On-Policy Distillation:融合 RL 与蒸馏优势,让小模型实现 “低成本超神”
博客链接:https://thinkingmachines.ai/blog/on-policy-distillation/

博客链接:https://thinkingmachines.ai/blog/on-policy-distillation/
一、先搞懂3个关键背景概念
在理解“在策略蒸馏”前,需要先明确大模型训练的核心阶段和两种经典后训练方式:
1. 大模型训练的“三段式”
大模型训练分为三个核心阶段:
- 预训练(Pre-training):教模型基础能力,比如语言理解、通用推理、世界常识(相当于小学打基础);
- 中期训练(Mid-training):注入领域知识,比如代码、医疗数据库、公司内部文档(相当于中学学专业分科);
- 后训练(Post-training):优化特定行为,比如遵循指令、解数学题、聊天互动(相当于大学练专项技能)。
小模型如果后训练得当,在专属领域里能打败通用大模型——而且小模型能本地部署(保护隐私)、更新方便、推理成本低,这也是研究后训练技术的核心意义。
2. 两种经典后训练方式的“优缺点对决”
后训练主要分两种思路,博客用表格清晰对比了它们和“在策略蒸馏”的差异:
| 方法 | 样本来源 | 奖励信号 | 核心特点 |
|---|---|---|---|
| 有监督微调 | Off-policy(外部数据,比如教师模型的输出) | 密集(每个token都有反馈) | 学得多但“不贴合自身” |
| 强化学习 | On-policy(学生模型自己生成的样本) | 稀疏(只有最终结果反馈) | 贴合自身但“学得慢” |
| 在策略蒸馏 | On-policy(学生自己生成) | 密集(每个token都有反馈) | 兼顾“贴合自身”和“学得快” |
举个通俗例子:如果训练模型下象棋
- 强化学习(RL):相当于自己下棋,只有赢/输的最终反馈,不知道哪步走对、哪步错;
- 离线蒸馏(SFT):相当于看象棋大师的比赛录像,知道每步“标准答案”,但大师的棋局和你自己会遇到的局面差异很大;
- 在策略蒸馏:相当于你自己下棋时,大师在旁边每步都点评(“这步妙”“这步错”)——既贴合你自己的下棋场景,又有密集反馈。
二、在策略蒸馏:核心原理是什么?
1. 核心思想:“让学生自己练,老师逐句点评”
在策略蒸馏的逻辑很简单:
- 让学生模型(要优化的小模型)自己生成任务样本(比如解数学题的完整步骤);
- 让教师模型(性能更强的大模型)对学生的每个token(每个字/词/步骤)打分;
- 学生根据“逐token反馈”调整自己,避免再犯同类错误。
比如解数学题“5 + (2 × 3) = ?”:
- 学生可能生成错误步骤:“5+2=7,7×3=21”;
- 教师模型会逐token点评:“5+2”这里错了(没先算括号里的乘法),“7×3”跟着错,最终“21”是错结果;
- 学生不仅知道“答案错了”,还知道“哪步错了”,下次就能针对性修正。

2. 数学基础:用反向KL散度做“打分函数”
博客用反向KL散度(reverse KL) 量化学生和教师的差异,作为训练的损失函数(Loss function):
KL(πθ∣∣πteacher)=Ex∼πθ[logπθ(xt+1∣x1..t)−logπteacher(xt+1∣x1..t)]\text{KL}\Bigl(\pi_\theta \lvert\rvert \pi_\text{teacher}\Bigr) = \mathbb{E}_{x \sim {\pi_\theta}} \Bigl[ \log \pi_\theta(x_{t+1} | x_{1..t}) - \log \pi_\text{teacher}(x_{t+1} | x_{1..t}) \Bigr]KL(πθ∣∣πteacher)=Ex∼πθ[logπθ(xt+1∣x1..t)−logπteacher(xt+1∣x1..t)]
- πθ\pi_\thetaπθ:学生模型在给定前序token x1..tx_{1..t}x1..t 后,生成下一个token xt+1x_{t+1}xt+1 的概率分布;
- πteacher\pi_\text{teacher}πteacher:教师模型的对应概率分布;
- 核心含义:反向KL越小,说明学生的每一步输出越接近教师——训练目标就是最小化这个值。
反向KL有两个关键优势:
- 「寻找众数(mode seeking)」:只学教师的最优行为,不分散精力在次优选项上;
- 「减少暴露偏差(exposure bias)」:避免学生在训练时学的是教师的场景,实际用的时候却遇到自己不会的场景(离线蒸馏的核心问题)。
3. 实现步骤:4步搞定,甚至能复用RL代码
博客提供了简洁的伪代码,核心步骤只有4步:
- 初始化教师模型客户端:调用大模型(比如Qwen3-32B)作为“评委”;
- 学生生成样本:让小模型(比如Qwen3-8B)自己生成任务轨迹(比如解题步骤),并记录自己的输出概率(logπθ\log \pi_\thetalogπθ);
- 教师打分:让教师模型计算学生每个token的输出概率(logπteacher\log \pi_\text{teacher}logπteacher),用反向KL算出每个token的“奖励”(负KL值,KL越小奖励越高);
- RL更新:用强化学习的“重要性采样损失”更新学生模型,让学生下次更倾向于生成教师认可的token。
伪代码简化版:
# 1.Initialize teacher client (main):
teacher_client = service_client.create_sampling_client(
base_model=teacher_config.base_model,
model_path=teacher_config.load_checkpoint_path,
)
# 2.Sample trajectories (main):
trajectories = do_group_rollout(student_client, env_group_builder)
sampled_logprobs = trajectories.loss_fn_inputs["logprobs"]
# 3.Compute reward (compute_teacher_reverse_kl):
teacher_logprobs = teacher_client.compute_logprobs(trajectories)
reverse_kl = sampled_logprobs - teacher_logprobs
trajectories["advantages"] = -reverse_kl
# 4.Train with RL (train_step):
training_client.forward_backward(trajectories, loss_fn="importance_sampling")
三、实验效果:在策略蒸馏有多厉害?
博客用两个核心场景验证效果:数学推理训练和个性化助手训练,数据证明它在“效果”和“效率”上都碾压传统方法。
1. 场景1:数学推理训练——用1/10成本达到更高分数
目标:让小模型(Qwen3-8B-Base)在数学基准测试AIME’24上以30倍加速达到70%的效果:
| 方法 | AIME’24分数 | Teacher FLOPs | Student FLOPs | CE vs SFT-2M |
|---|---|---|---|---|
| Initialization: SFT-400K | 60% | 8.5×10208.5 \times 10^{20}8.5×1020 | 3.8×10203.8 \times 10^{20}3.8×1020 | – |
| SFT-2M (extrapolated) | ~70% (extrapolated) | 3.4×10213.4 \times 10^{21}3.4×1021 | 1.5×10211.5 \times 10^{21}1.5×1021 | 1× |
| RL | 68% | - | - | ≈1× |
| On-policy distillation | 70% | 8.4×10198.4 \times 10^{19}8.4×1019 | 8.2×10198.2 \times 10^{19}8.2×1019 | 9-30× |
从计算量(FLOPs)来看,在策略蒸馏的成本更是只有离线蒸馏的 1/9~1/30:
- 离线蒸馏(SFT-2M):学生 + 教师总 FLOPs 约 4.9×10²¹;
- 在策略蒸馏:学生 + 教师总 FLOPs 约 1.66×10²⁰,是前者的 1/30。
博客还给出了训练曲线,能直观看到在策略蒸馏的“快”: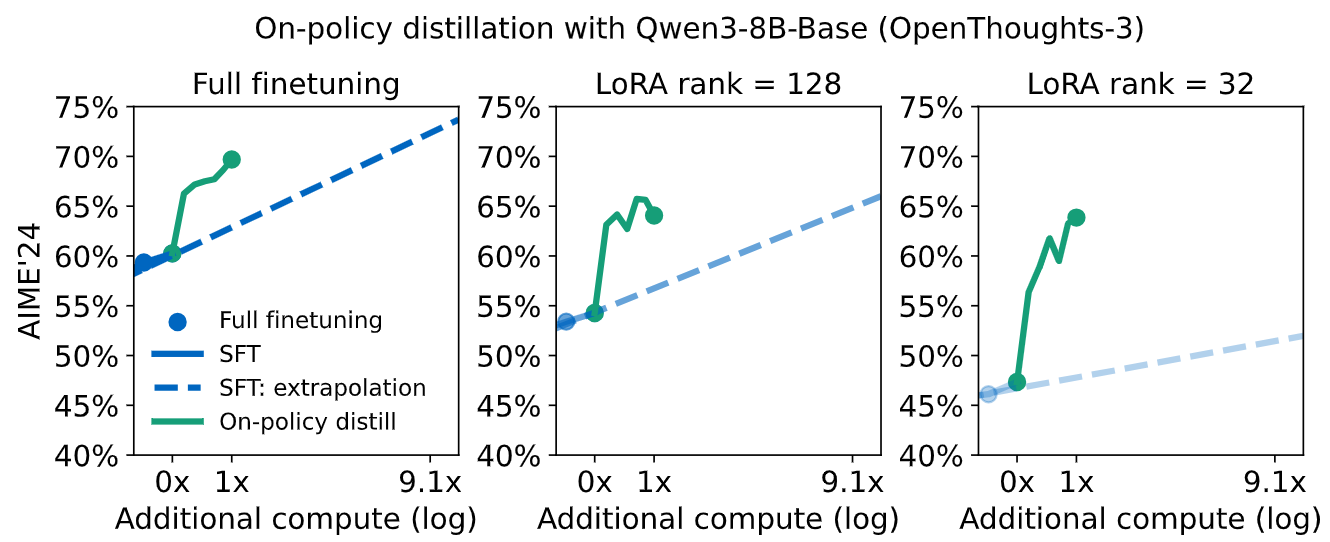
从图中能看出:
- 离线蒸馏(SFT)的分数增长越来越慢(log-linear趋势),要达到70分需要海量样本;
- 在策略蒸馏不管是全参数微调还是LoRA微调,分数都快速飙升,很快突破70分,且LoRA的性能差距也被缩小(LoRA rank=32时,离线蒸馏比全微调差13%,在线蒸馏后仅差6%)。
2. 场景2:个性化助手训练——解决“学新忘旧”的痛点
目标:训练一个“公司内部助手”,要求:
- 懂公司内部知识(通过学习内部文档);
- 保持良好的指令跟随能力(比如聊天、响应需求)。
传统方法的痛点:学新忘旧
用传统离线蒸馏(SFT)训练时,会出现“灾难性遗忘”:
- 只学内部文档:内部知识问答正确率从18%提升到43%,但指令跟随(IF-eval)分数从85%暴跌到45%;
- 混合内部文档+聊天数据(7:3):知识正确率36%,指令跟随79%,仍没恢复到原来的85%;
- 即使只用LoRA微调(限制参数更新),还是会“学少忘多”——知识提升有限,指令跟随仍会下降。
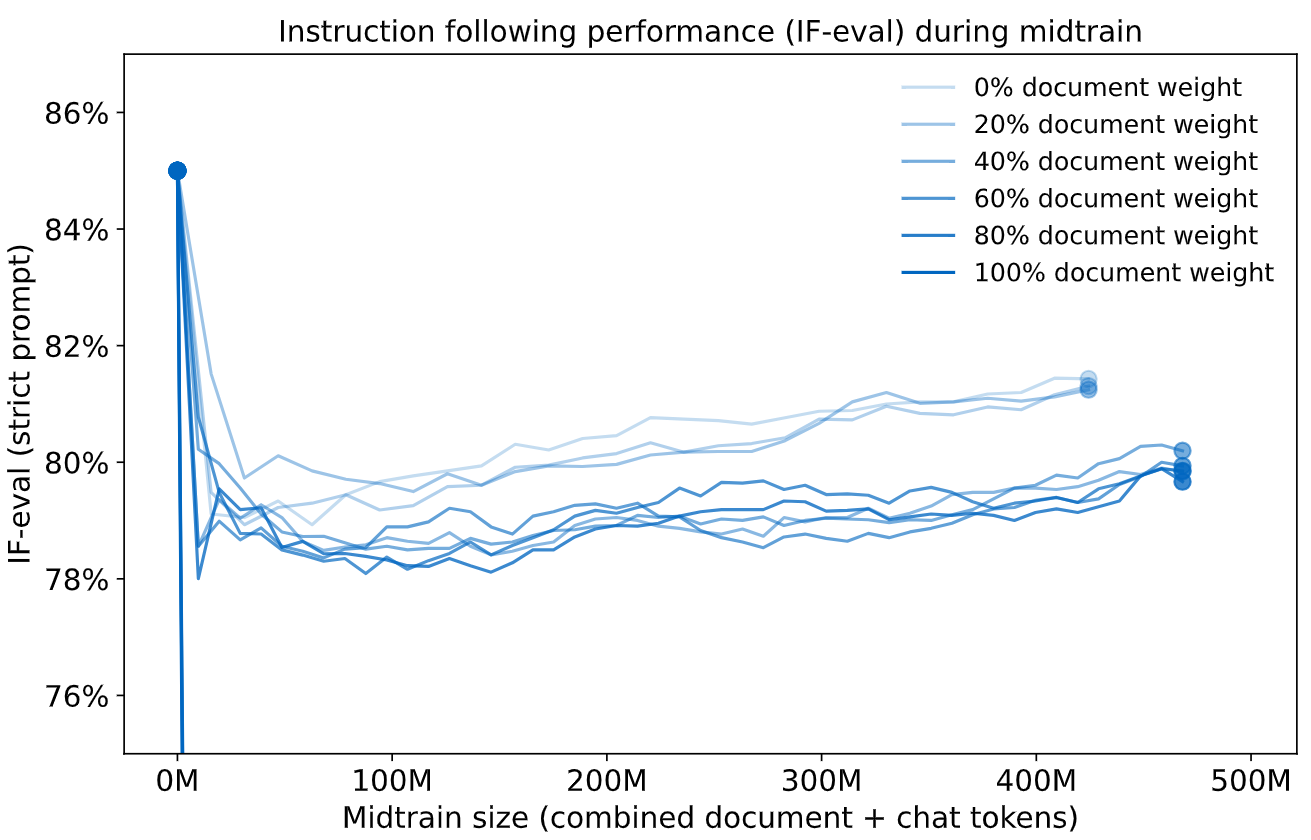
从图中能看到:不管内部文档占比多少,指令跟随分数都会随着训练持续下降,且无法恢复。
在策略蒸馏的解决方案:“学新不丢旧”
用在策略蒸馏做“恢复训练”——以原始Qwen3-8B(指令跟随能力强)为教师,在聊天数据上做蒸馏:
- 训练后:内部知识问答正确率从36%提升到41%(没丢新知识);
- 指令跟随分数从79%恢复到83%(接近原始水平85%)。
| 模型状态 | 内部QA正确率(知识) | IF-eval分数(指令跟随) |
|---|---|---|
| 原始Qwen3-8B | 18% | 85% |
| + 70%内部文档+30%聊天数据(SFT) | 36% | 79% |
| + 上述SFT + 在策略蒸馏 | 41% | 83% |
核心原因:在策略蒸馏能“精准恢复”丢失的行为——教师模型(原始Qwen3-8B)会逐token点评学生的聊天输出,让学生重新学会“怎么好好响应指令”,同时不覆盖已学到的内部知识。
四、关键讨论:为什么在策略蒸馏这么强?
博客从3个角度解释了其核心优势:
1. 密集反馈=更高训练效率
- 强化学习(RL):每个训练 episode(比如解一道题)只给1个最终反馈(赢/输、对/错),仅传递O(1)比特信息;
- 在策略蒸馏:每个token都给反馈,传递O(N)比特信息(N是token长度),相当于“每一步都在纠错”,效率自然高。
实验证明:在策略蒸馏学到RL相同的性能,仅需1/71/10的梯度步骤,计算效率提升50100倍。
2. 数据可复用=更低数据成本
传统RL不能重复用同一个训练样本(会导致模型死记硬背答案),但在策略蒸馏可以:
- 因为它学习的是“教师的概率分布”(比如解题的合理步骤),而不是“单个标准答案”;
- 博客实验:只用1道数学题的prompt,重复训练20步(5120个样本),就能达到教师模型的AIME’24分数——这意味着数据稀缺时,在策略蒸馏仍能有效训练。
3. 始终“在线”=避免误差累积
离线蒸馏的问题:学生学的是教师的场景,自己实际用的时候容易“跑偏”(比如学生犯了教师不会犯的早期错误,后续越错越远);
在策略蒸馏的优势:学生只学自己生成的场景,教师在每个步骤都“拉回正轨”,不会出现长期跑偏,这也是它适合“持续学习”的核心原因。
五、适用场景
- 小模型领域定制:比如训练医疗小模型(学医疗知识+保持推理能力)、企业内部助手(学内部文档+保持交互能力);
- 大模型持续更新:需要不断注入新知识(比如行业动态、新政策),又不想丢失原有核心能力;
- 低成本追赶SOTA:没有海量数据和GPU资源,用小模型+在策略蒸馏,能快速达到大模型的专项性能

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)