【ACP-LLM】大模型篇 3
本章介绍了影响大模型内容生成的两个随机性参数:温度和top_p。
2.2 影响大模型内容生成的随机性参数
假设在一个对话问答场景中,用户提问为:“在大模型ACP课程中,你可以学习什么?”。
为了模拟大模型生成内容的过程,我们预设了一个候选Token集合,这些Token分别为:“RAG”、“提示词”、“模型”、“写作”、“画画”。
大模型会从这5个候选Token中选择一个作为结果输出(next-token),如下所示。
用户提问:在大模型ACP课程中,你可以学习什么?
大模型回答:RAG
在这个过程中,有两个重要参数会影响大模型的输出:temperature 和 top_p,它们用来控制大模型生成内容的随机性和多样性。
下面介绍这两个参数的工作原理和使用方式。
2.2.1 temperature:调整候选Token集合的概率分布
在大模型生成下一个词(next-token)之前,它会先为候选Token计算一个初始概率分布。
这个分布表示每个候选Token作为next-token的概率。temperature是一个调节器,它通过改变候选Token的概率分布,影响大模型的内容生成。
通过调节这个参数,你可以灵活地控制生成文本的多样性和创造性。
为了更直观地理解,下图展示了不同temperature值对候选Token概率分布的影响。
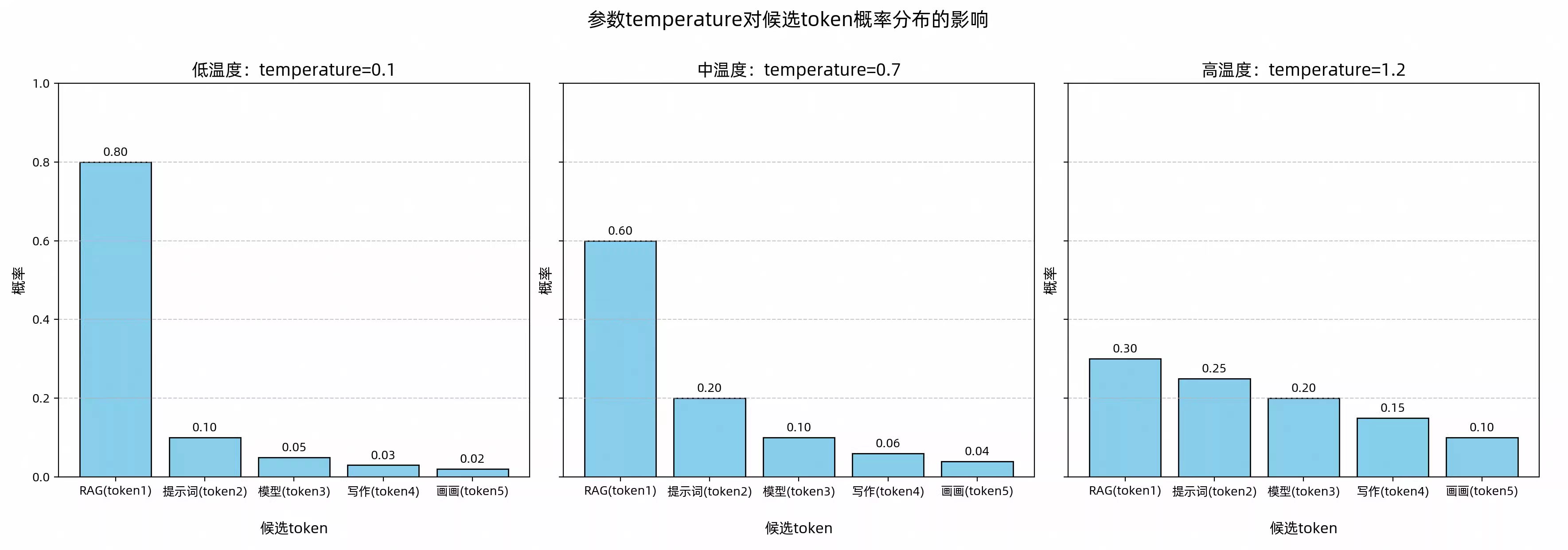
图中的低、中、高温度基于通义千问Max模型的范围[0, 2)划分。
由上图可知,温度从低到高(0.1 -> 0.7 -> 1.2),概率分布从陡峭趋于平滑,候选Token“RAG”从出现的概率从0.8 -> 0.6 -> 0.3,虽然依然是出现概率最高的,但是已经和其它的候选Token概率接近了,最终输出也会从相对固定到逐渐多样化。
针对不同使用场景,可参考以下建议设置 temperature 参数:
- 明确答案(如生成代码):调低温度。
- 创意多样(如广告文案):调高温度。
- 无特殊需求:使用默认温度(通常为中温度范围)。
需要注意的是,当 temperature=0 时,虽然会最大限度降低随机性,但无法保证每次输出完全一致。
如果想深入了解,可查阅 temperature的底层算法实现。
下面体验temperature的效果。
通过调整temperature值,对同一问题提问 10 次,观察回答内容的波动情况。
temperature的示例代码跟接下来要讲解的top_p类似,先封装以供后续使用。
import time
def get_qwen_stream_response(user_prompt, system_prompt, temperature, top_p):
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=temperature,
top_p=top_p,
stream=True
)
for chunk in response:
yield chunk.choices[0].delta.content
# temperature, top_p 默认值使用通义千问 Max 模型默认值
def print_qwen_stream_response(user_prompt, system_prompt, temperature=0.7, top_p=0.8, iterations=10):
for i in range(iterations):
print(f"输出 {i + 1} : ", end="")
# 防止限流,添加延迟
time.sleep(0.5)
response = get_qwen_stream_response(user_prompt, system_prompt, temperature, top_p)
output_content = ''
for chunk in response:
output_content += chunk
print(output_content)
实验1:temperature=0
# 示例
print_qwen_stream_response(user_prompt="马也可以叫做", system_prompt="请帮我续写内容,字数要求是4个汉字以内。", temperature=0)
输出 1 : 骏
输出 2 : 骏
输出 3 : 骏
输出 4 : 骏
输出 5 : 骏
输出 6 : 骏
输出 7 : 骏
输出 8 : 骏
输出 9 : 骏
输出 10 : 骏
实验2:temperature=1.9
# 或者
print_qwen_stream_response(user_prompt="马也可以叫做", system_prompt="请帮我续写内容,字数要求是4个汉字以内。", temperature=1.9)
输出 1 : 马儿
输出 2 : 骏
输出 3 : 骏马
输出 4 : 骏
输出 5 : 骏马
输出 6 : 骏
输出 7 : 骏
输出 8 : 骏马
输出 9 : 骏
输出 10 : 骏
从实验中可以明显观察到,温度值越高,模型生成的内容更具变化和多样性。
2.2.2 top_p:控制候选Token集合的采样范围
top_p 是一种筛选机制,用于从候选 Token 集合中选出符合特定条件的“小集合”。
具体方法是:按概率从高到低排序,选取累计概率达到设定阈值的 Token 组成新的候选集合,从而缩小选择范围。
下图展示了不同top_p值对候选Token集合的采样效果。
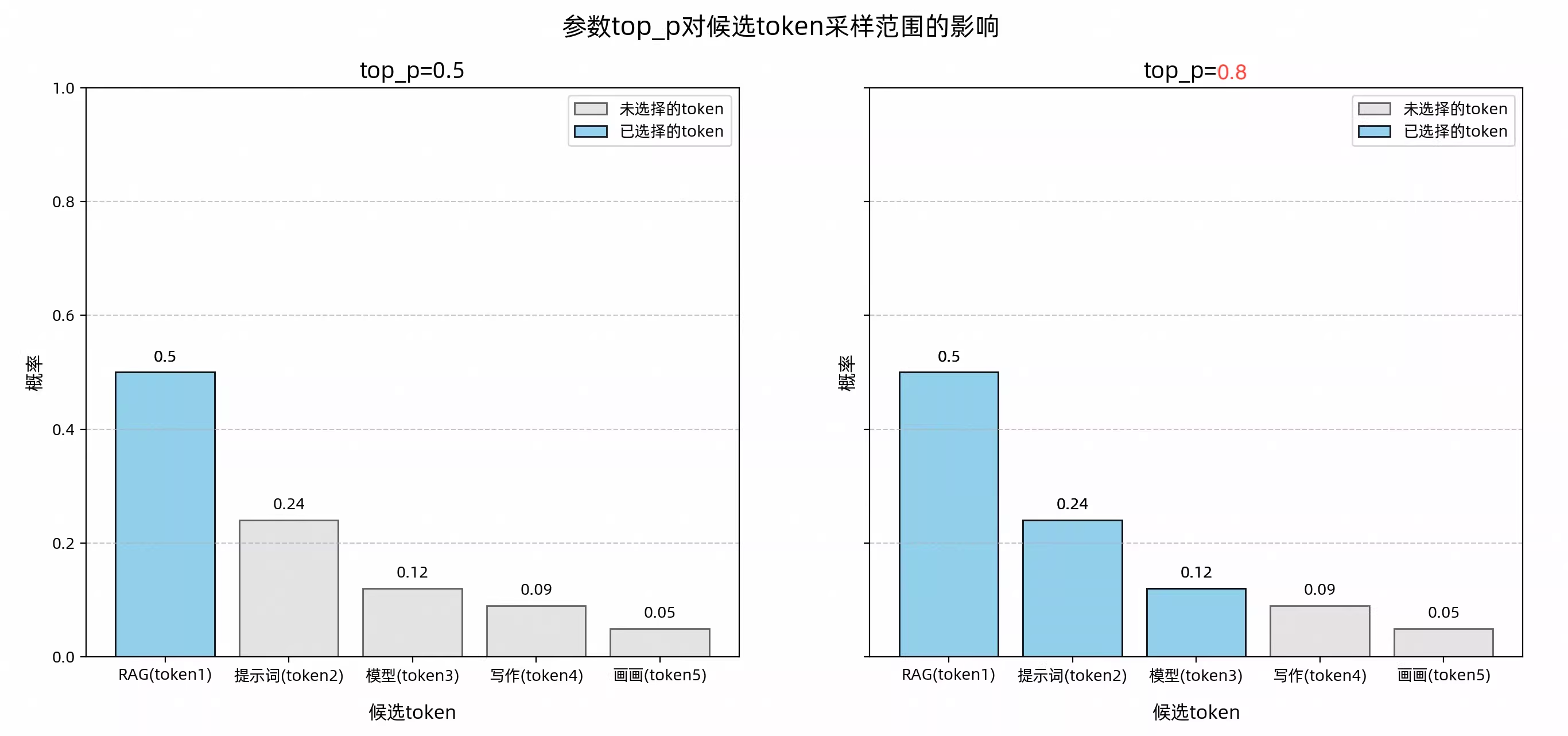
图示中蓝色部分表示累计概率达到top_p阈值(如0.5或0.8)的Token,它们组成新的候选集合;
灰色部分则是未被选中的Token。
当top_p=0.5时,模型优先选择最高概率的Token,即“RAG”;
而当top_p=0.8时,模型会在“RAG”、“提示词”、“模型”这三个Token中随机选择一个生成输出。
由此可见,top_p值对大模型生成内容的影响可总结为:
- 值越大 :候选范围越广,内容更多样化,适合创意写作、诗歌生成等场景。
- 值越小 :候选范围越窄,输出更稳定,适合新闻初稿、代码生成等需要明确答案的场景。
- 极小值(如
0.0001):理论上模型只选择概率最高的Token,输出非常稳定。
但实际上,由于分布式系统、模型输出的额外调整等因素可能引入的微小随机性,仍无法保证每次输出完全一致。
下面体验top_p的效果。
通过调整top_p值,对同一问题提问10次,观察回答内容的波动情况。
实验1:top_p=0.001
print_qwen_stream_response(user_prompt="为一款智能游戏手机取名,可以是", system_prompt="请帮我取名,字数要求是4个汉字以内。", top_p=0.001)
输出 1 : 骁影
输出 2 : 骁影
输出 3 : 骁影
输出 4 : 骁影
输出 5 : 骁影
输出 6 : 骁影
输出 7 : 骁影
输出 8 : 骁影
输出 9 : 骁影
输出 10 : 骁影
实验2:top_p=0.8
print_qwen_stream_response(user_prompt="为一款智能游戏手机取名,可以是", system_prompt="请帮我取名,字数要求是4个汉字以内。", top_p=0.8)
输出 1 : 星刃
输出 2 : 星刃
输出 3 : 骁影
输出 4 : 智竞先锋
输出 5 : 骁影
输出 6 : 骁影
输出 7 : 星刃
输出 8 : 骁影
输出 9 : 骁影
输出 10 : 星驰
注:
通义千问Max模型:top_p取值范围为(0,1],默认值为0.8。
根据实验结果可以发现,top_p值越高,大模型的输出结果随机性越高。
2.2.3 小结
- 是否需要同时调整
temperature和top_p?
为了确保生成内容的可控性,建议不要同时调整top_p和temperature,同时调整可能导致输出结果不可预测。
你可以优先调整其中一种参数,观察其对结果的影响,再逐步微调。
知识延展:
- 设置
temperature、top_p、seed控制大模型输出,为何仍存在随机性?
即使将temperature设置为0、top_p设置为极小值(如0.0001),并使用相同的seed,同一个问题的生成结果仍可能出现不一致。
这是因为一些复杂因素可能引入微小的随机性,例如大模型运行在分布式系统中,或模型输出引入了优化。
举个例子:
分布式系统就像用不同的机器切面包。
虽然每台机器都按照相同的设置操作,但由于设备之间的细微差异,切出来的面包片可能还是会略有不同。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)