一篇文章带你快速入门Spring AI Alibaba:与企业接轨
RAG允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答(比如学校总务系统,如果你只想要AI大模型输出准确的消息,而对不知道的事情不输出,就可以使用RAG)Java界的SpringCloud Openfeign,只不过Openfeign是用于微服务通讯的, 而MCP用于大模型通讯的,但它们都是为了通讯获取某项数据的一种机制。其核心功能是通过高效的索引结构和相似性
目录
Spring AI Alibaba

官网地址:
阿里云百炼平台
是什么
Spring AI Alibaba 开源项目基于 Spring AI 构建,是阿里云通义系列模型及服务在 Java AI 应用开发领域的最佳实践,提供高层次的 AI API 抽象与云原生基础设施集成方案和企业级 AI 应用生态集成。
能干什么
Spring AI Alibaba 基于 Spring AI 构建,因此SAA继承了SpringAI 的所有原子能力抽象并在此
基础上扩充丰富了模型、向量存储、记忆、RAG 等核心组件适配,让其能够接入阿里云的 AI 生态。
通过后续讲解配置规则,所有调用均基于 OpenAI协议标准或者SpringAI Aalibaba官方推荐模型服务灵积(DashScope)整合规则,实现一致的接口设计与规范,确保多模型切换的便利性,提供高度可扩展的开发支持
怎么用
大模型调用三件套
- 获得Api-key
- 获得模型名(qwen-plus)
- 获得baseUrl开发地址(使用SDK调用时需配置的base_url:https://dashscope.aliyuncs.com/compatible-mode/v1)
pom配置
<properties>
<spring-ai.version>1.0.0</spring-ai.version>
<spring-ai-alibaba.version>1.0.0.2</spring-ai-alibaba.version>
<spring-boot.version>3.4.5</spring-boot.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
</dependencies>写yml文件
server.port=8001
#大模型对话中文乱码UTF8编码处理
server.servlet.encoding.enabled=true
server.servlet.encoding.force=true
server.servlet.encoding.charset=UTF-8
spring.application.name=SAA-01HelloWorld
# ====SpringAIAlibaba Config=============...ApiKey不可以明文 需配置进环境变量

然后修改环境变量,环境变量名字与yml文件中相同
ChatModel,文本聊天交互模型
配置chatModel
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SaaLLMConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Bean
public DashScopeApi dashScopeApi(){
return DashScopeApi.builder().apiKey(apiKey).build();
}
}
调用大模型(直接输出和流式输出)
@RestController
public class ChatHelloController {
@Resource
private ChatModel chatModel;
@GetMapping(value = "/hello/dochat")
public String doChat(@RequestParam(name = "msg",defaultValue="你是谁") String msg)
{
String result = chatModel.call(msg);
return result;
}
@GetMapping(value = "/hello/streamchat")
public Flux<String> stream(@RequestParam(name = "msg",defaultValue="你是谁") String msg)
{
return chatModel.stream(msg);
}
}Ollama本地调用
我们总是听到这样的话,大厂里面不允许使用AI大模型,因为大厂里面可能会存在一些商业秘密或者一些不想让别人知道的信息,那么我们就可以使用ollama将大模型拉取到本地,然后进行调用,从而达到一个保密的效果
下载网址
https://ollama.com/download
注意设置ollama的下载地址(防止放在c盘导致内容崩溃)

cmd窗口验证是否安装成功
ollama --versionollama run qwen:4b退出: /bye引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<version>1.0.0</version>
</dependency>修改配置(ollama默认端口11434)
# ====Spring AI Ollama Config========
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.options.model=qwen3:latest模型的名字可以用ollama ps进行查看
@RestController
public class OllamaController {
@Resource(name="ollamaChatModel")
private ChatModel ollamaModel;
@GetMapping(value = "/ollama/dochat")
public String doChat(@RequestParam(name = "msg",defaultValue="你是谁") String msg)
{
String result = ollamaModel.call(msg);
return result;
}
@GetMapping(value = "/ollama/streamchat")
public Flux<String> stream(@RequestParam(name = "msg",defaultValue="你是谁") String msg)
{
return ollamaModel.stream(msg);
}
}
注意:一定要者resource后面指定类名,不然会导致寻找到俩个类,不知道导入那个


ChatClient
对话模型(ChatModel)是底层接口,直接与具体大语言模型交互, 提供call()和stream()方法,适合简单大模型交互场景
ChatClient是高级封装,基于ChatModel构建,适合快速构建标准化复杂AI服务,支持同步和流式交互,集成多种高级功能。
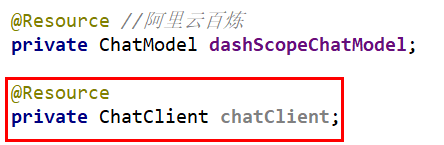
如果用自动注入的方式的话,会导致启动失败;
得出结论,ChatClient不支持自动注入只支持手动注入
参考文档:
@Configuration
public class SaaLLMConfig {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Bean
public DashScopeApi dashScopeApi(){
return DashScopeApi.builder().apiKey(apiKey).build();
}
@Bean
public ChatClient chatClient(@Qualifier("dashscopeChatModel") ChatModel dashScopeChatModel){
return ChatClient.builder(dashScopeChatModel).build();
}
}
@RestController
public class ChatClientController {
@Resource
@Qualifier("dashscopeChatModel")
private ChatModel chatModel;
@Resource
private ChatClient chatClient;
@GetMapping(value = "/client/dochat")
public String doChat(@RequestParam(name = "msg",defaultValue="你是谁") String msg)
{
String result = chatClient.prompt().user(msg).call().content();
return result;
}
}
两者不是非此即彼,可以同时出现交替使用
流式输出
是一种逐步返回大模型生成结果的技术,生成一点返回一点,允许服务器将响应内容
分批次实时传输给客户端,而不是等待全部内容生成完毕后再一次性返回。
。这种机制能显著提升用户体验,尤其适用于大模型响应较慢的场景(如生成长文本或复杂推理结果)。

SSE
一种让服务器能够主动、持续地向客户端(比如你的网页浏览器)推送数据的技术

多模型共存
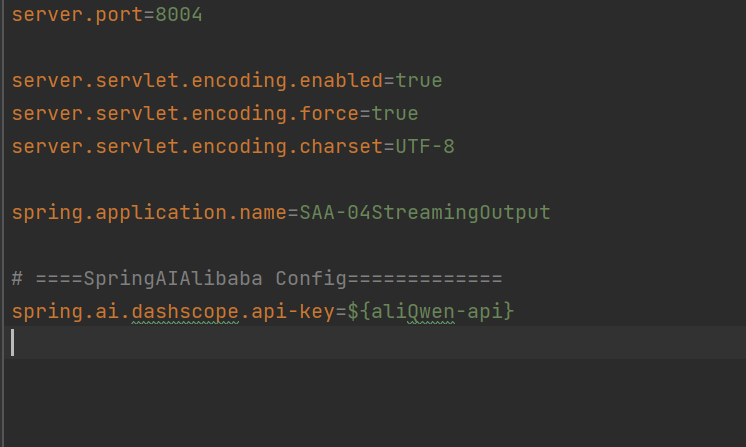
修改配置文件,让模型名字不固定,并且由于模型都是通过阿里云百炼平台调用的,所以baseurl也是默认就有的
修改配置类,主动指定模型选项
package com.atguigu.study.config;
import com.alibaba.cloud.ai.dashscope.api.DashScopeApi;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatModel;
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatOptions;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @auther zzyybs@126.com
* @create 2025-07-25 18:53
* @Description ChatModel+ChatClient+多模型共存
*/
@Configuration
public class SaaLLMConfig
{
// 模型名称常量定义,一套系统多模型共存
private final String DEEPSEEK_MODEL = "deepseek-v3";
private final String QWEN_MODEL = "qwen-max";
@Bean(name = "deepseek")
public ChatModel deepSeek()
{
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(System.getenv("aliQwen-api")).build())
.defaultOptions(DashScopeChatOptions.builder().withModel(DEEPSEEK_MODEL).build())
.build();
}
@Bean(name = "qwen")
public ChatModel qwen()
{
return DashScopeChatModel.builder()
.dashScopeApi(DashScopeApi.builder().apiKey(System.getenv("aliQwen-api")).build())
.defaultOptions(DashScopeChatOptions.builder().withModel(QWEN_MODEL).build())
.build();
}
@Bean(name = "deepseekChatClient")
public ChatClient deepseekChatClient(@Qualifier("deepseek") ChatModel deepseek)
{
return
ChatClient.builder(deepseek)
.defaultOptions(ChatOptions.builder().model(DEEPSEEK_MODEL).build())
.build();
}
@Bean(name = "qwenChatClient")
public ChatClient qwenChatClient(@Qualifier("qwen") ChatModel qwen)
{
return
ChatClient.builder(qwen)
.defaultOptions(ChatOptions.builder().model(QWEN_MODEL).build())
.build();
}
}@RestController
public class StreamOutputController
{
//V1 通过ChatModel实现stream实现流式输出
@Resource(name = "deepseek")
private ChatModel deepseekChatModel;
@Resource(name = "qwen")
private ChatModel qwenChatModel;
@GetMapping(value = "/stream/chatflux1")
public Flux<String> chatflux(@RequestParam(name = "question",defaultValue = "你是谁") String question)
{
return deepseekChatModel.stream(question);
}
@GetMapping(value = "/stream/chatflux2")
public Flux<String> chatflux2(@RequestParam(name = "question",defaultValue = "你是谁") String question)
{
return qwenChatModel.stream(question);
}
//V2 通过ChatClient实现stream实现流式输出
@Resource(name = "deepseekChatClient")
private ChatClient deepseekChatClient;
@Resource(name = "qwenChatClient")
private ChatClient qwenChatClient;
@GetMapping(value = "/stream/chatflux3")
public Flux<String> chatflux3(@RequestParam(name = "question",defaultValue = "你是谁") String question)
{
return deepseekChatClient.prompt(question).stream().content();
}
@GetMapping(value = "/stream/chatflux4")
public Flux<String> chatflux4(@RequestParam(name = "question",defaultValue = "你是谁") String question)
{
return qwenChatClient.prompt(question).stream().content();
}
}
提示词Prompt
DeepSeek提示词样例
Prompt Library | DeepSeek API Docs
官网解释:
Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应
提示词 (Prompt)-阿里云Spring AI Alibaba官网官网
prompt
Prompt > Message > String 简单的文本字符串提问
Prompt中的四大角色

ChatClient
public Flux<String> chat(String question)
{
return deepseekChatClient.prompt()
// AI 能力边界
.system("你是一个法律助手,只回答法律问题,其它问题回复,我只能回答法律相关问题,其它无可奉告")
.user(question)
.stream()
.content();
}Assistant
AI返回的响应信息,定义为”助手角色”消息。用它可以确保上下文能够连贯的交互。
@GetMapping("/prompt/chat4")
public String chat4(String question)
{
AssistantMessage assistantMessage = deepseekChatClient.prompt()
.user(question)
.call()
.chatResponse()
.getResult()
.getOutput();
return assistantMessage.getText();
}ChatModel
public Flux<ChatResponse> chat2(String question)
{
// 系统消息
SystemMessage systemMessage = new SystemMessage("你是一个讲故事的助手,每个故事控制在300字以内");
// 用户消息
UserMessage userMessage = new UserMessage(question);
Prompt prompt = new Prompt(userMessage, systemMessage);
return deepseekChatModel.stream(prompt);
} @GetMapping("/prompt/chat3")
public Flux<String> chat3(String question)
{
// 系统消息
SystemMessage systemMessage = new SystemMessage("你是一个讲故事的助手," +
"每个故事控制在600字以内且以HTML格式返回");
// 用户消息
UserMessage userMessage = new UserMessage(question);
Prompt prompt = new Prompt(userMessage, systemMessage);
return deepseekChatModel.stream(prompt)
.map(response -> response.getResults().get(0).getOutput().getText());
}至于tool,后面讲解
Prompt Template(提示词模板)
将消息分为不同角色(如用户、助手、系统等),设置功能边界,增强交互的复杂性和上下文感知能力;引入占位符(如{占位符变量名})以动态插入内容。
例如:入职邀请函,不再需要纯手动全部重写,只用填入词就行
主题:欢迎加入!给 [候选人姓名] 的入职邀请函
嗨 [候选人姓名],
重磅好消息!经过团队的一致认可,我们真诚地邀请你加入我司,成为我们的 [职位名称]!
从面试中的沟通,我们深深感受到了你的专业能力和对工作的热情,相信你的加入一定会让我们的团队更加出色。
以下是你的入职详情,请查收:
职位: [职位名称]
团队: [部门/团队名称]
工作地点: [公司地址]...@GetMapping("/prompttemplate/chat")
public Flux<String> chat(String topic, String output_format, String wordCount)
{
PromptTemplate promptTemplate = new PromptTemplate("" +
"讲一个关于{topic}的故事" +
"并以{output_format}格式输出," +
"字数在{wordCount}左右");
// PromptTempate -> Prompt
Prompt prompt = promptTemplate.create(Map.of(
"topic", topic,
"output_format",output_format,
"wordCount",wordCount));
return deepseekChatClient.prompt(prompt).stream().content();
}PromptTemplate读取模版文件实现模版功能
@Value("classpath:/prompttemplate/atguigu-template.txt")
private org.springframework.core.io.Resource userTemplate;
@GetMapping("/prompttemplate/chat2")
public String chat2(String topic,String output_format)
{
PromptTemplate promptTemplate = new PromptTemplate(userTemplate);
Prompt prompt = promptTemplate.create(Map.of("topic", topic, "output_format", output_format));
return deepseekChatClient.prompt(prompt).call().content();
}
PromptTemplate多角色设定
* 系统消息(SystemMessage):设定AI的行为规则和功能边界(xxx助手/什么格式返回/字数控制多少)。
* 用户消息(UserMessage):用户的提问/主题
@GetMapping("/prompttemplate/chat3")
public String chat3(String sysTopic, String userTopic)
{
// 1.SystemPromptTemplate
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate("你是{systemTopic}助手,只回答{systemTopic}其它无可奉告,以HTML格式的结果。");
Message sysMessage = systemPromptTemplate.createMessage(Map.of("systemTopic", sysTopic));
// 2.PromptTemplate
PromptTemplate userPromptTemplate = new PromptTemplate("解释一下{userTopic}");
Message userMessage = userPromptTemplate.createMessage(Map.of("userTopic", userTopic));
// 3.组合【关键】 多个 Message -> Prompt
Prompt prompt = new Prompt(List.of(sysMessage, userMessage));
// 4.调用 LLM
return deepseekChatClient.prompt(prompt).call().content();
}
@GetMapping("/prompttemplate/chat4")
public String chat4(String question)
{
//1 系统消息
SystemMessage systemMessage = new SystemMessage("你是一个Java编程助手,拒绝回答非技术问题。");
//2 用户消息
UserMessage userMessage = new UserMessage(question);
//3 系统消息+用户消息=完整提示词
//Prompt prompt = new Prompt(systemMessage, userMessage);
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
//4 调用LLM
String result = deepseekChatModel.call(prompt).getResult().getOutput().getText();
System.out.println(result);
return result;
}
@GetMapping("/prompttemplate/chat5")
public Flux<String> chat5(String question)
{
return deepseekChatClient.prompt()
.system("你是一个Java编程助手,拒绝回答非技术问题。")
.user(question)
.stream()
.content();
}格式化输出
假设我们期望将模型输出转换为Record记录类结构体,不再是传统的String
@GetMapping("/structuredoutput/chat")
public StudentRecord chat(@RequestParam(name = "sname") String sname,
@RequestParam(name = "email") String email) {
return qwenChatClient.prompt().user(new Consumer<ChatClient.PromptUserSpec>()
{
@Override
public void accept(ChatClient.PromptUserSpec promptUserSpec)
{
promptUserSpec.text("学号1001,我叫{sname},大学专业计算机科学与技术,邮箱{email}")
.param("sname",sname)
.param("email",email);
}
}).call().entity(StudentRecord.class);
}记录类record = entity + lombok

Chat Memory
Spring AI Alibaba中的聊天记忆提供了维护 AI 聊天应用程序的对话上下文和历史的机制。
因大模型本身不存储数据,需将历史对话信息一次性提供给它以实现连续对话,不然服务一重启就什么都没了......所以,必须持久化

将客户和大模型的对话问答保存进Redis进行持久化记忆留存
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-memory-redis</artifactId>
</dependency># ==========redis config ===============
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.database=0
spring.data.redis.connect-timeout=3
spring.data.redis.timeout=2@Configuration
public class RedisMemoryConfig
{
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Bean
public RedisChatMemoryRepository redisChatMemoryRepository()
{
return RedisChatMemoryRepository.builder()
.host(host)
.port(port)
.build();
}
} public String chat(String msg, String userId)
{
/*return qwenChatClient.prompt(msg).advisors(new Consumer<ChatClient.AdvisorSpec>()
{
@Override
public void accept(ChatClient.AdvisorSpec advisorSpec)
{
advisorSpec.param(CONVERSATION_ID, userId);
}
}).call().content();*/
return qwenChatClient
.prompt(msg)
.advisors(advisorSpec -> advisorSpec.param(CONVERSATION_ID, userId))
.call()
.content();
}文生图
public static final String IMAGE_MODEL = "wanx2.1-t2i-turbo";
@Resource
private ImageModel imageModel;
@GetMapping(value = "/t2i/image")
public String image(@RequestParam(name = "prompt",defaultValue = "刺猬") String prompt)
{
return imageModel.call(
new ImagePrompt(prompt, DashScopeImageOptions.builder().withModel(IMAGE_MODEL).build())
)
.getResult()
.getOutput()
.getUrl();
}文生音
JavaSDK调用方法参数及接口详解-大模型服务平台百炼-阿里云
SpeechSynthesizer类提供了语音合成的关键接口
提交文本后,服务端立即处理并返回完整的语音合成结果。整个过程是阻塞式的,客户端需要等待服务端完成处理后才能继续下一步操作。适合短文本语音合成场景
@RestController
public class Text2VoiceController
{
@Resource
private SpeechSynthesisModel speechSynthesisModel;
// voice model
public static final String BAILIAN_VOICE_MODEL = "cosyvoice-v2";
public static final String BAILIAN_VOICE_TIMBER = "longyingcui";//龙应催
/**
* http://localhost:8010/t2v/voice
* @param msg
* @return
*/
@GetMapping("/t2v/voice")
public String voice(@RequestParam(name = "msg",defaultValue = "温馨提醒,支付宝到账100元请注意查收") String msg)
{
String filePath = "d:\\" + UUID.randomUUID() + ".mp3";
//1 语音参数设置
DashScopeSpeechSynthesisOptions options = DashScopeSpeechSynthesisOptions.builder()
.model(BAILIAN_VOICE_MODEL)
.voice(BAILIAN_VOICE_TIMBER)
.build();
//2 调用大模型语音生成对象
SpeechSynthesisResponse response = speechSynthesisModel.call(new SpeechSynthesisPrompt(msg, options));
//3 字节流语音转换
ByteBuffer byteBuffer = response.getResult().getOutput().getAudio();
//4 文件生成
try (FileOutputStream fileOutputStream = new FileOutputStream(filePath))
{
fileOutputStream.write(byteBuffer.array());
} catch (Exception e) {
System.out.println(e.getMessage());
}
//5 生成路径OK
return filePath;
}
}
音色表
向量化和向量数据库
向量化是什么
将文本、图像和视频转换为称为向量(Vectors)的浮点数数组。这些向量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维度
向量数据库是什么
一种专门用于存储、管理和检索向量数据(即高维数值数组)的数据库系统。
其核心功能是通过高效的索引结构和相似性计算算法,支持大规模向量数据的快速查询与分析,向量数据库维度越高,查询精准度也越高,查询效果也越好。
向量数据库能干什么
将文本、图像和视频转换为称为向量的浮点数数组在 VectorStore中,查询与传统关系数据库不同。它们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,VectorStore 返回与查询向量“相似”的向量

将文本映射到高维空间中的点,使语义相似的文本在这个空间中距离较近。
我们这里使用RedisStack作为演示的向量数据库
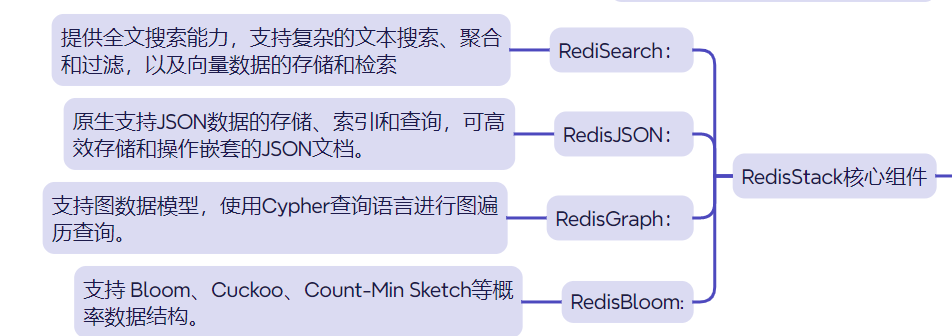
总结:RedisStack = 原生Redis + 搜索 + 图 + 时间序列 + JSON + 概率结构 + 可视化工具 + 开发框架支持
使用docker创建redisstack
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server引入向量大模型
spring.ai.dashscope.embedding.options.model=text-embedding-v3补全redisstack相关配置
# =======Redis Stack==========
spring.data.redis.host=localhost
spring.data.redis.port=6379
spring.data.redis.username=default
spring.data.redis.password=
spring.ai.vectorstore.redis.initialize-schema=true
启动时自动初始化 Redis 向量数据库的索引结构和存储模式
spring.ai.vectorstore.redis.index-name=custom-index
指定 Redis 中向量索引的名称为 custom-index
spring.ai.vectorstore.redis.prefix=custom-prefix
为 Redis 中存储的向量相关键(Key)添加统一前缀 custom-prefix
引入依赖
<!-- 添加 Redis 向量数据库依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
@RestController
@Slf4j
public class Embed2VectorController
{
@Resource
private EmbeddingModel embeddingModel;
@Resource
private VectorStore vectorStore;
@GetMapping("/text2embed")
public EmbeddingResponse text2Embed(String msg)
{
EmbeddingResponse embeddingResponse = embeddingModel.call(new EmbeddingRequest(List.of(msg),
DashScopeEmbeddingOptions.builder().withModel("text-embedding-v3").build()));
System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));
return embeddingResponse;
}
}
调用向量化大模型来实现文本向量化
/**
* 文本向量化 后存入向量数据库RedisStack
*/
@GetMapping("/embed2vector/add")
public void add()
{
List<Document> documents = List.of(
new Document("i study LLM"),
new Document("i love java")
);
vectorStore.add(documents);
}
将向量化后的数据存入redisStack
// 从向量数据库RedisStack查找,进行相似度查找
@GetMapping("/embed2vector/get")
public List getAll(@RequestParam(name = "msg") String msg)
{
SearchRequest searchRequest = SearchRequest.builder()
.query(msg)
.topK(2)
.build();
List<Document> list = vectorStore.similaritySearch(searchRequest);
System.out.println(list);
return list;
}从向量数据库RedisStack查找,进行相似度查找
RAG(检索增强生成)
需求分析:
AI智能运维助手,通过提供的错误编码,给出异常解释辅助运维人员更好的定位问题和维护系统
SpringAI+阿里百炼嵌入模型text-embedding-v3+向量数据库RedisStack+DeepSeek来实现RAG功能。
LLM的缺陷
- LLM的知识不是实时的,不具备知识更新.
- LLM可能不知道你私有的领域/业务知识.
- LLM有时会在回答中生成看似合理但实际上是错误的信息
RAG使用场景
LLM 的知识仅限于它所接受的训练数据。如果你想让一个 LLM 了解特定领域的知识或专有数据,你可以使用RAG
RAG技术就像给AI大模型装上了「实时百科大脑」,为了让大模型获取足够的上下文,以便获得更加广泛的信息源,通过先查资料后回答的机制,让AI摆脱传统模型的”知识遗忘和幻觉回复”困境
能干什么
通过引入外部知识源来增强LLM的输出能力,传统的LLM通常基于其训练数据生成响应,但这些数据可能过时或不够全面。RAG允许模型在生成答案之前,从特定的知识库中检索相关信息,从而提供更准确和上下文相关的回答(比如学校总务系统,如果你只想要AI大模型输出准确的消息,而对不知道的事情不输出,就可以使用RAG)
RAG 流程分为两个不同的阶段:索引和检索
提供知识文档
00000 系统OK正确执行后的返回
A0001 用户端错误一级宏观错误码
A0100 用户注册错误二级宏观错误码
B1111 支付接口超时
C2222 Kafka消息解压严重配置redisTemplate解决去重问标题,防止每次重启服务读取数据的时候都会重复读以前已经读过的数据(实际上工作的时候一般用不上:一般使用nacos就可以解决了)
@Configuration
@Slf4j
public class RedisConfig
{
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactor)
{
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactor);
//设置key序列化方式string
redisTemplate.setKeySerializer(new StringRedisSerializer());
//设置value的序列化方式json,使用GenericJackson2JsonRedisSerializer替换默认序列化
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
初始化读取知识文档
@Configuration
public class InitVectorDatabaseConfig
{
@Autowired
private VectorStore vectorStore;
@Autowired
private RedisTemplate<String,String> redisTemplate;
@Value("classpath:ops.txt")
private Resource opsFile;
@PostConstruct//在启动服务的时候就自动执行
public void init()
{
//1 读取文件
TextReader textReader = new TextReader(opsFile);
textReader.setCharset(Charset.defaultCharset());
//2 文件转换为向量(开启分词)
List<Document> list = new TokenTextSplitter().transform(textReader.read());
//3 写入向量数据库RedisStack
//vectorStore.add(list);
// 解决上面第3步,向量数据重复问题,使用redis setnx命令处理
//4 去重复版本
String sourceMetadata = (String)textReader.getCustomMetadata().get("source");
String textHash = SecureUtil.md5(sourceMetadata);
String redisKey = "vector-xxx:" + textHash;
// 判断是否存入过,redisKey如果可以成功插入表示以前没有过,可以假如向量数据
Boolean retFlag = redisTemplate.opsForValue().setIfAbsent(redisKey, "1");
System.out.println("****retFlag : "+retFlag);
if(Boolean.TRUE.equals(retFlag))
{
//键不存在,首次插入,可以保存进向量数据库
vectorStore.add(list);
}else {
//键已存在,跳过或者报错
//throw new RuntimeException("---重复操作");
System.out.println("------向量初始化数据已经加载过,请不要重复操作");
}
}
}
RAG检索,只能从已有的知识库中获取内容
@RestController
public class RagController
{
@Resource(name = "qwenChatClient")
private ChatClient chatClient;
@Resource
private VectorStore vectorStore;
/**
* http://localhost:8012/rag4aiops?msg=00000
* http://localhost:8012/rag4aiops?msg=C2222
* @param msg
* @return
*/
@GetMapping("/rag4aiops")
public Flux<String> rag(String msg)
{
String systemInfo = """
你是一个运维工程师,按照给出的编码给出对应故障解释,否则回复找不到信息。
""";
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder().vectorStore(vectorStore).build())
.build();
return chatClient
.prompt()
.system(systemInfo)
.user(msg)
.advisors(advisor)
.stream()
.content();
}
}
RAG检索流程:
读取文件->分段->向量化(加入向量化数据库)->LLM检索
Tool Calling工具调用
我们平时使用deepseek的时候总是可以看到有一个叫联网搜索的按钮
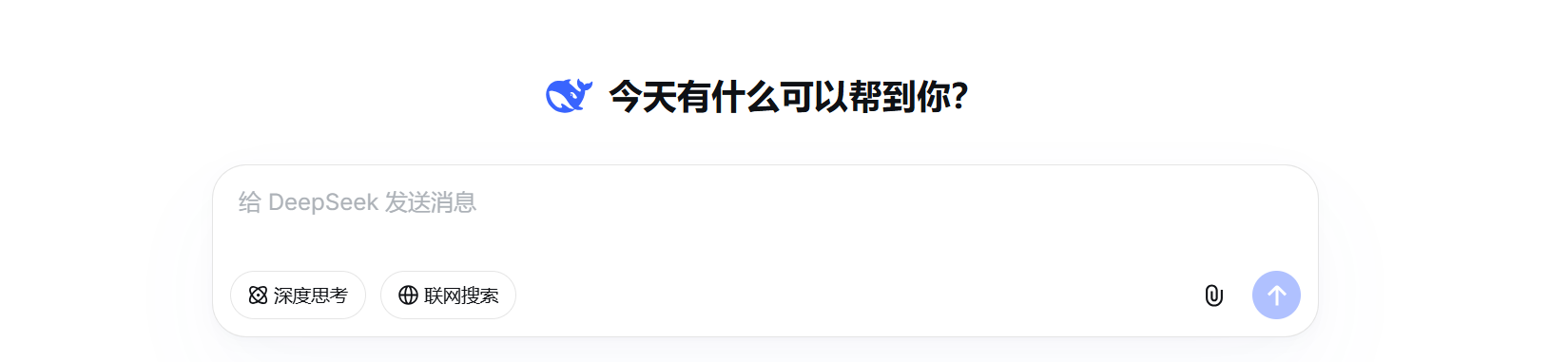
如果我们不点这个按钮的时候,我们问北京的未来三天的天气怎么样?它就会已读乱回,但是我们如果点击联网搜索的话,那么它就会回答我们正确的信息,这个就是tool calling的调用
ToolCalling(也称为FunctionCalling)它允许大模型与一组API或工具进行交互,将 LLM 的智能与外部工具或 API无缝连接,从而增强大模型其功能。
LLM本身并不执行函数,它只是指示应该调用哪个函数以及如何调用
大语言模型(LLMs)不仅仅是文本生成的能手,它们还能触发并调用第3方函数,比如发邮件/查询微信/调用支付宝/查看顺丰快递单据号等等......
public class DateTimeTools
{
/**
* 1.定义 function call(tool call)
* 2. returnDirect
* true = tool直接返回不走大模型,直接给客户
* false = 默认值,拿到tool返回的结果,给大模型,最后由大模型回复
*/
@Tool(description = "获取当前时间", returnDirect = false)
public String getCurrentTime()
{
return LocalDateTime.now().toString();
}
} @Resource
private ChatClient chatClient;
@GetMapping("/toolcall/chat2")
public Flux<String> chat2(@RequestParam(name = "msg",defaultValue = "你是谁现在几点") String msg)
{
return chatClient.prompt(msg)
.tools(new DateTimeTools())
.stream()
.content();
}MCP模型上下文协议
-
之前每个大模型(如DeepSeek、ChatGPT)需要为每个工具单独开发接口(FunctionCalling),导致重复劳动
是什么
Java界的SpringCloud Openfeign,只不过Openfeign是用于微服务通讯的, 而MCP用于大模型通讯的,但它们都是为了通讯获取某项数据的一种机制
提供了一种标准化的方式来连接 LLMs 需要的上下文,MCP 就类似于一个 Agent 时代的 Type-C协议,希望能将不同来源的数据、工具、服务统一起来供大模型调用
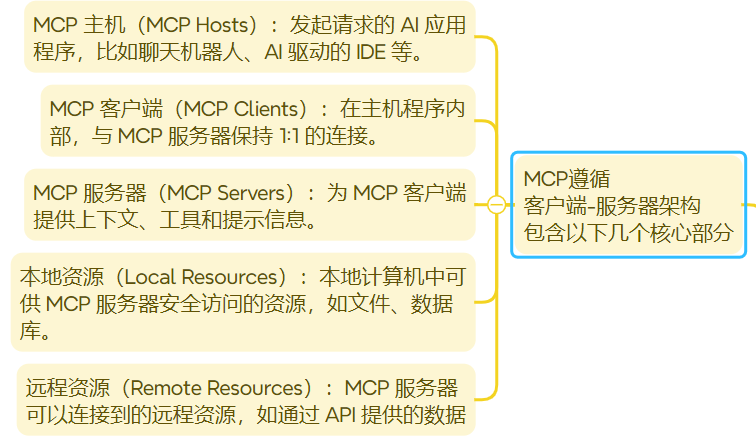
总结:MCP:协议,为了让大模型之间的相互调用
开发者只需写一次MCP服务端,所有兼容MCP协议的模型都能调用,MCP让大模型从"被动应答”变为”主动调用工具”
我调用一个MCP服务器就等价调用一个带有多个功能的Utils工具类,自己还不用受累携带
1.本地调用
MCP服务端
引入依赖,以及删除web依赖
<!--注意事项(重要)
spring-ai-starter-mcp-server-webflux不能和<artifactId>spring-boot-starter-web</artifactId>依赖并存,
否则会使用tomcat启动,而不是netty启动,从而导致mcpserver启动失败,但程序运行是正常的,mcp客户端连接不上。
-->
<!--mcp-server-webflux-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>配置MCP
# ====mcp-server Config=============
spring.ai.mcp.server.type=async
spring.ai.mcp.server.name=customer-define-mcp-server
spring.ai.mcp.server.version=1.0.0@Service
public class WeatherService
{
@Tool(description = "根据城市名称获取天气预报")
public String getWeatherByCity(String city)
{
Map<String, String> map = Map.of(
"北京", "11111降雨频繁,其中今天和后天雨势较强,部分地区有暴雨并伴强对流天气,需注意",
"上海", "22222多云,15℃~27℃,南风3级,当前温度27℃。",
"深圳", "333333多云40天,阴16天,雨30天,晴3天"
);
return map.getOrDefault(city, "抱歉:未查询到对应城市!");
}
}@Tool 是一个在 AI 开发框架中常用的注解,核心作用是将一个 Java 方法标记为 AI 大模型可以调用的 “工具函数”,让大模型在对话过程中能主动触发该方法来完成特定任务
将工具方法暴露
@Configuration
public class McpServerConfig
{
/**
* 将工具方法暴露给外部 mcp client 调用
* @param weatherService
* @return
*/
@Bean
public ToolCallbackProvider weatherTools(WeatherService weatherService)
{
return MethodToolCallbackProvider.builder()
.toolObjects(weatherService)
.build();
}
}MCP客户端
# ====mcp-client Config=============
spring.ai.mcp.client.type=async
spring.ai.mcp.client.request-timeout=60s
spring.ai.mcp.client.toolcallback.enabled=true
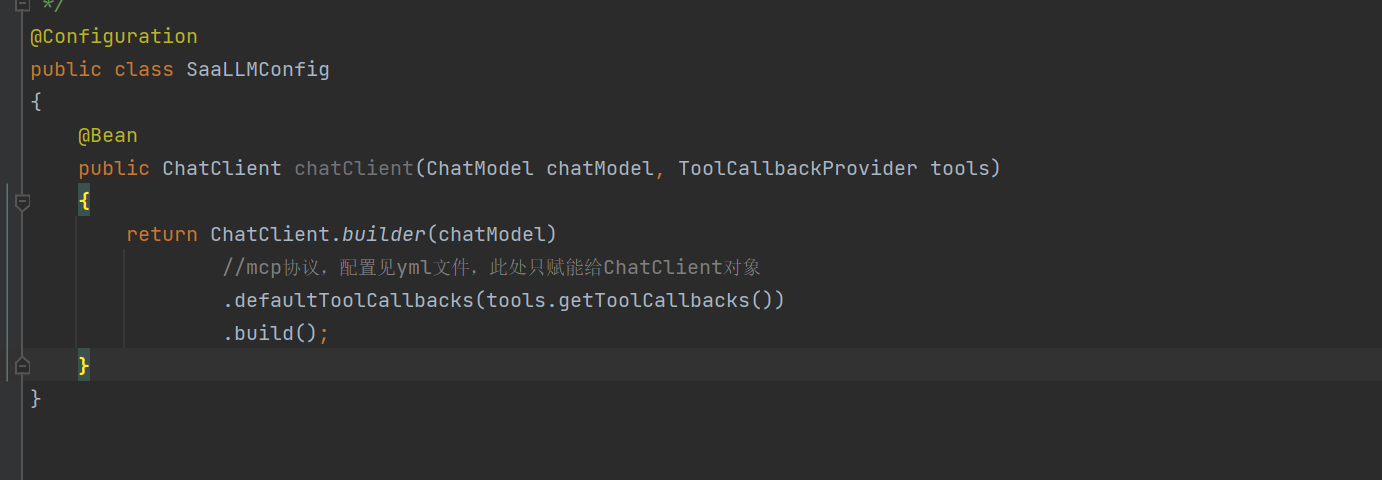
spring.ai.mcp.client.sse.connections.mcp-server1.url=http://localhost:8014@Configuration
public class SaaLLMConfig
{
@Bean
public ChatClient chatClient(ChatModel chatModel, ToolCallbackProvider tools)
{
return ChatClient.builder(chatModel)
.defaultToolCallbacks(tools.getToolCallbacks()) //mcp协议,配置见yml文件
.build();
}
}@GetMapping("/mcpclient/chat")
public Flux<String> chat(@RequestParam(name = "msg",defaultValue = "北京") String msg)
{
System.out.println("使用了mcp");
return chatClient.prompt(msg).stream().content();
}
2.网络调用
调用百度地图大模型
环境配置:
1.下载最新版的NodeJS
2.注册百度地图账号+申请API-key
3.nodejs配置编码-Typescript接入
{
"mcpServers": {
"baidu-map": {
"command": "npx",
"args": [
"-y",
"@baidumap/mcp-server-baidu-map"
],
"env": {
"BAIDU_MAP_API_KEY": "xxx"
}
}
}
}
// 构建McpTransport协议
//cmd:启动 Windows 命令行解释器。
///c:告诉 cmd 执行完后面的命令后关闭自身。
//npx:npx = npm execute package,Node.js 的一个工具,用于执行 npm 包中的可执行文件。
//-y 或 --yes:自动确认操作(类似于默认接受所有提示)。
//@baidumap/mcp-server-baidu-map:要通过 npx 执行的 npm 包名
//BAIDU_MAP_API_KEY 是访问百度地图开放平台API的AK 但我们这里使用json5,因为可以写注释
但我们这里使用json5,因为可以写注释
4.修改yml文件
# ====mcp-client Config=============
spring.ai.mcp.client.request-timeout=20s
spring.ai.mcp.client.toolcallback.enabled=true
spring.ai.mcp.client.stdio.servers-configuration=classpath:/mcp-server.json5配置类依旧
@GetMapping("/mcp/chat")
public Flux<String> chat(String msg)
{
return chatClient.prompt(msg).stream().content();
}如果你觉得哪里不清楚或者哪里有问题欢迎讨论

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)