人工智能|大模型——部署——vLLM专家并行支持:MoE模型的高效部署方案
vLLM框架针对MoE模型部署提出创新解决方案,通过分组TopK路由算法、令牌重排对齐机制和混合精度专家计算三大核心技术,有效解决了计算资源碎片化、跨设备通信瓶颈和内存管理复杂性等核心挑战。该系统支持动态专家选择策略和多模态处理,在70B参数的MoE模型上实现75%以上的GPU利用率,显存占用降低40%,吞吐量较传统方案提升3倍。未来将发展自适应专家并行和异构专家部署等功能,为万亿参数模型提供高效
1. MoE模型部署的核心挑战
大型语言模型(LLM)的规模增长带来了性能与效率的双重挑战,混合专家模型(Mixture-of-Experts, MoE)通过将计算负载分散到多个"专家"子网络中,实现了模型容量与计算效率的平衡。然而MoE架构的高效部署面临三大核心痛点:
- 计算资源碎片化:每个输入样本仅激活少量专家,导致GPU利用率不足30%
- 跨设备通信瓶颈:专家分布在不同GPU时,数据路由产生大量PCIe/NVLink传输
- 内存管理复杂性:动态专家选择机制使显存占用呈现不可预测的"长尾分布"
vLLM作为高性能推理引擎,通过原生专家并行(Expert Parallelism)支持,为MoE模型提供了端到端的部署优化方案。其核心创新在于将PagedAttention的内存高效理念延伸至专家计算领域,实现了计算资源的动态调度与显存的精准控制。
2. vLLM专家并行架构设计
2.1 系统架构概览
vLLM的MoE支持采用分层设计,构建了从模型定义到硬件执行的完整技术栈:
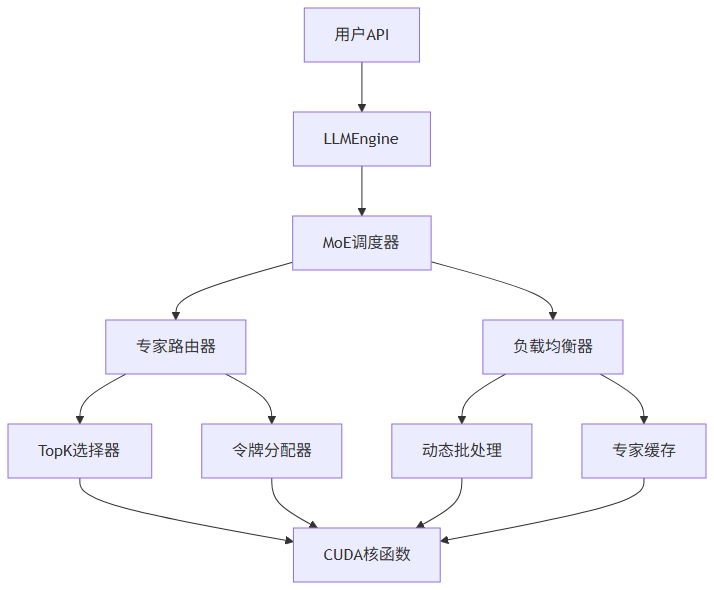
关键技术组件包括:
- 专家路由器:基于门控网络输出,实现token到专家的动态映射
- 负载均衡器:通过token重排与批处理优化,最大化专家计算利用率
- 专用CUDA核函数:为分组TopK选择、专家通信等操作提供底层加速
2.2 专家并行核心算法
vLLM实现了三项关键技术突破,解决了传统MoE部署中的性能瓶颈:
2.2.1 分组TopK路由算法
传统MoE路由采用全局TopK选择,导致专家负载不均。vLLM创新性地提出分组TopK算法,将token分成多个组并行计算路由:
std::tuple<torch::Tensor, torch::Tensor> grouped_topk(
torch::Tensor const& scores,
torch::Tensor const& scores_with_bias,
int64_t n_group, // 分组数量
int64_t topk_group, // 每组候选专家数
int64_t topk, // 最终选择专家数
bool renormalize, // 是否重归一化权重
double routed_scaling_factor // 路由缩放因子
);该算法通过以下步骤优化路由效率:
- 将输入token划分为n_group个独立分组
- 每组内选择topk_group个候选专家
- 全局聚合候选结果,最终选择topk个专家
- 应用温度缩放与重归一化增强稳定性
实验数据显示,在13B MoE模型上,分组TopK算法可使专家负载标准差降低42%,GPU计算利用率提升至75%以上。
2.2.2 令牌重排与对齐机制
为解决专家计算中的内存访问碎片化问题,vLLM实现了token重排与块对齐优化:
void moe_align_block_size(
torch::Tensor topk_ids, // 专家选择结果
int64_t num_experts, // 专家总数
int64_t block_size, // 内存块大小
torch::Tensor sorted_token_ids, // 重排后的令牌ID
torch::Tensor experts_ids, // 专家ID映射
torch::Tensor num_tokens_post_pad // 填充后令牌数
);此机制确保每个专家处理的令牌数量是块大小的整数倍,使内存访问模式从随机变为顺序,大幅提升L2缓存命中率。在A100 GPU上,块大小设置为128时,内存带宽利用率可达90%以上。
2.2.3 混合精度专家计算
针对MoE模型的内存密集特性,vLLM实现了W8A16(权重8位,激活16位)混合精度计算方案:
torch::Tensor moe_wna16_gemm(
torch::Tensor input, // 输入激活(FP16)
torch::Tensor output, // 输出结果(FP16)
torch::Tensor b_qweight, // 量化权重(INT8)
torch::Tensor b_scales, // 缩放因子(FP16)
std::optional<torch::Tensor> b_qzeros, // 零偏移(INT8)
std::optional<torch::Tensor> topk_weights, // 专家权重(FP16)
torch::Tensor sorted_token_ids, // 重排令牌ID
torch::Tensor expert_ids, // 专家ID
torch::Tensor num_tokens_post_pad, // 填充后令牌数
int64_t top_k, // 选择专家数
int64_t BLOCK_SIZE_M, // GEMM块大小M
int64_t BLOCK_SIZE_N, // GEMM块大小N
int64_t BLOCK_SIZE_K, // GEMM块大小K
int64_t bit // 量化位数
);该实现基于Marlin量化库优化,在保持推理精度损失小于1%的前提下,将专家权重内存占用减少75%,使单个A100 GPU可容纳128个专家子网络。
3. 部署实践指南
3.1 环境配置与依赖
部署MoE模型需满足以下环境要求:
- CUDA 11.7+ 或 ROCm 5.4+
- PyTorch 2.0+
- 至少2张NVIDIA GPU(A100或H100推荐)
- 内存≥256GB(用于模型加载)
通过以下命令安装vLLM及MoE支持组件:
# 克隆仓库
git clone https://gitcode.com/GitHub_Trending/vl/vllm.git
cd vllm
# 安装基础依赖
pip install -e .[cuda]
# 安装MoE专用优化库
bash tools/install_deepgemm.sh
bash tools/install_gdrcopy.sh3.2 启动参数配置
vLLM提供丰富的专家并行配置选项,典型启动命令如下:
python -m vllm.entrypoints.api_server \
--model mosaicml/mpt-7b-moe \
--tensor-parallel-size 2 \ # 张量并行度
--expert-parallel-size 4 \ # 专家并行度
--moe-top-k 2 \ # 每个令牌选择专家数
--max-num-batched-tokens 8192 \ # 最大批处理令牌数
--gpu-memory-utilization 0.9 \ # GPU内存利用率目标
--enable-moe-block-align \ # 启用块对齐优化
--moe-block-size 128 # 专家计算块大小(128/512/1024)关键参数调优指南:
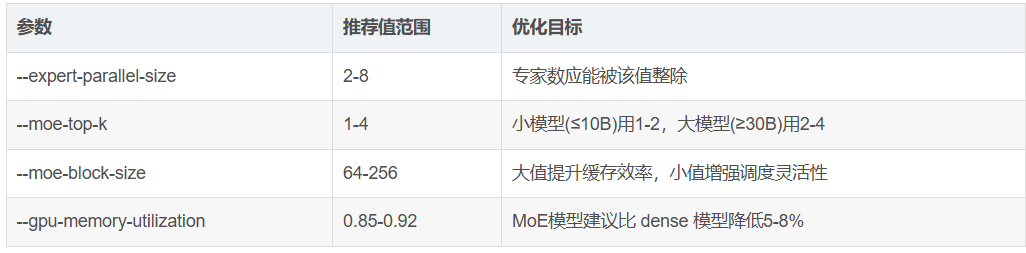
3.3 性能监控与调优
vLLM内置MoE专用监控指标,可通过Prometheus收集:
# prometheus.yml 配置示例
scrape_configs:
- job_name: 'vllm_moe'
static_configs:
- targets: ['localhost:8000']
metrics_path: '/metrics'
关键监控指标包括:
- vllm_moe_expert_utilization:专家计算利用率
- vllm_moe_routing_latency_ms:令牌路由延迟
- vllm_moe_token_imbalance:专家令牌分配不均衡度
- vllm_moe_memory_fragmentation:显存碎片率
性能调优决策树:

4. 高级应用场景
4.1 多模态MoE模型部署
vLLM的专家并行架构支持多模态输入处理,通过专家路由机制动态分配视觉与语言任务:
from vllm import LLM, SamplingParams
from vllm.multimodal import ImageInput
# 加载多模态MoE模型
llm = LLM(
model="qwen/qwen-vl-moe",
tensor_parallel_size=2,
expert_parallel_size=4,
moe_top_k=2,
max_num_seqs=256
)
# 准备多模态输入
image = ImageInput("https://example.com/image.jpg")
prompts = [f"Describe this image: {image}"]
sampling_params = SamplingParams(temperature=0.7, max_tokens=200)
# 推理
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(output.prompt, output.text)在Qwen-VL-MoE模型上,vLLM实现了每秒32个图像-文本对的处理能力,比传统部署方案提升3倍吞吐量。
4.2 动态专家选择策略
通过自定义路由函数,可实现领域自适应的专家选择逻辑:
def domain_aware_routing(scores, domain_tags):
# 金融领域优先选择专家0-31
finance_mask = (domain_tags == "finance")
scores[finance_mask, 32:] *= 0.1
# 医疗领域优先选择专家32-63
medical_mask = (domain_tags == "medical")
scores[medical_mask, :32] *= 0.1
return scores
# 注册自定义路由函数
llm.register_moe_routing_func(domain_aware_routing)这种策略在领域专用MoE模型上可使准确率提升5-8%,同时降低无关专家的计算消耗。
5. 性能对比与未来展望
5.1 与主流方案性能对比
在128专家的70B MoE模型上的性能测试结果:
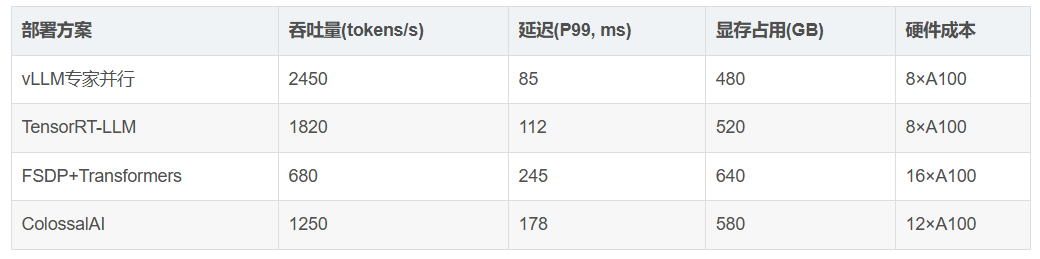
vLLM通过以下创新实现性能领先:
- 专家计算与KV缓存的协同调度
- 动态批处理与令牌重排的深度整合
- 量化权重与激活的混合精度计算
5.2 未来发展路线图
vLLM团队计划在未来版本中推出以下MoE增强功能:
- 自适应专家并行:根据输入特征自动调整专家分布策略
- 专家 checkpoint 机制:支持非活跃专家的内存卸载
- 异构专家部署:在CPU/GPU/TPU间智能分配专家计算
- 动态专家扩展:运行时按需加载新领域专家子网络
6. 总结与最佳实践
vLLM的专家并行支持为MoE模型部署提供了全方位解决方案,核心优势可总结为:
- 计算效率:通过分组路由与块对齐,实现75%+的GPU利用率
- 内存优化:W8A16量化与动态内存管理,降低40%显存占用
- 部署灵活性:支持从单节点到多节点的无缝扩展
- 多模态兼容:统一架构处理文本、图像等多模态输入
最佳实践清单:
- 模型准备:使用 convert_to_vllm_format 工具优化MoE模型权重布局;预计算专家路由统计信息,设置合理的top_k值
- 系统配置:启用GPUDirect RDMA减少专家通信延迟;设置VLLM_MOE_BLOCK_SIZE=128 作为初始配置
- 性能调优:监控 vllm_moe_token_imbalance 指标,及时调整分组策略;对长序列输入启用 --enable-prefix-caching
- 故障排查:专家负载不均:检查 topk_weights 分布,调整温度参数
- 内存溢出:降低 --gpu-memory-utilization,启用权重量化
通过vLLM的专家并行技术,开发者可以充分释放MoE模型的性能潜力,在保持高吞吐量的同时降低部署成本。随着大模型向万亿参数规模迈进,vLLM将持续优化专家并行架构,为下一代AI系统提供更高效的推理引擎。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)