卧槽!国产AI三巨头集体发力,1万亿参数大模型碾压GPT,编程小白也能秒变大神!
国内三家AI厂商发布大模型新版本:阿里Qwen3-Max-Thinking拥有1万亿参数,超越GPT-5.2;DeepSeek-OCR 2引入视觉因果流,准确率达91.09%;KIMI K2.5支持原生多模态和Agent Swarm。三款模型在推理、视觉理解和代码生成方面均有突破,展现国产AI技术实力。
国内三家AI厂商发布大模型新版本:阿里Qwen3-Max-Thinking拥有1万亿参数,超越GPT-5.2;DeepSeek-OCR 2引入视觉因果流,准确率达91.09%;KIMI K2.5支持原生多模态和Agent Swarm。三款模型在推理、视觉理解和代码生成方面均有突破,展现国产AI技术实力。
🍾Qwen3-Max-Thinking(0123)
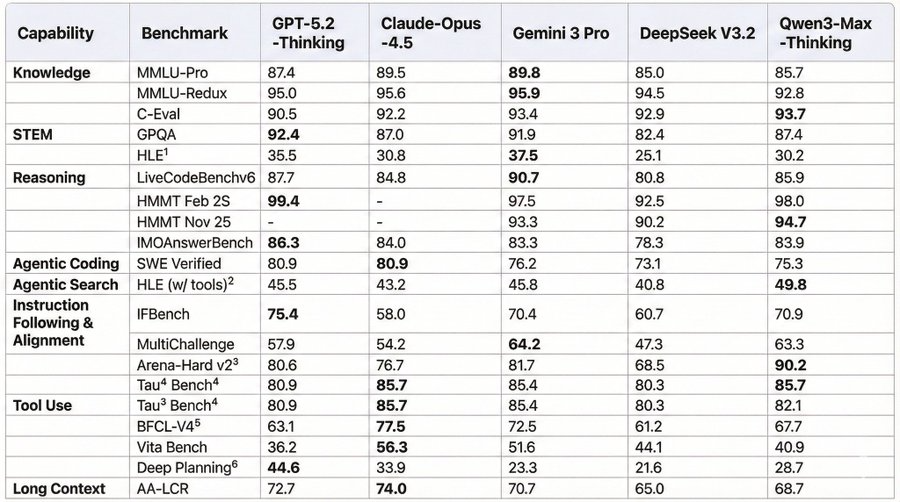
🚀今天阿里重磅发布Qwen3-Max-Thinking,多项基准测试碾压GPT-5.2-Thinking、Gemini 3 Pro和Claude-Opus-4.5!
💪 核心亮点
🧠 史上最强推理能力
- 预训练规模高达36万亿token,参数规模达1万亿
- 在Humanity’s Last Exam (HLE)测试中创下58.3分的惊人成绩,超越Gemini 3 Pro近13分!
- 复杂数学能力爆表:HMMT Feb测试拿下98.0高分
Qwen旗舰模型貌似一直都是不开放权重的,所以不要惊讶为什么不OSS
换句话说,确定你的设备能跑1T参数的大模型??😏
⚡ 革命性"经验累积"测试时扩展技术 不同于简单的多轮采样,Qwen3-Max-Thinking采用智能迭代策略:
- 每轮推理后自动提炼关键洞见(Insights)
- 避免重复推导,专注攻克未解决难点
- 就像做题时专门检查不确定的地方,而不是盲目重做
最大亮点是用了“测试时扩展技术(Test-Time Scaling)” (此TTS非彼TTS🤣), 据说这是本次跑分飙升的秘密武器。不是简单地多跑几遍取最优,而是基于所谓的“经验累积式多轮迭代策略”,即每轮推理后提炼关键洞见,避免重复推导已知结论,专注攻克未解决的难点。
🤖 原生代理能力全面升级
- 自适应工具调用:智能Search、Memory、Code Interpreter
- 大幅减少幻觉,专业级准确度
- 真正实现"想到即做到"的AI助手体验
智能Search:无需手动打开搜索引擎,模型自行判断是否需要联网搜索
Memory:用户偏好可存储于平台端记忆模块,模型根据需要自动调用
Code Interpreter:允许模型在对话过程中编写、执行和验证 Python 代码,运行在安全的沙箱(sandbox)环境中。比如旧模型解决不了类似计算“内部收益率(IRR)”这种trial error类型的问题,现在可以完美解决。✨
🍾视觉模型:DeepSeek-OCR 2
DeepSeek-OCR-2 是 DeepSeek AI 于今日(2026年1月27日)刚刚开源发布的新一代 OCR 模型(Hugging Face 和 GitHub 已上线,论文同步发布),社区讨论非常热烈,主要焦点集中在以下几点:
💎核心创新
- 打破“死板”的阅读顺序 > 传统的视觉模型(VLM)读图是“光栅扫描”式的(从左到右,从上到下),这很机械。
- 模仿人类视觉逻辑 > 人看复杂的文档(比如带表格、插图的论文)是有逻辑跳转(标题 > 正文 > 查图表)。
- DeepSeek-OCR2的核心增量 = 引入了“视觉因果流”(Visual Causal Flow)。它不按像素位置硬读,而是先理解语义,再按逻辑顺序把视觉信息“重排”给大模型看。
💡性能表现
-
OCR 准确率从上一代的 87.36% 提升至 91.09%(提升约 3.73-4%),编辑距离降低到 0.100。
-
在基准测试中超越 Gemini 3 Pro 等闭源模型,特别是在复杂文档布局、表格和数学公式识别上表现突出。
📢社区反馈
-
许多人认为这是 OCR 领域的重大进展,“AI 阅读方式更接近人类”,为未来多模态模型铺路。
-
部分讨论提到发布时机巧妙(紧随阿里 Qwen 系列之后),显示 DeepSeek 在视觉领域的快速迭代。
-
开源友好:模型支持 vLLM/Transformers 推理,已有 Unsloth 等工具支持 fine-tune,社区期待本地部署和应用测试。
-
少量吐槽:视觉编码器仍基于较老的 Qwen2-0.5B(非最新版),但整体评价高度正面,被赞“低调却炸裂”。
总之,静等Deepseek R2发布…
🍾KIMI K2.5
月之暗面(Moonshot AI)这次没有大张旗鼓宣传,而是采用了“静默推送”(silent rollout)的策略:用户打开 kimi.com 官网聊天界面或App,发现原本的K2模型已经自动升级成了K2.5,无需手动操作或额外公告。这也是为什么社区讨论目前看起来不算特别爆炸——很多人在上午/中午才陆续发现,热议还在发酵中。
🎉核心亮点
- 模型定位:Kimi迄今为止最智能、最全能的开源模型,原生多模态(native multimodal),支持文本+图像+视频输入,同时支持思考模式(thinking mode)和非思考模式、对话模式与Agent模式无缝切换。
- 参数规模:基于Kimi K2的1T总参数MoE架构(激活32B),继续预训练了约15万亿混合视觉-文本token。
- 性能(开源SOTA级别):
- Agent基准:HLE full set 50.2%、BrowseComp 74.9%(全球领先)
- 视觉理解:MMMU Pro 78.5%、VideoMMMU 86.6%
- 代码能力:SWE-bench Verified 76.8%(开源领先),特别强在“视觉编码”(visual coding),能直接从聊天、图片、视频生成美观的前端网站、带交互动画和动态布局。
- 最大创新:Agent Swarm(智能体集群,Beta)模型可以自主创建“分身”(sub-agents),最多并行调度100个子智能体,执行最多1500次工具调用,效率比单智能体提升最高4.5倍。适合处理超复杂、需要分解的任务(比如大型办公文档、研究项目)。
- 办公场景:号称“让人人精通Office”,能生成准专业水平的Word、Excel、PPT、PDF,甚至上万字论文、百页文档、金融模型、LaTeX公式等。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献625条内容
已为社区贡献625条内容

所有评论(0)