云平台降本增效实战:通过优化可观测性打破“高价”魔咒
在现代企业中,云可观测性(Cloud Observability)对于维持应用程序功能、保障用户体验至关重要,对自己的服务越了解,就能更好地管理它。但是,完善的可观测性是需要付出代价的,随着日志、指标和追踪等遥测数据的爆炸式增长,可观测性的成本往往变得难以承受。本文将揭示导致成本激增的深层原因,并提供六大核心策略,帮助大家在不牺牲可见性的前提下实现降本增效。
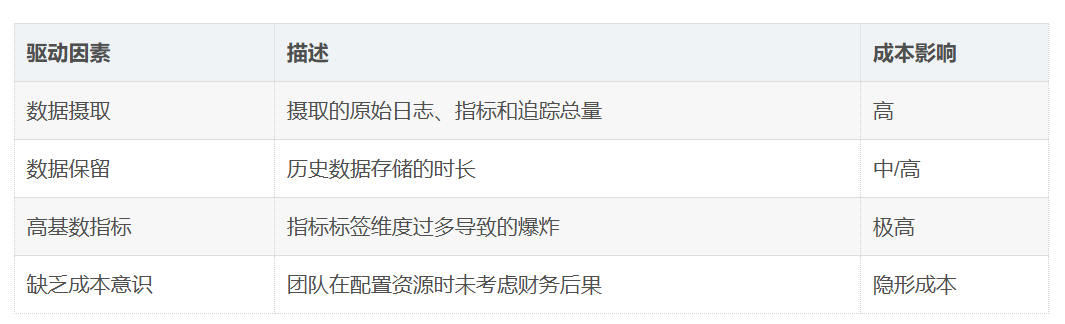
一、 为什么云账单会“爆表”?
在实施优化之前,必须识别成本的主要驱动因素:
- 数据摄取量巨大:来自应用、基础设施和第三方服务的日志和追踪数据越多,费用越高。
- 高基数指标:具有大量唯一标签或维度的指标会导致数据点和存储需求呈爆炸式增长。
- 过度收集:收集了大量从未用于监控、告警或分析的数据。
- 工具扩张:使用多个不互通的工具导致了重复的数据摄取和管理开销。
高基数指标是一个比较容易忽略的点,在Prometheus或类似的监控系统中,一个指标的总数据量是所有维度(通过Label来体现)取值组合的笛卡尔积。如果维度选取的值范围过大,存储指标的数据库就需要耗费非常大的存储空间。所以在选择持久化指标时,一定要慎重考虑。
二、 降本增效的六大技术策略
1. 从源头优化数据摄取
最有效的降本方式是确保只收集“真正重要”的数据。
- 精细化过滤:在源头剔除调试日志(Debug Logs)和非关键服务的无用数据。
- 战略性采样:对于高流量数据流,采用智能采样方法,仅捕获具有统计意义的子集,从而在检测异常的同时减少数据量。
- 调整采集间隔:将指标采集周期从 10 秒调整为 60 秒,可以大幅减少数据点数量。
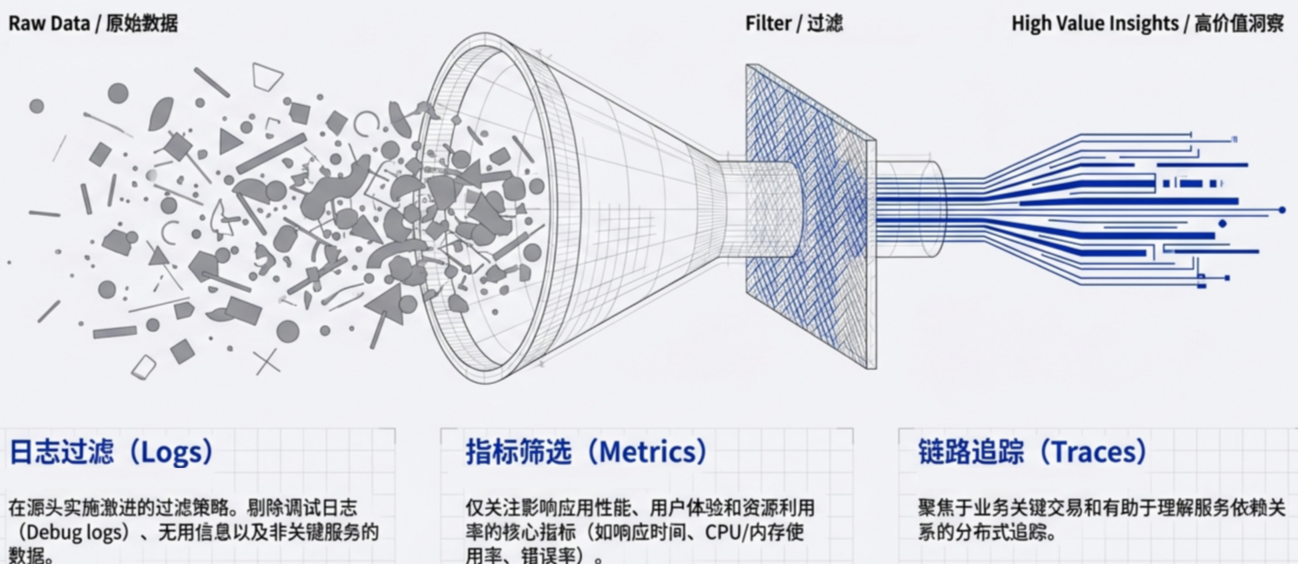
战略性采样一个典型的应用场景是全量采样异常数据,这些数据对于问题定位与修复至关重要。对于正常的、重复性的数据仅保留很小的比例。
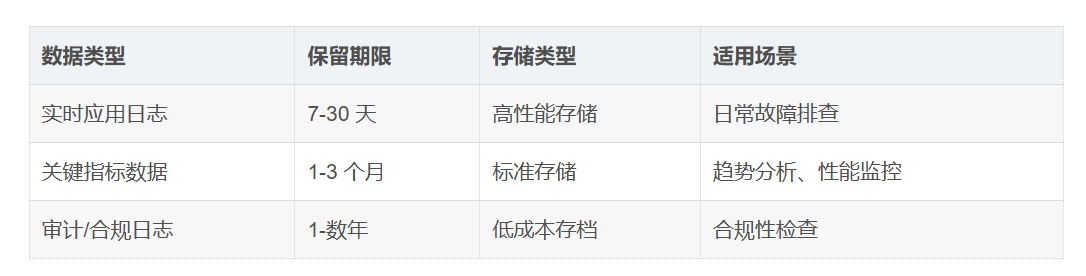
2. 实施智能数据保留策略
存储所有数据是极其昂贵的,应建立分层存储体系。
- 冷热分层:将细粒度数据在高性能存储中保留 7-30 天用于故障排除;将旧数据存档至低成本存储用于合规审计。
- 自动生命周期管理:利用自动化工具根据定义的策略进行归档或删除(如阿里云OSS的生命周期管理)。
3. 资源规模优化与调整
利用可观测性数据来识别云基础设施中的低效环节。
- 清理闲置资源:识别并停止未使用的实例、数据库或负载均衡器。
- 利用折扣方案:为可预测的负载选择预留实例或节省计划;为容错性强的负载使用竞价实例。
清理闲置资源是一个长期的工作,我们会经常登录云平台查看各类资源的利用情况,发现负载小的资源,能合并就尽量合并,比如负载均衡。发现没有使用的资源,要推进下架,工作中发现不少实验性项目平时没有什么请求量,这些资源要尽快落实下线。
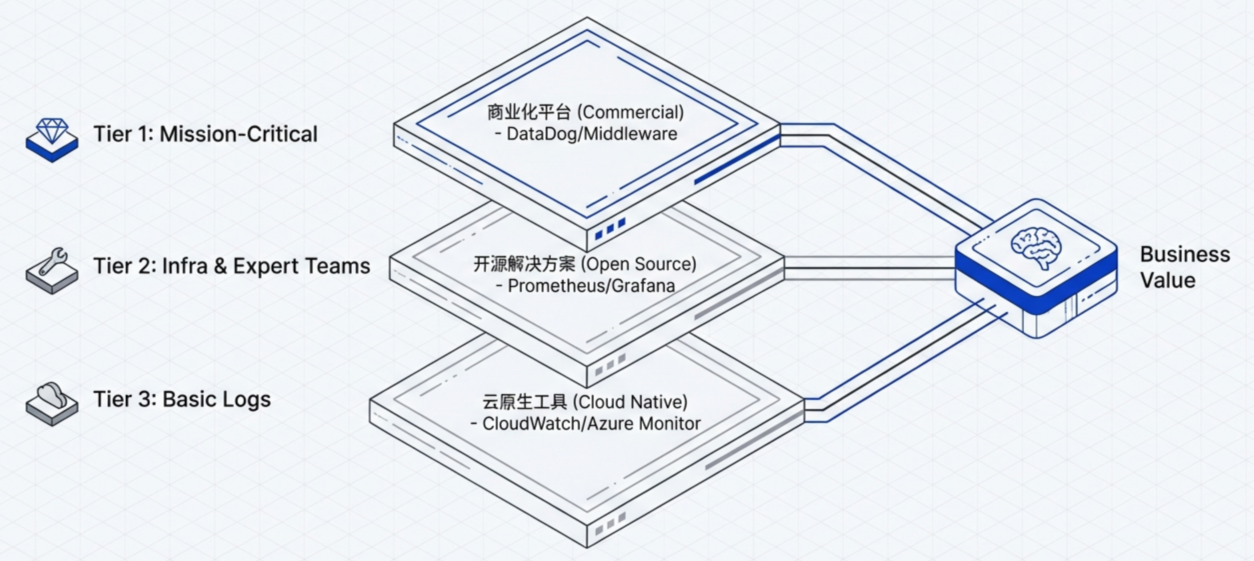
4. 去中心化与分布式观测
不要过度依赖单一且昂贵的商业平台。
- 开源与商业结合:对于核心应用使用成熟的商业平台(如国外知名的 Datadog,国内的听云、OneAPM),而对于非关键数据则使用自托管的开源工具(如 Prometheus、Grafana)。
- 利用云原生工具:使用阿里云、腾讯云等云服务商原生监控工具,它们通常是摄取基础遥测数据最经济的选择。
5. 培养 FinOps 成本文化
降本不仅是技术挑战,更是文化挑战。
- 设置预算告警:为可观测性支出设定明确预算,并在接近限额时发出警告。
- 成本分配(Tagging):通过打标签(Tagging)将成本分摊到具体的团队或项目,建立问责制。
公有云上的资源大都支持打标签,开通资源时,在标签中录入使用部门,月度核算时资源的费用就可以计算到使用部门的预算里面,这样申请云资源的部门就不会大手大脚,过度申请一些后面可能不怎么使用的资源。
6. 利用 AI 和机器学习
通过 AI 进一步实现自动化优化:
- 异常检测:自动识别数据摄取量或资源利用率的异常激增,防止配置错误导致的成本失控。
- 预测分析:根据历史趋势预测未来的可观测性需求和成本,实现主动优化。
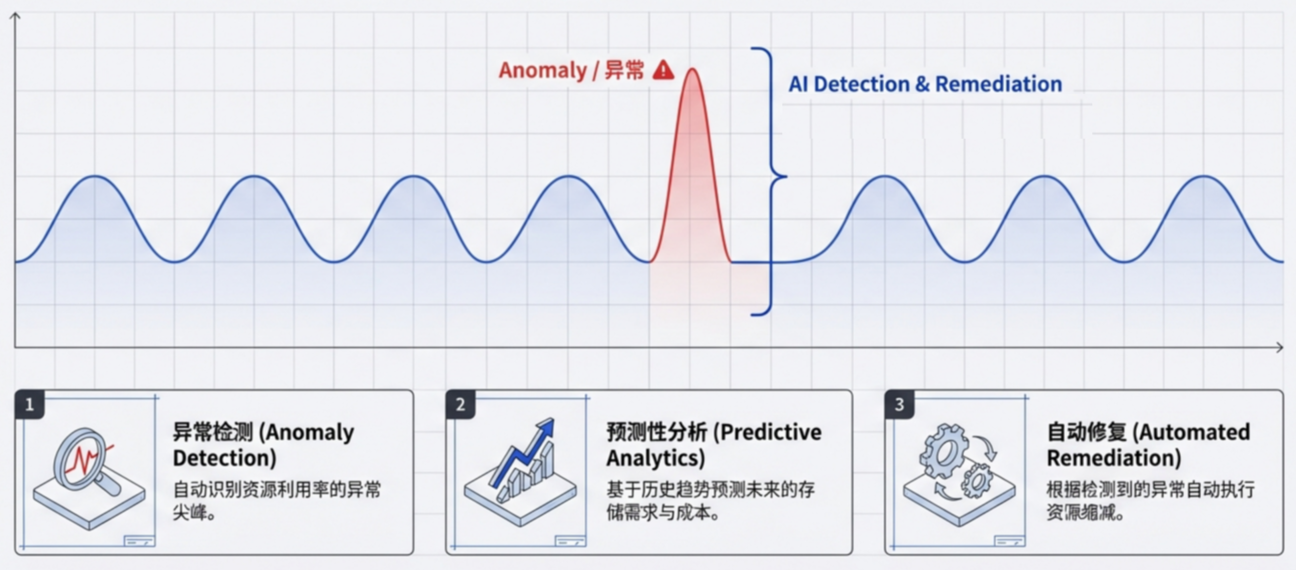
这是一个比较新的领域,平时工作中,我也在积极的探索,将那些超大数据量交给AI来分析,输出汇总数据,方便我们做决策。如果在你的工作中有这方面的实践,欢迎评论分享。
三、 结论:平衡与预算
企业不应无限制地投入资金,而应采取主动的、分析性的方法,在保持系统弹性的同时优化成本。通过从源头控制数据规模、智能管理保留期以及引入 AI 自动化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)