基于Docker Desktop 和 Ubuntu 在 Windows上部署轻量化大模型(Qwen-LLM)
目录
引言
近年来,大模型被广泛应用于各行各业的生产活动中,Gemini,Chat-GPT,豆包,deepseek,千问,Grok等各种大模型层出不穷,功能和性能上也不尽相同。而大模型的缺点也逐渐显露:在面对没见过的样本会出现幻觉,长期记忆很难保持等等。而对于这些问题,一些研究者和公司也给出了相应的处理方案,比如OpenAI采用Notebook,记录关键信息加强大模型的长期记忆能力。一些研究者也通过微调优化和模块优化改善幻觉问题,这也使得对于大模型的改进成为了近年比较热门的科研方向之一。
对于以上相关研究或者平时个人的一些需求,我们可以通过Docker Desktop来实现本地轻量化Frozen Model的部署。所谓Frozen Model就是在后续使用中参数不会再进行学习和修改,我们翻译为”冻结模型“。对于持有多个PC的用户而言,我们还提供了Tailscale相关操作,实现内网异地的分布式模型部署操作,即:再一个终端PC上部署模型,通过其他终端PC访问并使用模型。
注:下面章节在灰色框中的内容为操作步骤路,橙色标题的为可能出现的问题和解决办法。
1.下载Docker Desktop
Docker: Accelerated Container Application Development
点击以上链接进入docker官网,选择AMD64版本进行下载
2.安装Docker Desktop
在下载路径找到安装包:
点击后直接ok即可(不用改动勾选项),安装完成后重启电脑。

3.安装WSL(必须)
正常来讲,安装docker desktop会触发WSL自动安装的命令行窗口,但是由于很多种原因,会导致自动安装失败,因此我们选择手动安装:
https://github.com/microsoft/WSL/releases
点击上述链接进入WSL的版本发布网页,并找到x86版本进行下载。
找到下载好的msi文件,点击自动进行安装:
安装好后重启docker。
4.下载Docker Desktop汉化包(非必须)
https://github.com/asxez/DockerDesktop-CN/releases
点击上述链接,进入汉化包版本发布界面,选择Windows版本:
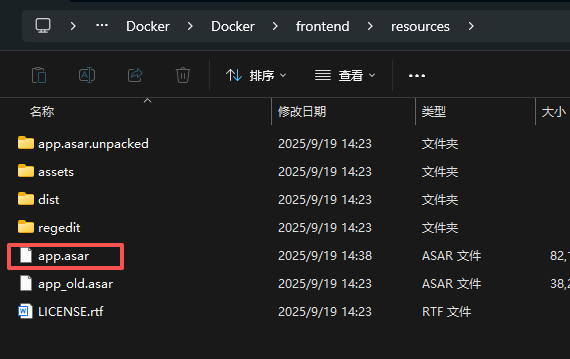
下载好后,将文件名重命名为app.asar
进入Docker Desktop安装路径,默认为:
C:\Program Files\Docker\Docker\frontend\resources将改好的文件替换掉app.asar,此图中是保留原先的app.asar为app_old.asar
5.安装Ubuntu
打开以管理员身份打开CMD输入:
wsl --install -d Ubuntu-22.04注:这个版本不一定非要用22.04,可以通过搜索或者提问AI Agent获取合适的版本。
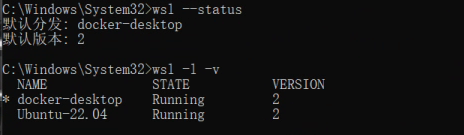
此时会显示一个安装进度条,此进度条可能在百分之70多卡住,这时新开一个命令行窗口,输入:
wsl --status wsl -l -v
这时其实ubuntu已经安装完毕了。
这里有些读者可能不会卡进度条,而是显示这个:
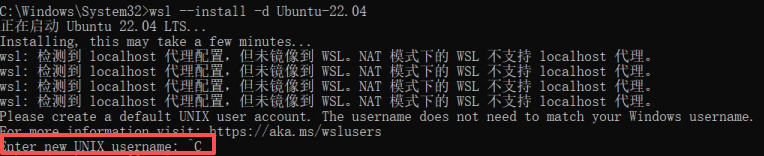
这种我们可以先退出,当我们再次进入时系统会自动用root操作,我们现在root上测试连通性,再使用单独的user环境进行大模型部署。
这时在docker中找到setting,找到resource,找到wsl,打开对ubuntu的WSL集成。一般会显示“应用并重启docker”
6.测试连通性
安装完ubuntu后,我们点击菜单会看到一个Ubuntu终端,点击进入,并输入:
注:以下所有指令全在Ubuntu终端进行!!!
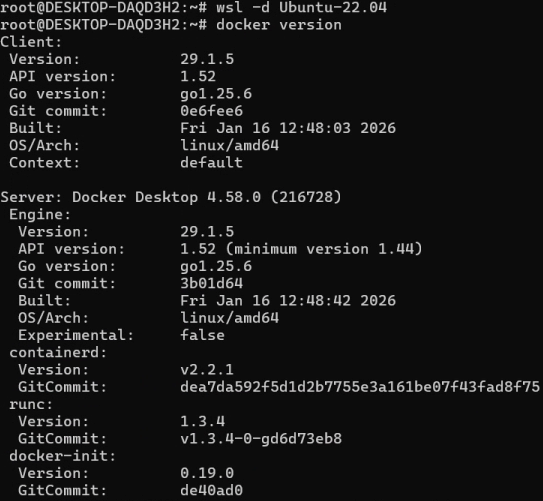
wsl --shutdown wsl -d Ubuntu-22.04 docker version这一步是为了刷新,测试docker是否在Ubuntu中可用。
输出系统和docker相关信息就成功了。
然后我们测试docker基本指令运行功能,输入:
docker run --rm hello-world

有些读者可能会遇到这种情况:

这是拉取镜像错误的问题,我们输入以下指令:
cat /root/.docker/config.json
如果是这种报错,我们直接输入:
mkdir -p /root/.docker
cp /root/.docker/config.json /root/.docker/config.json.bak 2>/dev/null || true
rm -f /root/.docker/config.json直接把这个文件备份并删除(对拉 public 镜像完全没影响),然后重试:
docker run --rm hello-world连通性的最后一步,是测试gpu是否可以正常使用,输入:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi出现这种显卡信息,就说明跑通了:
7.切换普通用户
创建一个普通用户(这里我的用户名是“lmclient”),输入:
adduser lmclient会要求设置密码,密码输入时是完全不可见的,空密码是不允许的。为了方便笔者用的123。
当弹出带“[]"的这些可以一路点回车,直到完成。
将用户加入sudo组:
usermod -aG sudo lmclient将用户加入docker组:
groupadd -f docker usermod -aG docker lmclient
这几步没什么输出。
转入用户控制台:
su - lmclient
验证是否有sudo权限,不报错会要求输入密码:
sudo -v
验证docker是否能正常使用:
docker version
如果报错(permission denied 或 Cannot connect):
sudo groupadd -f docker
sudo usermod -aG docker lmclient
newgrp docker
再做一遍普通用户的显卡连通性测试:
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
8. 显存-模型适配对照表
在正式拉取大模型之前,我们先看一组显存大小对应大模型对照表:
请根据实际硬件和配置情况选择需要拉取的模型。
显存档位 LLM 常驻建议(优先顺序) VLM 常驻建议(优先顺序) 典型可用上下文 并发/吞吐建议 适合“拉取策略” 8GB 3B~7B 4bit(或 7B 极限) 1B~3B(尽量 4bit) 2k~4k 1 路为主 只拉小模型;先跑通闭环 12GB 7B FP16/8bit 或 7B 4bit(更稳) 3B(可FP16/8bit),7B 需 4bit 4k~8k 1~2 路 LLM 与 VLM 以“小+稳”为主 16GB 7B FP16/8bit(最稳)/ 14B 4bit(AWQ)(可用) 3B FP16/8bit(推荐)/ 7B 4bit(可试) 8k 较稳;14B 4bit 建议 4k~8k 1~4 路(取决于上下文) 先拉 7B LLM + 3B VLM;跑通后再加 14B 或 7B-VL 24GB 14B FP16/8bit 稳,32B 4bit 有机会 7B FP16/8bit 稳,14B 4bit 有机会 8k~16k 2~8 路 可开始追求“更强模型 + 更长上下文” 48GB+ 32B FP16/8bit 或 70B 4bit 14B~34B(视模型) 16k~64k(看引擎) 多路并发 可以按业务追求质量和吞吐
9.拉取LLM(语言大模型)
注:以下操作使用WSL控制台!!!
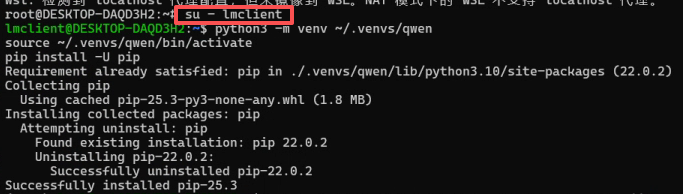
输入以下代码:切到lmclient(user),创建虚拟环境,防止安装混乱。
su - lmclient python3 -m venv ~/.venvs/qwen source ~/.venvs/qwen/bin/activate pip install -U pip
这个时候,我们的命令行多了一个(qwen),说明进入了虚拟环境。
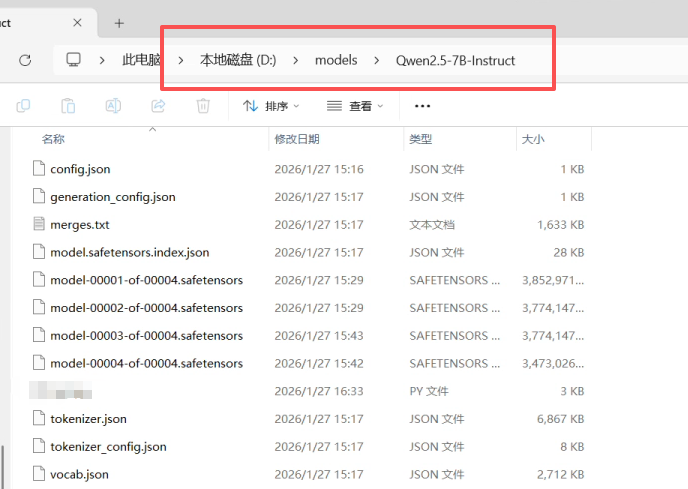
接下来我们手动在D盘建立一个文件夹(models),用于存储Qwen-7B-Instruct,Instruct说明是训练过的Frozen Model,而不是未训练模型。文件夹如此建立:
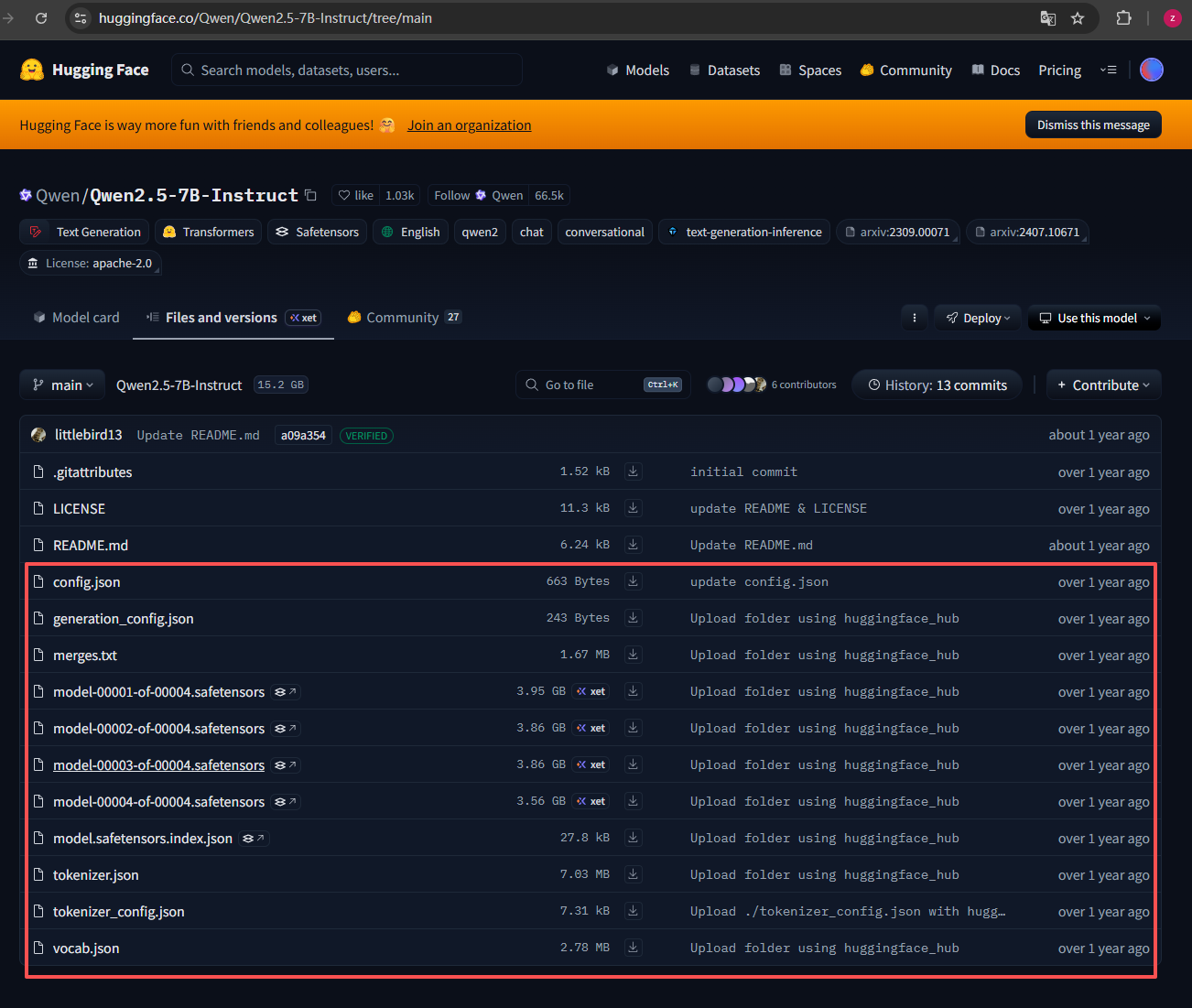
"D:\models\Qwen2.5-7B-Instruct"为了防止网络和路由等问题,我们选择手动拉取LLM,纯指令笔者试过,很难而且问题很多。我们进入hugging face Qwen-7B 网址:https://huggingface.co/Qwen/Qwen2.5-7B-Instruct/tree/main
这里也给出3B对应的网址https://huggingface.co/Qwen/Qwen2.5-3B-Instruct/tree/main
红框圈出来的是必须下载的,其余不需要,不下载没影响,下载好后放入我们刚才建好的文件夹。
下载好后安装torch,推理依赖和bit量化包(加快推理):
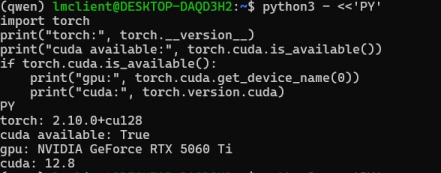
pip install -U torch pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu128 pip install -U "transformers==4.46.3" accelerate safetensors sentencepiece pip install -U bitsandbytes全部安装好进行环境自检:
python - <<'PY' import torch print("torch:", torch.__version__) print("cuda available:", torch.cuda.is_available()) if torch.cuda.is_available(): print("gpu:", torch.cuda.get_device_name(0)) print("cuda:", torch.version.cuda) PY
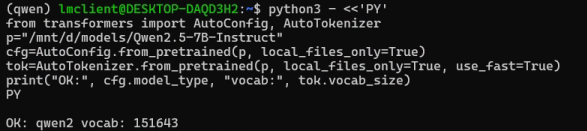
拉取本地Qwen2.5-7B-Instruct看是否成功:
python3 - <<'PY' from transformers import AutoConfig, AutoTokenizer p="/mnt/d/models/Qwen2.5-7B-Instruct" cfg=AutoConfig.from_pretrained(p, local_files_only=True) tok=AutoTokenizer.from_pretrained(p, local_files_only=True, use_fast=True) print("OK:", cfg.model_type, "vocab:", tok.vocab_size) PY
这里我们的拉取模型就完成了。

10. 本地测试LLM
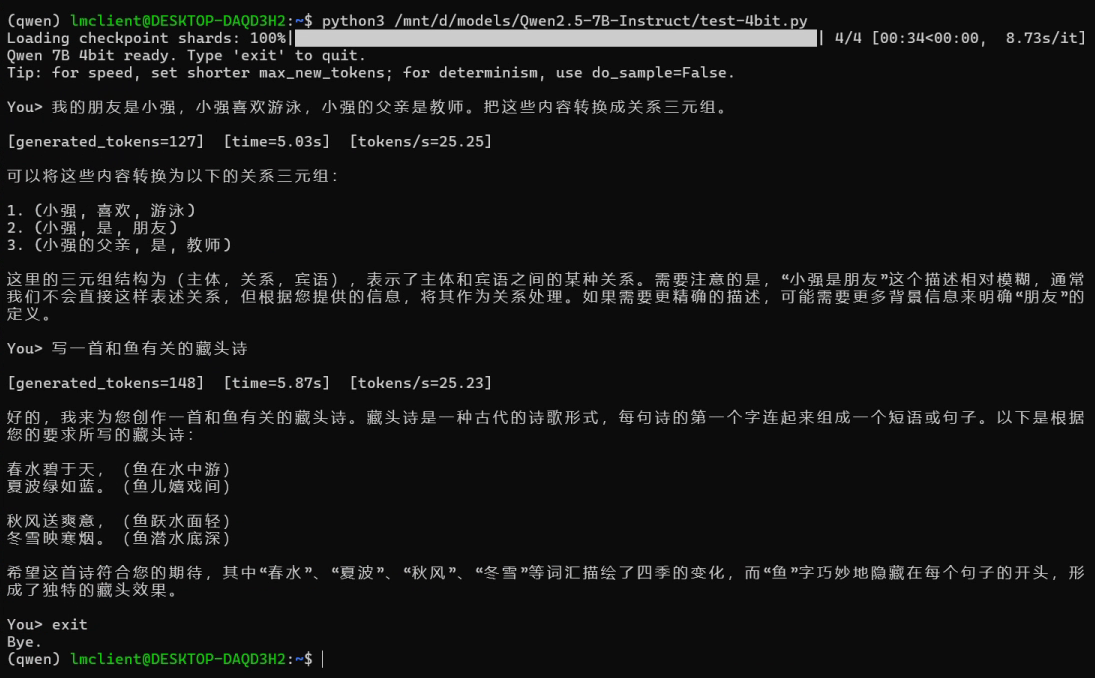
我们给出4bit量化代码来测试,本地非联网模型一般来说对发散问题处理较差,而纯文字处理较好。这种代码主观性比较强,因为调用的方式很多,因此也可以自己写。
#!/usr/bin/env python3 import os import sys import time import re import torch from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig MODEL_DIR = "/mnt/d/models/Qwen2.5-7B-Instruct" # --- 让终端 IO 更稳(对 WSL/中文/删除残留更友好)--- try: sys.stdin.reconfigure(encoding="utf-8", errors="ignore") sys.stdout.reconfigure(encoding="utf-8", errors="ignore") except Exception: pass def clean_cli_text(s: str) -> str: """ 清理 WSL/终端输入法可能产生的异常字符: - surrogate (U+D800..U+DFFF) - NUL - 一些不可见控制符(保留 \n \t) """ if not isinstance(s, str): s = str(s) # 去 surrogate(最关键) if any(0xD800 <= ord(ch) <= 0xDFFF for ch in s): s = s.encode("utf-8", "ignore").decode("utf-8", "ignore") # 去 NUL s = s.replace("\x00", "") # 去其它控制符(保留 \n \t) s = re.sub(r"[\x01-\x08\x0b\x0c\x0e-\x1f\x7f]", "", s) return s.strip() # --- tokenizer / model --- tok = AutoTokenizer.from_pretrained(MODEL_DIR, local_files_only=True, use_fast=True) bnb = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True, bnb_4bit_compute_dtype=torch.float16, ) model = AutoModelForCausalLM.from_pretrained( MODEL_DIR, local_files_only=True, quantization_config=bnb, device_map="cuda:0", ) bad_words = ["Human:", "Assistant:", "USER:", "SYSTEM:"] bad_words_ids = [tok.encode(w, add_special_tokens=False) for w in bad_words] @torch.inference_mode() def generate( user_prompt: str, max_new_tokens: int = 256, do_sample: bool = False, # 你要确定性输出就 False temperature: float = 0.7, # 仅 do_sample=True 时有效 top_p: float = 0.9, # 仅 do_sample=True 时有效 debug: bool = False, ): user_prompt = clean_cli_text(user_prompt) if not user_prompt: return "", 0, 0.0, 0.0 messages = [{"role": "user", "content": user_prompt}] if hasattr(tok, "apply_chat_template"): text = tok.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) else: text = user_prompt text = clean_cli_text(text) if debug: print("has_surrogate(text) =", any(0xD800 <= ord(ch) <= 0xDFFF for ch in text)) print("DEBUG text repr =", repr(text)[:200]) inputs = tok(text, return_tensors="pt", truncation=True).to("cuda") gen_kwargs = dict( max_new_tokens=max_new_tokens, do_sample=do_sample, eos_token_id=tok.eos_token_id, pad_token_id=tok.eos_token_id, bad_words_ids=bad_words_ids, ) # 只有采样模式才传 temperature/top_p,避免 transformers 警告 if do_sample: gen_kwargs.update(dict(temperature=temperature, top_p=top_p)) torch.cuda.synchronize() t0 = time.time() out = model.generate(**inputs, **gen_kwargs) torch.cuda.synchronize() t1 = time.time() gen_tokens = out.shape[1] - inputs["input_ids"].shape[1] sec = t1 - t0 tps = gen_tokens / max(sec, 1e-6) new_ids = out[0, inputs["input_ids"].shape[1]:] text_out = tok.decode(new_ids, skip_special_tokens=True).strip() return text_out, gen_tokens, sec, tps def main(): print("Qwen 7B 4bit ready. Type 'exit' to quit.") print("Tip: deterministic => do_sample=False; creative => do_sample=True.\n") while True: try: q = input("You> ") except (EOFError, KeyboardInterrupt): print("\nBye.") break q = clean_cli_text(q) if not q: continue if q.lower() in {"exit", "quit"}: print("Bye.") break ans, gen_tokens, sec, tps = generate( q, max_new_tokens=256, do_sample=False, # 你目前更适合先关采样,输出更稳 debug=False, ) print(f"\n[generated_tokens={gen_tokens}] [time={sec:.2f}s] [tokens/s={tps:.2f}]\n") print(ans) print() if __name__ == "__main__": main()将上述文件命名为“test-4bit.py",放到和模型一个文件夹中即:
D:\models\Qwen2.5-7B-Instruct输入运行指令: 本质上是文件位置前面加/mnt
source ~/.venvs/qwen/bin/activate python3 /mnt/d/models/Qwen2.5-7B-Instruct/test-4bit.py
11. Docker联动
注:以下操作使用WSL控制台!!!
新建文件夹,作为服务器部署基地:
mkdir -p ~/qwen_docker && cd ~/qwen_docker pwd
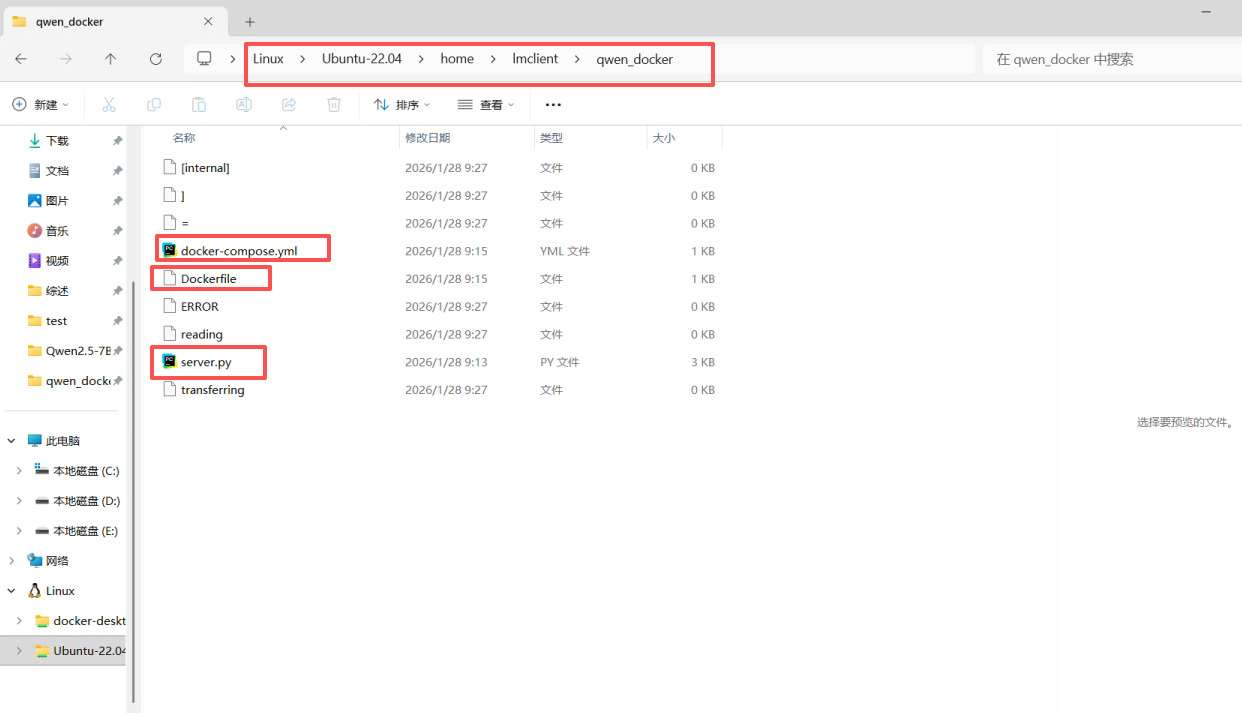
将以下三个文件放入上面输出的路径下:
server.py
# server.py import os import time import re from typing import Optional, List, Dict, Any import torch from fastapi import FastAPI from pydantic import BaseModel, Field from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig MODEL_DIR = os.environ.get("MODEL_DIR", "/models/qwen") DEVICE = os.environ.get("DEVICE", "cuda:0") app = FastAPI(title="Qwen2.5-7B-Instruct Server") tok = None model = None bad_words_ids = None def clean_text(s: str) -> str: """ 清理终端/输入法/WSL 可能产生的异常字符: - surrogate (U+D800..U+DFFF) - NUL - 其它不可见控制符(保留 \n \t) """ if s is None: return "" if not isinstance(s, str): s = str(s) # 去 surrogate(关键) if any(0xD800 <= ord(ch) <= 0xDFFF for ch in s): s = s.encode("utf-8", "ignore").decode("utf-8", "ignore") # 去 NUL s = s.replace("\x00", "") # 去其它控制符(保留 \n \t) s = re.sub(r"[\x01-\x08\x0b\x0c\x0e-\x1f\x7f]", "", s) return s.strip() def apply_stops(text: str, stops: Optional[List[str]]) -> str: """按最先出现的 stop 字符串截断(解码后截断,简单但很实用)""" if not stops: return text cut = None for s in stops: if not s: continue i = text.find(s) if i != -1: cut = i if cut is None else min(cut, i) return text if cut is None else text[:cut].rstrip() class Message(BaseModel): role: str # "system"|"user"|"assistant" content: str class GenReq(BaseModel): # 二选一: prompt: Optional[str] = None # 单轮输入 messages: Optional[List[Message]] = None # 多轮输入(推荐) # generation max_new_tokens: int = 256 do_sample: bool = False temperature: float = 0.7 top_p: float = 0.9 # behavior chat: bool = True # True=走 chat_template;False=纯文本 system: Optional[str] = None # 追加/覆盖 system prompt(可选) stop: Optional[List[str]] = Field(default=None, description="Stop strings to truncate output") debug: bool = False @app.on_event("startup") def load_model(): global tok, model, bad_words_ids t0 = time.time() tok = AutoTokenizer.from_pretrained(MODEL_DIR, local_files_only=True, use_fast=True) bnb = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=True, bnb_4bit_compute_dtype=torch.float16, ) model = AutoModelForCausalLM.from_pretrained( MODEL_DIR, local_files_only=True, quantization_config=bnb, device_map=DEVICE, ) model.eval() # 屏蔽常见“角色标记”污染(可选,但建议) bad_words = ["Human:", "Assistant:", "USER:", "SYSTEM:"] bad_words_ids = [tok.encode(w, add_special_tokens=False) for w in bad_words] torch.cuda.synchronize() print(f"[startup] loaded model from {MODEL_DIR} on {DEVICE} in {time.time()-t0:.2f}s") @app.get("/health") def health(): return {"ok": True, "cuda": torch.cuda.is_available(), "device": DEVICE, "model_dir": MODEL_DIR} @app.post("/generate") def generate(req: GenReq) -> Dict[str, Any]: assert tok is not None and model is not None # --------- build messages / prompt ---------- messages: List[Dict[str, str]] = [] if req.messages: for m in req.messages: messages.append({"role": m.role, "content": clean_text(m.content)}) else: p = clean_text(req.prompt or "") messages = [{"role": "user", "content": p}] if p else [] if req.system: # 如果前面已经有 system,就替换;否则插到最前 sys_msg = {"role": "system", "content": clean_text(req.system)} if messages and messages[0]["role"] == "system": messages[0] = sys_msg else: messages = [sys_msg] + messages if not messages: return {"text": "", "generated_tokens": 0, "time": 0.0, "tokens_per_s": 0.0} # --------- apply template ---------- if req.chat and hasattr(tok, "apply_chat_template"): text_in = tok.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) else: # 纯文本模式:拼一个简单格式 text_in = "\n".join([f'{m["role"]}: {m["content"]}' for m in messages]) text_in = clean_text(text_in) if req.debug: return { "debug": { "has_surrogate": any(0xD800 <= ord(ch) <= 0xDFFF for ch in text_in), "text_preview": repr(text_in)[:400], } } inputs = tok(text_in, return_tensors="pt", truncation=True).to(DEVICE) # --------- generation kwargs(完全按你本地逻辑) ---------- gen_kwargs = dict( max_new_tokens=req.max_new_tokens, do_sample=req.do_sample, eos_token_id=tok.eos_token_id, pad_token_id=tok.eos_token_id, bad_words_ids=bad_words_ids, ) if req.do_sample: gen_kwargs.update(dict(temperature=req.temperature, top_p=req.top_p)) torch.cuda.synchronize() t0 = time.time() with torch.inference_mode(): out = model.generate(**inputs, **gen_kwargs) torch.cuda.synchronize() t1 = time.time() gen_tokens = int(out.shape[1] - inputs["input_ids"].shape[1]) sec = float(t1 - t0) tps = float(gen_tokens / max(sec, 1e-6)) new_ids = out[0, inputs["input_ids"].shape[1]:] text_out = tok.decode(new_ids, skip_special_tokens=True).strip() text_out = apply_stops(text_out, req.stop) return {"text": text_out, "generated_tokens": gen_tokens, "time": sec, "tokens_per_s": tps}Dockerfile(无后缀)
# Dockerfile FROM nvidia/cuda:12.8.0-cudnn-runtime-ubuntu22.04 ENV DEBIAN_FRONTEND=noninteractive WORKDIR /app # system deps RUN apt-get update && apt-get install -y --no-install-recommends \ python3 python3-pip python3-venv git ca-certificates \ && rm -rf /var/lib/apt/lists/* # python deps RUN python3 -m pip install --no-cache-dir -U pip # 注意:这里让 pip 自己拉 torch(会很大,但最省事且和你当前环境一致) RUN python3 -m pip install --no-cache-dir \ torch==2.10.0 \ transformers==4.46.3 \ accelerate==1.12.0 \ safetensors==0.7.0 \ sentencepiece==0.2.1 \ bitsandbytes==0.49.1 \ fastapi==0.115.0 \ uvicorn[standard]==0.30.6 COPY server.py /app/server.py # 默认模型目录(运行时用 volume 覆盖) ENV MODEL_DIR=/models/qwen EXPOSE 8000 CMD ["python3", "-m", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8000"]docker-compose.yml
services: qwen7b: build: . container_name: qwen7b ports: - "8000:8000" environment: - MODEL_DIR=/models/qwen volumes: # 把你本地模型目录只读挂进去 - /mnt/d/models/Qwen2.5-7B-Instruct:/models/qwen:ro deploy: resources: reservations: devices: - capabilities: ["gpu"] restart: unless-stopped
先打开Docker,防止WSL检测不到。输入cuda拉取信息,耐心等待完成。
docker pull nvidia/cuda:12.8.0-cudnn-runtime-ubuntu22.04
检测拉取是否成功
docker images | grep nvidia/cuda docker image inspect nvidia/cuda:12.8.0-cudnn-runtime-ubuntu22.04 >/dev/null && echo OK
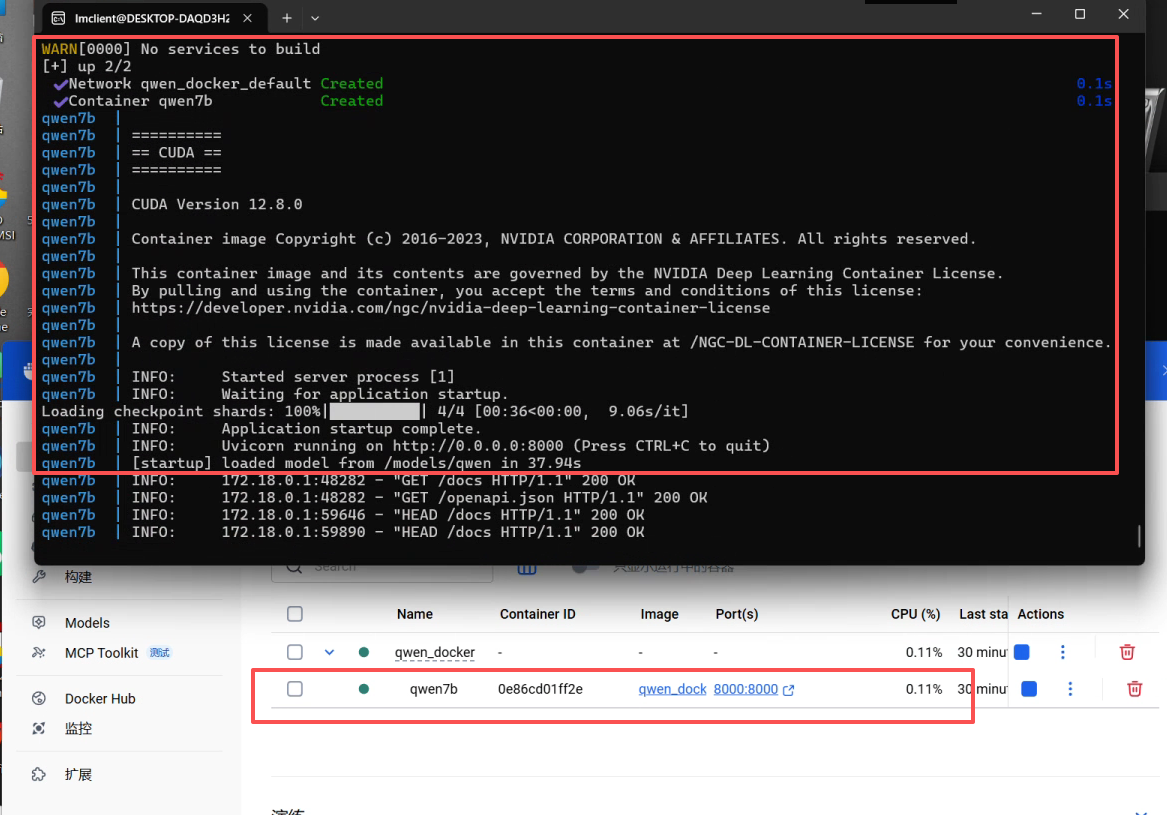
成功开始构建docker容器(时间有点长,请等待11步全部完成):
cd ~/qwen_docker export DOCKER_BUILDKIT=0 export COMPOSE_DOCKER_CLI_BUILD=0 docker compose build --no-cache docker compose up -d docker compose logs -f qwen7b
在这个过程中,docker会反复开关,容器名也是乱码,但是不用担心,所有11步全部完成后变回正常。
红框里面显示部署完毕,且已经正确分配端口8000。
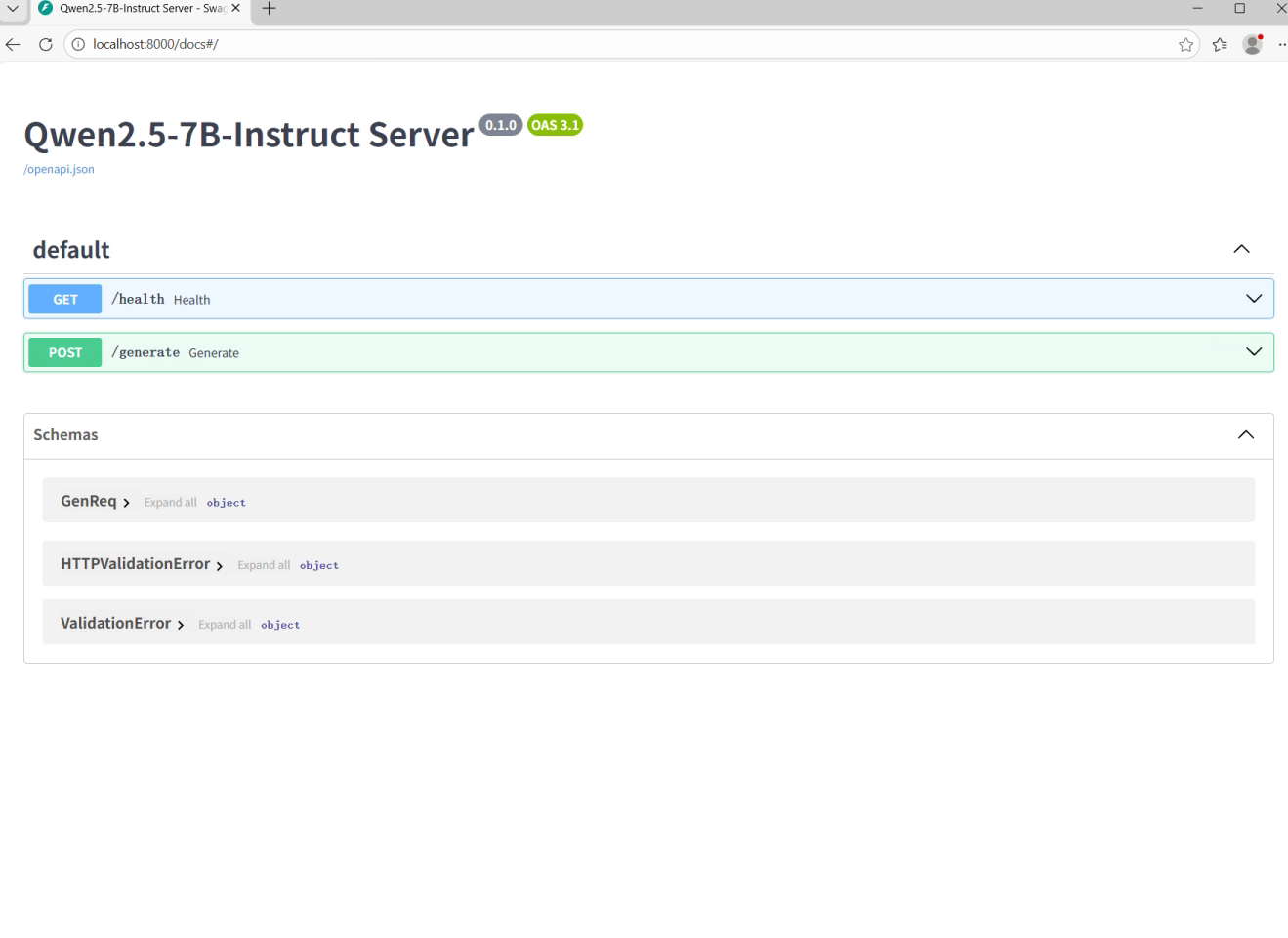
我们在运行服务器的主机上打开网址:
localhost:8000/docs#/
显示出FastAPI的经典界面说明已经成功了。



12. 内网穿透测试
部署到docker目的就是实现一个实时访问,多人异地访问的联合部署需求。因此我们采用Tailscale进行测试。
下载地址:https://tailscale.com/download
下载完后完成注册,tailscale的功能是在同一账号下的不同pc实现隧道传输,可以在内网打通路由不可达的问题,会分配虚拟地址,相当于在不同pc间使用虚拟专用网络。
在客户和服务端分别安装tailscale并使用同一个账号进行登录:
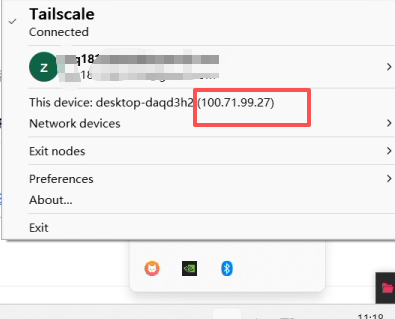
右键最小化的tailscale图标,我们能看到一个虚拟IP:
我们可以在客户端的命令行终端(CMD/Powershell)上ping服务段的ip,一定是可达的。
我们可以在客户端的命令行终端(CMD/Powershell)输入测试代码:
curl -X POST "http://100.71.99.27:8000/generate" ^ -H "Content-Type: application/json" ^ -d "{\"prompt\":\"你是KG三元组抽取器。只做抽取,严格按照(主语,谓语,宾语),不要举例。输入句子:我的朋友是小强,小强的父亲是老师,小强喜欢游泳。\\nJSON:\\n\",\"max_new_tokens\":96,\"do_sample\":false}"
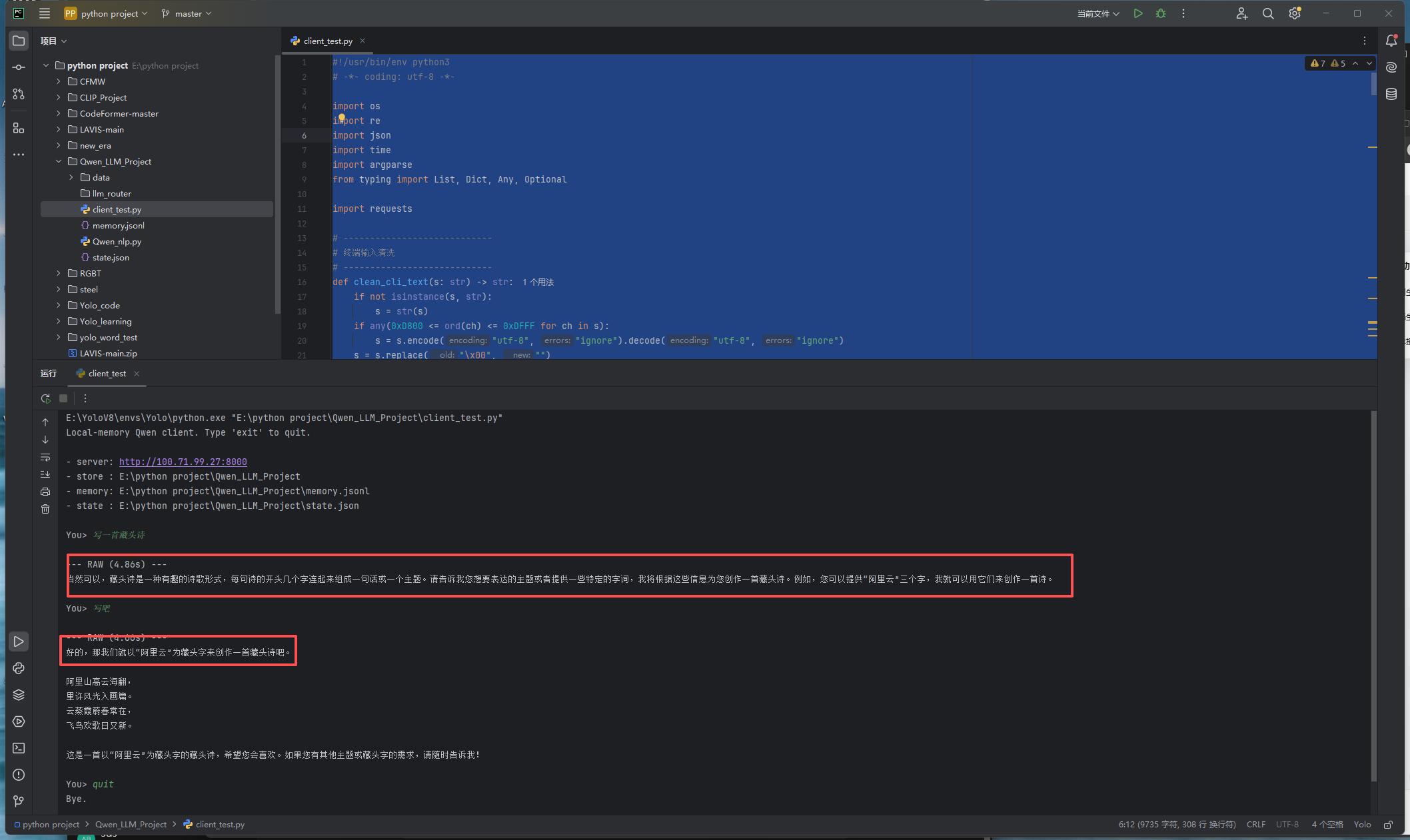
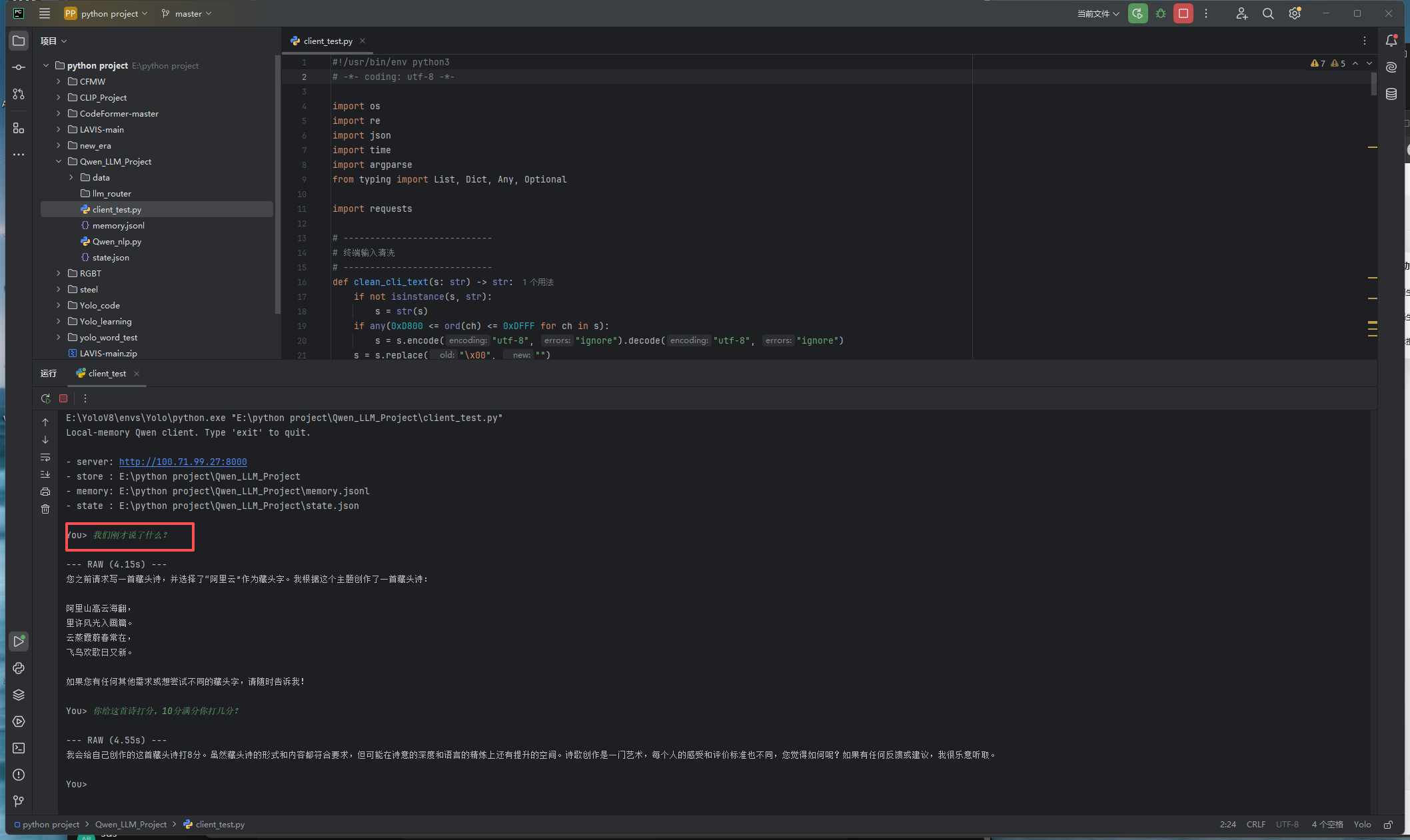
这里给出一个python脚本,可以让我们不再命令行一步一步敲指令,可以直接输入内容让其回答,并且我们在本地维护了两个json文件,用来保存我们和模型的对话记忆,在普通的日常使用中可以让模型记住聊过什么,即使是断连后重新连接也可以通过json得到记忆,在安装好必要依赖包后可直接运行:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import os import re import json import time import argparse from typing import List, Dict, Any, Optional import requests # ---------------------------- # 终端输入清洗 # ---------------------------- def clean_cli_text(s: str) -> str: if not isinstance(s, str): s = str(s) if any(0xD800 <= ord(ch) <= 0xDFFF for ch in s): s = s.encode("utf-8", "ignore").decode("utf-8", "ignore") s = s.replace("\x00", "") s = re.sub(r"[\x01-\x08\x0b\x0c\x0e-\x1f\x7f]", "", s) return s.strip() JSON_FENCE_RE = re.compile(r"```(?:json)?\s*(.*?)```", re.DOTALL | re.IGNORECASE) def extract_json_candidate(text: str) -> Optional[Any]: if not text: return None t = text.strip() m = JSON_FENCE_RE.search(t) if m: cand = m.group(1).strip() try: return json.loads(cand) except Exception: pass start = None for i, ch in enumerate(t): if ch in "{[": start = i break if start is None: return None end = None for i in range(len(t) - 1, -1, -1): if t[i] in "}]": end = i + 1 break if end is None or end <= start: return None cand = t[start:end].strip() try: return json.loads(cand) except Exception: return None def strip_code_fences(text: str) -> str: if not text: return text def repl(m): return m.group(1).strip() return JSON_FENCE_RE.sub(repl, text).strip() # ---------------------------- # 存储工具 # ---------------------------- def ensure_dir(p: str): os.makedirs(p, exist_ok=True) def load_state(path: str) -> Dict[str, Any]: if os.path.exists(path): with open(path, "r", encoding="utf-8") as f: return json.load(f) return {"summary": "", "turns": 0, "last_summarize_turn": 0} def save_state(path: str, state: Dict[str, Any]): with open(path, "w", encoding="utf-8") as f: json.dump(state, f, ensure_ascii=False, indent=2) def append_jsonl(path: str, obj: Dict[str, Any]): with open(path, "a", encoding="utf-8") as f: f.write(json.dumps(obj, ensure_ascii=False) + "\n") def tail_jsonl(path: str, n: int) -> List[Dict[str, Any]]: if n <= 0 or not os.path.exists(path): return [] out = [] with open(path, "r", encoding="utf-8") as f: for line in f: line = line.strip() if not line: continue try: out.append(json.loads(line)) except Exception: continue return out[-n:] def build_prompt(user_text: str, summary: str, recent_turns: List[Dict[str, Any]], system_hint: str = "") -> str: parts = [] if system_hint.strip(): parts.append(f"[System Hint]\n{system_hint.strip()}\n\n") if summary.strip(): parts.append(f"[Long-term Memory Summary]\n{summary.strip()}\n\n") if recent_turns: parts.append("[Recent Conversation]\n") for t in recent_turns: role = t.get("role", "") content = t.get("content", "") if role and content: parts.append(f"{role.upper()}: {content}\n") parts.append("\n") parts.append(f"[User]\n{user_text.strip()}\n[Assistant]\n") return "".join(parts) def call_server(base_url: str, prompt: str, max_new_tokens: int, do_sample: bool, temperature: float, top_p: float, timeout_s: int = 600) -> Dict[str, Any]: url = base_url.rstrip("/") + "/generate" payload = { "prompt": prompt, "max_new_tokens": max_new_tokens, "do_sample": do_sample, } if do_sample: payload["temperature"] = temperature payload["top_p"] = top_p r = requests.post(url, json=payload, timeout=timeout_s) r.raise_for_status() return r.json() def update_summary_if_needed(base_url: str, state: Dict[str, Any], mem_path: str, summarize_every: int, summarize_last_n: int, max_new_tokens_sum: int = 256) -> Dict[str, Any]: turns = state.get("turns", 0) last_sum_turn = state.get("last_summarize_turn", 0) if summarize_every <= 0: return state if turns - last_sum_turn < summarize_every: return state recent = tail_jsonl(mem_path, summarize_last_n * 2) if not recent: return state old_summary = state.get("summary", "") dialog_lines = [] for t in recent: role = t.get("role", "") content = t.get("content", "") if role and content: dialog_lines.append(f"{role.upper()}: {content}") dialog = "\n".join(dialog_lines) sum_prompt = ( "你是一个对话记忆压缩器。任务:将对话中对后续有用的信息压缩成“长期摘要”。\n" "要求:\n" "1) 输出纯文本摘要,不要标题,不要列表符号,尽量短但覆盖关键信息。\n" "2) 保留用户偏好、约束、已确定事实、正在进行的任务进度。\n" "3) 删除寒暄、重复、无关内容。\n\n" f"[Old Summary]\n{old_summary}\n\n" f"[Recent Dialog]\n{dialog}\n\n" "输出新的摘要:" ) resp = call_server( base_url=base_url, prompt=sum_prompt, max_new_tokens=max_new_tokens_sum, do_sample=False, temperature=0.7, top_p=0.9, ) new_sum = strip_code_fences(resp.get("text", "").strip()) state["summary"] = new_sum state["last_summarize_turn"] = turns return state # ---------------------------- # 主程序 # ---------------------------- def main(): script_dir = os.path.dirname(os.path.abspath(__file__)) # 默认:脚本所在目录 ap = argparse.ArgumentParser() ap.add_argument("--url", default="http://100.71.99.27:8000", help="Qwen server base url") # ✅ 存储目录可编辑,默认脚本目录 ap.add_argument("--store_dir", default=script_dir, help="where to store memory/state (default: script folder)") ap.add_argument("--mem_file", default="memory.jsonl", help="memory file name (jsonl)") ap.add_argument("--state_file", default="state.json", help="state file name (json)") ap.add_argument("--window", type=int, default=6, help="recent turns window") ap.add_argument("--max_new_tokens", type=int, default=2048) ap.add_argument("--do_sample", action="store_true", help="enable sampling") ap.add_argument("--temperature", type=float, default=0.7) ap.add_argument("--top_p", type=float, default=0.9) ap.add_argument("--clean", action="store_true", help="strip code fences in output") ap.add_argument("--pretty_json", action="store_true", help="if JSON detected, pretty print it") ap.add_argument("--system_hint", default="", help="optional behavior hint, kept on client") ap.add_argument("--summarize_every", type=int, default=8, help="summarize every N turns; 0 disables") ap.add_argument("--summarize_last_n", type=int, default=10, help="use last N turns to summarize") args = ap.parse_args() ensure_dir(args.store_dir) mem_path = os.path.join(args.store_dir, args.mem_file) state_path = os.path.join(args.store_dir, args.state_file) state = load_state(state_path) print("Local-memory Qwen client. Type 'exit' to quit.\n") print(f"- server: {args.url}") print(f"- store : {args.store_dir}") print(f"- memory: {mem_path}") print(f"- state : {state_path}\n") while True: try: q = input("You> ") except (EOFError, KeyboardInterrupt): print("\nBye.") break q = clean_cli_text(q) if not q: continue if q.lower() in {"exit", "quit"}: print("Bye.") break recent = tail_jsonl(mem_path, n=max(0, args.window * 2)) prompt = build_prompt( user_text=q, summary=state.get("summary", ""), recent_turns=recent, system_hint=args.system_hint, ) t0 = time.time() try: resp = call_server( base_url=args.url, prompt=prompt, max_new_tokens=args.max_new_tokens, do_sample=args.do_sample, temperature=args.temperature, top_p=args.top_p, ) except Exception as e: print(f"\n[ERROR] {e}\n") continue t1 = time.time() raw = resp.get("text", "") out = strip_code_fences(raw) if args.clean else raw append_jsonl(mem_path, {"ts": time.time(), "role": "user", "content": q}) append_jsonl(mem_path, {"ts": time.time(), "role": "assistant", "content": raw}) state["turns"] = int(state.get("turns", 0)) + 1 try: state = update_summary_if_needed( base_url=args.url, state=state, mem_path=mem_path, summarize_every=args.summarize_every, summarize_last_n=args.summarize_last_n, max_new_tokens_sum=256, ) except Exception: pass save_state(state_path, state) sec = t1 - t0 print(f"\n--- RAW ({sec:.2f}s) ---\n{raw}\n") if args.pretty_json: obj = extract_json_candidate(out) if obj is not None: try: pretty = json.dumps(obj, ensure_ascii=False, indent=2) print(f"--- PRETTY JSON ---\n{pretty}\n") except Exception: pass if args.clean and out != raw: print(f"--- CLEAN ---\n{out}\n") if __name__ == "__main__": main()
虽然这种记忆会加重模型负担,但是在轻量化,少访问的情况下,是合理的,性价比高的。

13. 声明
本文章更偏向实验记录/笔记,并不完全提供全过程问题解决方案。
本实验基于两台电脑,基本信息如下:
| 电脑型号 | 联想拯救者Y7000P 2024 | 自己组装台式 |
| 角色 | Client | Server |
| 系统版本 | Win11 | Win11+Ubuntu22.04.5 LTS |
| CPU | Intel i7-14700HX | AMD R5-9600x |
| GPU | RTX4070 Laptop 8G | RTX 5060Ti 16G |
| 内存 | 32G | 32G |
整个过程比较复杂冗长,在踩坑和整理笔记之间可能存在疏漏。如有问题,可以提问或者借助AI 进行解决。
另外,该教程仅限于初步的模型部署,有些问题比如:模型的上下文记忆,tokens相关问题并没有一致的方案。测试时的脚本也不唯一,性能也会有差距。
如果后续有机会,我们会进行上述问题的学习和解决,给出相应方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)