AI开发福音来了!大模型智能体生产级部署全攻略,Kubernetes容器化部署教程,让小白也能玩转AI架构
本文详细介绍了如何将火山引擎的AI智能体(VeADK Agent)部署到生产级Kubernetes容器服务(VKE)的完整流程,包括集群创建、安全配置、容器化、镜像推送、Kubernetes部署、弹性伸缩配置及API网关服务暴露。该方案为AI应用提供了安全可靠的环境、极致的弹性伸缩、全面的可观测性和开放的云原生生态,帮助开发者从实验阶段顺利过渡到生产成熟阶段。

背景
近年来,人工智能技术的发展正从模型为中心转向以应用为中心,智能体(Agent)作为 AI 应用的核心载体,其落地部署需求日益迫切。而随着 AI 应用向生产环境迁移,以 Kubernetes 为核心的云原生基础设施成为很多企业的默认选择,为 Agent 应用提供标准化、可扩展且具备成本效益的运行时环境势在必行。
根据 CNCF 最新发布的年度云原生调查:
Kubernetes 已从容器编排工具,发展为现代基础设施的核心,包括 AI 领域。在容器用户中,82% 已在生产环境使用 Kubernetes,66% 的 AI 采用者用它来扩展推理任务。Kubernetes 不再是小众工具,而是支撑规模、可靠性和 AI 系统的基础层。 —— CNCF Annual Cloud Native Survey The infrastructure of AI’s future
火山引擎的 Agent 开发套件(VeADK/AgentKit)目前已具备将 Agent 应用一键部署至函数服务(veFaaS)的能力。该路径为开发者提供了快速验证和轻量级部署的便利。然而,当 Agent 应用从实验阶段走向生产成熟阶段,其对环境的要求也随之提升。生产级应用通常需要更强的环境控制力、更复杂的依赖管理、更可靠的运行保障以及更精细的成本控制。因此,将 Agent 应用的部署目标从 veFaaS 延伸至火山引擎容器服务(VKE),是满足其生产化需求的一个可选的方向。
VKE 作为一个生产级的 Kubernetes 托管服务,能够提供:
- 安全可靠的环境:通过 IAM for Service Accounts (IRSA) 等机制实现细粒度的权限管控,避免敏感密钥硬编码。
- 极致的弹性伸缩:借助水平 Pod 自动扩缩容(HPA),根据负载自动调整资源,实现成本与性能的最佳平衡。
- 全面的可观测性:无缝集成日志服务、监控告警等系统,提供端到端的应用健康度洞察。
- 开放的云原生生态:与 API 网关、持续集成与持续部署(CI/CD)等工具链深度整合,加速应用交付与迭代。
本文旨在介绍一套将 VeADK Agent 部署至 VKE 的标准化路径,为 AI 应用提供一个真正意义上的生产级云原生托管方案,实现从开发、部署到运维的全生命周期高效管理。
一、操作流程
- 创建 VKE 托管版集群及节点池。
- 使用 IRSA 机制,安全地将应用与火山引擎的其他云服务 API 连接。
- 使用
Dockerfile将应用容器化,并将其推送到火山引擎容器镜像服务(CR)。 - 编写并应用 Deployment 和 Service 的 Kubernetes 声明式配置。
- 使用水平 Pod 自动扩缩容(HPA)配置应用的弹性伸缩。
- 使用火山引擎 API 网关将应用发布至公网。
- 日志查看与监控观测。
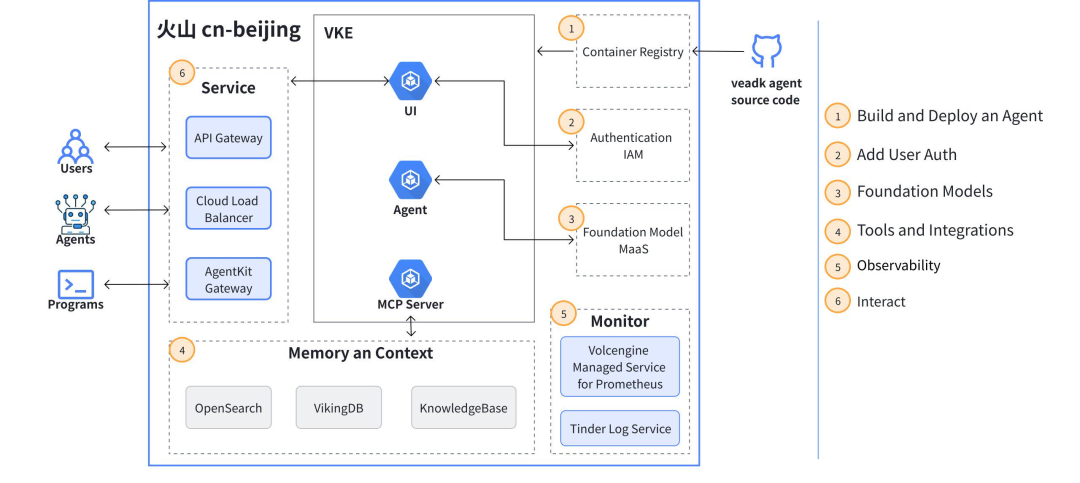
VeADK Agent 容器化部署实践
环境准备
在开始操作前,请完成以下准备工作。
火山引擎账号与访问密钥
你需要一个已完成实名认证的火山引擎账号,并创建访问密钥(Access Key),用于本地与云端资源的身份验证。
- 注册账号:若无账号,请前往火山引擎官网注册并完成实名认证。
- 创建访问密钥(AK/SK):
a. 登录火山引擎控制台。
b. 进入访问控制服务。
c. 在左侧导航栏选择用户,找到你的 IAM 用户(或新建用户)。
d. 点击用户名进入详情页,选择密钥管理标签页。
e. 点击新建密钥,生成 Access Key ID(AK)和 Secret Access Key(SK)。
重要提示:AK/SK 代表你的账户权限,请妥善保管,避免泄露导致安全风险。
配置本地开发环境
安装以下命令行工具,用于操作火山引擎 VKE 及 Kubernetes 集群。
- 安装 kubectl:
kubectl是与 Kubernetes 集群交互的标准命令行工具。请参考 Kubernetes 官方文档进行安装:https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/。 - 安装并配置火山引擎 CLI: 火山引擎 CLI 工具可以帮助你通过命令行管理云资源。
- 安装 CLI: 请参考火山引擎 CLI 官方文档进行安装:https://www.volcengine.com/docs/83927/1184023?lang=zh。
- 配置 CLI: 安装完成后,运行配置命令,并输入你之前创建的 AK/SK 和默认地域(例如
cn-beijing)。
volc configure
根据提示依次输入 AK、SK、Region 和 Output 格式。
Access Key ID [****************YQ==]: YOUR_ACCESS_KEY
Secret Access Key [****************NQ==]: YOUR_SECRET_KEY
Region [cn-beijing]: cn-beijing
Output [json]: json
开通所需云服务
请确保在火山引擎控制台已激活以下服务:
- 容器服务(VKE):用于部署与管理 AI 代理应用。
- 容器镜像服务(CR):用于存储应用容器镜像。
- API 网关(APIG):用于将服务公开至公网。
- 日志服务(TLS):用于收集与分析应用日志。
安装项目依赖
安装 uv 包管理器:
macOS / Linux(官方安装脚本)
curl -LsSf https://astral.sh/uv/install.sh | sh
或使用 Homebrew(macOS)
brew install uv
初始化项目依赖:
如果没有 uv 虚拟环境,可以使用命令先创建一个虚拟环境
uv venv --python 3.12
使用 pyproject.toml 管理依赖
uv sync
激活虚拟环境
source .venv/bin/activate
基础设施准备:创建 VKE 集群与节点
部署的第一步是搭建承载 Agent 应用的 Kubernetes 环境。
创建 VKE 托管版集群
首先,你需要创建一个 VKE 托管版集群作为 AI Agent 部署的基石。选择“托管版”可将 Kubernetes 控制面的管理工作(如扩缩容、升级和运维)交由火山引擎负责,使团队能更专注于业务应用。
- 创建集群
在终端中,创建一个名为 vke-veadk 的集群
ve vke CreateCluster --body '{
“KubernetesVersion”: “1.30”,
“Name”: “vke-veadk”,
“DeleteProtectionEnabled”: true,
“ProjectName”: “default”,
“ServicesConfig”: {
“ServiceCidrsv4”: [
“192.168.120.0/22”
]
},
“ClusterConfig”: {
“SubnetIds”: [
],
"ApiServerPublicAccessEnabled": true,
"ApiServerPublicAccessConfig": {
"PublicAccessNetworkConfig": {
"Bandwidth": 10,
"BillingType": 3
}
},
"ResourcePublicAccessDefaultEnabled": false
},
"PodsConfig": {
"PodNetworkMode": "VpcCniShared",
"VpcCniConfig": {
"SubnetIds": [
]
}
},
"KubernetesConfig": {
"ControlPlaneConfig": {
"KubeApiServerConfig": {
"AdmissionPlugins": {
"AlwaysPullImages": true
}
}
}
},
"MaintenanceWindowConfig": {
"Enabled": true,
"Duration": 4,
"WeeklyCycle": [
"Tuesday",
"Wednesday"
],
"StartTime": "17:00:00Z"
},
"MonitoringConfig": {
"ComponentConfigs": [
{
"Name": "KubeApiServer",
"Enabled": true
},
{
"Name": "KubeScheduler",
"Enabled": true
},
{
"Name": "Etcd",
"Enabled": true
},
{
"Name": "ClusterAutoscaler",
"Enabled": true
}
]
},
"LoggingConfig": {
"LogProjectId": "de71fc2e-\*\*\*",
"LogSetups": [
{
"LogType": "KubeApiServer",
"Enabled": true
},
{
"LogType": "KubeScheduler",
"Enabled": true
},
{
"LogType": "KubeControllerManager",
"Enabled": false
},
{
"LogType": "Etcd",
"Enabled": true
},
{
"LogType": "ClusterAutoscaler",
"Enabled": false
}
]
}
}’
说明:集群创建过程大约需要 5-10 分钟。请耐心等待。
- 创建节点池
在集群内创建一个或多个节点池,用于运行 Agent 应用的工作负载。建议根据应用对计算、内存或 GPU 的需求,选择合适的 ECS 实例规格。
Plain Text
ve vke CreateNodePool --body '{
"Name": "agent-nodes",
"KubernetesConfig": {
"Labels": [],
"Cordon": false,
"AutoSyncDisabled": false
},
"NodeConfig": {
"InstanceTypeIds": [
"ecs.g3il.xlarge",
"ecs.g3il.2xlarge",
"ecs.g3il.4xlarge"
],
"ImageType": "",
"ImageId": "image-ybqi99s7yq8rx7mnk44b",
"SubnetIds": [
],
"SystemVolume": {
"Size": 40,
"Type": "ESSD\_PL0"
},
"DataVolumes": [
{
"Size": 100,
"Type": "ESSD\_PL0"
}
],
"Security": {
"SecurityStrategies": [
"Hids"
],
"Login": {
}
},
"InstanceChargeType": "PostPaid",
"Period": 1,
"AutoRenew": true,
"AutoRenewPeriod": 1,
"AdditionalContainerStorageEnabled": true,
"HpcClusterIds": [],
"ProjectName": "default"
},
"AutoScaling": {
"DesiredReplicas": 3,
"SubnetPolicy": "ZoneBalance"
},
"Management": {
"Enabled": false
}
}’
- 生成 kubeconfig 并连接 VKE 集群
Plain Text
ve vke CreateKubeconfig --body '{
"Type": "Public"
}’
- 连接 VKE 集群
集群创建成功后,需要配置 kubectl 以便能够连接并管理它。
步骤1 获取 kubeconfig:
ve vke ListKubeconfigs
–body '{
“Filter”: {
"Types": ["Public"]
}
}’ | jq -r ‘.Result.Items[0].Kubeconfig’
步骤2 在你的本地终端中,粘贴并执行该命令:
示例命令,请以你控制台实际生成的为准
export
KUBECONFIG=~/.kube/config_vke_adk-vke-cluster_****
kubectl config use-context adk-vke-cluster
步骤3 执行完成后,运行以下命令验证是否已成功连接到集群:
kubectl get nodes
如果能看到你创建的节点信息列表,说明连接已成功建立。从现在起,你的 kubectl 命令都将指向这个新的 VKE 集群。
开启安全围栏配置(IRSA)
为了保障云服务访问的安全性,本方案采用 IAM for Service Accounts (IRSA) 机制,避免在应用代码或容器镜像中硬编码或存储静态的访问密钥(AK/SK)。
IRSA 的核心机制是将 Kubernetes 的服务账号(ServiceAccount, KSA)与火山引擎的 IAM 角色进行绑定。当一个 Pod 被配置为使用此 KSA 启动时,VKE 会自动为其注入临时的、具有特定权限的安全凭证。这样,Pod 内的应用程序(即 Agent)便可通过标准 SDK 直接调用其被授权的云服务 API,无需任何手动密钥配置。
开启 IRSA 请参考 VKE 产品文档:https://www.volcengine.com/docs/6460/1324613?lang=zh。
- 创建 IAM 角色
在 IAM 控制台,新建 OIDC 身份提供商类型的 IAM 角色,比如:agent_onvke。
- 给角色授予所需要的权限
这里以方舟大模型权限为例:
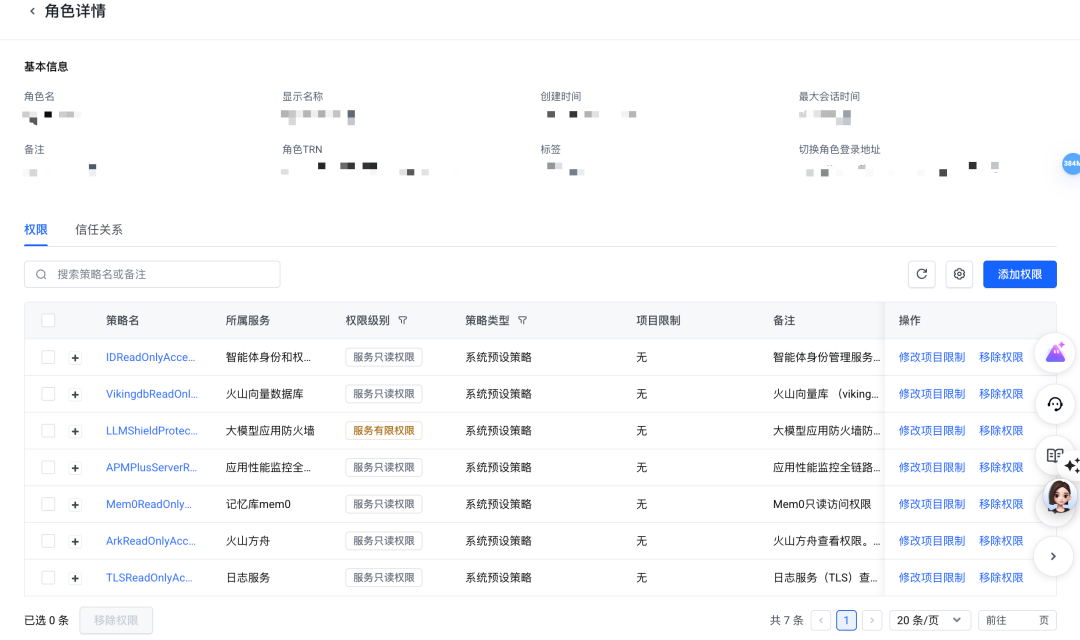
- 授权 VKE 集群内指定命名空间(NameSpace)下的服务账号(Service Account)
如 veadk-agent-sa,允许扮演上述创建的 IAM 角色。代码示例如下:
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献604条内容
已为社区贡献604条内容

所有评论(0)