AI大模型应用开发-数据工具:Numpy(数组计算)、Pandas(表格数据处理)、Matplotlib(画折线图 / 柱状图)
(Numpy+Pandas+Matplotlib),全程用pip安装,代码简洁可直接运行,聚焦「数组计算 + 表格处理 + 折线图 / 柱状图绘制」,用 Pandas 处理 Excel/CSV 数据,用 Matplotlib 画数据图表
(Numpy+Pandas+Matplotlib),全程用pip安装,代码简洁可直接运行,聚焦「数组计算 + 表格处理 + 折线图 / 柱状图绘制」,用 Pandas 处理 Excel/CSV 数据,用 Matplotlib 画数据图表。
一、 前置准备:pip 安装三个数据工具
用 Python 自带的pip安装,推荐使用国内镜像源加快下载速度,避免超时失败。
步骤 1:打开 Windows cmd(管理员身份更佳)
Win+R 输入cmd,回车打开命令提示符。
步骤 2:逐行输入安装命令(复制即可)
# 1. 安装Numpy(数组计算)
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 安装Pandas(表格数据处理)
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
# 3. 安装Matplotlib(数据可视化)
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
# 4. 补充:Pandas读取Excel需要额外安装openpyxl(小白必备)
pip install openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
步骤 3:验证安装成功
cmd 中输入以下命令,无报错即说明成功(无需显示版本号,能导入即可):
python
# 依次输入python → 进入Python交互环境
python
# 导入三个库,无报错即成功
import numpy
import pandas
import matplotlib
# 退出Python交互环境
exit()
 小白避坑
小白避坑
- 安装报错「Permission denied」:以管理员身份打开 cmd,重新执行安装命令。
- 提示 pip 版本过低:先升级 pip,命令:
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple。
二、 Numpy:数组计算(AI 数据运算的基础)
核心目标
理解 Numpy 数组(加强版列表),掌握简单的数组创建、批量运算、统计计算,对应 AI 场景中的 “数据预处理、矩阵运算”。
1. 小白通俗理解
Numpy 数组 = “提速版 Python 列表”,普通列表只能逐个元素运算(比如[1,2]+[3,4]是拼接,不是加法),而 Numpy 数组支持批量运算([1,2]+[3,4]直接得到[4,6]),运算速度更快,是 AI 中处理大量数据的必备工具。
2. 核心基础用法(代码可直接复制运行)
创建numpy_demo.py文件,粘贴以下代码,用python numpy_demo.py运行。
python
# 1. 导入Numpy,简写为np(小白固定写法,无需修改)
import numpy as np
# 2. 创建Numpy数组(两种常用方式)
# 方式1:从Python列表转换(最易上手)
arr1 = np.array([1, 2, 3, 4, 5]) # 一维数组(类似普通列表)
arr2 = np.array([[1, 2, 3], [4, 5, 6]]) # 二维数组(类似矩阵,2行3列)
print("=== 一维数组 ===")
print(arr1)
print(f"数组形状:{arr1.shape}") # 查看数组形状(元素个数)
print("\n=== 二维数组 ===")
print(arr2)
print(f"数组形状:{arr2.shape}") # 查看数组形状(行×列)
# 3. 批量运算(核心优势,无需循环)
print("\n=== 数组批量运算 ===")
arr1_add = arr1 + 10 # 每个元素都加10
arr1_mul = arr1 * 2 # 每个元素都乘2
arr2_sum = arr2 + arr2 # 二维数组对应元素相加
print(f"arr1每个元素加10:{arr1_add}")
print(f"arr1每个元素乘2:{arr1_mul}")
print(f"arr2自身相加:\n{arr2_sum}")
# 4. 统计计算(AI中常用,求均值、最大值、总和)
print("\n=== 数组统计计算 ===")
print(f"arr1的总和:{np.sum(arr1)}")
print(f"arr1的平均值:{np.mean(arr1):.2f}")
print(f"arr2的最大值:{np.max(arr2)}")
print(f"arr2每一列的平均值:{np.mean(arr2, axis=0)}") # axis=0:按列计算
3. 运行结果
=== 一维数组 ===
[1 2 3 4 5]
数组形状:(5,)
=== 二维数组 ===
[[1 2 3]
[4 5 6]]
数组形状:(2, 3)
=== 数组批量运算 ===
arr1每个元素加10:[11 12 13 14 15]
arr1每个元素乘2:[ 2 4 6 8 10]
arr2自身相加:
[[ 2 4 6]
[ 8 10 12]]
=== 数组统计计算 ===
arr1的总和:15
arr1的平均值:3.00
arr2的最大值:6
arr2每一列的平均值:[2.5 3.5 4.5]
4. AI 场景核心用途
- 数据缩放:将 AI 模型的输入数据(比如房价、像素值)批量缩放到 0-1 范围。
- 误差计算:批量计算模型预测值与真实值的差值,求平均误差。
- 矩阵运算:AI 模型中的权重参数更新,底层依赖 Numpy 数组运算。
三、 Pandas:表格数据处理(Python 版 Excel)
核心目标
掌握 Pandas 读取 / 创建表格、筛选数据、统计分析,能处理 Excel/CSV 格式数据,对应大纲中 “学生成绩统计可视化” 项目。
1. 小白通俗理解
Pandas = “Python 里的 Excel/CSV 工具”,无需打开 Excel,用代码就能实现 “读取表格、筛选数据、计算平均分、去重” 等操作,处理大量数据时比 Excel 更快更高效。
2. 核心基础用法(代码可直接复制运行)
创建pandas_demo.py文件,粘贴以下代码,用python pandas_demo.py运行。
python
# 1. 导入Pandas,简写为pd(小白固定写法,无需修改)
import pandas as pd
# 2. 创建表格数据(DataFrame,Pandas的核心数据结构,类似Excel表格)
# 模拟学生成绩表格(姓名、语文、数学、英语)
score_data = {
"姓名": ["小明", "小红", "小刚", "小丽", "小亮"],
"语文": [85, 92, 78, 95, 88],
"数学": [90, 86, 93, 89, 96],
"英语": [79, 88, 85, 90, 82]
}
# 转换为Pandas表格(DataFrame)
df = pd.DataFrame(score_data)
print("=== 原始学生成绩表格 ===")
print(df) # 打印完整表格
# 3. 基础表格操作(查看、筛选、统计)
print("\n=== 表格基础操作 ===")
# 查看前3行数据(避免数据过多时刷屏)
print("前3行数据:")
print(df.head(3))
# 筛选:语文成绩≥90分的学生
high_chinese = df[df["语文"] >= 90]
print("\n语文≥90分的学生:")
print(high_chinese)
# 统计:计算各科平均分、最高分
subject_mean = df[["语文", "数学", "英语"]].mean() # 各科平均分
subject_max = df[["语文", "数学", "英语"]].max() # 各科最高分
print("\n各科平均分:")
print(subject_mean.round(2)) # 保留2位小数
print("\n各科最高分:")
print(subject_max)
# 4. 保存表格到本地(Excel格式,方便用Excel打开查看)
df.to_excel("学生成绩表.xlsx", index=False)
print("\n表格已保存为「学生成绩表.xlsx」,可在当前文件夹下找到!")
3. 运行结果
=== 原始学生成绩表格 ===
姓名 语文 数学 英语
0 小明 85 90 79
1 小红 92 86 88
2 小刚 78 93 85
3 小丽 95 89 90
4 小亮 88 96 82
=== 表格基础操作 ===
前3行数据:
姓名 语文 数学 英语
0 小明 85 90 79
1 小红 92 86 88
2 小刚 78 93 85
语文≥90分的学生:
姓名 语文 数学 英语
1 小红 92 86 88
3 小丽 95 89 90
各科平均分:
语文 87.60
数学 90.80
英语 84.80
dtype: float64
各科最高分:
语文 95
数学 96
英语 90
dtype: int64
表格已保存为「学生成绩表.xlsx」,可在当前文件夹下找到!
4. 小白额外操作
运行完成后,在pandas_demo.py所在文件夹下,会出现学生成绩表.xlsx文件,双击可用 Excel 打开,和代码运行结果一致。
5. AI 场景核心用途
- 数据清洗:处理 AI 数据集的缺失值、重复值(比如删除无意义的数据)。
- 特征提取:从表格数据中筛选出模型需要的特征(比如从用户数据中提取 “年龄”“消费金额”)。
- 数据统计:分析数据集的分布(比如正负面样本的占比),为模型训练做准备。
四、 Matplotlib:数据可视化(画折线图 / 柱状图)
核心目标
掌握 Matplotlib 绘制折线图、柱状图,解决中文乱码问题,让数据更直观,对应大纲中 “学生成绩分布图表” 的学习目标。
1. 小白通俗理解
Matplotlib = “Python 里的画图工具”,能把 Pandas 处理后的表格数据,转换成 “折线图(看趋势)、柱状图(比大小)”,比数字更易理解。
2. 核心基础用法(先解决中文乱码,再画图)
创建matplotlib_demo.py文件,粘贴以下代码,用python matplotlib_demo.py运行。
python
# 1. 导入Matplotlib的绘图模块,简写为plt(小白固定写法)
import matplotlib.pyplot as plt
import pandas as pd
# 2. 解决中文乱码问题(小白必配,否则中文显示为方框)
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体为“黑体”,支持中文
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示为方框的问题
# 3. 准备数据(用Pandas读取之前创建的学生成绩表)
df = pd.read_excel("学生成绩表.xlsx", engine="openpyxl")
names = df["姓名"]
chinese_scores = df["语文"]
math_scores = df["数学"]
subjects = ["语文", "数学", "英语"]
subject_means = df[subjects].mean() # 各科平均分
# 4. 绘制折线图(查看单个学生成绩趋势,这里以小明为例)
print("=== 正在绘制折线图 ===")
plt.figure(figsize=(8, 4)) # 设置图表大小(宽×高)
# 绘制小明的成绩折线图
xiao_ming_scores = [df.loc[0, "语文"], df.loc[0, "数学"], df.loc[0, "英语"]]
plt.plot(subjects, xiao_ming_scores, marker="o", color="red", label="小明成绩")
# 添加图表标题和坐标轴标签
plt.title("小明各科成绩折线图")
plt.xlabel("科目")
plt.ylabel("成绩")
plt.grid(True, alpha=0.3) # 添加网格线,更易查看
plt.legend() # 显示图例
plt.savefig("小明成绩折线图.png") # 保存图表到本地
plt.show() # 弹出图表窗口
# 5. 绘制柱状图(对比各科平均分,更直观)
print("=== 正在绘制柱状图 ===")
plt.figure(figsize=(8, 4))
# 绘制各科平均分柱状图
plt.bar(subjects, subject_means, color=["blue", "green", "orange"], width=0.5)
# 给每个柱子添加数值标签(显示平均分)
for i, mean_score in enumerate(subject_means):
plt.text(i, mean_score + 1, f"{mean_score:.2f}", ha="center")
# 添加图表标题和坐标轴标签
plt.title("各科平均分柱状图")
plt.xlabel("科目")
plt.ylabel("平均成绩")
plt.ylim(0, 100) # 设置y轴范围(0-100,符合成绩逻辑)
plt.savefig("各科平均分柱状图.png")
plt.show()
print("图表已保存为「小明成绩折线图.png」和「各科平均分柱状图.png」!")
3. 运行结果
- 弹出两个图表窗口:分别显示 “小明各科成绩折线图”(红色带点折线)、“各科平均分柱状图”(三色柱子,带数值标签)。
- 在当前文件夹下,生成两个图片文件,可双击打开查看,永久保存。
- 柱状图中,每个柱子上方显示具体平均分,直观看到 “数学平均分最高”。
# 出现以下报错提示: === 正在绘制折线图 === Traceback (most recent call last): File "D:\Desktop\\编程与工具基础\数据工具.py", line 130, in <module> plt.show() # 弹出图表窗口 ^^^^^^^^^^ File "D:\soft\python3.12\Lib\site-packages\matplotlib\pyplot.py", line 613, in show return _get_backend_mod().show(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "D:\soft\PyCharm 2024.1\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py", line 41, in __call__ manager.show(**kwargs) File "D:\soft\PyCharm 2024.1\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py", line 144, in show self.canvas.show() File "D:\soft\PyCharm 2024.1\plugins\python\helpers\pycharm_matplotlib_backend\backend_interagg.py", line 85, in show buffer = self.tostring_rgb() ^^^^^^^^^^^^^^^^^ AttributeError: 'FigureCanvasInterAgg' object has no attribute 'tostring_rgb'. Did you mean: 'tostring_argb'? 进程已结束,退出代码为 1 --------------------------------------------------------------------------------------- # 报错原因:PyCharm 的「Matplotlib 工具窗口后端」与你安装的 Matplotlib(3.10.8)版本不兼容,plt.show()触发了后端的不兼容方法调用。 --------------------------------------------------------------------------------------- # 解决方案: 关闭 PyCharm 的「Matplotlib 工具窗口绘图」(无需改代码,最便捷) 核心思路:让 Matplotlib 使用自身默认的绘图后端,而非 PyCharm 的内置后端,避免版本兼容问题。步骤如下: 打开 PyCharm 的设置窗口: Windows:顶部菜单栏 File → Settings(快捷键 Ctrl + Alt + S) 中文界面:文件 → 设置 在设置窗口左侧,依次展开 Tools → Python Scientific(中文界面:工具 → Python 图) 在右侧窗口中,取消勾选「Show plots in tool window」(中文界面:「在工具窗口中显示绘图」) 点击底部 Apply → OK 保存设置 重新运行你的代码,此时plt.show()会弹出独立的 Matplotlib 图表窗口,不再报错。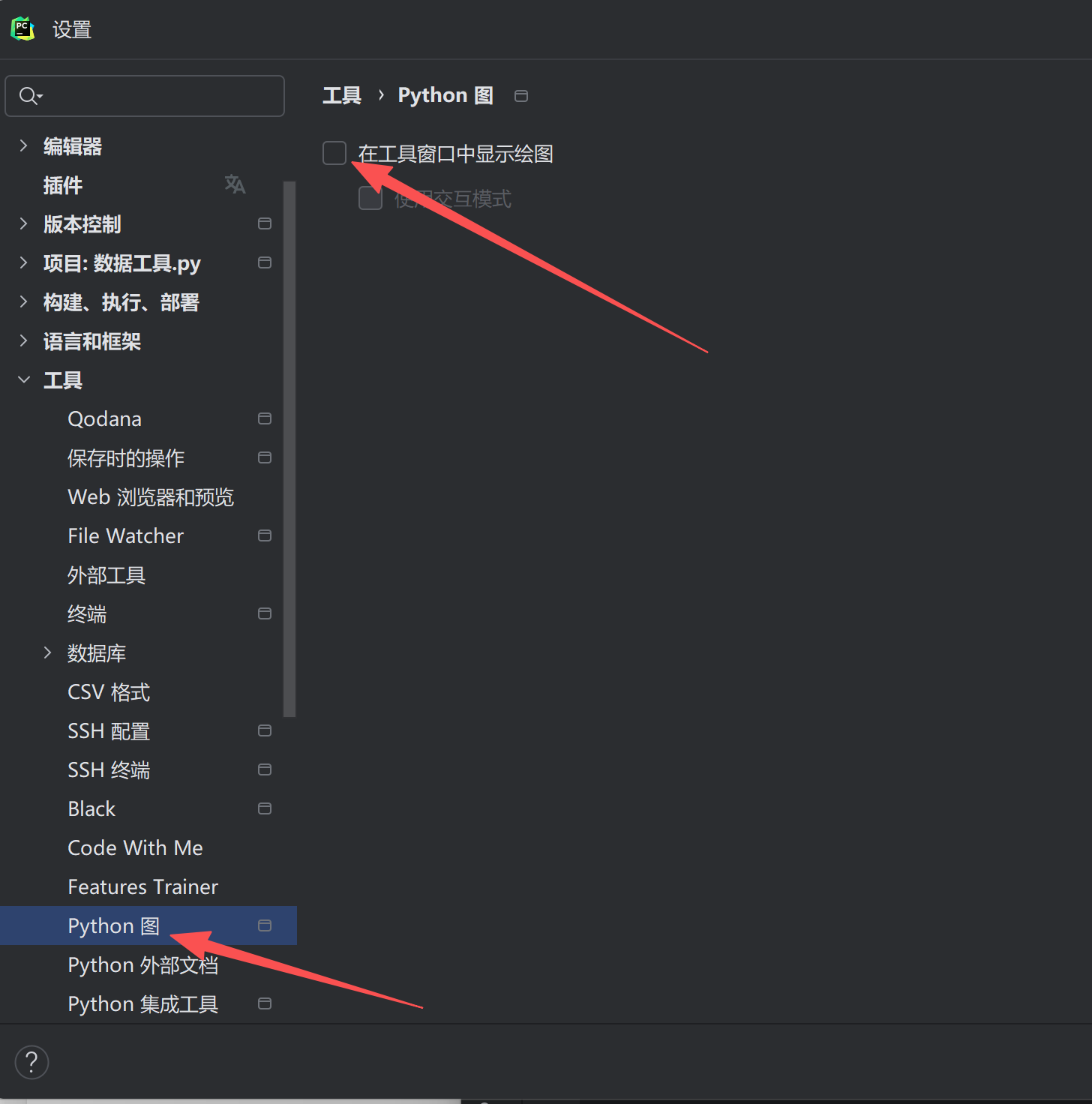
4. 小白避坑
- 中文乱码:必须添加
plt.rcParams两行配置,否则中文显示为方框。 - 图表无法保存:确保脚本所在文件夹有写入权限,无需管理员身份。
- 柱子数值标签错位:
plt.text()中的ha="center"确保数值居中显示。
5. AI 场景核心用途
- 模型评估:绘制模型 “准确率 / 损失值” 折线图,查看模型训练趋势(损失值逐渐下降说明训练有效)。
- 数据分布:绘制数据集的特征分布柱状图(比如不同年龄段用户的占比)。
- 结果展示:将 AI 模型的预测结果可视化,更易向他人展示。
五、 综合实操:三个工具协同工作(完整流程)
核心逻辑
Numpy(数组运算)→ Pandas(表格处理)→ Matplotlib(可视化),这是 AI 数据预处理的标准流程,小白掌握后可直接用于后续项目。
- Numpy:批量处理原始数据,完成缩放 / 统计。
- Pandas:将处理后的数据转换成表格,清洗 / 筛选。
- Matplotlib:将表格数据可视化,生成直观图表。
总结
- 安装:无 Anaconda 时用
pip安装三个工具,搭配国内镜像源,补充openpyxl支持 Excel 读取。 - Numpy:核心是批量数组运算,简化循环,提升效率,掌握
np.array()/np.mean()即可入门。 - Pandas:核心是DataFrame 表格处理,实现 “读取 - 筛选 - 统计 - 保存”,对应 Excel 操作,掌握
df[df[]]筛选、df.mean()统计即可。 - Matplotlib:核心是数据可视化,先解决中文乱码,再掌握
plt.plot()(折线图)、plt.bar()(柱状图),添加标签让图表更完整。 - 三个工具协同工作,是 AI 数据预处理的基础,后续项目中会频繁用到,先掌握基础用法,无需深入复杂功能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)