国产生成式人工智能解决物理问题能力研究——以“智谱AI”、“讯飞星火认知大模型”、“天工”、“360智脑”、“文心一言”为例
摘要:本研究评估了国内五大生成式AI模型(智谱GLM-3turbo、讯飞星火V2.0、天工1.0、360智脑4.0和文心一言3.5)在解决经典力学问题时的表现。通过29道题目测试发现,这些AI在概念理解方面表现较好(平均得分13.27),推理计算次之(生活实践类10.70,学习探索类13.27),实验设计最差。其中"天工"在概念理解表现最优,"文心一言"在推
导读:
ChatGPT是一款功能强大的预训练语言模型,自2022年发布以来,引发了人们的广泛关注。为紧跟人工智能的发展潮流,我国也相继出品了自己的生成式人工智能模型。为了检测国产模型解决实际物理问题的能力,本文选取了“智谱AI”、“讯飞星火”、“天工”、“360智脑”和“文心一言”等五大模型,以经典力学问题为例,分别测试了其概念理解、推理计算和实验设计能力。研究发现,上述五个模型在概念理解方面的解题能力最强,推理计算次之,实验设计最差,实际解题过程存在“计算失误”、“前后回答不一致”、“情境分析能力欠缺”等问题。横向比较:“天工”在概念理解方面的表现占优,而“文心一言”在推理计算方面的表现最好。总的来说,我国国产模型实现替代人类解题似乎还有很长的一段路要走。
作者信息:
庞付豪, 陈美娜*, 孙雨心:山东师范大学物理与电子科学学院,山东 济南
论文详情
研究设计
1.研究对象
文对各人工智能的三次测试时间为:2023年11月1日至2023年12月1日,具体测试对象为智谱GLM-3turbo模型;讯飞星火V2.0模型;天工1.0模型;360智脑4.0模型;文心一言3.5模型,均为各人工智能模型较为初级的版本,因此本文主要展示我国生成式人工智能起步阶段的解题表现。
2. 研究工具
本研究为了全面地了解上述生成式人工智能的物理问题解决能力,将问题分为概念理解题、推理计算题和实验设计题三类,并进一步将概念理解题分为没有图像的概念理解题与有图像的概念理解题,推理计算题分为了生活实践类情境的推理计算题和学习探索类的推理计算题两类,共设计了29个问题。本次研究仅局限于生成式人工智能针对经典力学问题的解决能力,后续不再进行重复强调。
3. 数据处理
本研究基于Likter 5点计分法设置评分标准,根据答案的符合程度将每题的得分分别记为1~5分。所有题目都由两位评分者基于同一标准单独评分,且每个题目重复测试三次,取平均分作为一位评分者对该题目的评分,再将两位评分者的评分取平均值作为该题的最终得分,具体评分标准见附录1 (表1)。
测试结果与分析
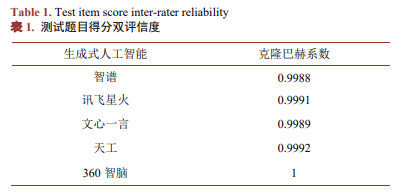
1. 五大生成式人工智能模型在物理概念理解题上的表现
各生成式人工智能概念理解题的得分情况如图1所示。
以第25题为例,展示不同人工智能针对概念理解题的解题情况(文心一言回答较长,仅截取最后结论部分)。
具体回答情况如表2所示,“智谱”、“文心一言”和“天工”能够基于牛顿第一定律得出正确的回答,其中“智谱”还特别指出重力不会影响水平方向的运动,而“讯飞星火”与“360智脑”将竖直方向的重力混入水平方向的受力,导致最后出现错误。


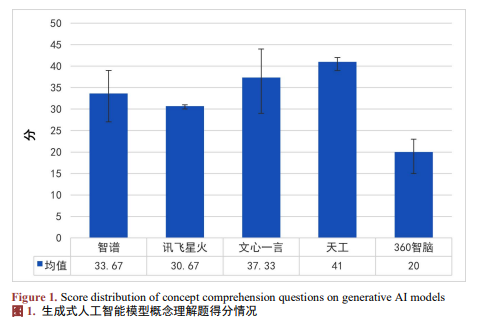
2. 五大生成式人工智能模型在推理计算题上的表现
五大生成式人工智能模型在解决推理计算题上的表现如图3所示。由图可见,它们在解决推理计算题时的整体表现处于中下水平,且在解决学习探索类推理计算题时的表现(平均分为13.27)优于解决生活实践类推理计算题的表现(平均分为10.70)。
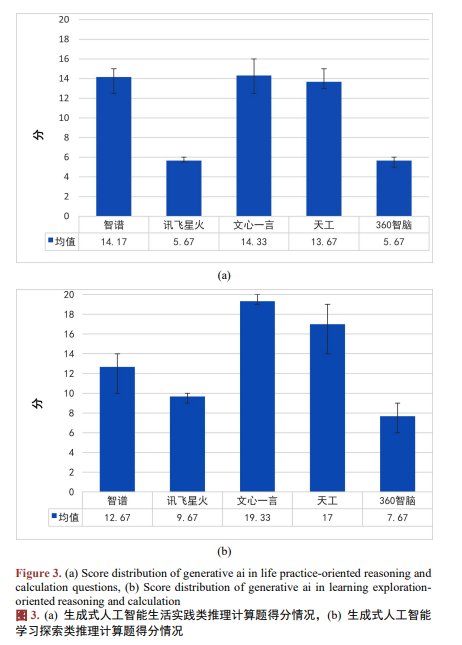
在研究中,笔者发现上述人工智能在解决推理计算题时,多次出现列出公式正确,代入数据正确,但是最后给出的结果错误的现象。
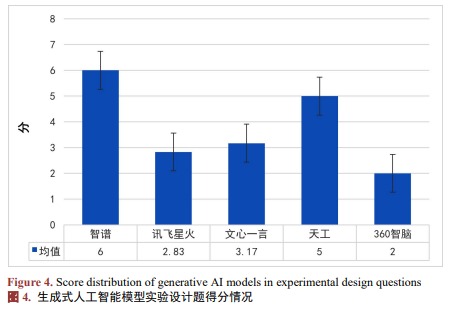
3. 实验设计题的解决能力处于中下水平
各生成式人工智能在实验设计题中的得分如图4所示。
在研究中,笔者发现上述人工智能都或多或少都存在解题能力不稳定的情况,如图5所示。
结论
经过前面的研究,笔者发现上述生成式人工智能求解经典力学问题的能力与人们对人工智能“全知全能”的预期还存在较大差距。具体表现为在解决概念理解题时的表现较好,但是在解决推理计算题与实验设计题时的表现有些不尽如人意。同时,还存在不同生成式人工智能之间的解题能力差距较大,同一生成式人工智能解决不同类型题目的表现差距较大,同一题目多次求解给出的答案前后不一等问题。相较于“讯飞星火”与“360智脑”,“天工”、“文心一言”和“智谱”在测试中的整体表现较好,基本可以理解题意,给出合理的解题思路。因此,虽然上述三个生成式人工智能还不能保证给出满分的回答,但是它们的回答能在一定程度上给予提问者情境分析与解题思路。
基金项目:
基于OBE理念的《数学物理方法》教学改革实践研究(项目编号:2024MJ31)
原文链接:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)