OPPO端侧AI算法优化在智慧语音和AI搜索实践【多图】
摘要:OPPO在2025 AICon大会上分享了端侧AI的实践成果。面对终端设备内存有限、电量不足等挑战,OPPO通过模型稀疏化压缩、量化感知训练和编解码加速三大技术,实现了7B大模型的端侧落地。数据显示,AndesVL-4B模型在高稀疏度下性能保持稳定,量化后OCR测试得分提升至95.8,解码速度达50.02 token/s。未来将聚焦超长上下文处理、NPU适配和端云协同,持续拓展端侧AI应用场
AI开发现在对于我最直观的感受是内存和显卡价格涨疯了。模型更新太快,落地业务逐渐开花,这是基于2025 AICon大会的OPPO端侧算法组宋晓辉《OPPO 多模态大模型端侧化应用实践》分享再oppo 智慧语音端侧化 和AI搜索上的落地实践。
在终端设备内存有限、电量宝贵、业务强耦合且OTA成本较高的约束下,OPPO端侧化算法组围绕模型高效部署展开深度探索,通过模型稀疏化压缩、量化感知训练、编解码加速三大核心技术路径,实现了端侧AI在效果、性能与功耗间的平衡,成功落地多个核心业务场景,为行业提供了可复用的实践经验。
一、核心观点
- 端侧AI的核心挑战集中于资源约束与业务适配,需在有限内存、电量条件下,兼顾多业务共用基模型的兼容性与低OTA更新频率下的稳定性,算法优化需贯穿模型设计、训练、部署全流程。
- 技术优化应采用 “架构创新+工程协同” 思路,通过结构化剪枝、量化感知训练等算法创新压缩模型体积、提升推理效率,同时联合芯片厂商与工程团队实现底层适配,确保技术落地可行性。
- 端侧AI的未来发展聚焦于超长上下文处理、端云协同与硬件适配,需持续突破NPU高性能架构、OS层资源调度等技术瓶颈,拓展隐私计算、具身智能等创新场景。
二、数据总结
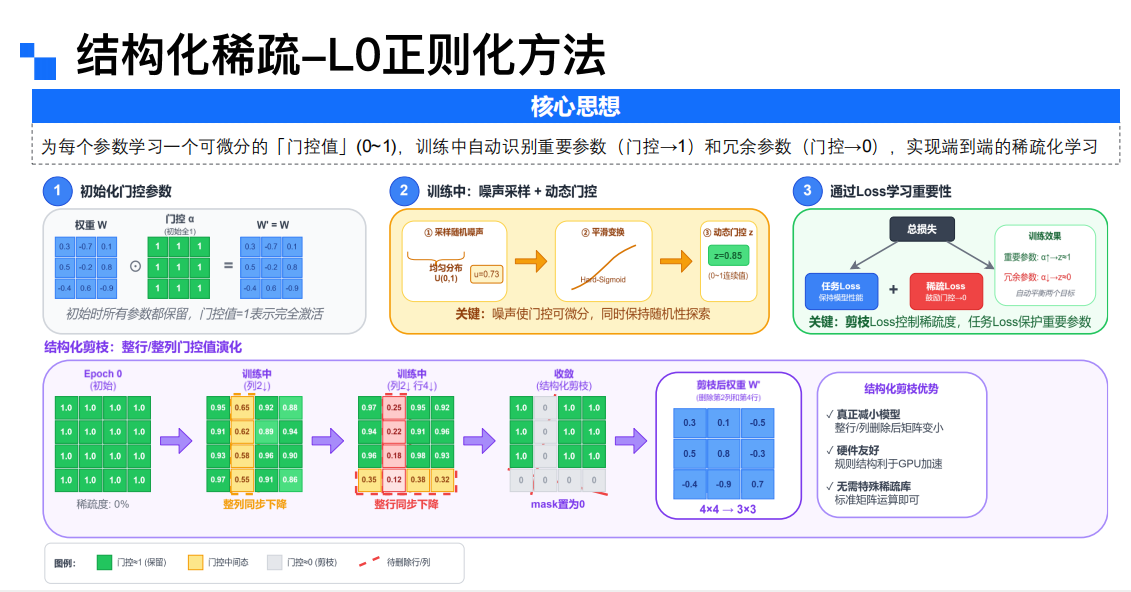
- 模型稀疏化效果:Qwen7B剪枝至4B后,在c3、clozet等多数据集上综合性能接近原始模型;AndesVL-4B在75%高稀疏度下,caption任务maxF1分数仍达48.87,autofill任务F1-Score保持0.933以上,核心能力无显著衰减。
- 量化训练提升:AndesVL-4B采用QAT+PTQ方案后,DocVQA、TextVQA等4个OCR基准测试综合得分从90.7提升至95.8,与浮点模型输出一致性超95%;QALFT框架相比传统QAT+PTQ方案,效果损失从3.93%降至1.43%。
- 推理与压缩效率:搭载MediaTek 9500芯片的设备,解码速度提升44.7%,达到50.02 token/s;BPV(每值比特数)降低33.6%,低至1.98;端侧模型峰值推理速度达240 tok/s,4B模型推理响应时间仅4秒,支持128K超长上下文与20万字级文档本地处理。
- 业务落地成果:OS14.0实现行业首个端侧7B大模型落地,OS16.0通过多模态基模型复用,实现通话摘要、AI搜索、记忆仓等多场景覆盖,通话摘要可精准提取行程规划、景点推荐等核心信息。
三、经验技巧
-
稀疏化优化策略:采用“动态交替剪枝”模式,结合L0正则化与梯度缩放因子,平衡剪枝速度与模型效果;针对不同层特性分配非均匀稀疏度(敏感层30%、冗余层80%),避免核心能力损失;利用硬件支持的2:4结构化稀疏或不规则稀疏模式,兼顾计算加速与存储优化。
-
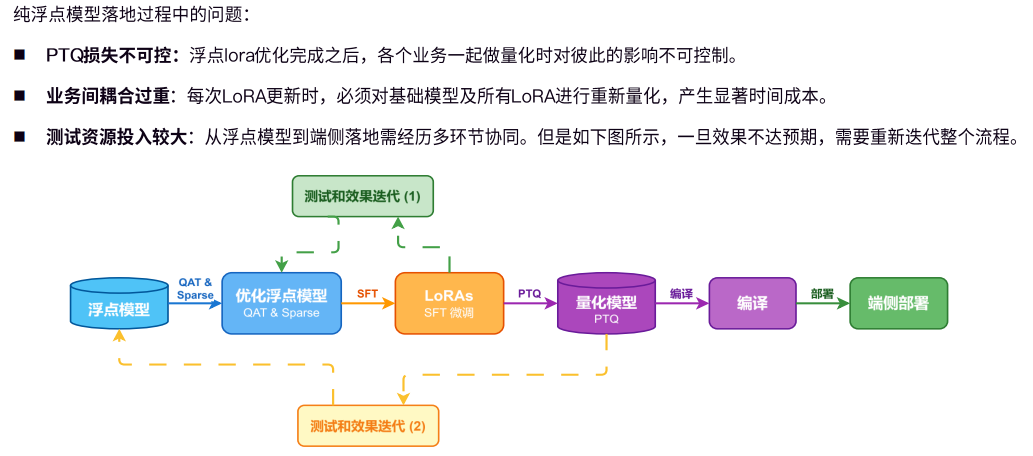
量化训练实践:构建自研QALFT框架,实现模型、数据、训练器解耦,支持SFT、蒸馏等多范式与MTK/Qualcomm多平台适配;采用动态精度分配与端到端静态量化,细粒度识别高敏感点位,绕过PTQ迭代不确定性,降低部署损失;通过LoRA微调与量化感知训练结合,解决多业务量化相互干扰问题。
-
编解码加速方法:采用“草稿模型+验证模型”两阶段方案,通过topk采样与total_tokens排序提升草稿接受率,减少重复推理;融合KV-Cache压缩与Prompt压缩技术,控制长文本推理的内存膨胀与计算量;针对端侧硬件特性优化解码逻辑,利用Tensor Core等硬件加速单元提升执行效率。
-
工程落地保障:建立“算法-工程-芯片”协同机制,在模型设计阶段同步考虑硬件适配;采用多维度测试体系,覆盖算法质量、稳定性、功耗、发热等指标,降低OTA更新风险;通过模块化、零代码化部署框架,提升多业务快速适配能力。
四、核心要点概括

- 技术聚焦:以稀疏化、量化、编解码加速为核心,突破端侧资源约束,实现模型“轻量化+高性能”平衡。
- 落地关键:通过框架自研、硬件协同、多场景复用,将技术优化转化为实际业务价值,保障效果与体验双提升。
- 未来方向:聚焦超长上下文处理、NPU架构适配、端云协同,拓展隐私化、智能化端侧AI应用边界。
2025年AI Con大会 其他pdf下载,关注 “A小码哥” 公众号,回复 “AiCon” 获取下载地址
本文分享pdf下载地址:https://www.wesee.club/usr/uploads/2025/12/1986711299.pdf

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)