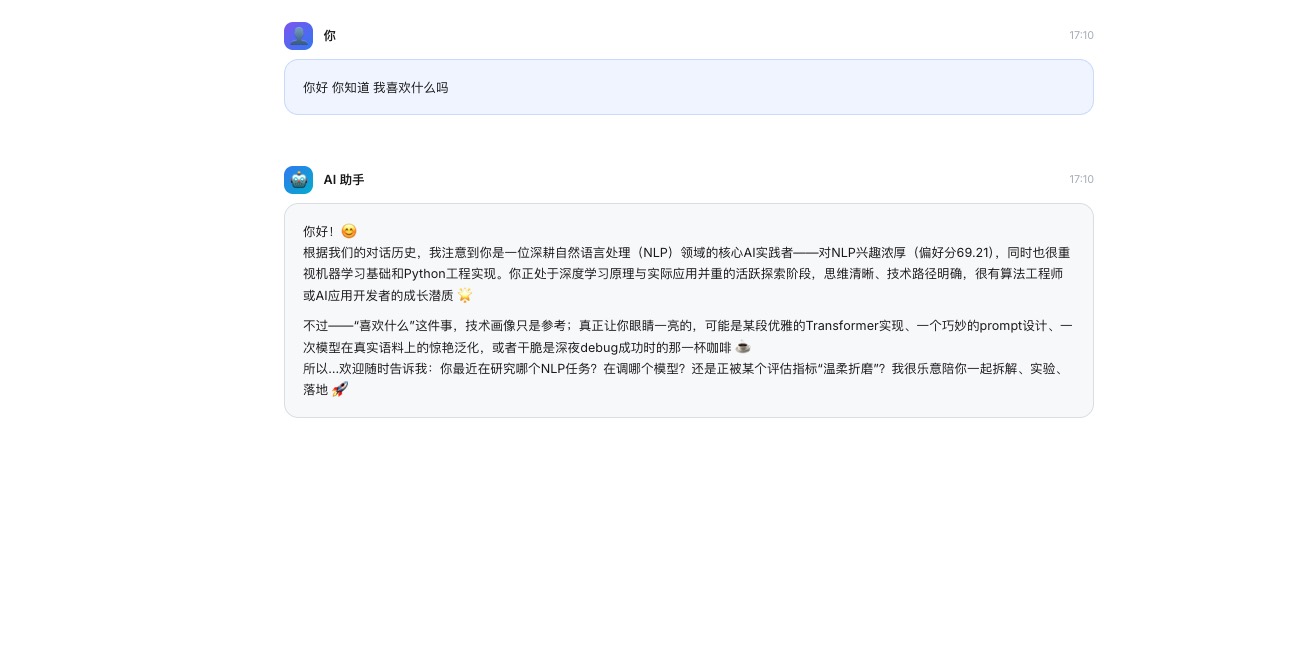
✍️ 总结
AgentForce 是一个展示了 GraphRAG 与 Agentic Workflow 如何落地的优秀案例。无论你是想学习最新的 RAG 技术,还是想搭建一个私有的企业级知识库,这个项目都值得一试。
如果你觉得项目不错,欢迎去 GitHub 点个 Star ⭐️ 支持一下作者!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)