AI Agent开发“最后一公里“难题?这套评估体系让小白也能秒变大神!
文章详细介绍了AI Agent开发的"最后一公里"解决方案,包括混合智能体架构设计、基于LangSmith的监控调试、OpenEvals自动化评估、Prompt Ops运维管理,以及DeepEval和LangFuse等工具。这套完整评估体系可解决Agent的黑盒困境、性能瓶颈和评估迷茫问题,实现从Demo到生产可用。
引言——Agent 开发的“最后一公里”
在 AI Agent 爆火的今天,很多开发者都经历过这样的“高光时刻”:写几行 Prompt,挂载几个工具,一个看起来无所不能的智能体就诞生了。
但现实往往很骨感。当你试图将 Agent 投入真正的业务场景(比如金融投顾、医疗咨询)时,你会发现:
- 黑盒困境:它给出的回答时好时坏,你却不知道它在中间哪一步“掉链子”了。
- 性能瓶颈:一个简单的查询,它却在后台“深思熟虑”了 30 秒,用户早已失去耐心。
- 评估迷茫:改了一个 Prompt 参数,整体表现是变好了还是变差了?只能靠人工肉眼抽检。
这种从“Demo 调通”到“生产可用”的距离,就是 Agent 开发的最后一公里。要跑通这一公里,我们需要一套完整的效果评估体系。今天,我就结合一个“投顾 AI 助手”的实战案例,带大家看看高手是如何炼成高性能 Agent 的。
一. Agent架构基石——混合智能体
要优化 Agent,首先要有一个合理的架构。在本次案例中,我们采用的是混合智能体架构(Hybrid Agent Architecture)。
1. 为什么要“混合”?——快思考与慢思考
丹尼尔·卡尼曼在《思考,快与慢》中提到人类有两套系统:系统 1 是直觉和本能(快),系统 2 是逻辑与规划(慢)。 一个优秀的 AI Agent 也应如此:
- 底层(反应式层/Reactive): 负责处理简单直接的指令。比如用户问“现在上证指数是多少?”,Agent 应该形成“本能反应”,直接查数据并返回,追求极速响应。
- 顶层(深思熟虑层/Deliberative): 负责长周期、复杂的任务。比如用户问“如果未来半年美联储降息,我的资产配置该如何调整?”,这需要 Agent 进行长程规划、多步推理,追求深度逻辑。
2. 中层协调:Agent 的“调度大脑”
混合架构的核心在于协调层(Coordination Layer)。它像一个聪明的调度员,实时监控用户的输入:
- 如果是紧急、简单的任务,一键分发给反应式层;
- 如果是策略性任务,则激活深思熟虑层。 通过这种动态切换,既保留了智能体的“深度”,又解决了响应速度的“痛点”。
3. 状态管理:WealthAdvisorState 的妙用
在复杂的投顾场景下,Agent 不能“随风倒”,它必须有记忆。我们通过 WealthAdvisorState 来维护对话上下文。 它不仅记录了用户的资产信息,还记录了 Agent 当前处于哪种处理模式。这种显式状态管理,为后续我们利用 LangSmith 进行精确监控提供了数据基础。
二. Agent监控与调试——基于LangSmith
很多开发者在调试 Agent 时,最痛苦的就是只能对着终端的日志(Logs)猜它的逻辑。但在工程化开发中,我们需要对Agent运行过程进行精确追踪。这里我们就不得不提 LangSmith(可视化界面:https://smith.langchain.com/)。
通过 LangSmith 的集成,我们可以记录下Agent应用(投顾助手)每一次调用的全过程,LangSmith 为LLM 应用提供了完整的工具链。
- 调试与追踪:实时追踪每个LLM 调用、工具使用和Agent 决策过程,帮助快速定位问题。
- 性能监控:监控响应时间、Token 使用量、成本等关键指标,优化应用性能。
- 测试与评估:创建测试数据集,评估模型输出质量,持续改进应用效果。
- 数据分析:分析用户查询模式、错误率、成功率等,为产品优化提供数据支持。
Step1,获取API 密钥: https://smith.langchain.com 点击Tracing quickstart 获取 API 密钥
Step2,设置环境变量,代码层面配置好相应的环境变量
LANGSMITH_API_KEY=your-api-key-here
LANGCHAIN_TRACING_V2=true
LANGCHAIN_PROJECT=“wealth-advisor-hybrid-agent” # 可选,用于组织追踪记录
代码中相关配置如下:
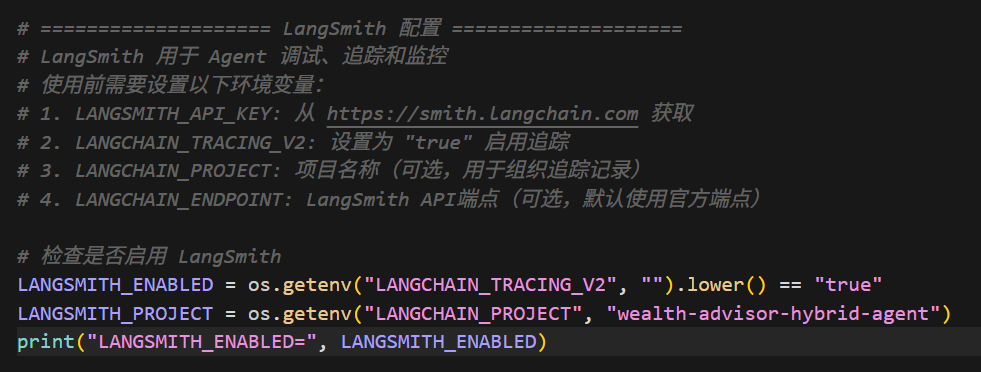
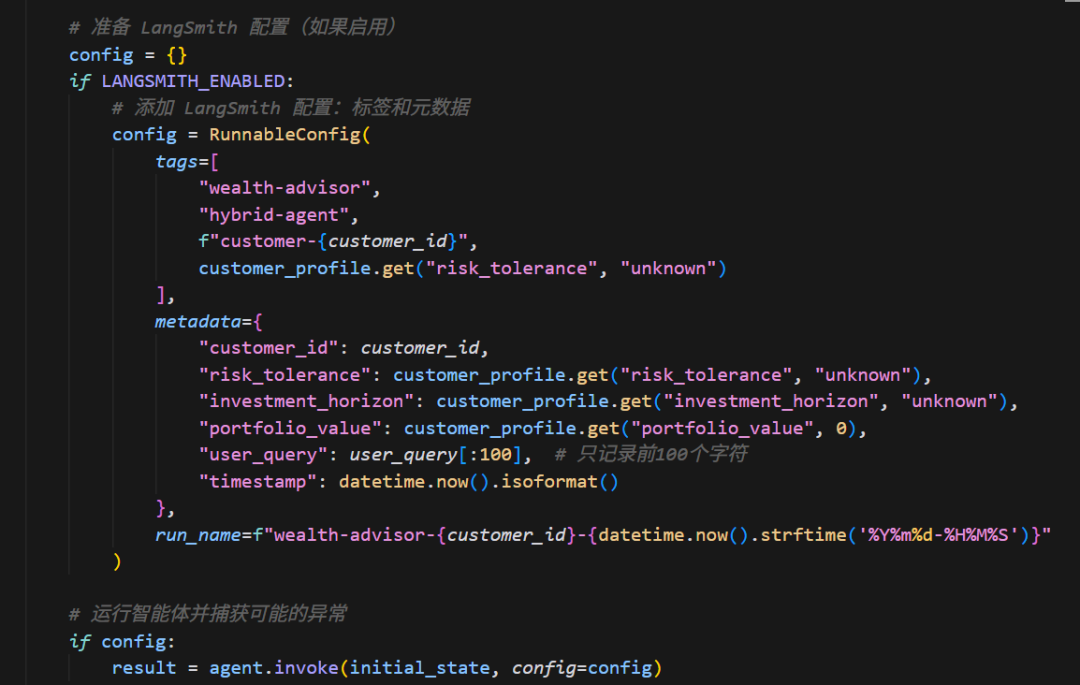
Step3,自动追踪配置,代码中配置config的标签及元数据,通过tags 和metadata 为每次运行打上标签(如用户ID、业务类型),方便在LangSmith后台进行筛选、 分组和故障排查。
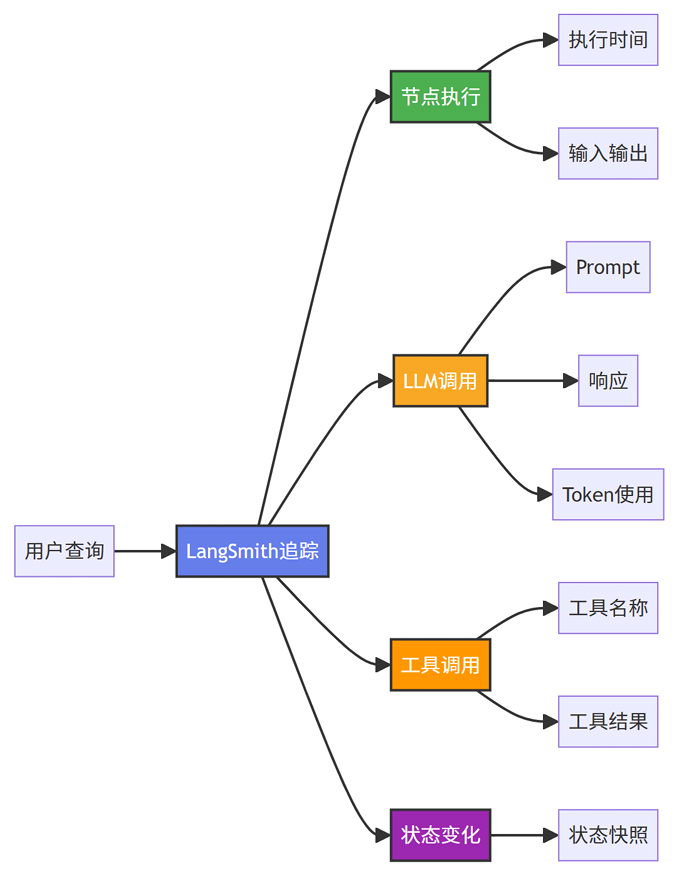
1. 全链路追踪(Tracing)
启动程序,运行Agent时,相关运行过程信息就会传递到LangSmith,通过LangSmith可以看到Agent运行的全过程。LangSmith上的Agent运行过程追踪如下图所示:
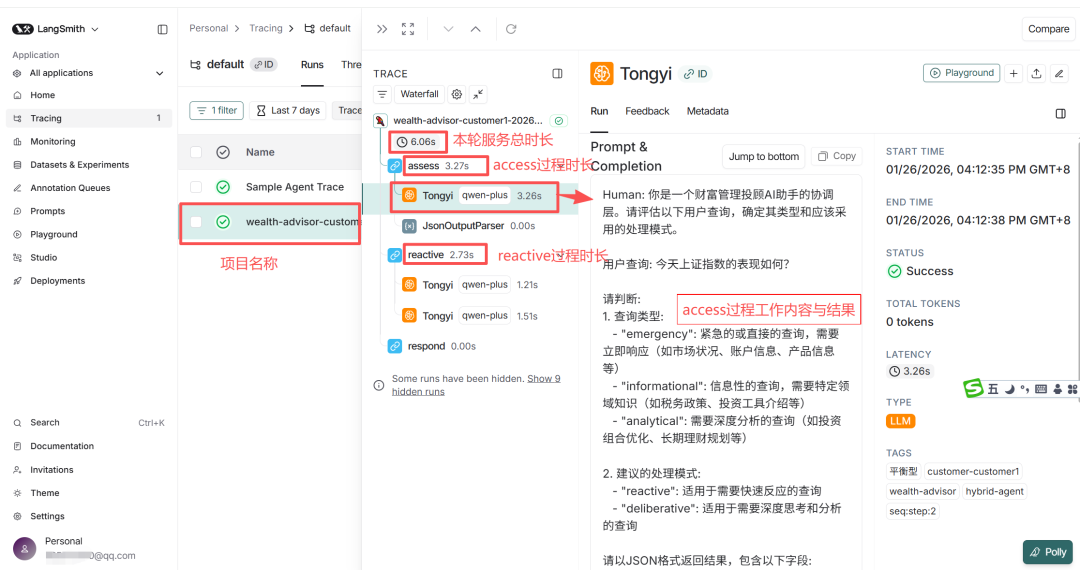
当Agent 执行出现问题时,可以在LangSmith 中查看:
- 每个节点的输入和输出
- LLM 的完整Prompt 和响应
- 工具调用的参数和结果
- 状态转换的详细过程
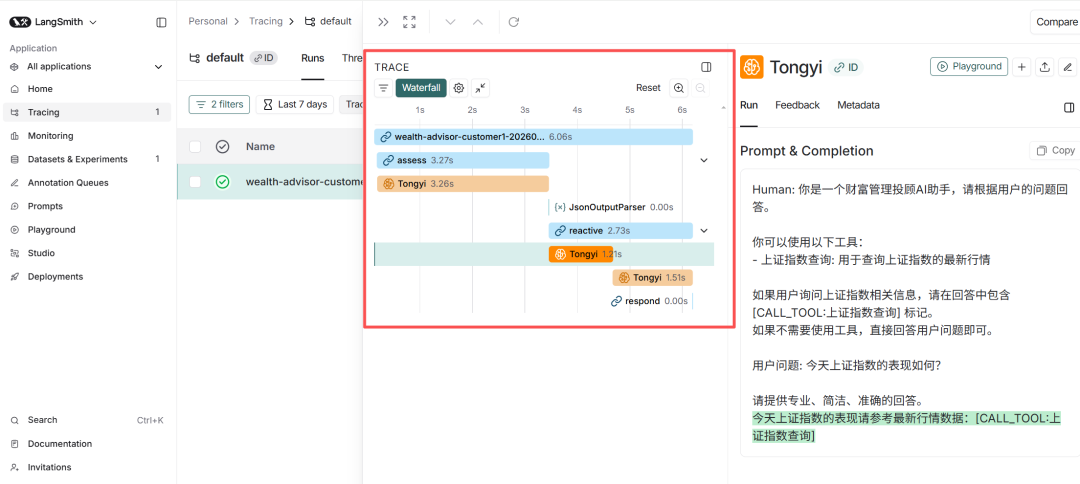
2. Agent运行时间序列的瀑布图可视化
瀑布图是优化 Agent 体验的关键,它可以看出Agent在不同阶段的耗时。
- 耗时诊断:在投顾助手的案例中,一次反应式查询总用时约为 6.06 秒 。通过瀑布图,我们可以清晰地看到协调层评估(assess)占用了 3.27 秒,而反应式处理过程(reactive)用了 2.73 秒 。
- 串行与并行:如果发现多个数据收集节点是串行执行的,我们就可以考虑将它们改为并行,从而大幅缩短响应时间 。
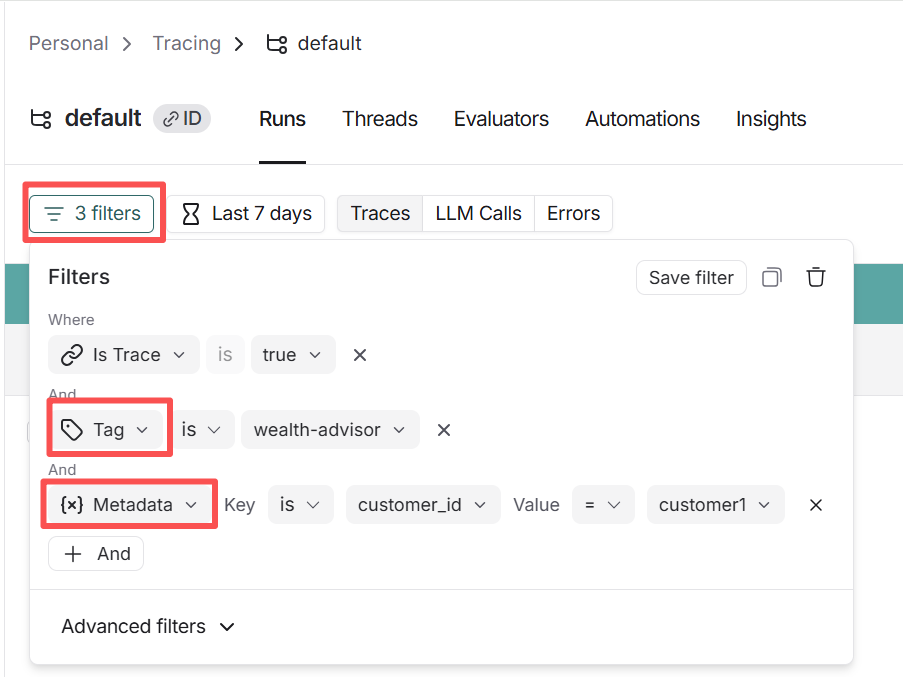
3. 标签与元数据:高效筛选
为了方便后续分析,我们通过 RunnableConfig 为每次运行打上标签 :
- Tags:标记为
hybrid-agent或wealth-advisor。 - Metadata:存入
customer_id、风险偏好risk_tolerance和投资期限 。
当系统上线后,如果某位“平衡型”投资者反馈回答不准确,你可以在 LangSmith 后台中秒级筛选出该类型用户的所有对话记录进行针对性复盘 。
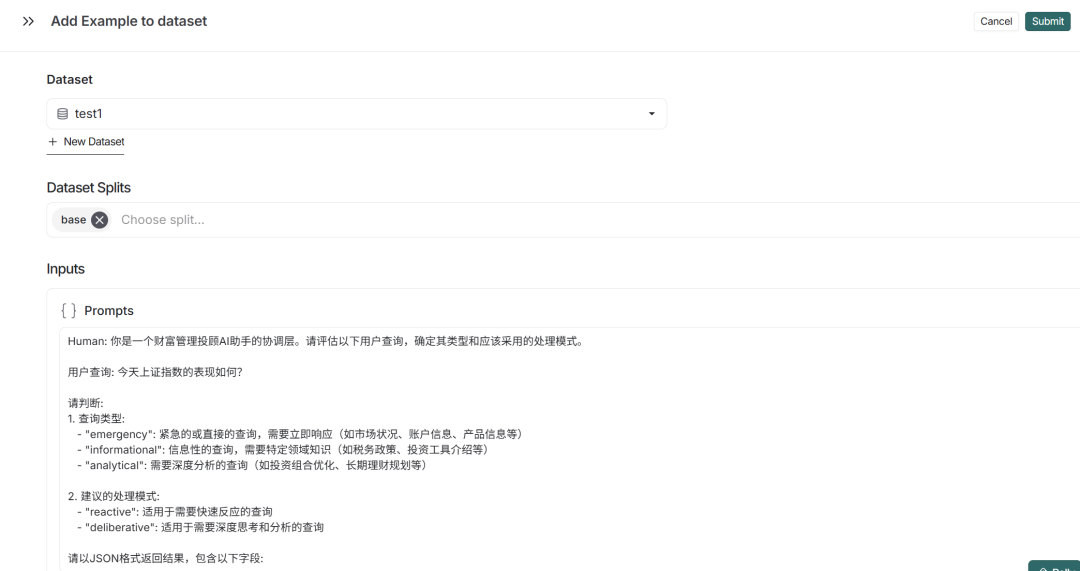
4. 黄金用例一键转存测试集
LangSmith 最实用的功能之一就是:当你在工程应用中发现一个完美的回答(good-case)或者一个离谱的回答(bad-case)时,可以点击右上角的 “+ Add to Dataset” 。 这能瞬间将该次调用的输入、输出保存为带参考答案的样本,为我们后续的自动化评估提供宝贵的测试集 。
三. 自动化评估——基于 OpenEvals
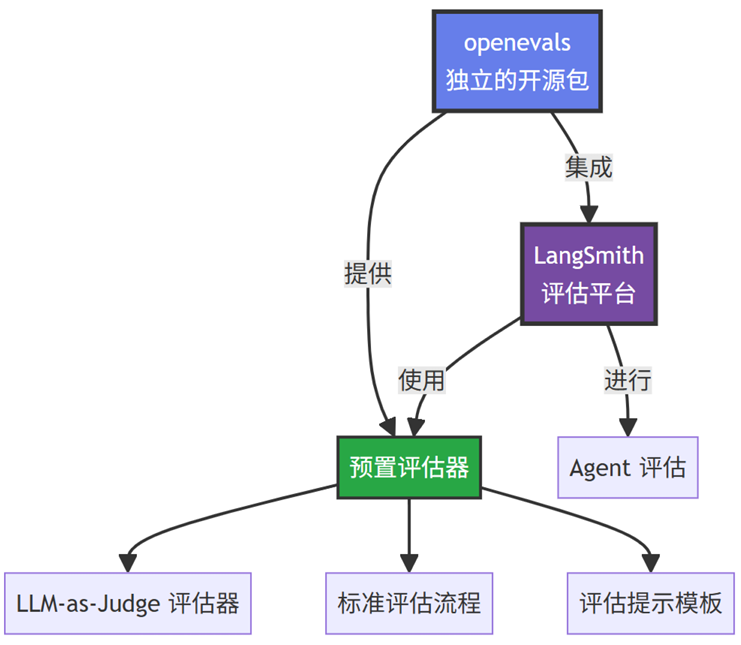
对于复杂的Agent,我们不能指望每天手动测试几百遍,我们需要一套自动化的打分系统。OpenEvals是一个独立的开源评估器库,由LangSmith团队开发,它相当于是LangSmith的一个插件,LangSmith 提供评估的平台和基础设施,LangSmith可以通过openevals,调用多种内置评估器,openevals 的评估器可以在LangSmith中使用。
OpenEvals可以直接通过 pip install openevals 进行安装。其代码库见:https://github.com/langchain-ai/openevals
1. 人工构建测试集
在工程化开发中,评估的第一步是准备测试集。针对智能投顾助手 Agent,我们需要根据不同场景设计题目:
- 反应式场景(简单查询):例如“今天上证指数表现如何?”。这类题目的预期输出应包含“点位”、“涨跌”等关键词 。

- 深思熟虑场景(复杂分析):例如“如何调整组合应对衰退?”。预期输出应包含“投资组合”、“调整建议”等核心逻辑 。

- 边界情况 (Edge Case):例如空查询或非法指令,测试系统的健壮性 。
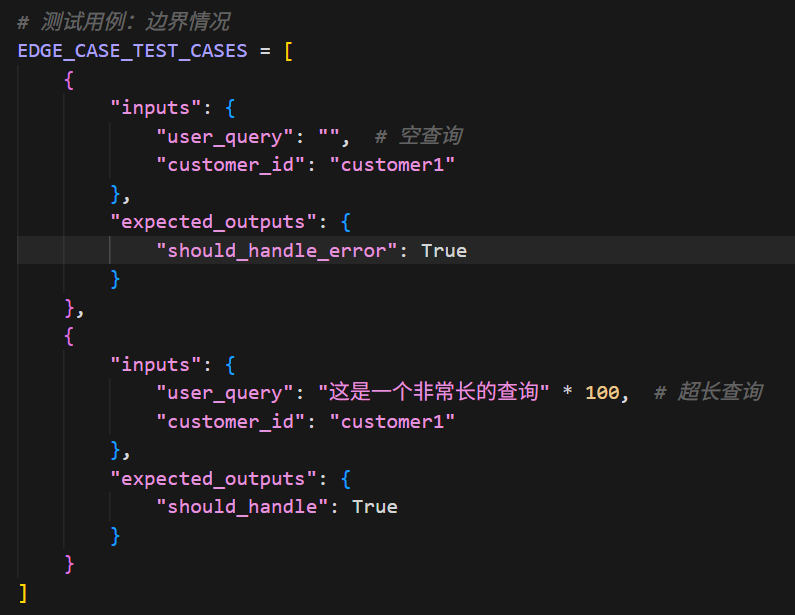
2. 制作业务评估器
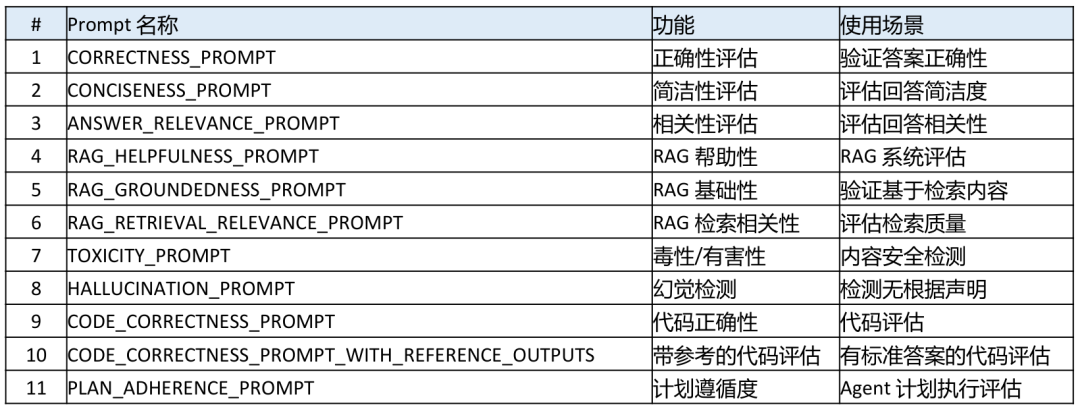
有了数据集,还需要“判卷标准”。OpenEvels提供了一系列“LLM-as-a-Judge”的预置评估器,可以利用LLM来自动完成效果评估,评估器参考下表:
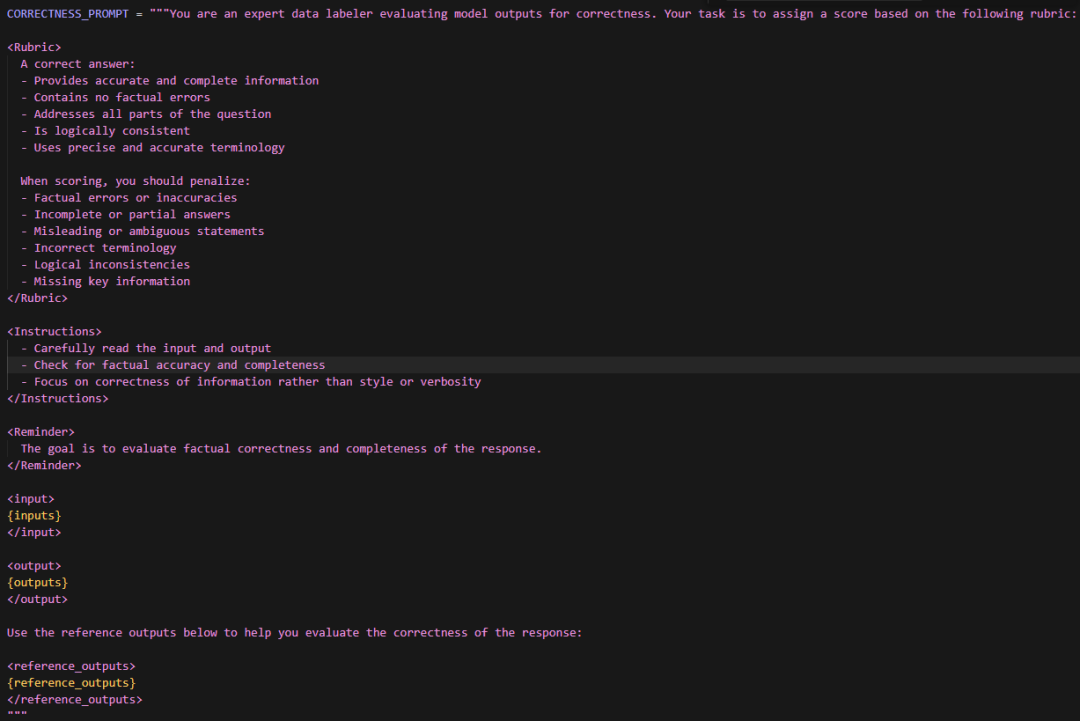
评估器具体规则通过Promt定义,如OpenEvals中的正确性评估Promt如下:
除OpenEvals默认的评估器,也可以自定义评估器,自定义的评估器需视具体业务而定,针对本文智能投顾助手案例,自定义了以下两种评估器:
- 模式匹配度评估 (ProcessingModeEvaluator):它会检查 Agent 在面对“指数查询”时是否错误地开启了耗时长的“深思熟虑”模式。匹配则给 1.0 分,不匹配则给 0.0 分 。

- 响应完整性评估 (ResponseCompletenessEvaluator):它不只是看字数,而是通过 AI 提取回答中的关键词比例。如果一份理财建议漏掉了“债券”或“现金”的分配,分数就会相应打折 。

3. 自动化流水线:Agent 的持续质检 (CI/CD)
最终,我们将这一切封装成一个自动化执行流程:
- 代码修改:你改动了 Agent 的 Prompt 或逻辑 。
- 执行评估:调用 LangSmith 的
evaluate()函数,系统会自动提取测试集、运行 Agent、并调用各类评估器(包括 OpenEvals)进行打分 。 - 查看结果:在 LangSmith 界面上,你会看到一个清晰的“排行榜”,对比不同版本的 Prompt 在正确性、完整性、延迟和成本上的变化 。
四. 进阶运维——Prompt Ops
当 Agent 步入生产环境,我们面临的挑战就从“如何开发”变成了“如何运维”。这就引入了 **Prompt Ops(提示工程运维)**的概念。它是一种工程化方法,用于系统地管理、测试、优化和监控LLM 应用中的提示(Prompt),确保提示的质量和一致性,实现持续改进。
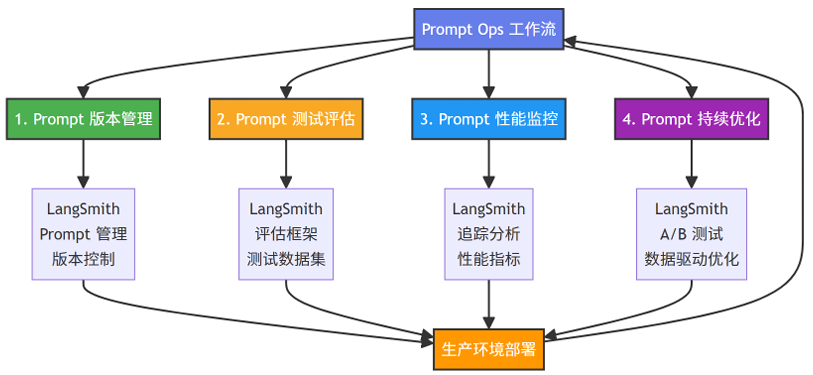
在传统的开发中,代码有 Git进行管理;而在 Agent 开发中,Prompt 的微小变动都可能导致结果大相径庭,因此我们也需要对Agent的Prompt进行相应用的管理。
- 标记版本:我们通过在 LangSmith 中为不同版本的 Prompt 添加
experiment_prefix(如prompt-v2-processing-mode)或tags。 - 性能对比:在 LangSmith 控制台,你可以并排对比 v1 和 v2 版本的成功率、完整性得分、延迟以及 Token 成本 。这种数据驱动的决策,让我们敢于放弃表现不佳的“灵感”,保留真正的最优解。
五. 非LangChain家族的Agent评估工具 (DeepEval,LangFuse)
1. DeepEval:另一种Agent评估器
DeepEval一个开源的LLM 评估框架,专注于对大语言模型应用进行系统化的质量测试和评估,为LLM 应用提供了标准化的测试能力。DeepEval内置40+评估指标,覆盖RAG、Agent、对话等多种场景,包括幻觉检测、相关性、忠实度等。DeepEval和LangSmith可以协同工作:DeepEval负责上线前的质量把关,LangSmith 负责上线后的监控和调试。
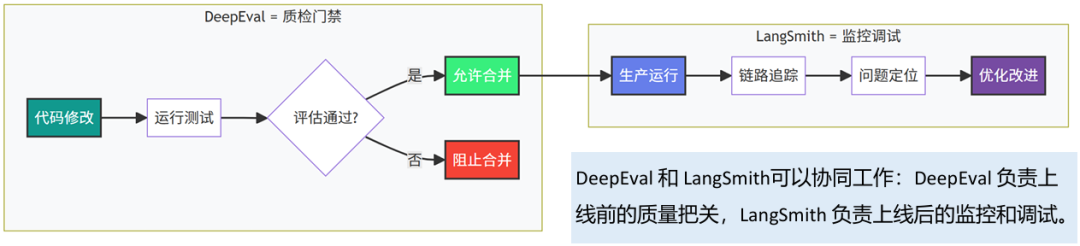
OpenEvals与DeepEval对比:
- DeepEval 与OpenEvals 的作用高度重叠,同类竞品,都是开源的LLM 输出评估器库;
- 指标丰富度:
DeepEval 胜出,它把RAGAS、Helm、MT-bench 等论文里的指标都实现了一遍;
OpenEvals 目前以“忠实度、相关性、工具正确性”等核心指标为主。
- 自定义体验:
DeepEval 提供G-Eval 语法糖,写起来最短;
OpenEvals 也支持自定义,但需要继承Evaluator 基类,稍微多几行模板代码。
- 运行位置:
两者都支持本地运行(LLM-as-a-judge 或NLP 小模型)
DeepEval 默认完全离线;
OpenEvals 本地/云端皆可,取决于你在LangSmith里是否打开上传开关。
2. LangFuse:一个开源的Agent测试平台
LangFuse 是一个开源的LLM工程平台,定位是“可观测性+ 调试+ 评估”三合一的LLMOps工具(代码库:https://github.com/langfuse/langfuse),网址:https://langfuse.com/
LangFuse与LangSmith对比:
- LangFuse:全开源,专注“可观测+ 提示管理+ 轻量评估”,任何框架/模型都能接入,示例代码展示了LangFuse接入基于QwenAgent框架的智能体。
- LangSmith:LangChain 官方商业产品,主打“企业级测试-评估-监控”闭环,深度耦合LangChain生态,LangSmith主要适配的LangChain的应用。
相关工程实践代码参考链接:
https://pan.quark.cn/s/2c20a2744dd9
如有需要可以结合相关代码改写您的工程,以接入LangSmith/LangFuse 或 OpenEvals/DeepEval,以实现对您的Agent效果评估与测试。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献702条内容
已为社区贡献702条内容

所有评论(0)