一文带大家掌握如何通过LoRA对大模型进行微调
LoRA(低秩适应)是一种高效微调大模型的技术,通过训练少量适配器参数实现模型定制,无需修改原模型。与QLoRA(量化版LoRA)相比,LoRA显存占用中等、训练较快,QLoRA通过4-bit量化显著节省显存但速度略慢。HuggingFace的peft库集成了LoRA技术,提供便捷的微调工具。对千问模型微调时,需配置LoRA参数(如秩r)、准备数据,并使用Trainer进行训练。训练后可合并适配器
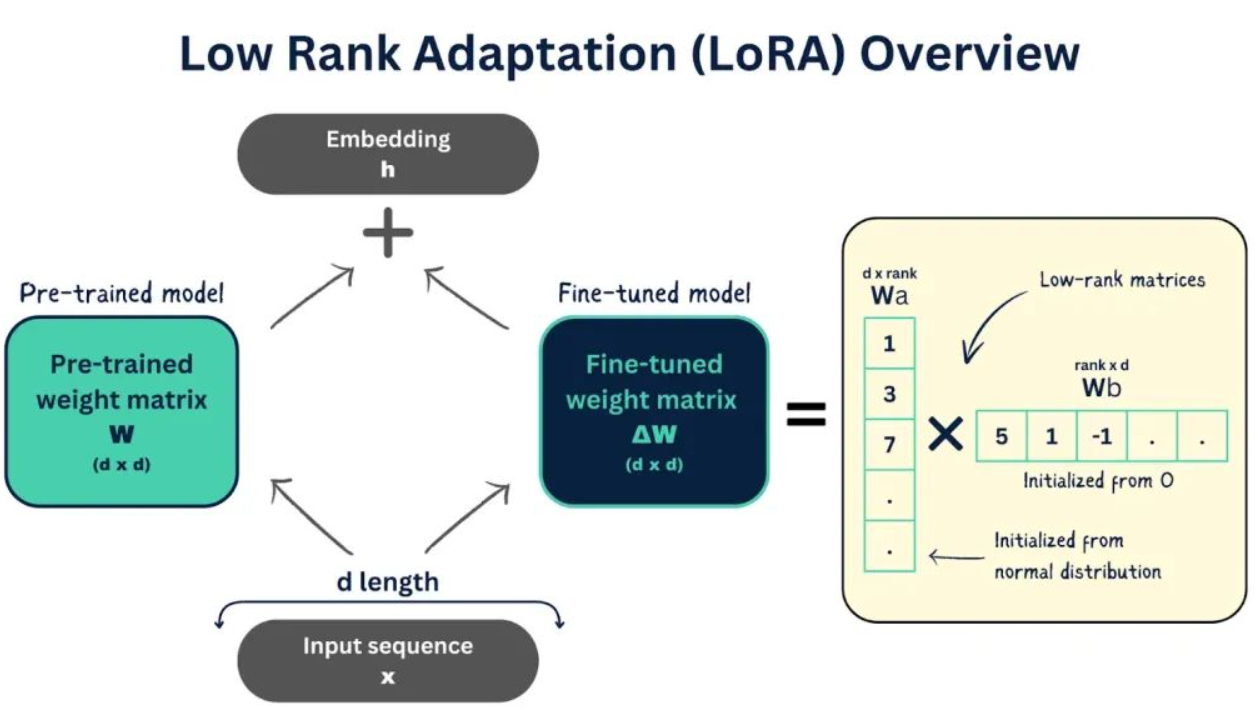
重要概念解释
LoRA
LoRA(Low-Rank Adaptation,低秩适应)是一种参数高效微调(PEFT)技术。它的核心思想是:在不修改原始大模型参数的前提下,通过训练少量的额外参数(适配器),来让大模型学会新技能。
LoRA 与 QLoRA 的区别
| 特性 | LoRA (Low-Rank Adaptation) | QLoRA (Quantized LoRA) |
|---|---|---|
| 核心思想 | “冻结+插件”:冻结原模型 99% 的参数,只训练一个小型的“适配器”插件。 | “量化+LoRA”:在 LoRA 的基础上,将原模型量化为 4-bit(如 NF4),进一步压缩显存。 |
| 显存占用 | 中等(需要加载 FP16 精度的原模型) | 极低(4-bit 量化,显存节省约 70%) |
| 训练速度 | 较快 | 略慢于 LoRA(因涉及量化/反量化计算) |
| 模型性能 | 接近全量微调 | 几乎无损,极接近全量微调 |
| 适用场景 | 显存充足(如 24GB+),追求极致速度 | 显存受限(如 8GB-16GB),微调大模型 |
通俗理解:
- LoRA 就像是给一辆大卡车(预训练模型)加装一个可调节的悬挂系统(LoRA 适配器),你只调整悬挂,卡车本身不动。
- QLoRA 则是先把这辆大卡车拆解压缩成一个模型(量化),然后再加装悬挂系统。虽然开起来(推理时)会自动还原成大卡车,但在车库(显存)里它占的地方很小。
Hugging Face 与 LoRA
这是一个“工具箱”与“工具”的关系。
- Hugging Face (HF):
它是一个开源社区,提供了transformers这个 Python 库。你可以把它看作是一个“万能遥控器”或者“发动机管理软件”。
它负责:下载模型、加载模型、处理数据、控制训练循环。
没有它,很难直接操作 PyTorch/TensorFlow 去加载千问这种复杂的模型。
- LoRA:
它是一种“算法技术”。它定义了“如何在不修改原模型的情况下,通过低秩矩阵来适配模型”。 - 它们怎么合作?
Hugging Face 的团队非常牛,他们把 LoRA 这种技术集成到了他们的另一个库 peft (Parameter-Efficient Fine-Tuning) 中。
关系链:使用 Hugging Face 提供的 peft 库,来调用 LoRA 算法。
代码体现:在代码中 from peft import LoraConfig,这就是在用 Hugging Face 的工具来实现 LoRA。
如何对千问(Qwen)模型进行微调
可以使用 Hugging Face 的 transformers 和 peft 库来轻松实现。以下是基于 Python 的标准操作流程:
第一步:环境准备
需要安装必要的库。如果你要使用 QLoRA,还需要安装 bitsandbytes 来支持量化。
pip install torch transformers accelerate peft datasets
# 如果使用 QLoRA,还需要安装
pip install bitsandbytes
第二步:加载千问模型(以 QLoRA 为例)
这里的关键区别在于是否使用量化配置。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
import torch
model_name = "Qwen/Qwen-7B" # 例如加载 Qwen-7B 模型
# 1. 配置量化(仅 QLoRA 需要,LoRA 可跳过此步)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit 量化
bnb_4bit_quant_type="nf4", # NF4 量化类型
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True, # 双量化,进一步省显存
)
# 2. 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config, # QLoRA 传入量化配置
device_map="auto", # 自动分配GPU
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)第三步:配置 LoRA 参数
这是微调的核心配置。你可以通过调整 r(秩)来控制模型的学习能力。
from peft import LoraConfig
lora_config = LoraConfig(
r=64, # 秩,越大学习能力越强,但也更占显存(常见值:8, 16, 32, 64)
lora_alpha=16, # 缩放因子,通常设为 r 的倍数
target_modules=["q_proj", "v_proj"], # 目标模块,通常选择 Query 和 Value 矩阵
lora_dropout=0.05, # dropout
bias="none",
task_type="CAUSAL_LM"
)
# 将 LoRA 适配器“注入”到模型中
model = get_peft_model(model, lora_config)第四步:准备数据与训练
使用标准的 PyTorch 或 Hugging Face Trainer 进行训练。
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="./qwen_lora_output",
per_device_train_batch_size=1, # 显存受限时设小一点
gradient_accumulation_steps=8, # 梯度累积,模拟大 batch
learning_rate=2e-4,
num_train_epochs=3,
logging_steps=10,
save_strategy="epoch",
optim="paged_adamw_8bit", # 使用分页优化器防止内存碎片(重要)
fp16=True, # 混合精度训练
)
# 假设你已经准备好了 dataset
trainer = Trainer(
model=model,
args=training_args,
train_dataset=your_tokenized_dataset,
)
trainer.train()在数据准备的过程中,我们不需要让模型去背诵《百科全书》(那是预训练干的事),我们需要给它看例子,教它“遇到这种问题,要这样回答”。我们主要的工作:收集几百到几千条这样的数据。
格式:通常是 JSON 格式。
例子:
{
"instruction": "把这句话翻译成文言文",
"input": "今天天气真好",
"output": "今者天氣甚佳。"
}或者:
{
"instruction": "请扮演一个暴躁的程序员",
"input": "帮我写个代码",
"output": "写什么写!需求文档呢?没需求别找我!"
}第五步:合并与推理
训练完成后,你可以将 LoRA 适配器的权重合并回原模型,或者直接独立使用。
# 方式1:推理时直接加载(节省磁盘空间)
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")
# model = PeftModel.from_pretrained(model, "./qwen_lora_output/checkpoint-xxx")
# 方式2:合并权重并保存为完整模型(推理速度更快)
model.merge_and_unload() # 将 LoRA 权重合并到原模型,并卸载适配器
model.save_pretrained("./final_merged_qwen_model")通俗流程总结
- 准备阶段:
- 你的硬盘:空空如也。
- 你的数据:准备好了
my_data.json。
- 加载阶段(代码运行第一步):
- 下载:代码从 Hugging Face Hub 把
Qwen-7B模型下载到本地缓存。 - 加载:代码把
Qwen-7B读入显存。
- 下载:代码从 Hugging Face Hub 把
- 注入阶段(代码运行第二步):
- 挂载:代码使用
peft库,在 Qwen 模型上“挂”一个 LoRA 适配器。 - 冻结:代码把 Qwen 原本的参数设置为“不可训练”(冻住大模型)。
- 激活:代码把 LoRA 适配器设置为“可训练”。
- 挂载:代码使用
- 训练阶段:
- 喂数据:你的
my_data.json被喂给模型。 - 计算:只有 LoRA 适配器在调整参数,显存占用极低。
- 保存:训练结束,代码只保存了 LoRA 适配器的参数(一个很小的
adapter_model.bin文件)。
- 喂数据:你的
- 使用阶段(推理):
- 合并加载:你写推理代码,同时加载
Qwen-7B(大脑)和adapter_model.bin(小脑)。 - 工作:当用户问问题时,大脑负责理解语言,小脑负责控制它按照你的“风格”或“技能”来回答。
- 合并加载:你写推理代码,同时加载
一句话总结:利用 Hugging Face 这个工具,把 千问 这个大模型下载下来,然后给它装上 LoRA 这个“外挂”,让它学会你教给它的新本事,最后把这个“外挂”保存下来,以后每次运行千问时都带上这个“外挂”。
实操建议
- 硬件选择:
- 如果想微调 Qwen-1.8B 或 7B:使用 QLoRA,单张 24GB 显存的显卡(如 RTX 3090/4090)通常足够。
- 如果显存只有 8GB-16GB:建议微调 Qwen-1.8B 或更小的模型,并务必使用 QLoRA。
- 参数调整:
r(rank):如果任务简单(如特定格式回复),r=8或16就够了;如果任务复杂(如学习特定写作风格),建议r=32或64。target_modules:对于 Qwen 模型,通常选择["q_proj", "v_proj"]效果较好。
- 数据格式:
- 确保你的训练数据是按照 Qwen 的对话模板(Chat Template)进行拼接的,这样微调出来的模型在推理时才能正确理解指令。
通过以上步骤,就可以在千问模型的基础上,利用 LoRA 或 QLoRA 快速打造出一个属于你自己的“定制版”模型了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)