AI神经网络训练基本流程实战笔记(一个小项目让小白自学快速上手神经网络训练)
本文介绍了一个使用PyTorch实现的简单神经网络训练项目,旨在学习两个变量乘积函数Y=X1*X2的拟合关系。项目包含数据生成与标准化、神经网络模型定义、训练配置和训练循环四个核心模块。采用三层全连接网络结构,使用ReLU激活函数和Adam优化器,通过MSE损失函数进行1000轮训练。文章详细解释了神经网络前向传播过程、标准化处理和训练参数设置,并展示了典型的AI项目文件结构,为初学者提供了完整的
神经网络训练入门实战笔记—从一个Pytorch小项目开始
一、项目概述
这是一个完整的PyTorch神经网络训练项目,用简单神经网络拟合,学习两个变量的乘积函数 Y = X1 * X2(输入X1和X2,让神经网络能通过训练学习到Y与X1、X2的对应关系)。通过这个项目以掌握神经网络训练的基本流程。本文的项目结构简单,只用了一个.py文件来呈现简单神经网络的训练过程,旨在快速看懂一个神经网络的训练过程(pytorch架构下)
而下面这个文件树所呈现的结构是为了以后系统接触更多项目的预先了解。
二、一般AI项目文件树结构
simple_nn_project/ # 项目根目录
├── data/ # 数据相关(存放数据集)
│ ├── processed/ # 处理后的数据
│ └── raw/ # 原始数据
├── models/ # 模型相关
│ ├── checkpoints/ # 训练过程中保存的模型,每训练一轮次,若出现更好的模型这个文件就会被重写
│ └── best.pth/ # 训练好的最终模型(可能直接存模型,也可能存模型参数)
├── src/ # 源代码
│ ├── data_preprocessing.py #数据处理程序
│ ├── model.py #存储写好的模型框架,包括实现核心算法的模型类,训练的时候方便直接调用
│ ├── train.py # 训练主流程所在的位置,一般运行这个文件训练就会开始。
│ └── test.py#测试文件所在位置,一般运行这个文件测试就会开始,有时也会直接放在train.py里
├── notebooks/ # Jupyter笔记本
├── logs/ # 训练日志
├── tests/ # 单元测试
├── requirements.txt # 依赖包列表(使用一些命令可以一键配置环境,但有些包通常还得自己pip或者配置)
├── config.yaml # 配置文件
└── README.md # 项目说明(通过这个一般可以快速了解项目功能和使用办法)
三、进入神经网络训练项目
模块1:数据生成与预处理
数据生成
本文用简单神经网络拟合,学习两个变量的乘积函数 Y = X1 * X2(输入X1和X2,让神经网络能通过训练学习到Y与X1、X2的对应关系),因此,数据集由我自己生成:
# 1. 数据生成
X1 = 1 + 9 * torch.rand(1000) # 生成1000个[1,10)的随机数
X2 = 1 + 9 * torch.rand(1000) # 同样生成1000个
Y = X1 * X2 # 目标值:X1和X2的乘积

预处理:数据标准化(Z-score标准化)为了让1到10之间的数处在0到1之间
def z_score(x):
"""
将数据标准化为均值为0,标准差为1
公式: (x - mean) / std
为什么要标准化?
- 加速训练收敛
- 防止梯度爆炸/消失
- 使不同特征在同一量级
"""
return (x - x.mean()) / x.std(), x.mean(), x.std()
# 2. 标准化
X1 ,X1_mean,X1_std= z_score(X1)
X2 ,X2_mean,X2_std= z_score(X2)
Y ,Y_mean,Y_std = z_score(Y)
# 3. 数据合并
X = torch.stack([X1, X2], dim=1) # 将两个特征合并成一个矩阵,合并后由X1 = [x11,x12,···]和X2 = [x21,x22,···]合成X = [[x11,x21],[x12,x22],···]
Y = Y.unsqueeze(-1) # 将标签变为列向量 这样一个y就对应一组[x11,x21]
#这里你需要查查stack函数和unsqueeze函数的作用

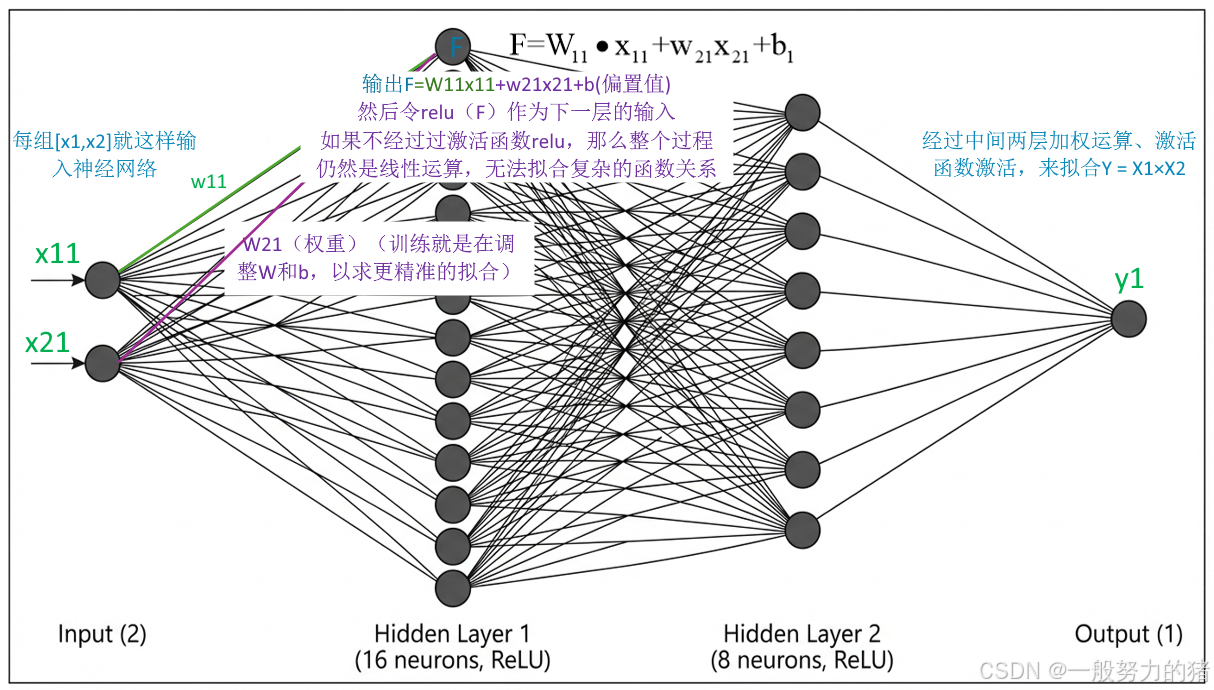
模块2:神经网络模型定义
class simpleNN(nn.Module):
"""
三层全连接神经网络
神经网络结构:
输入层(2维) → 隐藏层1(16维) → 隐藏层2(8维) → 输出层(1维)
"""
def __init__(self):
super(simpleNN, self).__init__()
# 定义网络层
self.fc = nn.Linear(2, 16) # 全连接层:输入2维,输出16维
self.fc2 = nn.Linear(16, 8) # 全连接层:输入16维,输出8维
self.fc3 = nn.Linear(8, 1) # 全连接层:输入8维,输出1维
def forward(self, x):
"""
前向传播过程
x: 输入数据,形状为 [batch_size, 2]
"""
x = torch.relu(self.fc(x)) # 第一层 + ReLU激活函数
x = torch.relu(self.fc2(x)) # 第二层 + ReLU激活函数
x = self.fc3(x) # 第三层(输出层)
return x
# ReLU激活函数的作用:
# - 引入非线性,使网络可以学习复杂模式
# - 缓解梯度消失问题
# - 计算简单,加速训练
整个网络的参数部分,表示成矩阵如下:

那么训练过程中前向传播过程如下:
取batch_size=4(取4组[x1,x2])为例):




这个前向传播的个过程在神经网络中的定义就是
模块3:训练配置
# 1. 损失函数 - 均方误差损失
criterion = nn.MSELoss()
"""
MSE公式: 1/n * Σ(y_pred - y_true)²
为什么用MSE?
- 对于回归问题效果好
- 梯度计算简单
- 惩罚大误差更重
"""
# 2. 优化器 - Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
"""
Adam优化器的优点:
- 自适应学习率
- 对稀疏梯度效果好
- 内存需求小
参数说明:
- lr=0.001: 学习率,控制参数更新步长
太大→震荡不收敛,太小→收敛慢
"""
# 3. 训练参数
batch_size = 100 # 每个批次的大小
num_epochs = 1000 # 训练轮数
dataset_size = len(X) # 数据集大小
num_batches = dataset_size // batch_size # 批次数量
设置损失函数,损失函数根据研究不同可以自己定义或使用pytorch提供的自带损失函数,这里我使用pytorch自带的mseloss。
设置优化器,就是在计算损失后,可以自己帮你调整W和b参数矩阵里所有元素的值。
设置batch_size在上文中已经提到过,刚才距离用的batch_size就等于4,这里在实际训练中我设计的是100,具体设计多少和你显存能一次算多少(算力)有关,这个可以查查相关的设置batchsize的知识。
训练轮数,就是这个输入数据—得到预测值—计算损失—调整参数的过程进行多少次。
总结:我设置了1000轮训练,每轮训练10批数据(num_batches),每批数据100组(batch_size),初始输入矩阵的维度就是(100,2)
模块4:训练循环(核心)
for epoch in range(num_epochs):
# 步骤1:打乱数据顺序(防止模型记住顺序)
indices = torch.randperm(dataset_size)
X_shuffle = X[indices]
Y_shuffle = Y[indices]
epoch_loss = 0 # 记录本轮总损失
# 步骤2:批次训练
for i in range(num_batches):
# 获取当前批次数据
start = i * batch_size
end = (i + 1) * batch_size
batch_x = X_shuffle[start:end] # 形状: [100, 2]
batch_y = Y_shuffle[start:end] # 形状: [100, 1]
# 步骤3:前向传播
optimizer.zero_grad() # 清空梯度(重要!)
y_pred = model(batch_x) # 模型预测
loss = criterion(y_pred, batch_y) # 计算损失
# 步骤4:反向传播
loss.backward() # 计算梯度
# 步骤5:参数更新
optimizer.step() # 更新模型参数
# 步骤6:记录损失
epoch_loss += loss.item()
# 步骤7:计算并打印平均损失
avg_loss = epoch_loss / num_batches
if (epoch + 1) % 10 == 0:
print(f'Epoch[{epoch+1}/1000], loss: {avg_loss:.4f}')
代码说明如下(关于梯度更新的过程可以看我的上一篇文章一次性搞懂张量梯度计算和反向传播原理以及参数如何更新(巨详细版)):
最终1000论训练结束以后,保存训练好的模型(其实理论上应该在训练时择优保存,选择损失更小的模型保存)
模块5:模型保存与加载
这里我只保存了模型参数,但是也可以直接保存模型结构,最终想测试的时候加载的方法不一样就是了。
# 1. 保存模型
torch.save(model.state_dict(), "simpleNN.pth")
"""
只保存模型参数,不保存模型结构
.pth是PyTorch的标准模型文件后缀
保存的是state_dict(参数字典)
"""
# 2. 加载模型
model = simpleNN() # 先创建模型实例
model.load_state_dict(torch.load("simpleNN.pth"))
model.eval() # 切换到评估模式
"""
这个切换到评估模式非常重要,可以具体搜一搜为什么
model.eval()的作用:
- 关闭Dropout层(如果有)
- 固定BatchNorm的统计量
- 确保推理结果一致
"""
模块6:模型测试与推理
这里我用了10组数据来测试看看到底神经网络有没有学到Y=X1*X2:
with torch.no_grad(): # 关闭梯度计算,节省内存
test_x = X[:10] # 取前10个样本测试
predictions = model(test_x) # 模型预测
# 反标准化:将标准化后的数据还原回原始范围
for i in range(10):
original_x1 = test_x[i, 0] * X1_std + X1_mean
original_x2 = test_x[i, 1] * X2_std + X2_mean
predicted_y = predictions[i, 0] * Y_std + Y_mean
actual_y = Y[i, 0] * Y_std + Y_mean
# 计算并显示误差
error = abs(predicted_y.item() - actual_y.item())
可以看到:
差不太多,嘿嘿,也算完成了一个小功能
四、完整训练流程总结
五、关键概念解释
1. 张量(Tensor)
PyTorch中的基础数据结构,类似于NumPy数组,但可以在GPU上运行。
# 创建张量
tensor_1d = torch.tensor([1, 2, 3]) # 一维
tensor_2d = torch.tensor([[1, 2], [3, 4]]) # 二维
2. 前向传播 vs 反向传播
- 前向传播:输入数据通过网络得到预测结果
- 反向传播:计算损失对每个参数的梯度,用于更新参数
3. 批次训练(Batch Training)
- Epoch:所有训练数据都过一遍网络
- Batch:一次前向-反向传播处理的数据量
- Iteration:完成一个batch的训练
4. 损失函数 vs 优化器
- 损失函数:衡量模型预测与真实值的差距
- 优化器:根据损失函数的梯度更新模型参数
六、碎碎念
复盘整个项目,其实这个项目真的很简单,但能让初学神经网络训练的小白大致理解训练的流程和过程。
除此之外,对于更真实复杂的项目而言,数据集有时大概率用pytorch里的dataloader来做,所以我将这个项目中自己生成的数据也用dataloder的办法写了一遍放在下面
从准备数据到训练到验证,这里面的办法从来都不是死结构,而是根据项目灵活调整,本文只是提供了一个大致框架,还需见识更多的项目才能把我其中的技巧。
七、附完整代码
本文版:
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
torch.manual_seed(1)
np.random.seed(1)
class simpleNN(nn.Module):
def __init__(self):
super(simpleNN, self).__init__()
self.fc = nn.Linear(2,16)
self.fc2 = nn.Linear(16,8)
self.fc3 = nn.Linear(8,1)
def forward(self, x):
x = torch.relu(self.fc(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = simpleNN()
print(model)
# X1 = torch.tensor([i for i in range(10)], dtype=torch.float32)
# X2 = torch.tensor([i+1 for i in range(10)], dtype=torch.float32)
# Y = torch.tensor([i*(i+1) for i in range(10)], dtype=torch.float32)
# X1 从 1 到 10,100 个点
# X1 从 1 到 10,100 个点
X1 = 1 + 9 * torch.rand(1000) # rand() 生成 [0,1),乘 9 再加 1 → [1,10)
X2 = 1 + 9 * torch.rand(1000) # 保持 X2 比 X1 大 1
Y = X1 * X2
def z_score(x):
return (x - x.mean()) / x.std() , x.mean(), x.std()
X1 ,X1_mean,X1_std= z_score(X1)
X2 ,X2_mean,X2_std= z_score(X2)
Y ,Y_mean,Y_std = z_score(Y)
X = torch.stack([X1,X2],dim=1)
Y = Y.unsqueeze(-1)
batchsize = 100
num_epochs = 1000
dataset_size = len(X)
num_batches = dataset_size // batchsize
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
indices = torch.randperm(dataset_size)
X_shuffle = X[indices]
Y_shuffle = Y[indices]
epoch_loss = 0
for i in range(num_batches):
start = i*batchsize
end = (i+1)*batchsize
batch_x = X_shuffle[start:end]
batch_y = Y_shuffle[start:end]
optimizer.zero_grad()#清空梯度
y_pred = model(batch_x)#计算模型输出
loss = criterion(y_pred, batch_y)#计算损失
loss.backward() #反向传播,计算梯度
optimizer.step() #调整参数
epoch_loss += loss.item() #计算当前批次总损失
avg_loss = epoch_loss / num_batches #计算一个批次的平均损失
if (epoch+1) % 10 == 0:
print(f'Epoch[{epoch+1}/1000],loss:{loss.item():.4f}')
torch.save(model.state_dict(), "simpleNN.pth")
model = simpleNN()
model.load_state_dict(torch.load("simpleNN.pth"))
model.eval()
with torch.no_grad():
# 使用前10个样本进行测试
test_x = X[:10]
predictions = model(test_x)
print("\n前10个样本的预测结果:")
print("=" * 40)
for i in range(10):
# 将标准化后的数据反标准化回原始范围
original_x1 = test_x[i, 0] * X1_std + X1_mean
original_x2 = test_x[i, 1] * X2_std + X2_mean
predicted_y = predictions[i, 0] * Y_std + Y_mean
actual_y = Y[i, 0] * Y_std + Y_mean
print(f"样本 {i + 1}:")
print(f" 输入: X1={original_x1.item():.4f}, X2={original_x2.item():.4f}")
print(f" 实际 Y: {actual_y.item():.4f}")
print(f" 预测 Y: {predicted_y.item():.4f}")
print(f" 误差: {abs(predicted_y.item() - actual_y.item()):.4f}")
print("-" * 40)
dataloader版:
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader, TensorDataset
torch.manual_seed(1)
np.random.seed(1)
class simpleNN(nn.Module):
def __init__(self):
super(simpleNN, self).__init__()
self.fc = nn.Linear(2,16)
self.fc2 = nn.Linear(16,8)
self.fc3 = nn.Linear(8,1)
def forward(self, x):
x = torch.relu(self.fc(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = simpleNN()
print(model)
# X1 = torch.tensor([i for i in range(10)], dtype=torch.float32)
# X2 = torch.tensor([i+1 for i in range(10)], dtype=torch.float32)
# Y = torch.tensor([i*(i+1) for i in range(10)], dtype=torch.float32)
# X1 从 1 到 10,100 个点
# X1 从 1 到 10,100 个点
X1 = 1 + 9 * torch.rand(1000) # rand() 生成 [0,1),乘 9 再加 1 → [1,10)
X2 = 1 + 9 * torch.rand(1000) # 保持 X2 比 X1 大 1
Y = X1 * X2
def z_score(x):
return (x - x.mean()) / x.std() , x.mean(), x.std()
X1 ,X1_mean,X1_std= z_score(X1)
X2 ,X2_mean,X2_std= z_score(X2)
Y ,Y_mean,Y_std = z_score(Y)
X = torch.stack([X1,X2],dim=1)
Y = Y.unsqueeze(-1)
dataset = TensorDataset(X, Y)
batchsize = 100
dataloader = DataLoader(dataset, batch_size=batchsize,shuffle=True)
num_epochs = 1000
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
epoch_loss = 0.0
num_batches = 0
for batch_x,batch_y in dataloader:
optimizer.zero_grad()#清空梯度
y_pred = model(batch_x)#计算模型输出
loss = criterion(y_pred, batch_y)#计算损失
loss.backward() #反向传播,计算梯度
optimizer.step() #调整参数
epoch_loss += loss.item() #计算当前批次总损失
num_batches += 1
avg_loss = epoch_loss / num_batches #计算一个批次的平均损失
if (epoch+1) % 10 == 0:
print(f'Epoch[{epoch+1}/1000],loss:{loss.item():.4f}')
torch.save(model.state_dict(), "simpleNN.pth")
model = simpleNN()
model.load_state_dict(torch.load("simpleNN.pth"))
model.eval()
with torch.no_grad():
# 使用前10个样本进行测试
test_x = X[:10]
predictions = model(test_x)
print("\n前10个样本的预测结果:")
print("=" * 40)
for i in range(10):
# 将标准化后的数据反标准化回原始范围
original_x1 = test_x[i, 0] * X1_std + X1_mean
original_x2 = test_x[i, 1] * X2_std + X2_mean
predicted_y = predictions[i, 0] * Y_std + Y_mean
actual_y = Y[i, 0] * Y_std + Y_mean
print(f"样本 {i + 1}:")
print(f" 输入: X1={original_x1.item():.4f}, X2={original_x2.item():.4f}")
print(f" 实际 Y: {actual_y.item():.4f}")
print(f" 预测 Y: {predicted_y.item():.4f}")
print(f" 误差: {abs(predicted_y.item() - actual_y.item()):.4f}")
print("-" * 40)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)